回目录 《线程安全》
关键词: 并发 并行 高并发 低并发 互斥 同步 异步 单线程 多线程
程序,进程 线程 协程/纤程quasar
程序是静态的编码,是有序指令的集合,是存放在硬盘的文件,被组织成:正文段(指令集) + 用户数据段(数据); 进程是动态的,程序加载到内存中,分配内存空间,存放正文段(指令集) + 用户数据段(栈 + 堆) + 系统数据段(PCB等系统用到的数据结构),正式定义:所谓进程是由正文段(text)、用户数据段(user segment)以及系统数据段(system segment)共同组成的一个执行环境; 线程是一个进程的最小执行单元;
刚开始工作的时候也曾天真的认为使用一些看起来线程安全的工具类就可以让程序线程安全,比如:使用ConcurrentHashMap一定线程安全? (opens new window)
实际情况复杂的多
# 线程安全概述
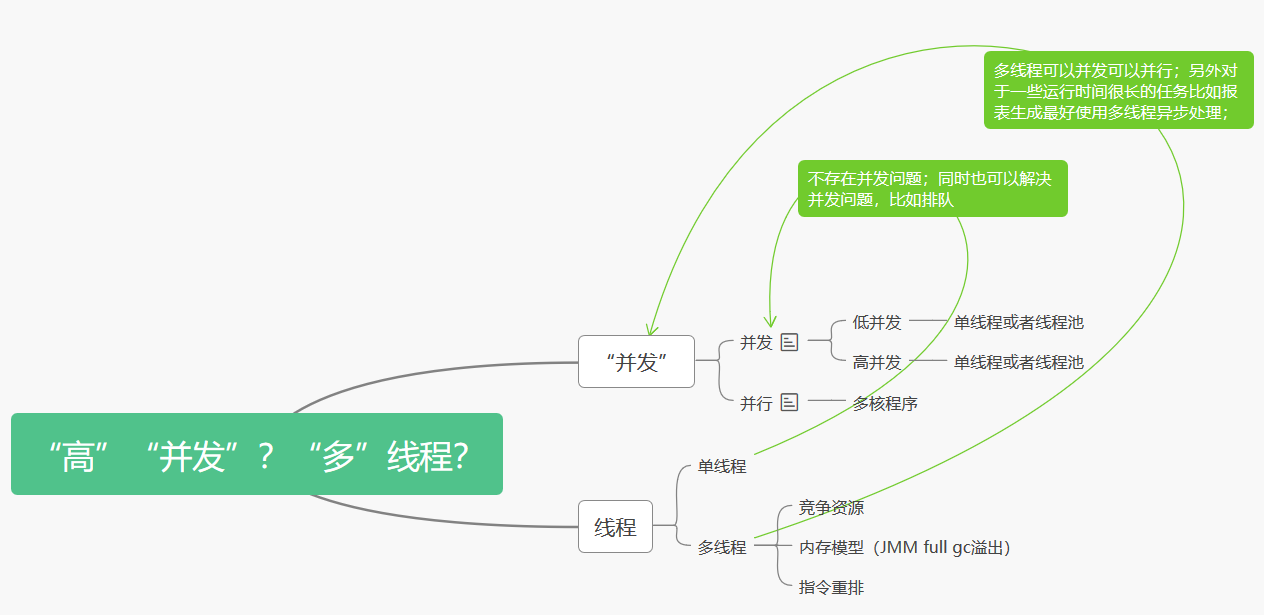
同步 异步 单线程 多线程? 同步,意思是后面操作的输入依赖于前面操作的输出,只能按顺序执行,如果所有操作都是同步的,这种情况一般都是用单线程; 当然了并不是说同步一定是单线程编程,多个线程设置进程之间一样可以实现同步,只不过是互相等待; 因为真实的程序世界并不是非同步就异步,而是两者都有; 异步也并不意味着要多线程,异步强调的是非阻塞,是一种编程模式(pattern),多线程只是一种实现方式,另一种实现方式就是单线程event loop, 引用我在java实用基础一文中的描述:
举例餐厅比喻web应用,传统的blocking做法是,有个http pool(.net的http handler或java的servlet),pool就是一个工作组,工作组里的每个服务员都是处理线程,当一个客人即web request进来时,餐厅立马分配一个服务员给这个客户,全程服务,直到客人离开(http response或者websocket断开连接),整个过程中这个服务员是被独占的,所以是阻塞式; 而假设换一种做法,类似于nodejs和netty的event loop单线程处理方式,餐厅只请一个服务员,第一个客人过来之后,服务员过来安排座位,记下菜单,然后发送给后厨,然后同时第二个客人来了,服务员立马过去做同样的事情,因为是非阻塞式的,在后厨做好饭,服务员端给第一个客人之前,服务员可以利用空余时间去服务其他客人,比如刚才的场景,或者其他服务员要加餐等等,这就是所谓的java响应式编程; 可能有人会疑惑具体什么机制让单线程可以处理并发,很多人之前还以为只有多线程才能产生并发,换个问题:单核时代是如何实现的并发,并发是个宏观的概念,单核微观上同一个时刻只可能处理一个task,只是其他线程在排队等待,然后分片迅速切换,所以nodejs的单线程也是一样的办法,进行排队;再进一步上升到架构角度看,架构中采用message queue的方式也是一种排队处理的扩展方式,下游可以增加多个消费者;
什么时候需要多线程?
1).处理并发,关于并发我说过不一定要用多线程,单线程也可以处理并且效率更高, 但是实际情况下仅仅靠单线程是不够的,一般是主线程为单线程,加上辅助线程处理; 另外有时候不算是很高的并发还是用多线程处理比较简便;
比如数据库的连接, webscoket的连接等;
2).需要长时间处理的程序,要开线程放到后台处理,比如生成报告;
什么是critical resource竞争资源? 跟前面同步完全相反的概念是互斥,互斥是指进程间相互排斥的使用临界资源的现象; 多线程自然涉及到线程安全问题,根本在于是否存在互斥,critical resource竞争资源, 如果多线程不会访问竞争资源就不存在安全问题,否则则要处理,首先要看不同的线程是否在竞争同一个资源: 如果是各自访问其上下文context的资源,比如kafka consumer partition worker线程访问各自的storage则是互相不打扰的; 如果执行的某个方法内只用到了局部变量,由于局部变量位于各自thread的栈里,所以互不干扰; 如果执行的某个方法用到了传入的变量,也就是所谓的形式参数变量,则要看这个传入的变量是否是object,如果只是普通的参数则没关系,如果是对象,要看对象是否是同一个引用,不同引用没有关系; 如果执行的某个方法内用到了同一个引用,不管是传入的还是外部全局的变量,比如log4的logger,由于log4已经做好了线程安全写log,所以不用担心; 如果执行的某个方法内用到了同一个引用: i)但是只是读没有写,读和读是没有冲突的,也没有关系; ii)都有写,但是写不依赖于读,即线程不需要获取“最新”数据就可以直接写入覆盖,这种情况也没有关系; iii)都有写,而且写依赖于读到最新数据,则需要处理; iv)补充一种情况,两个线程A和B,A先读取,然后B再写入修改同一个数据,这种情况不会有线程安全问题,读写不会竞争,但是会有可见性问题(根据下面提到的缓存模型,线程A可能看不到B修改后的数据)
如何保证多线程在竞争资源时的安全?
1)多线程编程安全最“简单”的方式就是加锁(悲观锁); 锁升级:偏向锁(不加锁,记录threadid)、自旋锁(占用cpu,死循环等待)、重量级锁(内核态,操作系统级别) Java 中实现悲观锁的方式主要有以下两种:
synchronized 关键字:Java 中最常见的实现悲观锁的方式就是使用 synchronized 关键字。当一个线程进入代码块时,其他线程会被阻塞,直到当前线程执行完毕。
Lock 接口:Java 5 提供了 Lock 接口来替代 synchronized 关键字。Lock 接口中定义了 lock() 和 unlock() 方法,用来上锁和解锁。与 synchronized 不同的是,Lock 接口支持公平锁和非公平锁两种方式,并且可以在特定时间内尝试获取锁。
悲观锁的优点是可以保证数据操作的一致性,避免并发冲突。但是它会导致系统资源利用不充分、效率低下,因为所有其他线程只有等待当前线程释放锁之后才能执行。
2)另一种方式自然是“不加锁”,网上经常混淆各种概念,总结一下无锁基本两种思路:
乐观锁方式
版本号机制:数据库中记录每条数据更新的版本号,在更新某条数据时,先取出当前的版本号,然后将新的版本号加 1,并且与原版本号进行比较。如果两个版本号相同,则说明数据未被其他线程修改,可以执行更新操作;如果不同,则表示有其他线程已经修改过该数据,需要重新获取最新版本号再试一次。
时间戳机制:数据库中记录每条数据修改的时间戳。当有线程要更新数据时,它会通过比较自己持有的时间戳和数据库中的时间戳来判断该数据是否被其他线程修改过。如果时间戳相同,则更新成功;如果不同,则需要重新获取最新时间戳并重试。
乐观锁的优点是能够充分利用系统资源,提高并发性。但是,由于多个线程可以同时对同一数据进行操作,因此会导致版本号(或时间戳)频繁变化,需要额外的开销用于维护版本号。 本质就是基于CAS实现的, java中常见的就是基于CAS AtomicInteger或AtomicReference(注意:1.AtomicInteger本身是自旋锁 2.AtomicInteger在多核的情况下依然会有锁LOCK_IF_MP)
引入一个有界或无界队列来排队,实际上队列也分为有锁和无锁的,具体可以看我前面写的并发控制concurrent, 所以相当于把多线程的水龙头对接到一个队列上,把对共享资源的访问通过排队的方式隔离开,至于队列本身的实现同样可以参考我写的并发控制一章,所以多线程安全问题转换成了如何排队的问题; 例如: LMAX开发的Disruptor就是这么一个无锁高性能有界循环队列,其内部实现没有研究过,估计也是乐观锁的方式
关于线程安全问题,还有两个不可忽视的重要问题,比如高并发下引起的jmm内存溢出,以及jvm优化的指令重排问题instruction reordering
一般高并发引起的jmm full gc及内存溢出不归类于线程安全问题,因为其引起的原因是因为内存的分配不合理加上高并发/高频内存分配引起的问题,但是我这里并没有说“多”线程还是“单”线程, 所以总归也是属于线程问题,full gc到溢出也绝对属于安全问题;
而多线程会涉及到另外一个指令重排的问题 (opens new window), 指令重排有两个条件: a)首先在单线程下,编译器、runtime和处理器都必须遵守as-if-serial语义,不管怎么重排序(编译器和处理器为了提高并行度),单线程序的执行结果不能被改变。 b)存在数据依赖关系的不允许重排序
总结一下: 不管并发问题需不需要多线程来处理,多线程本身自然是引入了并发问题,又是鸡生蛋蛋生鸡的问题,并发访问竞争资源就会产生:幻读、不可重复读、脏读等读写冲突问题,对于一个应用程序来说, 任何一个环节都可能有问题,数据库层面已经帮我们做好了一定程度的处理,参考我在并发一文中提到的数据库隔离水平,但是应用层还需要我们自己做好处理,另外过高的并发还可能引起内存溢出、指令重排, 这个又涉及到底层比如JVM级别的优化处理;
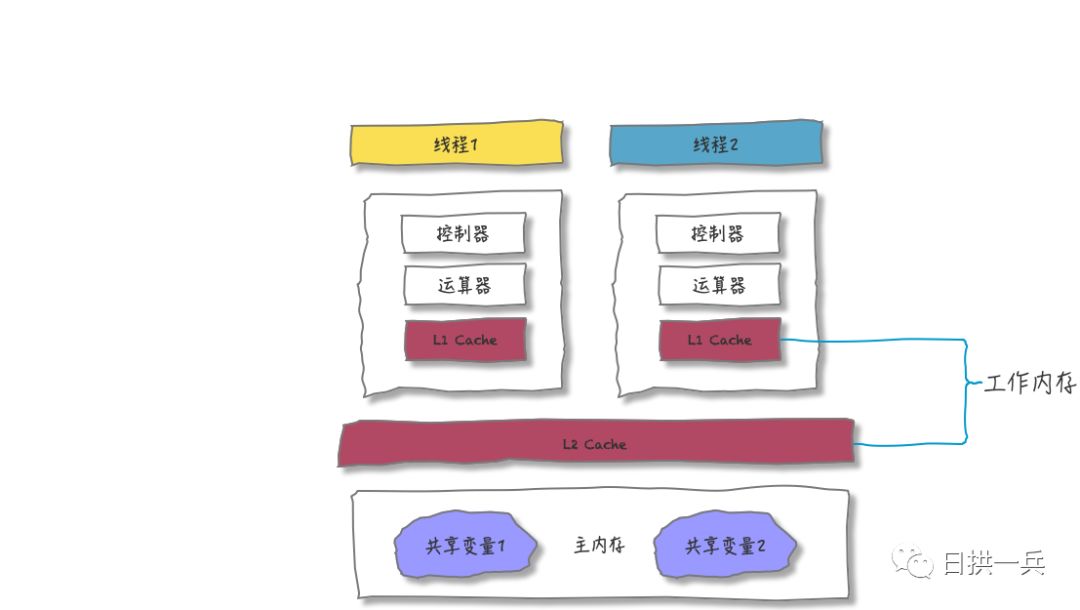
# 内存模型与竞争资源
到底什么是内存模型呢?看到有两种不同的观点:
A:内存模型是用来描述编程语言在支持多线程编程中对共享内存访问的顺序。 B:内存模型的本质是指在单线程情况下CPU指令在多大程度上发生指令重排(Reorder) [1]。
实际上A,B两种说法都是正确的,只不过是在尝试从不同的角度去说明memory model的概念。不过个人认为,内存模型表达为“内存顺序模型”可能更加贴切一点。 一个良好的memory model定义包含3个方面:
Atomic Operations Partial order of operations Visable effects of operations
这里要强调的是:
我们这里所说的内存模型和CPU的体系结构、编译器实现和编程语言规范( C/C++和Java等不同的编程语言都有定义内存模型相关规范。)3个层面都有关系。
- jmm
- C++11引入memory order的意义在于:在语言层提供了一个与运行平台无关和编译器无关的标准库, 让我们可以在high level languange层面实现对多处理器对共享内存的交互式控制。 https://juejin.cn/post/7350089511291289615
https://www.youtube.com/watch?v=Sa08x_NMZIg
不同的系统内存缓存模型可能不同,甚至有的没有缓存,https://developpaper.com/what-exactly-does-volatile-solve/
多核共享内存 (opens new window) 
volatile和synchronized到底啥区别?多图文讲解告诉你 (opens new window) synchronized 是独占锁/排他锁,而volatile不是排他的,根据下面内存模型可以知道,volatile只是说不用L1 L2缓存,直接读写主内存,只有在写入不依赖读的情况下才可以用volatile, 否则只要是竞争资源就不可以用volatile,换句话说volatile解决的是上面提到的“可见性”问题,但是不能解决线程安全问题,至于原因在/docs/software/java 关于JMM部分提到了
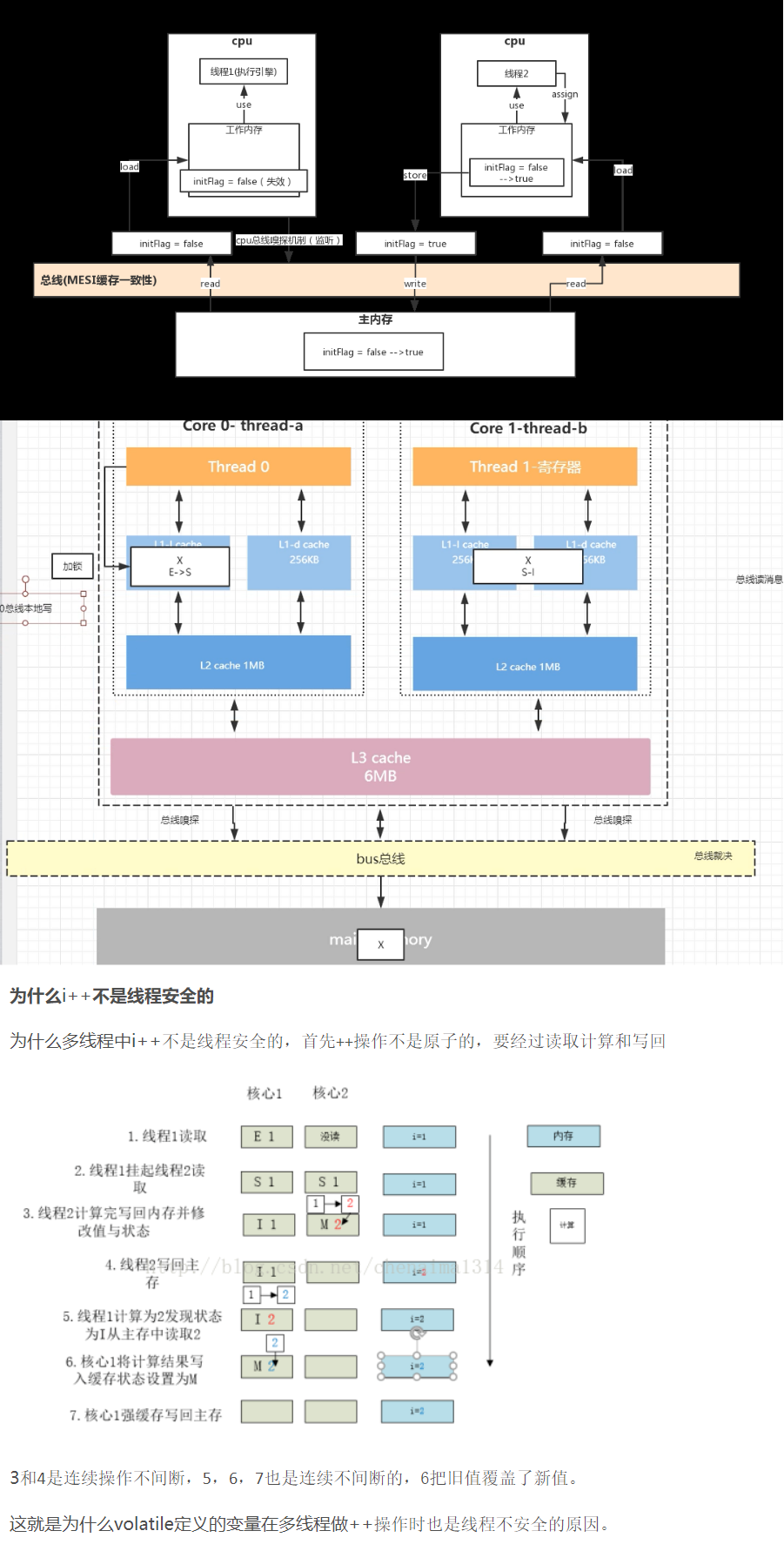
JMM即java内存模型规范是个抽象概念,本质上跟上面所描述的cpu缓存模型是类似的,当然有其标准如JSR 133规范 (opens new window)
高并发下JMM的指令重排(volatile可以禁用指令重排)
指令重排 memory reorder instruction reorder 编译期重排 运行期重排
# 锁机制解读
# 死锁
# 死锁的条件
死锁的发生必须同时满足以下四个条件:
- mutual exclusion 互斥条件:Two or more resources are non-shareable (Only one process can use at a time). 一个资源每次只能被一个进程使用。即系统中存在一个资源一次只能被一个进程所使用。
- resource holding 请求与保持条件(也称为占有且等待条件):A process is holding at least one resource and waiting for resources. 一个进程因请求资源而阻塞时,对已获得的资源保持不放。即系统中存在一个进程已占有了分给它的资源,但仍然等待其它资源。
- no preemption 不剥夺条件(也称为不可抢占条件):A resource cannot be taken from a process unless the process releases the resource. 进程已获得的资源,在未使用完之前,不能强行剥夺。即系统中存在一个资源仅能被占有它的进程所释放,而不能被别的进程强行抢占。
- circular wait 循环等待条件:A set of processes waiting for each other in circular form. 若干进程之间形成一种头尾相接的循环等待资源关系。即在系统中存在一个由若干进程形成的环形请求链,其中的每一个进程均占有若干种资源中的某一种,同时每一个进程还要求链上下一个进程所占有的资源。 只要这四个条件中的任何一个不成立,死锁就不会发生。
# 死锁的类型
- Lock-Ordering-Deadlock 锁顺序死锁:这是最基本的死锁类型,它发生在两个或多个线程以不同的顺序请求同一组锁时。如果每个线程都持有部分锁并等待获取剩余的锁,而这些锁已经被其他线程持有,那么就会形成死锁。
public class LeftRightDeadLock {
private final Object left = new Object();
private final Object right = new Object();
public void leftRight(){
synchronized (left) {
synchronized (right) {
//doSomethoing();
}
}
}
public void rightLeft(){
synchronized (right) {
synchronized (left) {
//doSomethoing();
}
}
}
}
死锁原因:
两个线程试图以不同的顺序来获得相同的锁。LeftRight线程获得left锁而尝试获得right锁,而rightLeft线程获得了right锁而尝试获得left锁,并且两个线程的操作是交错执行的,因此它们会发生死锁。
解决方法:
如果按照相同的顺序来请求锁,那么就不会发生死锁。例如,每个需要L和M的线程都一相同的顺序来获取L和M,就不会发生死锁了。
要想验证锁顺序的一致性,需要对程序中的加锁行为进行全局分析。如果只是单独地分析 每条获取多个锁的代码路径,那是不够的 :leftRight 和 rightLeft 都采用了“合理的”方式来获 得锁,它们只是不能相互兼容。当需要加锁时,它们需要知道彼此正在执行什么操作。
- 动态锁顺序死锁:这种死锁类型与锁顺序死锁相似,但区别在于锁的顺序不是固定的,而是根据运行时的数据或条件动态决定的。这增加了死锁发生的复杂性和难以预测性。
下面的代码:将资金从一个账户转入另一个账户。在开始转账之前,首先要获得这两个Account对象的锁,以确保通过原子的方式来更新两个账户中的余额。
public void transferMoney(Account fromAccount, Account toAccount, DollarAmount amount) throws InsufficientFundsException {
synchronized (fromAccount) {//先锁住fromAccount
synchronized (toAccount) {//再锁住toAccount
if (fromAccount.getBalance().compareTo(amount) < 0) {
fromAccount.debit(amount);
toAccount.credit(amount);
}
}
}
}
死锁原因:
