回目录 《storm》
# 1.Basics
https://storm.apache.org/releases/1.2.2/index.html https://storm.apache.org/releases/current/Tutorial.html
Master node runs Nimbus Worker nodes runs Supervisor The supervisor listens for work assigned to its machine and starts and stops worker processes as necessary based on what Nimbus has assigned to it. Each worker process executes a subset of a topology; a running topology consists of many worker processes spread across many machines. Each node in a topology contains processing logic, and links between nodes indicate how data should be passed around between nodes
A stream is an unbounded sequence of tuples The basic primitives Storm provides for doing stream transformations are "spouts" and "bolts". Spouts and bolts have interfaces that you implement to run your application-specific logic. A spout is a source of streams A bolt consumes any number of input streams, does some processing, and possibly emits new streams. A topology is a graph of stream transformations where each node is a spout or bolt. Edges in the graph indicate which bolts are subscribing to which streams. Each node in a Storm topology executes in parallel. In your topology, you can specify how much parallelism you want for each node, and then Storm will spawn that number of threads across the cluster to do the execution
Executor == thread
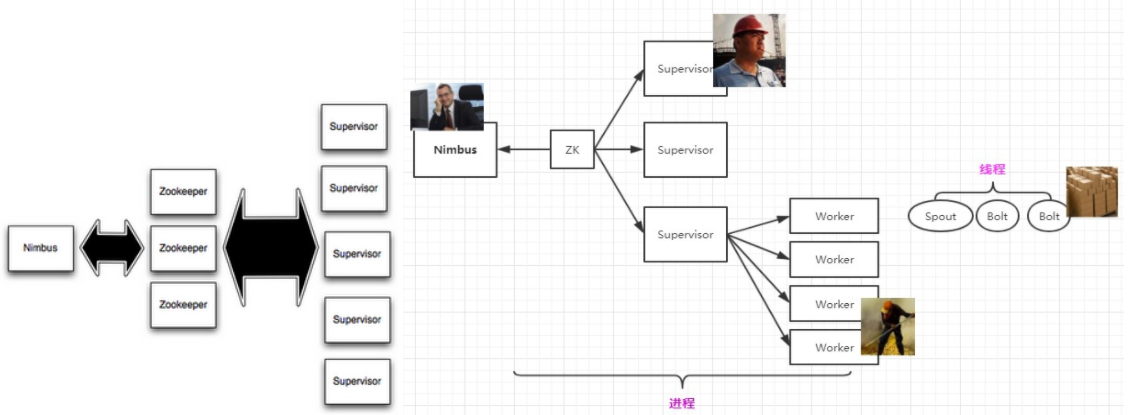
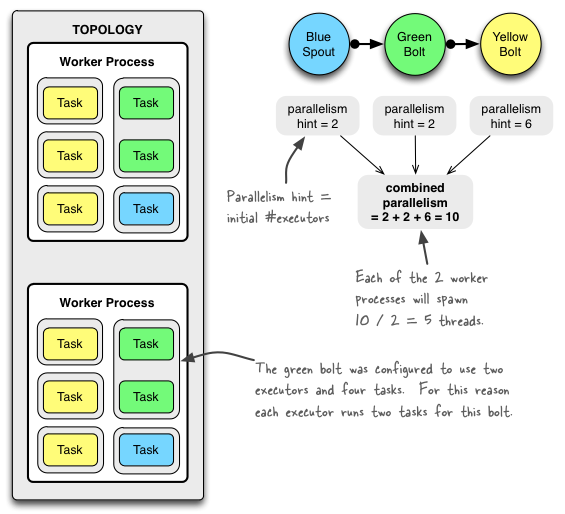
# 1.1 Tasks(==partitions of data)
Each spout or bolt executes as many tasks across the cluster. Each task corresponds to one thread of execution, and stream groupings define how to send tuples from one set of tasks to another set of tasks. You set the parallelism for each spout or bolt in the setSpout and setBolt methods of TopologyBuilder.
# 1.2 Workers
Topologies execute across one or more worker processes. Each worker process is a physical JVM and executes a subset of all the tasks for the topology. For example, if the combined parallelism of the topology is 300 and 50 workers are allocated, then each worker will execute 6 tasks (as threads within the worker). Storm tries to spread the tasks evenly across all the workers.