所有的线程似乎都是按照相同的顺序来获得锁,但事实上锁的顺序取决于传递给transferMoney的参数顺序,而这些参数顺序又取决于外部输入。如果两个线程同时调用transferMoney,其中一个线程从X向Y转账,另一个线程从Y向X转账,那么就会发生死锁。
A可能获得myAccount的锁并等待yourAccount锁,而B持有yourAccount的锁并等待myAccount的锁。
解决方法:
这种死锁可以使用锁顺序死锁中的方法来检查——查看是否存在嵌套的锁获取操作。由于我们无法控制参数的顺序,因此要解决这个问题,必须定义锁的顺序,并在整个应用程序中都按照这个顺序来获取锁。①在制定锁的顺序时,可以使用System.identityHashCode()方法,该方法将返回有Object.hashCode返回的值。
private static final Object tieLock = new Object();
public void transferMoney(final Account fromAccount, final Account toAccount, final DollarAmount amount) {
class Helper {
public void transfer() {
if (fromAccount.getBalance().compareTo(amount) < 0) {
throw new RuntimeException();
} else {
fromAccount.debit(amount);
toAccount.credit(amount);
}
}
}
// 通过唯一hashcode来统一锁的顺序, 如果account具有唯一键, 可以采用该键来作为顺序.
int fromHash = System.identityHashCode(fromAccount);
int toHash = System.identityHashCode(toAccount);
if (fromHash < toHash) {
synchronized (fromAccount) {
synchronized (toAccount) {
new Helper().transfer();
}
}
} else if (fromHash > toHash) {
synchronized (toAccount) {
synchronized (fromAccount) {
new Helper().transfer();
}
}
} else {
synchronized (tieLock) { // 针对fromAccount和toAccount具有相同的hashcode
synchronized (fromAccount) {
synchronized (toAccount) {
new Helper().transfer();
}
}
}
}
}
②在极少数情况下,两个对象可能拥有相同的散列值,此时必须通过某种任意的方法来决定锁的顺序,而这可能又会引入死锁。为了避免这种情况,可以使用“加时赛”锁。在获得两个Account之前,首先获得这个“加时赛”锁,从而保证每次只有一个线程以未知的顺序获得这两个锁,从而消除了死锁发生的可能性(只要一致地使用这种机制)。如果经常会出现散列冲突的情况,那么这种技术可能会成为并发性的一个瓶颈(这类似于在整个程序中只有一个锁的情况),但由于System.identityHashCode中出现散列冲突的频率非常低,因此这项技术以最小的代价,换来了最大的安全性。
如果在Account中包含一个唯一的,不可变的并且具备可比性的键值,例如账号,那么要制定锁的顺序就更加容易了,通过键值对对象进行排序,因而不需要使用“加时赛”锁。
- 协作对象间死锁:这种类型强调的是不同对象或组件之间的协作过程中因锁的顺序或资源管理不当而导致的死锁。虽然它也涉及到锁的顺序,但更多地是从系统架构设计或组件间交互的角度来考虑的。
public class Taxi {
private final Dispatcher dispatcher;
private Point location, destination;
public Taxi(Dispatcher dispatcher) {
this.dispatcher = dispatcher;
}
public synchronized Point getLocation() {
return location;
}
public synchronized void setLocation(Point location){//加锁
this.location = location;
if(location.equals(destination)){
dispatcher.notifyAvaliable(this);//加锁
}
}
}
public class Dispatcher {
private final Set<Taxi> taxis;
private final Set<Taxi> avaliableTaxis;
public Dispatcher() {
taxis = new HashSet<Taxi>();
avaliableTaxis = new HashSet<Taxi>();
}
public synchronized void notifyAvaliable(Taxi taxi) {//加锁
avaliableTaxis.add(taxi);//加锁
}
public synchronized Image getImage() {
Image image = new Image();
for (Taxi t : taxis) {
image.drawMarker(t.getLocation());
}
return image;
}
}
死锁原因:
尽管没有任何方法会显式的获取两个锁,但setLocation和getImage等方法的调用者都会获得两个锁。因为setLocation和notifyAvailable都是同步方法,因此调用setLocation的线程将首先获得Taxi的锁,然后获取Dispatcher的锁,同样调用getImage的线程将首先获取Dispatcher的锁,然后再获取每一个Taxi的锁,两个线程按照不同的顺序来获取两个锁,这时就有可能产生死锁。
解决方案:
开放调用(如果在调用某个方法时不需要持有锁,那么这种调用被称为开放调用),使同步代码块仅被用于保护那些涉及共享状态的操作
public class Taxi {
private final Dispatcher dispatcher;
private Point location, destination;
public Taxi(Dispatcher dispatcher) {
this.dispatcher = dispatcher;
}
public synchronized Point getLocation() {
return location;
}
public synchronized void setLocation(Point location) {
boolean reachedLocation;
synchronized (this) {
this.location = location;
reachedLocation = location.equals(destination);
}
if (reachedLocation) {
dispatcher.notifyAvaliable(this);
}
}
}
public class Dispatcher {
private final Set<Taxi> taxis;
private final Set<Taxi> avaliableTaxis;
public Dispatcher() {
taxis = new HashSet<Taxi>();
avaliableTaxis = new HashSet<Taxi>();
}
public synchronized void notifyAvaliable(Taxi taxi) {
avaliableTaxis.add(taxi);
}
public Image getImage(){
Set<Taxi> copy;
synchronized (this){
copy = new HashSet<Taxi>();
}
Image image = new Image();
for(Taxi t: copy){
image.drawMarker(t.getLocation());
}
return image;
}
}
- 资源死锁:这是一个更宽泛的概念,它不仅仅局限于锁的顺序,而是指任何形式的资源(如文件、内存、数据库连接等)被多个进程或线程以循环等待的方式持有和请求,从而导致死锁。
正如当多个线程相互持有彼此正在等待的锁而又不释放自己已持有的锁时会发生死锁,当 它们在相同的资源集合上等待时,也会发生死锁。 假设有两个资源池,例如两个不同数据库的连接池。资源池通常采用信号量来实现(请参 见 5.5.3节)当资源池为空时的阻塞行为。如果一个任务需要连接两个数据库,并且在请求这 两个资源时不会始终遵循相同的顺序,那么线程A可能持有与数据库D的连接,并等待与数 据库 Dz的连接,而线程B则持有与D的连接并等待与D的连接。(资源池越大,出现这种情 况的可能性就越小。如果每个资源池都有N个连接,那么在发生死锁时不仅需要N个循环等待 的线程,而且还需要大量不恰当的执行时序。) 另一种基于资源的死锁形式就是线程饥饿死锁(Thread-Starvation Deadlock)。 8.1.1节给出 了这种危害的一个示例:一个任务提交另一个任务,并等待被提交任务在单线程的Executor 中 执行完成。这种情况下,第一个任务将永远等待下去,并使得另一个任务以及在这个Executor 中执行的所有其他任务都停止执行。如果某些任务需要等待其他任务的结果,那么这些任务往
总结: 尽管这些类型在本质上是相互关联的,但将它们区分开来有助于我们更深入地理解死锁发生的不同场景和原因,并据此制定更有效的预防和解决策略。例如,对于锁顺序死锁,我们可以通过固定锁的顺序来避免;而对于动态锁顺序死锁,我们可能需要引入更复杂的锁管理策略或资源分配算法来应对。
# 饥饿
所谓“饥饿”指的是线程因无法访问所需资源而无法执行下去的情况。引发饥饿最常见的最常见资源就是CPU始终时间周期。如果线程优先级“不均”,在 CPU 繁忙的情况下,优先级低的线程得到执行的机会很小,就可能发生线程“饥饿”;持有锁的线程,如果执行的时间过长,也可能导致“饥饿”问题。 解决“饥饿”问题的方案很简单,有三种方案:
一是保证资源充足,二是公平地分配资源,三就是避免持有锁的线程长时间执行。
这三个方案中,方案一和方案三的适用场景比较有限,因为很多场景下,资源的稀缺性是没办法解决的,持有锁的线程执行的时间也很难缩短。倒是方案二的适用场景相对来说更多一些。那如何公平地分配资源呢?在并发编程里,主要是使用公平锁。也就是一种先来后到,线程的等待是有顺序的,排在等待队列前面的线程会优先获得资源。
# 活锁
活锁(Livelock) 是另一种形式的活跃性问题:它不会阻塞线程,但也不能继续执行,因为线程将不断重复执行相同的操作,而且总是失败。可以类比现实世界里的例子,路人甲从左手边出门,路人乙从右手边进门,两人为了不相撞而互相谦让,路人甲让路走右手边,路人乙也让路走左手边,结果是两人又相撞了。这种情况,基本上谦让几次就解决了,因为人会交流。可是如果这种情况发生在程序中,就有可能会一直没完没了地“谦让”下去,成为没有发生阻塞但依然执行不下去的“活锁”。解决“活锁”的方案很简单,谦让时,尝试等待一个随机的时间就可以了。例如上面的那个例子,路人甲走左手边发现前面有人,并不是立刻换到右手边,而是等待一个随机的时间后,再换到右手边;同样,路人乙也不是立刻切换路线,也是等待一个随机的时间再切换。由于路人甲和路人乙等待的时间是随机的,所以同时相撞后再次相撞的概率就很低了。“等待一个随机时间”的方案虽然很简单,却非常有效,Raft 这样知名的分布式一致性算法中也用到了它。
活锁通常发生在处理事务消息的应用程序中:如果不能成功地处理某个消息,那么消息处理机制将会回滚整个事务,并将它重新放到队列的开头。如果消息处理器在处理某种特定类型的消息时存在错误并导致它失败,那么每当这个消息从队列中取出并传递到存在错误的处理器时,都会发生事务回滚。由于这条消息被放到队列开头,因此消息处理器将被反复调用,并返回相同的结果(有时也被称为毒药消息,Poison Message)。虽然处理消息的线程没阻塞,但也无法继续执行。这种形式的活锁通常是由过度的错误恢复代码造成的,因为它错误地将不可修复的错误作为可修复的错误。
# 死锁预防/避免/检测/消除
# 银行家算法
银行家算法(Banker's Algorithm)是一种避免死锁的资源分配策略,主要应用于操作系统中,用于动态分配资源,以确保系统始终处于安全状态。以下通过一个例子来详细解释银行家算法的工作原理:
class BankersAlgorithm:
def __init__(self, num_processes, num_resources, available, max_demand, allocation):
self.num_processes = num_processes
self.num_resources = num_resources
self.available = available[:] # Copy the list
self.max_demand = [row[:] for row in max_demand] # Copy the matrix
self.allocation = [row[:] for row in allocation] # Copy the matrix
self.need = [[self.max_demand[i][j] - self.allocation[i][j] for j in range(num_resources)] for i in range(num_processes)]
def request_resources(self, process_id, request):
# Step 1: Check if the request exceeds the maximum claim
if any(request[j] > self.need[process_id][j] for j in range(self.num_resources)):
return False, "Request exceeds maximum claim"
# Step 2: Check if there are enough resources available
if all(request[j] <= self.available[j] for j in range(self.num_resources)):
# Try to allocate resources
self.available = [self.available[j] - request[j] for j in range(self.num_resources)]
self.allocation[process_id] = [self.allocation[process_id][j] + request[j] for j in range(self.num_resources)]
self.need[process_id] = [self.need[process_id][j] - request[j] for j in range(self.num_resources)]
# Step 3: Check for safety
if self.is_safe():
return True, "Resources allocated successfully"
else:
# If not safe, rollback the allocation
self.available = [self.available[j] + request[j] for j in range(self.num_resources)]
self.allocation[process_id] = [self.allocation[process_id][j] - request[j] for j in range(self.num_resources)]
self.need[process_id] = [self.need[process_id][j] + request[j] for j in range(self.num_resources)]
return False, "Allocation would lead to unsafe state"
else:
return False, "Insufficient resources available"
def is_safe(self):
# Work and Finish vectors
work = self.available[:]
finish = [False] * self.num_processes
# Try to find a safe sequence
while True:
found = False
for i in range(self.num_processes):
if not finish[i] and all(self.need[i][j] <= work[j] for j in range(self.num_resources)):
# Process i can finish
for j in range(self.num_resources):
work[j] += self.allocation[i][j]
finish[i] = True
found = True
if not found:
# No more processes can finish
break
# Check if all processes have finished
return all(finish)
# Example usage
num_processes = 5
num_resources = 3
available = [3, 3, 2]
max_demand = [
[7, 5, 3],
[3, 2, 2],
[9, 0, 2],
[2, 2, 2],
[4, 3, 3]
]
allocation = [
[0, 1, 0],
[2, 0, 0],
[3, 0, 2],
[2, 1, 1],
[0, 0, 2]
]
banker = BankersAlgorithm(num_processes, num_resources, available, max_demand, allocation)
# Testing a resource request
request = [1, 0, 2] # Request from process 0
success, message = banker.request_resources(0, request)
print(f"Request Result: {success}, {message}")
系统设定 假设系统中有以下资源类型和进程:
- 资源类型:A, B, C 三种资源。
- 进程:P0, P1, P2, P3, P4 五个进程。
数据结构 系统使用以下数据结构来管理资源和进程:
- Available:一个数组,表示当前系统中每种资源的可用数量。
- Max:一个矩阵,表示每个进程对每种资源的最大需求。
- Allocation:一个矩阵,表示当前已分配给每个进程的资源数量。
- Need:一个矩阵,表示每个进程还需要多少资源才能完成其任务。Need[i, j] = Max[i, j] - Allocation[i, j]。
初始状态 假设初始状态如下:
Available = [3, 3, 2]
Max = [
[7, 5, 3],
[3, 2, 2],
[9, 0, 2],
[2, 2, 2],
[4, 3, 3]
]
Allocation = [
[0, 1, 0],
[2, 0, 0],
[3, 0, 2],
[2, 1, 1],
[0, 0, 2]
]
根据Allocation和Max,我们可以计算出Need矩阵。
进程请求资源 假设进程P0现在请求资源[0, 2, 0],即需要额外的0个A资源,2个B资源和0个C资源。
银行家算法步骤
- 检查请求是否超过最大需求:
Request[0] = [0, 2, 0] Need[0] = [7, 5, 3] - [0, 1, 0] = [7, 4, 3] 因为 Request[0] <= Need[0],所以请求没有超过P0的最大需求。
- 检查系统是否有足够的资源:
Request[0] = [0, 2, 0] Available = [3, 3, 2] 因为 [0, 2, 0] <= [3, 3, 2],所以系统有足够的资源满足P0的请求。
- 试探性分配资源:
更新Available, Allocation, Need矩阵。 Available = [3, 3, 2] - [0, 2, 0] = [3, 1, 2] Allocation[0] = [0, 1, 0] + [0, 2, 0] = [0, 3, 0] Need[0] = [7, 4, 3] - [0, 3, 0] = [7, 1, 3]
- 执行安全性检查:
尝试找到一个安全序列,即检查是否存在一个进程序列,使得对于每个进程Pi,它在未来需要的资源量不超过系统当前剩余资源量与所有在Pi之前的进程Pj当前占有资源量之和。 如果存在这样的序列,则分配是安全的;否则,需要撤销这次试探性分配,恢复系统到分配前的状态,并让请求进程等待。 在这个例子中,由于我们没有具体执行安全性检查的所有步骤,所以我们假设系统找到了一个安全序列,并允许这次资源分配。
安全性检查算法详细步骤
在进行了试探性资源分配后,我们需要执行安全性检查来确保系统仍然处于安全状态。以下是安全性检查的详细步骤:
- 初始化工作向量和完成向量:
Work:初始化为Available向量,即系统中每种资源的可用数量。 Finish:一个布尔数组,用于跟踪每个进程是否已经被考虑在安全序列中。初始时,所有进程的Finish值都设为false。
- 查找可安全完成的进程:
遍历所有进程,查找一个其Need资源量不超过当前Work向量的进程Pi(即Need[i] <= Work)。 如果找到这样的进程,则标记该进程为已完成(Finish[i] = true),并更新Work向量,加上该进程当前已分配的资源量(Work = Work + Allocation[i])。这是因为如果进程Pi能够在未来某个时刻完成(即它需要的资源量现在就可以被满足),那么它所占用的资源将在它完成后被释放回系统,这些资源可以被其他进程使用。
- 重复步骤2:
继续查找下一个可安全完成的进程,并更新Work向量和Finish向量,直到所有进程的Finish值都为true(即所有进程都能在安全序列中完成),或者没有更多的进程可以被标记为已完成(即系统处于不安全状态)。
- 判断系统是否安全:
如果所有进程的Finish值都为true,则系统处于安全状态,试探性分配成功,资源可以被分配给请求的进程。 如果存在至少一个进程的Finish值为false,则系统处于不安全状态,试探性分配失败,需要撤销这次资源分配,恢复系统到分配前的状态,并让请求进程等待。
# 锁分类
https://tech.meituan.com/2018/11/15/java-lock.html
| 锁/类型 | 公平/非公平锁 | 可重入/不可重入锁 | 共享/独享锁 | 乐观/悲观锁 |
|---|---|---|---|---|
| synchronized | 非公平锁 | 可重入锁 | 独享锁 | 悲观锁 |
| ReentrantLock | 都支持 | 可重入锁 | 独享锁 | 悲观锁 |
| ReentrantReadWriteLock | 都支持 | 可重入锁 | 读锁-共享,写锁-独享 | 悲观锁 |
https://cloud.tencent.com/developer/article/1082708
在Java中,不同类型的锁通过不同的实现方式和用途来区分。
# 按锁的特性分类
# 公平锁(Fair Lock)
多个线程按照申请锁的顺序获得锁。这种锁保证了线程访问的公平性,但可能会降低性能,因为需要维护一个线程等待队列
Java中的ReentrantLock类支持公平锁模式。通过构造函数ReentrantLock(boolean fair),并传入true作为参数,可以创建一个公平锁。
import java.util.concurrent.locks.ReentrantLock;
public class FairLockExample {
private final ReentrantLock lock = new ReentrantLock(true); // 公平锁
public void criticalSection() {
lock.lock();
try {
// 临界区代码
System.out.println("Locked in critical section with fair lock");
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
FairLockExample example = new FairLockExample();
// 在这里可以创建多个线程来调用criticalSection方法,以观察公平锁的效果
}
}
# 非公平锁(Non-fair Lock)
多个线程获得锁的顺序不按照申请顺序。这种锁的优点在于吞吐量通常比公平锁大,因为线程在尝试获取锁时不需要进行额外的等待
ReentrantLock也支持非公平锁模式,这是其默认行为。通过构造函数ReentrantLock()或传入false作为参数到ReentrantLock(boolean fair),可以创建非公平锁。
import java.util.concurrent.locks.ReentrantLock;
public class NonFairLockExample {
private final ReentrantLock lock = new ReentrantLock(); // 默认非公平锁
public void criticalSection() {
lock.lock();
try {
// 临界区代码
System.out.println("Locked in critical section with non-fair lock");
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
NonFairLockExample example = new NonFairLockExample();
// 在这里可以创建多个线程来调用criticalSection方法,以观察非公平锁的效果
}
}
# 可重入锁(Reentrant Lock)
同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁。这种锁避免了死锁的发生(或更准确地说是线程自我阻塞),因为线程可以重复获取自己已经持有的锁,可重入性只是确保了一个线程不会因为多次尝试获取同一个锁而导致死锁。死锁仍然可能发生在多个线程之间,如果它们以不同的顺序获取多个锁,并且每个线程都持有对方需要的锁的一部分。
因此,要完全避免死锁,你需要采取更全面的并发控制策略,比如确保所有线程都以相同的顺序获取锁,使用锁超时,或者设计无锁的数据结构等。但在单个线程多次获取同一个锁的场景中,可重入锁的可重入性确实是一个有用的特性,它使得这种场景下的并发控制变得更加简单和安全。
ReentrantLock本身就是一种可重入锁。可重入意味着同一个线程可以多次获得同一个锁。
import java.util.concurrent.locks.ReentrantLock;
public class ReentrantLockExample {
private final ReentrantLock lock = new ReentrantLock();
public void outerMethod() {
lock.lock();
try {
System.out.println("Entered outer method");
innerMethod();
} finally {
lock.unlock();
}
}
public void innerMethod() {
lock.lock(); // 同一个线程再次获取锁
try {
System.out.println("Entered inner method");
} finally {
lock.unlock(); // 需要释放两次,因为获取了两次
}
}
public static void main(String[] args) {
ReentrantLockExample example = new ReentrantLockExample();
example.outerMethod(); // 这里会成功,因为可重入锁允许同一个线程多次获取
}
}
注意:在上面的ReentrantLockExample中,虽然内层方法也调用了lock.lock(),但在实际使用中,通常不需要在可重入锁的内部方法中再次显式加锁,除非有特定的理由。另外,示例中的innerMethod释放了两次锁,这在实际应用中是不推荐的,因为可能导致其他线程无法获取锁(如果外层锁已被其他线程持有)。
在可重入锁(如ReentrantLock)的上下文中,如果outerMethod已经加锁,那么同一个线程在调用innerMethod时再次加锁(假设innerMethod也是被这个锁保护的)实际上是安全的,因为可重入锁允许同一个线程多次获得锁。
然而,在innerMethod中也加锁的原因通常不是为了防止同一个线程重新获取锁(这是可重入锁设计时就考虑到的特性),而是出于以下几种可能的考虑:
代码封装和清晰性:即使innerMethod总是从已经持有锁的outerMethod中被调用,将锁的逻辑包含在innerMethod内部可以使得这个方法的调用更加灵活和独立。如果未来innerMethod需要被其他没有显式锁的上下文调用,那么它内部的锁机制就能确保数据的一致性。
防止未来修改引入的bug:如果未来innerMethod的调用路径发生变化,例如它被另一个没有加锁的线程直接调用,那么内部的锁就能保护数据不被并发访问破坏。
显式表达锁的意图:在innerMethod中明确加锁可以清晰地表达这个方法的并发访问策略,使得代码更易于理解和维护。
安全性考虑:在某些情况下,即使innerMethod总是从outerMethod中被调用,也可能存在其他线程通过反射、动态代理或其他高级技术绕过outerMethod直接调用innerMethod的风险。在这种情况下,innerMethod内部的锁就提供了一层额外的保护。
然而,值得注意的是,如果innerMethod总是且仅在被outerMethod锁保护的上下文中调用,并且没有上述提到的风险,那么在innerMethod中加锁可能是不必要的,这取决于具体的代码设计和并发控制需求。
最后,使用可重入锁时,重要的是要确保锁的释放与获取相匹配,避免死锁和锁泄露等问题。如果innerMethod在抛出异常时没有正确释放锁,那么可能会导致死锁或资源泄露。因此,通常建议使用try-finally语句来确保锁总是被释放。
# 独享锁(Exclusive Lock)
该锁一次只能被一个线程所持有。ReentrantLock和synchronized在默认情况下都是独享锁
ReentrantLock和synchronized在默认情况下都是独享锁。它们保证了在任意时刻,只有一个线程可以访问被保护的资源或代码段。
// 使用synchronized实现独享锁
public class ExclusiveLockExample {
private Object lock = new Object();
public void criticalSection() {
synchronized (lock) {
// 临界区代码
System.out.println("Locked in critical section with synchronized");
}
}
// ...