# 1.3 Stream groupings
Part of defining a topology is specifying for each bolt which streams it should receive as input. A stream grouping defines how that stream should be partitioned among the bolt's tasks. There are eight built-in stream groupings in Storm, and you can implement a custom stream grouping by implementing the CustomStreamGrouping interface: Shuffle grouping: Tuples are randomly distributed across the bolt's tasks in a way such that each bolt is guaranteed to get an equal number of tuples. Fields grouping: The stream is partitioned by the fields specified in the grouping. For example, if the stream is grouped by the "user-id" field, tuples with the same "user-id" will always go to the same task, but tuples with different "user-id"'s may go to different tasks. Understanding the Parallelism of a Storm Topology https://storm.apache.org/releases/1.2.2/Understanding-the-parallelism-of-a-Storm-topology.html
More:: Concepts https://storm.apache.org/releases/current/Concepts.html Local Mode https://storm.apache.org/releases/current/Local-mode.html Running Topologies on a Production Cluster https://storm.apache.org/releases/current/Running-topologies-on-a-production-cluster.html
Guaranteeing Message Processing https://storm.apache.org/releases/current/Guaranteeing-message-processing.html Transactional Topologies(exactly-once messaging semantics) https://storm.apache.org/releases/current/Transactional-topologies.html Distributed RPC https://storm.apache.org/releases/current/Distributed-RPC.html
refer https://www.twblogs.net/a/5c2317edbd9eee16b3db28d5/zh-cn
# 1.4 Handson
Apache Storm is awesome. This is why (and how) you should be using it. https://medium.freecodecamp.org/apache-storm-is-awesome-this-is-why-you-should-be-using-it-d7c37519a427?gi=208845af9b84
# Run in Local
https://storm.apache.org/releases/current/Setting-up-development-environment.html
Let's quickly go over the relationship between your machine and a remote cluster. A Storm cluster is managed by a master node called "Nimbus". Your machine communicates with Nimbus to submit code (packaged as a jar) and topologies for execution on the cluster, and Nimbus will take care of distributing that code around the cluster and assigning workers to run your topology. Your machine uses a command line client called storm to communicate with Nimbus. The storm client is only used for remote mode; it is not used for developing and testing topologies in local mode. Installing a Storm release locally is only for interacting with remote clusters. For developing and testing topologies in local mode, it is recommended that you use Maven to include Storm as a dev dependency for your project. You can read more about using Maven for this purpose on Maven. The previous step installed the storm client on your machine which is used to communicate with remote Storm clusters. Now all you have to do is tell the client which Storm cluster to talk to. To do this, all you have to do is put the host address of the master in the ~/.storm/storm.yaml file. It should look something like this: nimbus.seeds: ["123.45.678.890"] Configuration: https://github.com/apache/storm/blob/v1.1.2/conf/defaults.yaml
export PATH="/home/test/workspace/storm/apache-storm-1.2.2/bin:$PATH" https://github.com/apache/storm/tree/v1.2.2/examples/storm-starter /home/test/workspace/storm/apache-storm-1.2.2/examples/storm-starter
For local cluster testing(submit to local cluster and view with storm ui), must provide args[0] which means run in cluster mode, Local mode(run with mvn) will use LocalCluster, it won’t be submit to the cluster!!!