}
// 使用ReentrantLock实现独享锁(前面已给出示例)
# 共享锁(Shared Lock)
该锁可以被多个线程所持有。读写锁中的读锁就是一个典型的共享锁,它允许多个线程同时读取数据
在Java中,共享锁的一个常见例子是ReentrantReadWriteLock中的读锁。这个锁允许多个线程同时读取数据,但在有线程正在写入时,会阻塞读操作。
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class SharedLockExample {
private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private final java.util.concurrent.locks.Lock readLock = readWriteLock.readLock();
public void readData() {
readLock.lock();
try {
// 读取数据的代码
System.out.println("Reading data with shared lock");
} finally {
readLock.unlock();
}
}
// 假设还有其他写数据的方法使用writeLock
}
# 按锁的设计分类
# 互斥锁(Mutex Lock)
互斥锁是一种基本的锁类型,它保证了在任意时刻,只有一个线程可以访问被保护的资源或代码段。ReentrantLock和synchronized都可以看作是互斥锁的实现
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class ExclusiveLockExample {
private final Lock lock = new ReentrantLock();
public void criticalSection() {
lock.lock();
try {
// 临界区代码
System.out.println("Executing critical section with exclusive lock");
} finally {
lock.unlock();
}
}
}
# 读写锁(Read-Write Lock)
读写锁是一种允许多个线程同时读取数据,但只允许一个线程写入数据的锁。它提高了读操作的并发性,因为读操作不会相互阻塞 Java中的ReentrantReadWriteLock提供了读写锁的实现。它允许多个线程同时读取数据,但只允许一个线程写入数据。
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class ReadWriteLockExample {
private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private final Lock readLock = readWriteLock.readLock();
private final Lock writeLock = readWriteLock.writeLock();
public void readData() {
readLock.lock();
try {
// 读取数据的代码
System.out.println("Reading data with read lock");
} finally {
readLock.unlock();
}
}
public void writeData() {
writeLock.lock();
try {
// 写入数据的代码
System.out.println("Writing data with write lock");
} finally {
writeLock.unlock();
}
}
public static void main(String[] args) {
ReadWriteLockExample example = new ReadWriteLockExample();
// 可以在不同的线程中调用readData()和writeData()来观察读写锁的行为
// 注意:同时有多个线程调用readData()是允许的,但如果有线程正在写入数据(即调用了writeData()),则其他线程必须等待直到写入完成。
}
在这个例子中,ReadWriteLock被用来控制对某个共享资源的访问。通过readLock和writeLock,我们可以分别控制读操作和写操作的并发性。多个线程可以同时获得readLock(即同时读取数据),但每次只有一个线程可以获得writeLock(即写入数据)。这种机制优化了并发性能,因为读取操作通常不会修改数据,因此可以安全地并行执行。
需要注意的是,虽然读写锁提高了并发性能,但在某些情况下可能会引入复杂性,因为你需要明确地管理锁的获取和释放。此外,如果写操作非常频繁,或者读写操作之间的数据依赖性很强,那么读写锁可能并不是最佳选择。在这种情况下,使用简单的互斥锁(如synchronized或ReentrantLock的独享锁模式)可能更简单、更直接。
# 分段锁(Segment Lock)
分段锁并不是具体的一种锁,而是一种锁的设计思路。它通过细化锁的粒度来减少锁的竞争,提高并发性能。例如,ConcurrentHashMap就采用了分段锁的设计
// 注意:这只是一个概念上的示例,并非真正的分段锁实现
public class SegmentedLockExample {
private final Object[] segments = new Object[4]; // 假设有4个分段
public void accessSegment(int index, Runnable task) {
synchronized (segments[index % segments.length]) {
task.run();
}
}
public static void main(String[] args) {
SegmentedLockExample example = new SegmentedLockExample();
// 模拟多个线程访问不同的分段
for (int i = 0; i < 10; i++) {
new Thread(() -> example.accessSegment(i, () -> {
// 执行分段内的操作
System.out.println("Accessing segment " + i % 4 + " with simulated segmented lock");
})).start();
}
}
}
# 按并发控制策略分类
# 乐观锁(Optimistic Locking)
乐观锁不是指具体的锁类型,而是一种并发控制策略。它假设在并发操作期间,数据被其他线程修改的可能性较小,因此不直接加锁,而是通过其他方式(如版本号或时间戳)来检测数据是否被修改过
public class OptimisticLockExample {
private int value = 0;
private int version = 0;
public synchronized void updateValue(int newValue, int expectedVersion) {
if (expectedVersion == version) {
value = newValue;
version++;
System.out.println("Value updated successfully with optimistic lock");
} else {
System.out.println("Update failed due to version mismatch");
}
}
// 假设有方法来获取当前值和版本号
}
# 悲观锁(Pessimistic Locking)
与乐观锁相反,悲观锁认为在并发操作期间,数据被其他线程修改的可能性较大,因此在访问数据时总是先加锁
public class PessimisticLockExample {
public synchronized void criticalSection() {
// 临界区代码
System.out.println("Executing critical section with pessimistic lock");
}
}
# 自旋锁(Spin Lock)CAS-compare and swap
自旋锁是一种尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁的锁机制。它减少了线程上下文切换的消耗,但会消耗CPU资源;
在Java中实现自旋锁时,虽然不一定直接使用名为“原子锁”的类(因为Java标准库中并没有直接提供这样的类),但通常会依赖原子操作来确保锁状态的正确性和线程安全。这是因为自旋锁需要快速且安全地检查并修改锁的状态,而原子操作正是提供这种保证的手段。
CAS-compare and swap 自旋锁(java AtomicInteger 为例)
还是以 i++ 为例
public class AtomicIntegerTest {
private static int count = 0;
public static void increment() {
count++;
}
public static void main(String[] args) {
IntStream.range(0, 100)
.forEach(i->
new Thread(()->IntStream.range(0, 1000)
.forEach(j->increment())).start());
// 这里使用2或者1看自己的机器
// 我这里是用run跑大于2才会退出循环
// 但是用debug跑大于1就会退出循环了
while (Thread.activeCount() > 1) {
// 让出CPU
Thread.yield();
}
System.out.println(count);
}
}
这里起了100个线程,每个线程对count自增1000次,你会发现每次运行的结果都不一样,但它们有个共同点就是都不到100000次,所以直接使用int是有问题的。
public class AtomicIntegerTest {
private static AtomicInteger count = new AtomicInteger(0);
public static void increment() {
count.incrementAndGet();
}
public static void main(String[] args) {
IntStream.range(0, 100)
.forEach(i->
new Thread(()->IntStream.range(0, 1000)
.forEach(j->increment())).start());
// 这里使用2或者1看自己的机器
// 我这里是用run跑大于2才会退出循环
// 但是用debug跑大于1就会退出循环了
while (Thread.activeCount() > 1) {
// 让出CPU
Thread.yield();
}
System.out.println(count);
}
}
这里总是会打印出100000。
todo 整理:https://xie.infoq.cn/article/79fd68d510b0a52324d6ca7e1 + https://xie.infoq.cn/article/5b2731c61bd4e7966c898314d + https://my.oschina.net/u/4339514/blog/4181506/print
https://blog.csdn.net/fengyuyeguirenenen/article/details/123646048
https://juejin.cn/post/7075293889271169060#heading-10
多核仍然要lock - Java中CAS底层实现原理分析cpu的原语LOCK_IF_MP
自旋锁举例:实现CAS算法的乐观锁
/**
* 题目:实现一个自旋锁
* 自旋锁好处:循环比较获取没有类似wait的阻塞。
*
* 通过CAS操作完成自旋锁,A线程先进来调用myLock方法自己持有锁5秒钟,B随后进来后发现
* 当前有线程持有锁,不是null,所以只能通过自旋等待,直到A释放锁后B随后抢到。
*/
public class SpinLockDemo
{
AtomicReference<Thread> atomicReference = new AtomicReference<>();
public void myLock()
{
Thread thread = Thread.currentThread();
System.out.println(Thread.currentThread().getName()+"\t come in");
while(!atomicReference.compareAndSet(null,thread))
{
}
}
public void myUnLock()
{
Thread thread = Thread.currentThread();
atomicReference.compareAndSet(thread,null);
System.out.println(Thread.currentThread().getName()+"\t myUnLock over");
}
public static void main(String[] args)
{
SpinLockDemo spinLockDemo = new SpinLockDemo();
new Thread(() -> {
spinLockDemo.myLock();
try { TimeUnit.SECONDS.sleep( 5 ); } catch (InterruptedException e) { e.printStackTrace(); }
spinLockDemo.myUnLock();
},"A").start();
//暂停一会儿线程,保证A线程先于B线程启动并完成
try { TimeUnit.SECONDS.sleep( 1 ); } catch (InterruptedException e) { e.printStackTrace(); }
new Thread(() -> {
spinLockDemo.myLock();
spinLockDemo.myUnLock();
},"B").start();
}
}
CAS虽然很高效的解决了原子操作问题,但是CAS仍然存在三大问题。
- 循环时间长开销很大。
- 只能保证一个共享变量的原子操作。
- ABA问题。
https://cloud.tencent.com/developer/article/1614763
https://blog.csdn.net/javazejian/article/details/72772470
# 按锁的状态分类-锁升级(状态变化)
在Java中,锁升级的过程并不是直接通过编写代码来显式控制的,而是由JVM在运行时根据同步代码块的竞争情况自动进行的。不过,我们可以通过一个例子来模拟并解释锁升级的概念。
首先,需要注意的是,我们无法直接查看JVM内部的锁状态变化,但可以通过分析代码和了解JVM的锁优化机制来推断锁升级的过程。
以下是一个简单的Java例子,展示了多个线程可能竞争同一个锁的情况:
public class LockUpgradeExample {
private final Object lock = new Object();
public void method() {
synchronized (lock) {
// 模拟一些耗时的操作
try {
Thread.sleep(100);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
// 访问或修改共享资源
System.out.println(Thread.currentThread().getName() + " is accessing the resource.");
}
}
public static void main(String[] args) {
LockUpgradeExample example = new LockUpgradeExample();
// 创建多个线程来模拟竞争
for (int i = 0; i < 10; i++) {
new Thread(() -> {
example.method();
}, "Thread-" + i).start();
}
}
}
在这个例子中,LockUpgradeExample 类有一个被 synchronized 关键字保护的同步代码块,它使用了一个对象锁 lock。在 main 方法中,我们创建了10个线程,它们都会尝试执行 method 方法,并因此竞争同一个锁。
然而,由于JVM的锁升级是自动进行的,并且这个过程对开发者来说是透明的,我们无法直接通过代码来观察锁升级的过程。但我们可以根据JVM的锁优化机制来推断这个过程:
偏向锁阶段:当第一个线程进入同步代码块时,JVM会尝试将锁偏向于这个线程。此时,锁的状态是偏向锁。如果在这个线程持有锁期间没有其他线程尝试进入同步代码块,那么锁将一直保持偏向锁状态。
轻量级锁阶段:如果有其他线程尝试进入同步代码块(即竞争锁),JVM会检查当前锁的状态。如果锁是偏向锁,并且只有一个线程在竞争,JVM可能会尝试将锁升级为轻量级锁。轻量级锁通过CAS操作来尝试获取锁,避免了重量级锁中的线程阻塞和上下文切换。 设计初衷是在没有多线程竞争或竞争较少的情况下,减少重量级锁的使用以提高系统性能。它主要通过CAS操作来实现,适用于锁竞争不激烈、锁持有时间短的场景。在这样的场景下,轻量级锁能够快速响应并减少线程阻塞和上下文切换的开销。在没有竞争或竞争较少的情况下,轻量级锁的性能优于重量级锁,因为它避免了使用操作系统级别的互斥量,减少了线程上下文切换和调度的开销。
重量级锁阶段:如果轻量级锁的竞争变得激烈(即多个线程频繁地尝试获取锁),或者锁的自旋次数超过了JVM的阈值,那么JVM可能会将锁升级为重量级锁。此时,未能获取锁的线程将进入阻塞状态,等待锁的释放。基于操作系统的互斥量(Mutex Lock)或信号量(Semaphore)实现,确保资源的独占性,适用于锁竞争激烈、锁持有时间长的场景。它通过阻塞竞争失败的线程来避免CPU资源的浪费,并在锁释放后唤醒阻塞的线程。在竞争激烈的情况下,轻量级锁中的CAS操作可能会导致大量的自旋等待,占用大量的CPU资源。此时,重量级锁通过阻塞等待的线程来避免CPU资源的浪费,反而表现出更好的性能
需要注意的是,上述的锁升级过程是一个简化的描述,实际情况可能更加复杂。JVM的锁优化机制会根据具体的运行时环境和竞争情况来动态地调整锁的状态。
此外,由于JVM的锁升级和降级过程对开发者是透明的,因此开发者通常不需要关心锁的具体状态,而是应该关注如何合理地设计并发程序,以充分利用JVM的锁优化机制来提高程序的性能。
在Java中,偏向锁、轻量级锁和重量级锁的实现涉及到在对象头(Object Header)中添加或修改一些字段来记录锁的状态和相关信息。这些字段的具体实现和布局可能会随着JVM的实现和版本的不同而有所差异,但基本原理是相似的。
对象头(Object Header) 在HotSpot JVM中,每个Java对象都有一个对象头(Object Header),它包含了对象的运行时数据,如哈希码(HashCode)、GC分代年龄(Generational GC Age)或锁状态(Lock State)等。对象头的大小取决于JVM的实现和是否开启了压缩指针(Compressed Oops)。在32位JVM中,如果开启了压缩指针,对象头通常是8字节;在64位JVM中,如果开启了压缩指针,对象头通常是12字节,否则是16字节。
偏向锁的实现 当启用偏向锁时,JVM会在对象头中设置一个偏向锁标志位(Biased Lock Flag),并记录下持有偏向锁的线程ID(Thread ID)。当线程尝试获取锁时,JVM会检查锁对象的偏向锁标志位和线程ID:
如果锁对象的偏向锁标志位为1,且线程ID与当前线程的ID相同,表示当前线程已经持有该偏向锁,可以直接进入同步代码块。 如果锁对象的偏向锁标志位为1,但线程ID与当前线程的ID不同,表示偏向锁被其他线程持有,需要进行偏向锁的撤销(Revoke)和重新偏向(Rebias)过程,或者升级为轻量级锁。 如果锁对象的偏向锁标志位为0,表示该锁对象当前没有偏向任何线程,需要尝试获取锁。 轻量级锁和重量级锁的实现 轻量级锁和重量级锁的实现也涉及到对象头的修改。在轻量级锁状态下,JVM会在对象头中设置一个轻量级锁标志位,并使用CAS操作来尝试将锁的所有权赋予当前线程。如果CAS操作成功,当前线程就获取了轻量级锁;如果失败,则表示有其他线程在竞争锁,可能需要升级为重量级锁。
在重量级锁状态下,JVM会在对象头中设置一个指向重量级锁(通常是Monitor对象)的指针,并将未能获取锁的线程挂起(Block)在Monitor对象的等待队列中。当持有锁的线程释放锁时,它会唤醒等待队列中的一个或多个线程来竞争锁。
总结 偏向锁、轻量级锁和重量级锁的实现都涉及到对对象头的修改。JVM通过在这些字段中记录锁的状态和相关信息,来实现对同步代码块的并发访问控制。由于这些实现细节是JVM的内部机制,因此开发者通常不需要关心它们的具体实现方式,而是应该关注如何合理地设计并发程序,以充分利用JVM的锁优化机制来提高程序的性能。
重量级锁在Java中的实现涉及到操作系统内核的调用,特别是在Linux等操作系统上。具体来说,重量级锁是通过底层的互斥量(Mutex)来实现的,而互斥量的实现通常依赖于操作系统提供的同步机制。
在Linux操作系统中,互斥量可以通过内核中的Futex(Fast Userspace Mutex)系统调用来实现。Futex是一种用户空间和内核空间混合的同步机制,它允许用户空间的程序直接进行同步操作,而无需频繁地切换到内核空间。然而,在重量级锁的情况下,当线程无法获取锁时,它会被阻塞,并且这种阻塞状态需要由操作系统来管理。
当线程尝试获取一个被其他线程持有的重量级锁时,如果锁无法立即被获取(即锁已被其他线程持有),那么当前线程将执行以下操作:
发送请求到操作系统:线程会向操作系统发送一个请求,表示它想要获取某个锁。在Linux中,这通常是通过系统调用来完成的,尽管具体的系统调用可能因JVM的实现而异。
线程阻塞:操作系统会将该线程从运行状态转换为阻塞状态,并将其放入一个等待队列中。这样,线程就不会占用CPU的时间片,从而避免资源的浪费。
上下文切换:线程状态的转换(从运行状态到阻塞状态)涉及到用户态和内核态之间的切换。这种切换需要消耗一定的处理器时间,因为操作系统需要保存当前线程的状态,并加载等待队列中下一个线程的状态。
锁释放和唤醒:当持有锁的线程释放锁时,操作系统会检查等待队列中是否有线程正在等待该锁。如果有,操作系统会唤醒等待队列中的一个线程,并将其状态从阻塞状态转换为运行状态,以便它能够继续执行。
需要注意的是,虽然Futex系统调用提供了一种高效的同步机制,但在重量级锁的情况下,由于线程的阻塞和唤醒都需要操作系统的介入,因此性能相对较低。这就是为什么在高并发场景下,重量级锁容易造成线程阻塞,导致系统性能下降的原因。
为了减轻重量级锁的性能影响,JVM在实现时会采取一些优化措施,如锁消除、锁粗化、自旋锁升级等。这些措施旨在减少锁的使用频率和持续时间,从而降低线程阻塞和上下文切换的开销。然而,在某些情况下,当需要保证线程的安全性和正确性时,重量级锁仍然是一个可靠的选择。
最后,需要强调的是,具体的实现细节可能会因JVM的版本和操作系统的不同而有所差异。因此,在开发过程中,应该根据实际的运行环境和需求来选择合适的同步机制。
想想多线程竞争资源的本质,想安全的使用竞争资源就需要一种“锁”机制,注意,有人可能会说不是说不用锁也可以么,java的上下文中,“无锁”也是一种“锁”,java锁的本质就是在对象头的标志位更改;
然后再抽象的说,多线程竞争资源做到安全获取锁,本质就是通过锁这种机制获取对资源的临时占有,关键问题是在jvm中就完成,还是要下到内核中去完成,在jvm中完成就是相对轻量级的锁,如果需要操作系统介入,交给内核去处理就是相对重量级的锁,由于jvm用户态的线程跟内核态的线程是有一一对应关系的,所以再换句话说,线程的切换是在用户态就完成,还是要到内核态去切换
synchronized锁升级和jol https://www.cnblogs.com/katsu2017/p/12610002.html
synchronized锁升级优化 https://zhuanlan.zhihu.com/p/92808298
https://zhuanlan.zhihu.com/p/61892830 jvm用户态的线程和内核的线程的对应关系;
JDK1.2之前,绿色线程——用户线程。JDK1.2——基于操作系统原生线程模型来实现。Sun JDK,它的Windows版本和Linux版本都使用一对一的线程模型实现,一条Java线程就映射到一条轻量级进程之中。 Solaris同时支持一对一和多对多。
重量级是指需要内核态的参与(操作系统、内核、系统总线、南北桥);
JDK 1.6之前,synchronized 还是一个重量级锁,是一个效率比较低下的锁。但是在JDK 1.6后,JVM为了提高锁的获取与释放效率对synchronized 进行了优化,引入了偏向锁和轻量级锁 ,从此以后锁的状态就有了四种:无锁、偏向锁、轻量级锁、重量级锁。并且四种状态会随着竞争的情况逐渐升级,而且是不可逆的过程,即不可降级,这四种锁的级别由低到高依次是:无锁、偏向锁,轻量级锁,重量级锁。
无锁态
偏向锁
自旋锁(说白了就是死循环等待,一般是依赖于CAS实现,CAS是通过cpu原语LOCK_IF_MP锁定整个消息总线的方式保证原子性,所以可见整个过程没有真正的锁,是通过CAS底层原子性来实现的“锁机制”) 消耗内存 等待时间长; 等待线程多;
特别的对于CAS实现来说,如果大量写不适合;
升级到重量级
Synchronized 使用的是用户态的CAS 而futex的 CAS是内核态
Mutual exclusion (mutex) algorithms are used to prevent processes simultaneously using a common resource. A fast user-space mutex (futex) is a tool that allows a user-space thread to claim a mutex without requiring a context switch to kernel space, provided the mutex is not already held by another thread.
例子:blockingqueue https://www.cnblogs.com/WangHaiMing/p/8798709.html
# linux内核 锁 - C/C++
# 互斥锁(Mutex)
互斥锁是一种基本的锁机制,用于保证同一时间只有一个线程可以访问共享资源。在Linux中,可以使用pthread_mutex_t类型和相关函数来实现互斥锁。
示例:
#include <pthread.h>
#include <stdio.h>
pthread_mutex_t lock;
void* func(void* arg) {
pthread_mutex_lock(&lock);
// 访问共享资源
printf("Thread %ld is running\n", (long)arg);
pthread_mutex_unlock(&lock);
return NULL;
}
int main() {
pthread_t thread1, thread2;
pthread_mutex_init(&lock, NULL);
pthread_create(&thread1, NULL, func, (void*)1);
pthread_create(&thread2, NULL, func, (void*)2);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
pthread_mutex_destroy(&lock);
return 0;
}
# 自旋锁(Spinlock)
自旋锁是一种轻量级的锁,当线程尝试获取锁时,如果锁已被其他线程持有,则线程会进入忙等待状态(自旋),而不是睡眠阻塞。自旋锁通常用于锁被持有的时间非常短的情况。
示例(底层驱动代码,通常不在用户态程序中直接使用):
#include <linux/spinlock.h>
spinlock_t my_lock = SPIN_LOCK_UNLOCKED;
void my_function(void) {
spin_lock(&my_lock);
// 访问共享资源
spin_unlock(&my_lock);
}
# 读写锁(Read-Write Lock)
读写锁允许多个线程同时读取共享资源,但只允许一个线程写入共享资源。这种锁适用于读操作远多于写操作的场景。
示例(使用pthread_rwlock_t):
#include <pthread.h>
#include <stdio.h>
pthread_rwlock_t rwlock;
void* reader(void* arg) {
pthread_rwlock_rdlock(&rwlock);
// 读取共享资源
printf("Reader %ld is reading\n", (long)arg);
pthread_rwlock_unlock(&rwlock);
return NULL;
}
void* writer(void* arg) {
pthread_rwlock_wrlock(&rwlock);
// 写入共享资源
printf("Writer %ld is writing\n", (long)arg);
pthread_rwlock_unlock(&rwlock);
return NULL;
}
int main() {
pthread_t readers[10], writers[2];
pthread_rwlock_init(&rwlock, NULL);
// 创建读者和写者线程
// ...
// 等待所有线程完成
// ...