** Way 1: Local Mode/Directly run**
First install dependency mvn clean install -DskipTests=true [INFO] Installing /home/test/workspace/storm/apache-storm-1.2.2/examples/storm-starter/target/storm-starter-1.2.2.jar to /home/test/.m2/repository/org/apache/storm/storm-starter/1.2.2/storm-starter-1.2.2.jar [INFO] Installing /home/test/workspace/storm/apache-storm-1.2.2/examples/storm-starter/dependency-reduced-pom.xml to /home/test/.m2/repository/org/apache/storm/storm-starter/1.2.2/storm-starter-1.2.2.pom or If not install with “mvn clean install -DskipTests=true”, should do this instead ‘build fat jar with dependency'
https://stackoverflow.com/questions/16903185/why-cant-i-run-the-example-from-storm-starter-using-this-command
Then cd /home/test/workspace/storm/apache-storm-1.2.2/examples/storm-starter mvn compile exec:java -Dstorm.topology=org.apache.storm.starter.ExclamationTopology
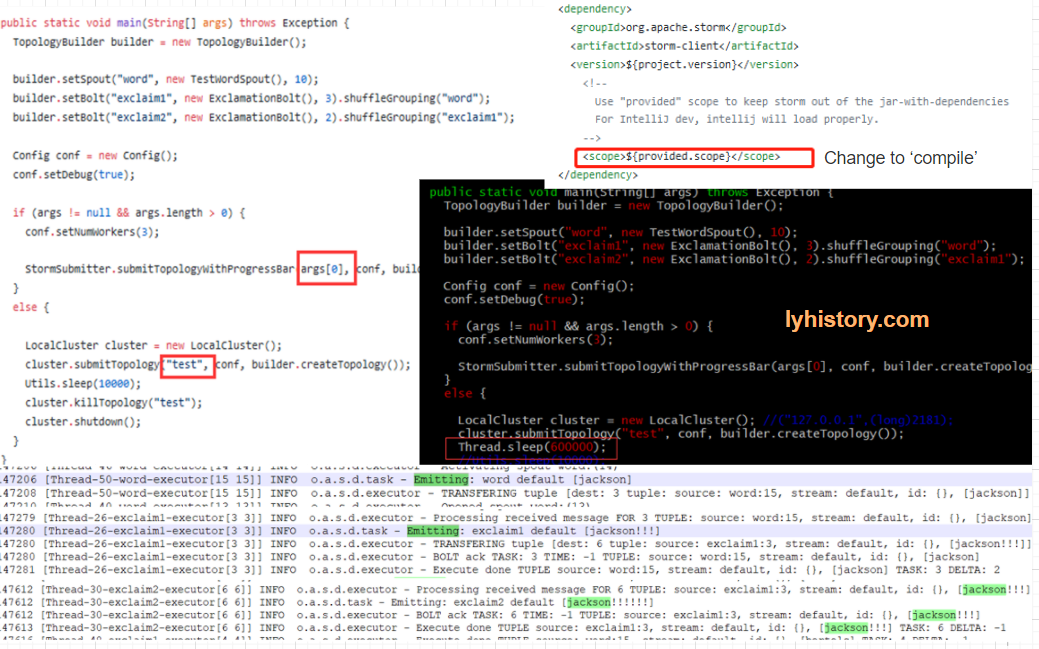
mvn compile exec:java -Dstorm.topology=org.apache.storm.starter.WordCountTopology (failed, because it cann’t be run in local mode) AttributeError: 'module' object has no attribute 'BasicBolt' https://stackoverflow.com/questions/31985819/how-to-run-wordcounttopology-from-storm-starter-in-intellij
https://medium.com/@Sugeesh/connecting-python-bolt-for-apache-storm-topology-af6c2e3f2200