pthread_rwlock_destroy(&rwlock);
return 0;
}
注意:上述读写锁的示例中省略了创建线程的代码,因为完整的示例会比较长。
# 信号量(Semaphore)
信号量是一种更通用的同步机制,它用于控制多个线程或进程对共享资源的访问。信号量的值表示可用资源的数量。
示例:
#include <semaphore.h>
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
sem_t sem;
void* func(void* arg) {
sem_wait(&sem); // P操作,等待信号量
// 访问共享资源
printf("Thread %ld is accessing the shared resource\n", (long)arg);
// 假设这里有一些处理时间
sleep(1); // 模拟处理时间
sem_post(&sem); // V操作,释放信号量
return NULL;
}
int main() {
pthread_t threads[5];
int rc;
long t;
// 初始化信号量,初始值为1,表示只有一个线程可以同时访问共享资源
sem_init(&sem, 0, 1);
// 创建线程
for (t = 0; t < 5; t++) {
printf("In main: creating thread %ld\n", t);
rc = pthread_create(&threads[t], NULL, func, (void *)t);
if (rc) {
printf("ERROR; return code from pthread_create() is %d\n", rc);
exit(-1);
}
}
// 等待所有线程完成
for (t = 0; t < 5; t++) {
pthread_join(threads[t], NULL);
printf("Joined thread %ld\n", t);
}
// 销毁信号量
sem_destroy(&sem);
printf("Exiting main\n");
pthread_exit(NULL);
return 0; // 实际上这行代码不会被执行,因为pthread_exit已经调用了
}
在这个示例中,我们创建了一个信号量sem,其初始值为1,表示同时只允许一个线程访问共享资源。然后,我们创建了5个线程,每个线程都会尝试通过sem_wait()函数等待信号量变为可用,执行一些操作(在这里是打印一条消息并休眠1秒来模拟处理时间),然后通过sem_post()函数释放信号量。
在main函数的最后,我们使用pthread_join()函数等待所有线程完成,然后销毁信号量并退出程序。
请注意,虽然在这个示例中我们使用了pthread_exit(NULL);来退出线程,但在main函数的末尾还包含了一个return 0;语句。然而,由于pthread_exit()已经被调用,main函数中的return 0;实际上不会被执行。在main函数中,通常我们会使用return语句来返回程序的退出状态,但在多线程程序中,通常会在最后一个线程退出后使用exit()函数来结束整个进程。不过,在这个示例中,由于main函数中的线程都已经被pthread_join()等待完成,所以直接使用pthread_exit(NULL);在main函数中也是可行的(尽管这在实际编程中并不常见),或者更常见的做法是省略pthread_exit(NULL);并直接让main函数通过return 0;正常结束。然而,在这个上下文中,由于pthread_exit(NULL);已经被调用,return 0;就不会被执行。为了清晰起见,您可以选择保留或删除pthread_exit(NULL);和return 0;中的任意一个。
# "无锁"/轻量级锁/原子锁
atomic_t 是 Linux 内核中用于实现原子操作的一种数据类型,它通常用于实现无锁编程(lock-free programming)或轻量级的同步机制,但并不直接等同于传统意义上的锁(如互斥锁、自旋锁等)。
然而,可以说 atomic_t 类型的操作在某些锁的实现中可能作为底层机制的一部分被使用,尤其是在那些需要高效且低开销的同步操作的场景中。但是,这种使用通常是隐藏在锁的实现细节中的,对于使用锁的高层代码来说是透明的。
通过 atomic 实现的机制通常适用于轻量级的无锁编程,特别是那些预期只有少量竞争或竞争时间非常短的场景。atomic 操作保证了操作的原子性,即这些操作在执行过程中不会被其他线程的操作打断,从而避免了竞态条件。
atomic 类型的操作通常比传统的锁机制(如互斥锁、读写锁等)具有更低的开销,因为它们不需要在内核中进行上下文切换或等待其他线程释放锁。这使得 atomic 操作在高频次访问且竞争不激烈的场景下非常有效。
然而,当竞争变得激烈时,即多个线程频繁地尝试对同一个 atomic 变量进行操作时,这些操作可能会因为缓存一致性协议(如MESI协议)的开销而变得不那么高效。此时,使用锁机制可能会是更好的选择,因为锁可以通过减少实际执行 atomic 操作的频率来降低这种开销。
此外,atomic 操作通常只支持简单的算术运算和位运算,而不支持更复杂的同步需求,如条件变量或复杂的锁策略。因此,在需要这些更复杂同步机制的场景中,传统的锁机制通常是必需的。
综上所述,atomic 操作是轻量级无锁编程的有力工具,但在选择是否使用它们时,需要根据具体的应用场景和性能需求进行权衡。
如果你想要一个直接使用 atomic_t 类型的例子,那么你可以考虑一个简单的原子计数器,它使用 atomic_inc() 和 atomic_dec() 函数来增加和减少计数器的值,而无需额外的锁机制来保护计数器。但是,请注意,这并不是一个锁的实现,而是一个使用原子操作来避免竞态条件的例子。
下面是一个使用 atomic_t 的简单例子,它实现了一个线程安全的计数器
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <linux/atomic.h> // 注意:这个头文件是Linux内核空间的,用户空间应使用<stdatomic.h>
// 在用户空间,你应该使用 <stdatomic.h> 而不是 <linux/atomic.h>
// 但为了演示目的,这里我们假设我们在内核模块中或者以某种方式包含了内核头文件
// 在用户空间,你应该这样做:
// #include <stdatomic.h>
// atomic_int counter = ATOMIC_INIT(0);
// 假设我们有一个atomic_t类型的变量(在实际用户代码中,应使用atomic_int)
// 注意:由于我们在这里使用了<linux/atomic.h>,我们直接声明一个atomic_t变量
// 在用户空间,你应该使用C11的<stdatomic.h>库中的atomic_int类型
atomic_t counter = ATOMIC_INIT(0);
void* increment_counter(void* arg) {
// 使用atomic_inc函数安全地增加计数器的值
atomic_inc(&counter);
return NULL;
}
int main() {
pthread_t threads[10];
int i;
// 创建多个线程来同时增加计数器的值
for (i = 0; i < 10; i++) {
pthread_create(&threads[i], NULL, increment_counter, NULL);
}
// 等待所有线程完成
for (i = 0; i < 10; i++) {
pthread_join(threads[i], NULL);
}
// 打印计数器的最终值
printf("Final counter value: %d\n", atomic_read(&counter));
return 0;
}
// 注意:上面的代码在用户空间中运行时需要修改,因为<linux/atomic.h>是内核头文件
// 用户空间应使用<stdatomic.h>,并且atomic_t应替换为atomic_int等类型
重要提示:上面的代码示例中包含了内核头文件 <linux/atomic.h>,这通常不是用户空间程序应该做的。在用户空间程序中,你应该使用 C11 标准中引入的 <stdatomic.h> 头文件,它提供了原子类型的支持和操作函数。我已经在注释中指出了这一点,并提供了用户空间程序应该如何做的建议。
atomic VS volatile
atomic 类型的原子操作在底层确实涉及到对内存的直接操作,但它们并不完全等同于 volatile 关键字的行为。
atomic 类型的原子操作 atomic 类型的原子操作(如 Go 语言的 sync/atomic 包中的函数)提供了一组保证操作原子性的函数,用于在多线程或多 goroutine 环境中安全地访问和修改共享变量。这些操作是通过底层硬件指令(如 CAS,即 Compare-And-Swap)来实现的,以确保操作的不可分割性。
原子操作的关键特性在于它们能够保证在执行过程中不会被其他线程或 goroutine 打断,从而避免了竞态条件(race condition)的发生。在 Go 语言中,sync/atomic 包提供了如 AddInt32、CompareAndSwapInt32 等函数,这些函数通过 CPU 提供的原子指令来确保操作的原子性。
volatile 关键字 volatile 关键字是另一种在并发编程中常用的技术,但它与原子操作在功能和目的上有所不同。volatile 关键字的主要作用是确保变量的可见性(visibility)和有序性(ordering),但它并不保证操作的原子性。
可见性:volatile 关键字会阻止编译器对变量访问进行优化,确保每次访问都是直接从内存中读取或写入,从而保证了变量对多线程的可见性。 有序性:volatile 关键字还能防止编译器对代码进行重排序,确保代码的执行顺序与编写顺序一致。 然而,由于 volatile 不保证操作的原子性,因此它通常用于那些本身已经是原子操作的数据类型(如 Java 中的 boolean 变量),或者作为其他同步机制(如锁)的辅助手段。
总结 atomic 类型的原子操作通过底层硬件指令确保操作的原子性,适用于需要保证操作不可分割性的场景。 volatile 关键字主要用于确保变量的可见性和有序性,但不保证操作的原子性。 在实际编程中,通常会根据具体需求选择合适的同步机制,以确保并发程序的正确性和高效性。 需要注意的是,虽然 volatile 在某些编程环境中(如 Java)有特定的用途,但在 Go 语言中并没有直接对应的 volatile 关键字。Go 语言通过 sync/atomic 包等机制来提供类似的功能
https://zhuanlan.zhihu.com/p/345530854 https://www.geeksforgeeks.org/mutex-lock-for-linux-thread-synchronization/
# futex
futex不是个完整的锁,他是“支持实现userspace的锁的building block“。也就是说,如果你想实现一个mutex,但不想把整个mutex都弄到内核里面去,可以通过futex来实现。但futex本身主要就是俩系统调用futex_wait和futex_wake.
https://www.zhihu.com/question/393124801/answer/1210081499
在Linux中,有多种锁机制用于实现并发控制和同步,以保护共享资源并防止数据不一致。以下是一些主要的Linux锁种类: futex(Fast Userspace Mutex)实际上并不是传统意义上的锁,而是一种用于在用户空间和内核空间之间实现高效同步的机制。尽管它的名字中包含“Mutex”(互斥锁),但它更像是一个提供底层同步能力的工具,而不是一个具体的锁实现。
与前面提到的锁(如互斥锁、自旋锁等)相比,futex在以下几个方面有所不同:
作用范围:
互斥锁(Mutex)和自旋锁(Spinlock)等传统锁主要是用于在内核空间或用户空间内部保护共享资源,防止多个线程或进程同时访问。 futex则跨越了用户空间和内核空间的界限,提供了一种在用户空间和内核空间之间进行高效同步的方法。 实现方式:
互斥锁和自旋锁通常通过原子操作、自旋等待或内核调用来实现同步。 futex通过允许用户空间代码直接操作特定的同步变量(futex字),并在必要时通过系统调用来请求内核介入,从而实现等待-唤醒机制。这种方式减少了不必要的系统调用和上下文切换,提高了同步效率。 应用场景:
互斥锁和自旋锁适用于各种需要同步保护的场景,如多线程编程中的共享资源访问。 futex则特别适用于那些需要在用户空间和内核空间之间共享资源并进行同步的场景,如pthread库中的条件变量实现就依赖于futex。 灵活性:
futex提供了比传统锁更丰富的同步原语,如重排队(requeue)和优先级继承(PI)等,这使得futex能够更灵活地应对各种复杂的同步需求。 因此,可以说futex是一种提供底层同步能力的工具,而互斥锁、自旋锁等传统锁则是基于这种能力实现的特定类型的锁。在实际应用中,开发者可以根据具体需求选择合适的同步机制来实现线程或进程间的同步。
需要注意的是,虽然futex提供了强大的同步能力,但其使用也需要注意避免死锁、活锁和优先级反转等同步问题。此外,由于futex涉及到系统调用和内核态的切换,因此在高并发场景下使用时也需要注意其对系统性能的影响。
以下是关于futex的一些例子,这些例子展示了futex在不同场景下的应用:
- 基本的等待-唤醒机制 假设有两个线程,线程A和线程B,它们共享一个futex变量futex_var。线程A想要修改某个共享资源,而线程B在修改完成前需要等待。
线程A在修改共享资源前,会检查futex_var的值,如果发现需要线程B等待,则修改futex_var的值,并调用futex_wake来唤醒线程B(尽管在这个例子中,可能线程B还没有开始等待)。 线程B在尝试访问共享资源前,会检查futex_var的值,如果发现需要等待,则调用futex_wait将自己放入等待队列,并释放CPU。当线程A完成修改并调用futex_wake时,线程B会被唤醒并继续执行。 2. 条件变量的实现 在pthread库中,条件变量(pthread_cond_t)的实现通常依赖于futex。条件变量用于线程间的同步,当某个条件不满足时,线程会阻塞等待。
当线程调用pthread_cond_wait时,它实际上会调用futex_wait,将线程放入等待队列,并释放CPU。 当另一个线程改变了条件,并调用pthread_cond_signal或pthread_cond_broadcast时,它会调用futex_wake来唤醒一个或所有等待的线程。 3. 优先级继承(PI) 虽然这不是futex的直接用法,但futex支持优先级继承(PI)功能,这有助于解决优先级反转问题。
当一个低优先级的线程持有一个高优先级线程需要的锁时,如果高优先级线程因为等待锁而被阻塞,那么持有锁的线程(低优先级线程)的优先级可能会被临时提升到与高优先级线程相同。 在futex的PI实现中,这通常通过额外的系统调用来完成,如futex_lock_pi和futex_unlock_pi,它们允许内核跟踪锁的持有者和等待者,并在必要时调整优先级。 注意 由于futex是Linux内核中的一个复杂机制,直接操作它通常是通过高级库(如pthread)或特定的系统调用接口来完成的。在编写应用程序时,开发者通常不需要直接与futex打交道,而是使用这些高级接口来实现线程同步。
此外,由于futex的使用涉及到内核态和用户态之间的切换,以及可能的优先级调整等复杂操作,因此在使用时需要格外小心,以避免引入死锁、活锁或其他同步问题。
# 自定义原子锁(原子操作+内存屏障)及性能测试
# 通过原子操作自定义原子锁:
在实现锁时,特别是使用原子操作实现的锁(如自旋锁),**必须考虑指令重排的影响。**原因如下:
内存可见性:原子操作虽然保证了操作的原子性和完整性,但如果不加控制地允许指令重排,可能会导致其他线程无法及时看到原子操作的结果,从而影响程序的正确性。
锁的正确性:锁的实现依赖于一系列有序的操作,如果这些操作被无序地重排,可能会导致锁无法正确工作。例如,在自旋锁的实现中,如果检查锁状态和更新锁状态的操作被重排,可能会导致多个线程同时进入临界区。
解决方案 为了避免指令重排对原子操作和锁实现的影响,现代编程语言和处理器提供了多种机制,如内存屏障(memory barriers)和volatile关键字:
内存屏障:内存屏障是一种特殊的指令,用于阻止指令重排。在原子操作或锁实现的关键点插入内存屏障,可以确保指令的执行顺序不被打乱。
volatile关键字:在某些编程语言中(如Java),volatile关键字被用来标记变量,表明该变量的读写操作不能被重排,且每次读写都必须直接从主内存中读取或写入,从而保证了变量的可见性和有序性。