https://github.com/apache/storm/blob/master/storm-multilang/python/src/main/resources/resources/storm.py
Download to /home/test/workspace/storm/apache-storm-1.2.2/examples/storm-starter/multilang/resources/
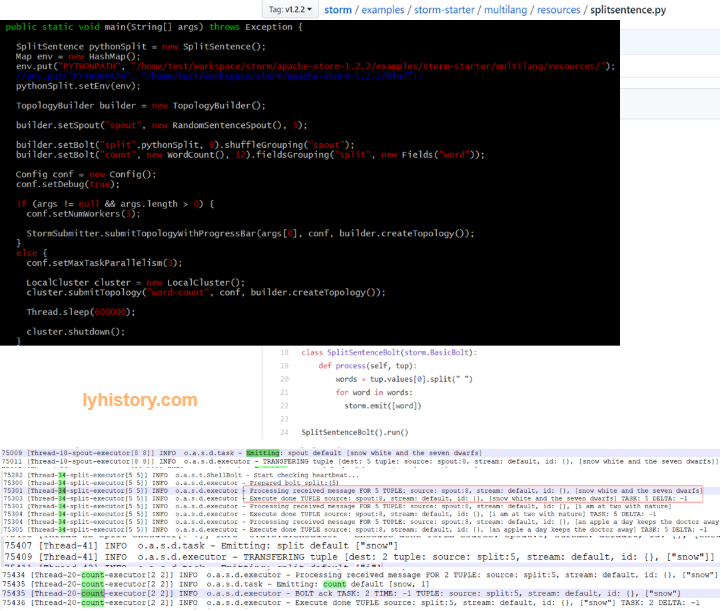
** Way 2: Cluster Mode/submit to local ‘cluster:: ** https://storm.apache.org/releases/1.2.2/Command-line-client.html http://www.haroldnguyen.com/blog/2015/01/setting-up-storm-and-running-your-first-topology/ http://storm.apache.org/releases/current/Setting-up-a-Storm-cluster.html
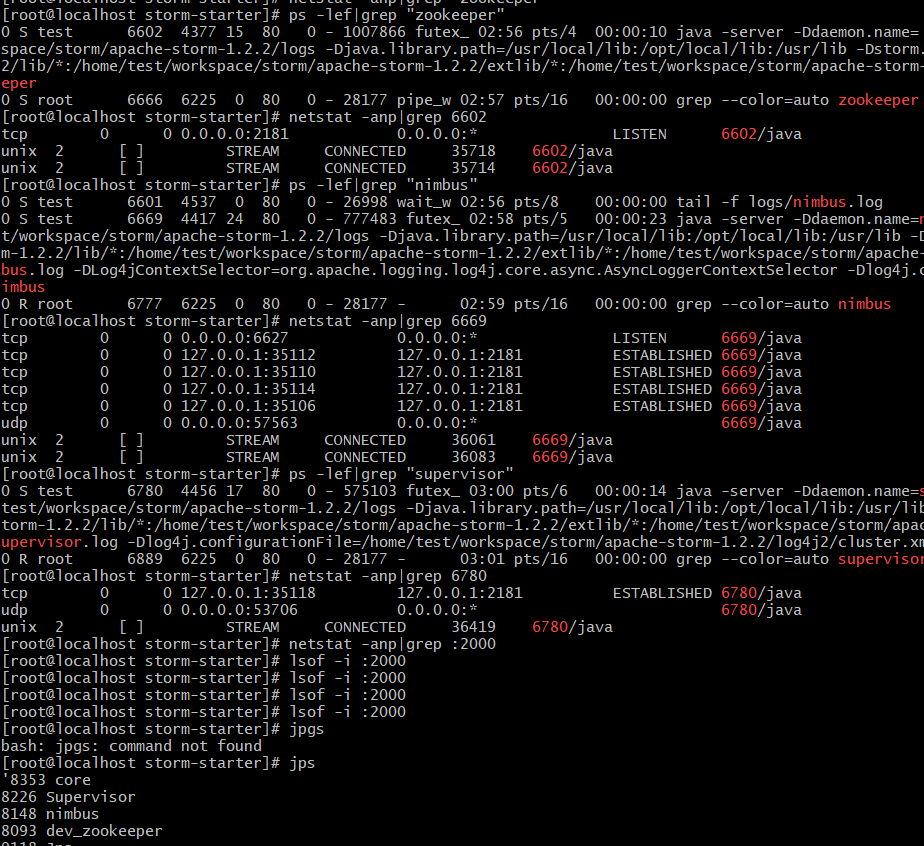
storm dev-zookeeper [port 2181]
storm nimbus
storm supervisor
storm list
storm logviewer
storm monitor test
storm ui
/apache-storm-1.2.2/conf/storm.yaml
### ui.* configs are for the master
ui.host: 0.0.0.0
ui.port: 8080
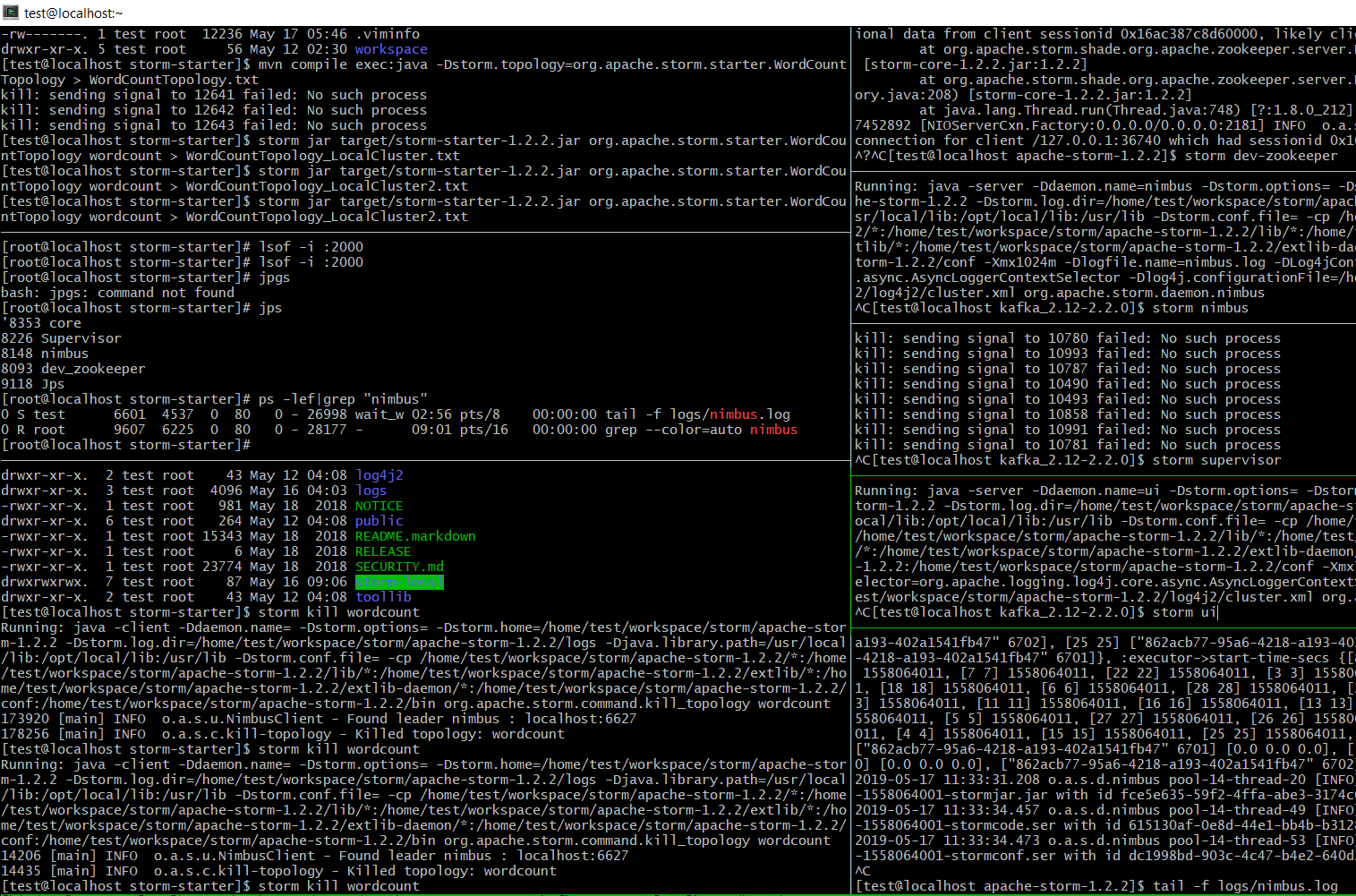
storm jar target/storm-starter-1.2.2.jar org.apache.storm.starter.ExclamationTopology test
storm jar target/storm-starter-1.2.2.jar org.apache.storm.starter.WordCountTopology wordcount storm jar target/storm-starter-1.2.2.jar org.apache.storm.starter.WordCountTopology wordcount > WordCountTopology_LocalCluster.txt
[root@localhost test]# find / -name "wordcount-1-1558059690" -type d -print /home/test/workspace/storm/apache-storm-1.2.2/logs/workers-artifacts/wordcount-1-1558059690 /home/test/workspace/storm/apache-storm-1.2.2/storm-local/supervisor/stormdist/wordcount-1-1558059690 [root@localhost test]# ls /home/test/workspace/storm/apache-storm-1.2.2/logs/workers-artifacts/wordcount-1-1558059690 6700 6701 6702 6703 [root@localhost test]# ls /home/test/workspace/storm/apache-storm-1.2.2/logs/workers-artifacts/wordcount-1-1558059690/6702 gc.log.0.current worker.log worker.log.err worker.log.metrics worker.log.out worker.yaml [root@localhost test]# vim /home/test/workspace/storm/apache-storm-1.2.2/logs/workers-artifacts/wordcount-1-1558059690/6702/worker.log
?# Error on initialization of server mk-worker chmod 777 /home/test/workspace/storm/apache-storm-1.2.2/storm-local/
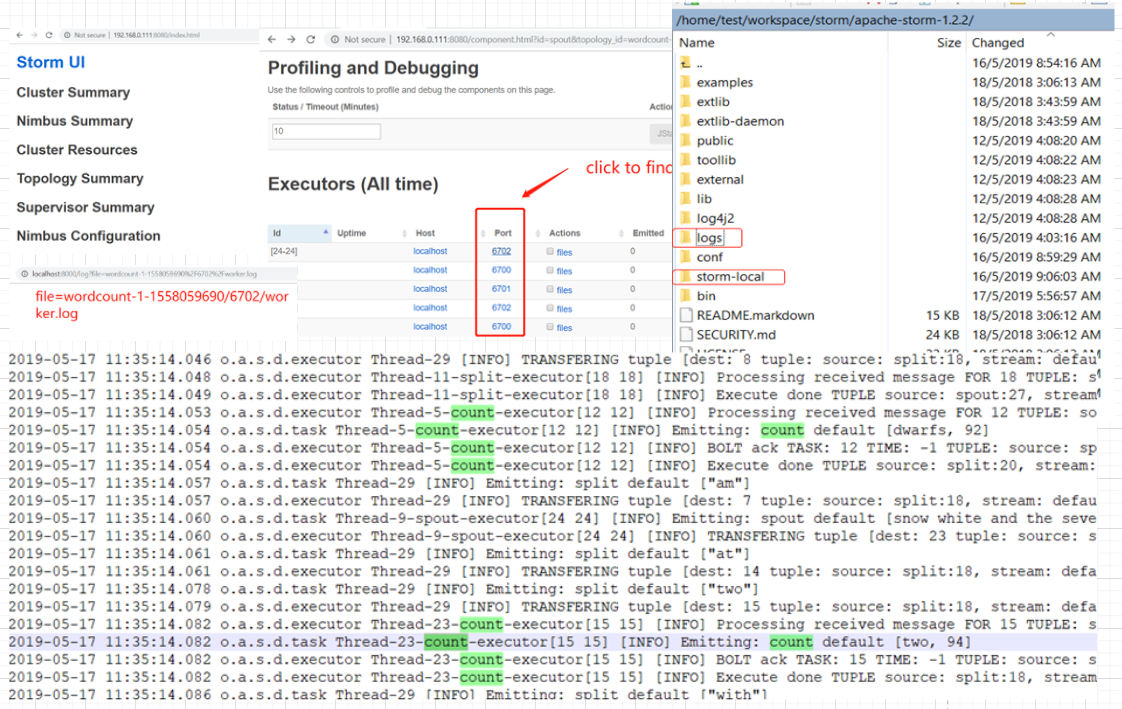 storm kill wordcount
storm kill wordcount
# Run in cluster
https://www.cnblogs.com/xiaoheike/p/7236363.html
# storm vs kafka
Kafka wordcount是stateful operation,因为每个task/consumer完全独立跑完整的topology,每个consumer处理某一个partition,所以要借助data store来存储ktable“中间”状态,data store也是多个consumer/task“协作”的结果 而storm wordcount是stateless operation,因为一个topology是分成sprout,bolt,每个sprout/bolt会开启一个或多个task,这些task在work process中执行,这些work process可能位于不同的机器,所以第一步是split bolt,然后将这些单词进行partition发送至相应的tasks,比如the这个单词会一直发送到某个特定的task进行count,所以对于最后一步count是很简单的,不需要reduce操作,每个count task都只统计相应的单词,互相之间没有重叠,不像kafka那样因为partition比较早,所以不同的parttion之间是有重叠的单词的,所以必须借助一个第三者存储来统计