综上所述,原子操作虽然提供了操作的原子性和完整性,但在实现锁等并发控制机制时,仍需要考虑指令重排的影响,并通过相应的机制来避免潜在的问题。
# 为什么Java中不需要考虑指令重排?
在Java中,使用AtomicReference的compareAndSet(CAS)方法实现的锁(如自旋锁或基于CAS的锁)通常不需要开发者直接考虑指令重排的问题,因为Java内存模型(Java Memory Model, JMM)和AtomicReference的实现已经为开发者封装好了必要的内存可见性和有序性保证。
Java内存模型
Java内存模型定义了线程和主内存之间的抽象关系,以及线程之间共享变量的可见性和有序性规则。JMM确保了在多线程环境下,对共享变量的操作是安全且可预测的。具体来说,JMM通过以下几种方式来保证内存可见性和有序性:
volatile关键字:虽然AtomicReference本身不使用volatile来标记其内部变量(因为CAS操作已经足够保证原子性),但JMM规定了对volatile变量的读写操作具有特殊的内存语义,包括防止指令重排。不过,AtomicReference的实现依赖于底层的CAS操作,而不是直接使用volatile。
锁和同步机制:JMM还定义了锁和同步机制(如synchronized关键字和显式锁)的内存语义,这些机制同样能够防止指令重排,并确保共享变量的正确同步。然而,AtomicReference并不依赖于这些传统的锁机制,而是使用CAS操作来实现无锁的线程安全。
CAS操作:AtomicReference的compareAndSet方法底层实现依赖于CAS操作。CAS操作是一个原子操作,它包含三个参数:内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值。由于CAS操作是由底层硬件直接支持的,因此它是原子的,并且处理器在执行CAS操作时,会隐式地防止指令重排,以确保操作的完整性和可见性。
封装好的保证
因此,当开发者使用AtomicReference的compareAndSet方法来实现锁时,他们实际上是在利用一个已经封装好了内存可见性和有序性保证的原子操作。开发者不需要(也不应该)直接干预指令重排的过程,因为Java平台和底层硬件已经为他们处理了这些细节。
总结来说,使用AtomicReference的compareAndSet方法实现的锁不需要开发者直接考虑指令重排的问题,因为Java内存模型和AtomicReference的实现已经为开发者提供了必要的内存可见性和有序性保证。
# 性能测试-无锁(不是前面的“无锁”是真没有锁),互斥锁,自旋锁,自定义原子锁
1)原子锁初始化
atomic_bool atomic_lock; //定义原子锁
atomic_init(&atomic_lock, false); //初始化原子锁
2)原子锁加锁
bool val = false;//通过CAS指令实现原子锁加锁
while(!atomic_compare_exchange_weak_explicit(&atomic_lock, &val, true, memory_order_acquire, memory_order_relaxed)) {
val = false;
}
解释:
atomic_compare_exchange_weak_explicit 是一个原子操作,它尝试以原子方式更新一个原子变量的值,但它是“弱”版本的比较交换操作。这个操作的“弱”意味着它可能会在某些情况下“伪失败”(spuriously fail),即使没有其他线程同时修改该变量。这意味着调用者通常需要在一个循环中重试该操作,直到它成功为止。
atomic_compare_exchange_weak_explicit 是一个原子操作,它尝试以原子方式更新一个原子变量的值,但它是“弱”版本的比较交换操作。这个操作的“弱”意味着它可能会在某些情况下“伪失败”(spuriously fail),即使没有其他线程同时修改该变量。这意味着调用者通常需要在一个循环中重试该操作,直到它成功为止。
参数说明
&atomic_lock:指向要操作的原子变量的指针。在这个例子中,atomic_lock 是一个 atomic<bool> 类型的原子变量,用作锁。
&val:这是一个指向变量的指针,该变量包含我们期望在原子变量中的当前值(在比较之前)。如果原子变量中的值与此值相等,则比较交换操作将尝试更新该值。在比较之后,此变量将被更新为原子变量的实际值。
true:这是我们想要将原子变量更新为的新值(如果当前值等于 val 指向的值)。
memory_order_acquire:
当前线程执行的memory_order_acquire指令能够保证读到其他线程memory_order_release指令之前的所有内存写入操作。
这是成功时的内存顺序。如果比较交换成功(即,原子变量中的值之前确实等于 val),则此内存顺序确保在此操作之前的所有读取和写入操作都不会被重排到该操作之后,且对所有后续memory_order_acquire 或更强顺序进行的读取都是可见的。
memory_order_relaxed:这是失败时的内存顺序。如果比较交换失败(即,原子变量中的值之前不等于 val),则此内存顺序表示不进行任何额外的内存顺序保证。
3)原子锁解锁
//通过store指令设置原子锁的值为false
atomic_store_explicit(&atomic_lock, false, memory_order_release);
memory_order_release: 当前线程memory_order_release指令之前的所有内存写操作对于其他线程memory_order_acquire指令之后可见。
进一步解释:
通常情况下,我们的确期望先获取锁(或执行具有 memory_order_acquire 语义的原子操作),然后再进行受保护的内存操作。然而,memory_order_acquire 的“阻止之前的内存操作重排到该原子操作之后”这一作用,主要是从编译器和处理器优化的角度来考虑的。
在多线程程序中,编译器和处理器可能会对指令进行重排(reordering),以优化程序的执行效率。这种重排通常是在保证单线程执行顺序不变的前提下进行的。但是,在多线程环境中,如果这种重排涉及到共享数据的访问,就可能导致数据竞争或逻辑错误(比如这里可能把bool val = false排到后面肯定就会运行出错)。
具体到 memory_order_acquire,它告诉编译器和处理器,在执行具有 memory_order_acquire 语义的原子操作之前,所有之前的内存访问操作(无论是读还是写)都不能被重排到该原子操作之后。这样做是为了确保在逻辑上,这些内存访问操作发生在获取锁(或执行具有 memory_order_acquire 语义的原子操作)之前。
虽然在实际编程中,我们通常会在获取锁之后再进行受保护的内存操作,但 memory_order_acquire 的这一作用仍然很重要,因为它确保了即使在编译器和处理器进行优化的情况下,这种逻辑顺序也不会被打破。
此外,值得注意的是,memory_order_acquire 和 memory_order_release 通常是一起使用的,它们共同建立了一个“释放-获取”关系,用于在多线程之间同步对共享数据的访问。在这个关系中,memory_order_release 确保在释放锁(或执行具有 memory_order_release 语义的原子操作)之前的所有内存访问操作都不会被重排到该原子操作之后,并且这些操作对随后获取锁(或执行具有 memory_order_acquire 语义的原子操作)的线程是可见的。
完整代码:
#include <stdio.h>
#include <stdbool.h>
#include <pthread.h>
#include <stdatomic.h>
#define THREAD_NUM (4) //测试线程数量
#define TIMES (50000000LL) //每个线程自增次数
#define LOCK_TYPE (3) //锁类型
#define FREE_LOCK 0 //无锁
#define MUTEX_LOCK 1 //互斥锁
#define SPIN_LOCK 2 //自旋锁
#define ATOMIC_LOCK 3 //自定义原子锁
long long sum = 0;
pthread_mutex_t mutex;
pthread_spinlock_t spinlock;
atomic_bool atomic_lock;
void do_lock() {
#if (LOCK_TYPE == MUTEX_LOCK)
pthread_mutex_lock(&mutex);
#elif (LOCK_TYPE == SPIN_LOCK)
pthread_spin_lock(&spinlock);
#elif (LOCK_TYPE == ATOMIC_LOCK)
bool val = false;
while(!atomic_compare_exchange_weak_explicit(&atomic_lock, &val, true, memory_order_acquire, memory_order_relaxed)) {
val = false;
}
#else
#endif
}
void do_unlock() {
#if (LOCK_TYPE == MUTEX_LOCK)
pthread_mutex_unlock(&mutex);
#elif (LOCK_TYPE == SPIN_LOCK)
pthread_spin_unlock(&spinlock);
#elif (LOCK_TYPE == ATOMIC_LOCK)
atomic_store_explicit(&atomic_lock, false, memory_order_release);
#else
#endif
}
void *test_proc(void *arg) {
for (long long i = 0; i < TIMES; i++) {
do_lock();
sum++;
do_unlock();
}
return NULL;
}
int main(int argc, char *argv[]) {
pthread_t th[THREAD_NUM];
pthread_mutex_init(&mutex, NULL);
pthread_spin_init(&spinlock, 0);
atomic_init(&atomic_lock, false);
for (int i = 0; i < THREAD_NUM; i++) {
pthread_create(&th[i], NULL, test_proc, NULL);
}
for (int i = 0; i < THREAD_NUM; i++) {
pthread_join(th[i], NULL);
}
pthread_mutex_destroy(&mutex);
pthread_spin_destroy(&spinlock);
printf("sum:%u\n", sum);
return 0;
}
测试参数:
THREAD_NUM:测试线程数量。
TIMES:每个线程自增次数。
LOCK_TYPE:锁类型。
通过gcc test.c -o test命令将程序编译成可执行程序,然后通过time命令执行程序。
显然无锁的结果肯定是错的,主要是对比互斥锁、自旋锁和自定义原子锁的性能
# 无锁队列
Linux高性能编程_无锁队列 (opens new window)
#include <stdatomic.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <unistd.h>
#include <pthread.h>
#define PROD_THREAD_NUM (1) //生产者线程数量
#define CONS_THREAD_NUM (1) //消费者线程数量
#define TOTAL_PACKET_NUM (20000000) //测试入队数据包总数量
#define LOCK_TYPE (1)
#define FREE_LOCK (0)
#define MUTEX_LOCK (1)
struct mini_ring;
struct mini_ring *g_ring;
_Atomic(uint32_t) g_seq; //全局数据包序列号,每产生一个新的数据包加1
_Atomic(uint32_t) g_count; //全局出队数据包序列号,每出队一个数据包加1
int g_done;
pthread_mutex_t g_mutex;
pthread_cond_t g_cond;
struct mini_packet {
uint32_t seq; //数据包序列号
};
struct mini_packet *mini_packet_alloc() {
struct mini_packet *pkt = (struct mini_packet *)malloc(sizeof(*pkt));
if (!pkt) return NULL;
pkt->seq = atomic_fetch_add(&g_seq, 1);
if (pkt->seq > TOTAL_PACKET_NUM) {
return NULL;
}
return pkt;
}
void mini_packet_free(struct mini_packet *pkt) {
free(pkt);
}
struct mini_headtail {
_Atomic(uint32_t) head;
_Atomic(uint32_t) tail;
};
struct mini_ring {
struct mini_headtail prod;
struct mini_headtail cons;
uint32_t head;
uint32_t tail;
uint32_t size;
uint32_t mask;
};
struct mini_ring* mini_ring_create(uint32_t size) {
uint32_t count = sizeof(struct mini_ring) + (sizeof(void *) * size);
#if 0
printf("mini ring size:%u, size:%u, count:%u\n",
sizeof(struct mini_ring),
size,
count);
#endif
struct mini_ring *ring = (struct mini_ring *)malloc(count);
if (!ring) return NULL;
atomic_init(&ring->prod.head, 0);
atomic_init(&ring->prod.tail, 0);
atomic_init(&ring->cons.head, 0);
atomic_init(&ring->cons.tail, 0);
ring->head = 0;
ring->tail = 0;
ring->size = size;
ring->mask = size - 1;
return ring;
}
int mini_ring_free(struct mini_ring *ring) {
free(ring);
}
int mini_ring_move_prod_head(struct mini_ring *ring, uint32_t n, unsigned int *cur_head, unsigned int *next_head) {
uint32_t cons_tail;
int free_entries;
bool suc;
*cur_head = atomic_load_explicit(&ring->prod.head, memory_order_relaxed);
do {
//atomic_thread_fence(memory_order_acquire);
cons_tail = atomic_load_explicit(&ring->cons.tail, memory_order_acquire);
free_entries = ring->size - (*cur_head - cons_tail);
if (n > free_entries) {
#if 0
printf("mini queue enqueue ring->size:%u, *cur_head:%u, cons_tail:%u, free_entries:%u\n",
ring->size,
*cur_head,
cons_tail,
free_entries);
#endif
return -1;
}
*next_head = *cur_head + n;
suc = atomic_compare_exchange_strong_explicit(&ring->prod.head,
cur_head,
*next_head,
memory_order_relaxed,
memory_order_relaxed);
} while (suc == false);
return 0;
}
int mini_ring_enqueue_elems(struct mini_ring *ring, uint32_t *cur_head, void *obj_table, uint32_t n) {
uint32_t id = (*cur_head) & ring->mask;
uint64_t **slot = (uint64_t**)&ring[1];
uint64_t **p = (uint64_t **)obj_table;
if ((id + n) <= ring->size) {
for (int i = 0; i < n; i++) {
slot[id++] = p[i];
}
} else {
int i = 0;
for (; id < ring->size; i++) {
slot[id++] = p[i];
}
for (id = 0; i < n; i++) {
slot[id++] = p[i];
}
}
return 0;
}
int mini_ring_update_prod_tail(struct mini_ring *ring, uint32_t *cur_head, uint32_t *next_head) {
while(atomic_load_explicit(&ring->prod.tail, memory_order_relaxed) != *cur_head) {}
atomic_store_explicit(&ring->prod.tail, *next_head, memory_order_release);
}
int mini_ring_enqueue(struct mini_ring *ring, void *obj_table, uint32_t n) {
#if (LOCK_TYPE == FREE_LOCK)
uint32_t cur_head;
uint32_t next_head;
int ret = mini_ring_move_prod_head(ring, n, &cur_head, &next_head);
if (ret) {
//printf("mini ring move prod head error\n");
return -1;
}
mini_ring_enqueue_elems(ring, &cur_head, obj_table, n);
mini_ring_update_prod_tail(ring, &cur_head, &next_head);
#elif (LOCK_TYPE == MUTEX_LOCK)
uint32_t cur_head;
uint32_t next_head;
uint32_t free_entries;
pthread_mutex_lock(&g_mutex);
free_entries = ring->size - (ring->head - ring->tail);
if (n > free_entries) {
pthread_cond_signal(&g_cond);
pthread_mutex_unlock(&g_mutex);
return -1;
}
cur_head = ring->head;
next_head = ring->head + n;
mini_ring_enqueue_elems(ring, &cur_head, obj_table, n);
ring->head = next_head;
pthread_cond_signal(&g_cond);
pthread_mutex_unlock(&g_mutex);
#else
#endif
return 0;
}
int mini_ring_move_cons_head(struct mini_ring *ring, uint32_t n, unsigned int *cur_head, unsigned int *next_head) {
uint32_t prod_tail;
int entries;
bool suc;
*cur_head = atomic_load_explicit(&ring->cons.head, memory_order_relaxed);
do {
//atomic_thread_fence(memory_order_acquire);
prod_tail = atomic_load_explicit(&ring->prod.tail, memory_order_acquire);
entries = prod_tail - *cur_head;
if (n > entries) return -1;
*next_head = *cur_head + n;
suc = atomic_compare_exchange_strong_explicit(&ring->cons.head,
cur_head,
*next_head,
memory_order_relaxed,
memory_order_relaxed);
}while (suc == false);
return 0;
}
int mini_ring_dequeue_elems(struct mini_ring *ring, uint32_t *cur_head, void *obj_table, uint32_t n) {
uint32_t id = (*cur_head) & ring->mask;
uint64_t **slot = (uint64_t**)&ring[1];
uint64_t **p = (uint64_t **)obj_table;
if ((id + n) <= ring->size) {
for (int i = 0; i < n; i++) {
p[i] = slot[id++];
}
} else {
int i = 0;
for (; id < ring->size; i++) {
p[i] = slot[id++];
}
for (id = 0; i < n; i++) {
p[i] = slot[id++];
}
}
return 0;
}
int mini_ring_update_cons_tail(struct mini_ring *ring, uint32_t *cur_head, uint32_t *next_head) {
while(atomic_load_explicit(&ring->cons.tail, memory_order_relaxed) != *cur_head) {}
atomic_store_explicit(&ring->cons.tail, *next_head, memory_order_release);
}
int mini_ring_dequeue(struct mini_ring *ring, void *obj_table, uint32_t n) {
#if (LOCK_TYPE == FREE_LOCK)
uint32_t cur_head;
uint32_t next_head;
int ret = mini_ring_move_cons_head(ring, n, &cur_head, &next_head);
if (ret) {
//printf("mini ring move cons head ret:%d error\n", ret);
return -1;
}
mini_ring_dequeue_elems(ring, &cur_head, obj_table, n);
mini_ring_update_cons_tail(ring, &cur_head, &next_head);
#elif (LOCK_TYPE == MUTEX_LOCK)
uint32_t cur_tail;
uint32_t next_tail;
uint32_t entries;
pthread_mutex_lock(&g_mutex);
entries = ring->head - ring->tail;
#if 0
if (n > entries) {
pthread_mutex_unlock(&g_mutex);
return -1;
}
#else
while((n > entries) && (g_done == 0)) {
pthread_cond_wait(&g_cond, &g_mutex);
entries = ring->head - ring->tail;
}
if (g_done != 0) {
pthread_mutex_unlock(&g_mutex);
return -1;
}
#endif