# Question
port 2000 factory https://github.com/apache/storm/blob/21bb1388414d373572779289edc785c7e5aa52aa/storm-server/src/main/java/org/apache/storm/utils/ZookeeperServerCnxnFactory.java
117291 [org.apache.storm.starter.ExclamationTopology.main()] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - binding to port 0.0.0.0/0.0.0.0:2000 117316 [org.apache.storm.starter.ExclamationTopology.main()] INFO o.a.s.zookeeper - Starting inprocess zookeeper at port 2000 and dir /tmp/dd4462c7-2d70-40ae-ac09-87e16ce24574 118661 [org.apache.storm.starter.ExclamationTopology.main()] INFO o.a.s.s.o.a.z.ZooKeeper - Initiating client connection, connectString=localhost:2000/storm sessionTimeout=20000 watcher=org.apache.storm.shade.org.apache.cura tor.ConnectionState@3ddce4b7 118953 [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2000] INFO o.a.s.s.o.a.z.s.NIOServerCnxnFactory - Accepted socket connection from /127.0.0.1:38478
https://blog.csdn.net/jpf254/article/details/80787018
LocalCluster https://github.com/apache/storm/blob/master/storm-server/src/main/java/org/apache/storm/LocalCluster.java
# Indepth
Aggregation http://storm.apache.org/releases/current/Trident-tutorial.html
For batch processing(control spout) https://github.com/ptgoetz/storm-signals