cur_tail = ring->tail;
next_tail = ring->tail + n;
mini_ring_dequeue_elems(ring, &cur_tail, obj_table, n);
ring->tail = next_tail;
pthread_mutex_unlock(&g_mutex);
#else
#endif
return 0;
}
void *prod_thread(void *arg) {
int thread_num = (int)arg;
uint64_t **obj_table = NULL;
while(1) {
//for (int i = 0; i < 10000; i++) ;
struct mini_packet *pkt = mini_packet_alloc();
if (!pkt) {
printf("入队:%d个数据包,生产者线程:%d 退出!\n", TOTAL_PACKET_NUM, thread_num);
break;
}
//printf("prod thread num:%d, new pkt seq:%u\n", thread_num, pkt->seq);
obj_table = (uint64_t **)&pkt;
try_again:
int ret = mini_ring_enqueue(g_ring, (void *)obj_table, 1);
if (ret) {
//printf("mini ring enqueue ret:%d error\n", ret);
goto try_again;
}
}
return NULL;
}
void *cons_thread(void *arg) {
int thread_num = (int)arg;
int ret = 0;
uint64_t **obj_table = NULL;
struct mini_packet *pkt = NULL;
int failed_times = 0;
uint32_t count = 0;
while(1) {
count = atomic_load(&g_count);
if (count > TOTAL_PACKET_NUM) {
printf("出队:%d个数据包,消费者线程:%d 退出!\n", count - 1, thread_num);
break;
}
obj_table = (uint64_t **)&pkt;
ret = mini_ring_dequeue(g_ring, (void *)obj_table, 1);
if (ret < 0) {
if (failed_times < 1000) {
failed_times++;
} else {
//printf("dequeue failed times:%d\n", failed_times);
usleep(10);
failed_times = 0;
}
continue;
}
#if 0
if ((pkt->seq % 1000) == 0){
printf("cons thread num:%d, dequeue pkt seq:%u\n", thread_num, pkt->seq);
}
#endif
mini_packet_free(pkt);
atomic_fetch_add(&g_count, 1);
}
g_done++;
return NULL;
}
int main(int argc, char *argv[]) {
atomic_init(&g_seq, 0);
atomic_init(&g_count, 0);
pthread_mutex_init(&g_mutex, NULL);
pthread_cond_init(&g_cond, NULL);
g_done = 0;
int size = 4096;
g_ring = mini_ring_create(size);
pthread_t prod_th[PROD_THREAD_NUM];
pthread_t cons_th[CONS_THREAD_NUM];
for (int i = 0; i < CONS_THREAD_NUM; i++) {
pthread_create(&cons_th[i], NULL, cons_thread, (void *)i);
}
for (int i = 0; i < PROD_THREAD_NUM; i++) {
pthread_create(&prod_th[i], NULL, prod_thread, (void *)i);
}
for (int i = 0; i < PROD_THREAD_NUM; i++) {
pthread_join(prod_th[i], NULL);
}
while(g_done < CONS_THREAD_NUM) {
pthread_cond_signal(&g_cond);
usleep(10);
//printf("g_done:%d\n", g_done);
}
//printf("--g_done:%d\n", g_done);
for (int i = 0; i < CONS_THREAD_NUM; i++) {
pthread_join(cons_th[i], NULL);
}
pthread_mutex_destroy(&g_mutex);
pthread_cond_destroy(&g_cond);
return 0;
}
# 编程考虑
# 局部变量线程安全?
- 普通的局部变量确实是线程安全的, 方法里的局部变量,因为不会和其他线程共享,所以不会存在并发问题。这种解决问题的技术也叫做线程封闭。官方的解释为:仅在单线程内访问数据。由于不存在共享,所以即使不设置同步,也不会出现并发问题! (opens new window)
- 但是如果引用的是全局变量就不安全了
# 静态static与单例singleton的线程安全
关于static及singleton: Singleton可以是static的,static是vm级别的静态变量,singleton可以是application级别的单例,如果是vm级别的,需要考虑application之间的冲突,如果是standalone程序,则可以使用vm static,引用一段shiro关于SecurityManager的注释:
The Shiro development team prefers that SecurityManager instances are non-static application singletons
* and <em>not</em> VM static singletons. Application singletons that do not use static memory require some sort
* of application configuration framework to maintain the application-wide SecurityManager instance for you
* (for example, Spring or EJB3 environments) such that the object reference does not need to be static.
singleton is created at Class-load time:
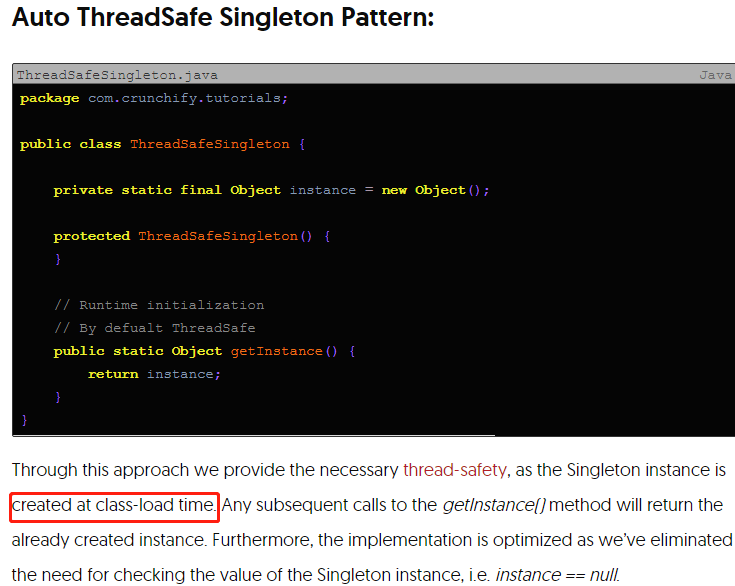
Static method defeat OOP, because static method is not object behavior, For thread safe, we should look at static variable not static method/instruction t’s not the static methods that you have to watch out for – it’s the static fields.
https://stackoverflow.com/questions/7026507/why-are-static-variables-considered-evil
静态变量经常用作全局初始化的global state: init(write at application start) and used(read) from everywhere, 比如ConcurrentDictionary
静态方法线程安全?No Many of the classes in the .NET framework have the following remark in the “Thread Safety” section: > "Any public static (Shared in Visual Basic) members of this type are thread safe. Any instance members are not guaranteed to be thread safe. "Does this mean static methods are inherently thread safe? The answer is no. Classes with the above note will have thread safe static methods because the Microsoft engineers wrote the code in a thread safe manner, perhaps by using locks or other thread synchronization mechanisms File.Open(XXX) String.XXX
单例模式例子: Plugin Example: log4net Log4net Thread-Safe but not Process-Safe http://hectorcorrea.com/blog/log4net-thread-safe-but-not-process-safe/17
# Use it in thread-safe way
System.timer It will Continue Executing on different thread So set autoreset=false
Message queue, multiple consumer retrieve messages from queue.
Refer: https://odetocode.com/articles/313.aspx
todo: Java Concurrency issues and Thread Synchronization https://www.callicoder.com/java-concurrency-issues-and-thread-synchronization/#:~:text=Memory%20inconsistency%20errors%20occur%20when,up%20using%20the%20old%20data.
concurrency queue
concurrency dictionary
C#在多线程环境中,进行安全遍历操作
http://stanzhai.github.io/2013/06/27/csharp-read-data-in-multithread-safely/
Implementing the Singleton Pattern in C#
http://csharpindepth.com/Articles/General/Singleton.aspx
Thread Safety In C# www.c-sharpcorner.com/UploadFile/1c8574/thread-safety369/ (opens new window)
System.timer Thread.timer
腾讯面试官:如何停止一个正在运行的线程? https://mp.weixin.qq.com/s/9xjGYbcNwl1aQY5GNOx58g
# 节点安全 - 分布式锁
- 线程锁 主要用于控制同一进程中的多个线程对共享资源的访问。
- 进程锁 进程锁是用于控制同一台机器上的多个进程对共享资源的访问。进程锁可以是系统级的,如文件锁,也可以是用户级的,如信号量(Semaphore)。
- 分布式锁 分布式锁是用于控制分布式系统中的多个节点对共享资源的访问。由于分布式系统中的节点可能位于不同的机器甚至不同的地理位置,因此分布式锁的实现比线程锁和进程锁要复杂得多。分布式锁需要在网络中的多个节点之间进行协调,以保证锁的唯一性和一致性。
对于分布式系统来说,同样存在着访问竞争资源的问题,比如最基本的是竞争称为leader,这个一般就需要采用一种“分布式锁”来进行资源保护,
分布式锁特性:
- 互斥性:在任何时刻,只有一个节点可以持有锁。
- 不会发生死锁:如果一个节点崩溃,锁可以被其他节点获取。
- 公平性:如果多个节点同时申请锁,系统应该保证每个节点都有获取锁的机会。
- 可重入性:同一个节点可以多次获取同一个锁,而不会被阻塞。
- 高可用:锁服务应该是高可用的,不能因为锁服务的故障而影响整个系统的运行
分布式锁的常见实现方式:
- 基于数据库 select for update
- 基于redis (opens new window)
- 基于zookeeper的ephemeral sequential node
# Troubleshooting
# Servlet ConcurrentModificationException
2024-01-15 08:08:37.018 [31mERROR[m [35m26037GG[m [io-10001-exec-3] [36mc.q.f.w.a.CommonExceptionHandler[m : InternalException: null
java.util.ConcurrentModificationException
at java.util.HashMap$HashIterator.nextNode(HashMap.java:1429)
at java.util.HashMap$KeyIterator.next(HashMap.java:1453)
at com.test.security.SessionInterceptor.preHandle(SessionInterceptor.java:36)
at org.springframework.web.servlet.HandlerExecutionChain.applyPreHandle(HandlerExecutionChain.java:148)
at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:1055)
at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:962)
at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:1006)
at org.springframework.web.servlet.FrameworkServlet.doPost(FrameworkServlet.java:909)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:652)
at org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:883)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:733)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:227)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
at org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:53)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:112)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:61)
at org.apache.shiro.web.servlet.AdviceFilter.executeChain(AdviceFilter.java:108)
at org.apache.shiro.web.servlet.AdviceFilter.doFilterInternal(AdviceFilter.java:137)
at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:66)
at org.apache.shiro.web.servlet.AdviceFilter.executeChain(AdviceFilter.java:108)
at org.apache.shiro.web.servlet.AdviceFilter.doFilterInternal(AdviceFilter.java:137)
at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:66)
at org.apache.shiro.web.servlet.AdviceFilter.executeChain(AdviceFilter.java:108)
at org.apache.shiro.web.servlet.AdviceFilter.doFilterInternal(AdviceFilter.java:137)
at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:66)
at org.apache.shiro.web.servlet.AdviceFilter.executeChain(AdviceFilter.java:108)
at org.apache.shiro.web.servlet.AdviceFilter.doFilterInternal(AdviceFilter.java:137)
at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
at org.apache.shiro.web.servlet.ProxiedFilterChain.doFilter(ProxiedFilterChain.java:66)
at org.apache.shiro.web.servlet.AbstractShiroFilter.executeChain(AbstractShiroFilter.java:449)
at org.apache.shiro.web.servlet.AbstractShiroFilter$1.call(AbstractShiroFilter.java:365)
at org.apache.shiro.subject.support.SubjectCallable.doCall(SubjectCallable.java:90)
at org.apache.shiro.subject.support.SubjectCallable.call(SubjectCallable.java:83)
at org.apache.shiro.subject.support.DelegatingSubject.execute(DelegatingSubject.java:387)
at org.apache.shiro.web.servlet.AbstractShiroFilter.doFilterInternal(AbstractShiroFilter.java:362)
at org.apache.shiro.web.servlet.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:125)
at org.springframework.web.filter.DelegatingFilterProxy.invokeDelegate(DelegatingFilterProxy.java:358)
at org.springframework.web.filter.DelegatingFilterProxy.doFilter(DelegatingFilterProxy.java:271)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
at com.alibaba.druid.support.http.WebStatFilter.doFilter(WebStatFilter.java:123)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
at org.springframework.web.filter.RequestContextFilter.doFilterInternal(RequestContextFilter.java:100)
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
at org.springframework.web.filter.FormContentFilter.doFilterInternal(FormContentFilter.java:93)
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
at org.springframework.boot.actuate.metrics.web.servlet.WebMvcMetricsFilter.doFilterInternal(WebMvcMetricsFilter.java:93)
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
at org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:201)
at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:119)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162)
at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:202)
at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:97)
at org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:542)
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:143)
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:92)
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:78)
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:357)
at org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:374)
at org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:65)
at org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:893)
at org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1707)
at org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61)
at java.lang.Thread.run(Thread.java:745)
对应代码是
@Component
public class SessionInterceptor implements HandlerInterceptor {
private static final Logger logger = LoggerFactory.getLogger(SessionInterceptor.class);
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
HttpSession httpSession = request.getSession();
if(null == httpSession.getId()){
return true;
}
ServletContext application = httpSession.getServletContext();
SSOUser ssoUser = (SSOUser) httpSession.getAttribute("LoginSessionUser");
// 在application范围由一个HashSet集保存所有的session
HashSet<OnlineUserDto> onlineUserSet = (HashSet) application.getAttribute("onlineUser");
。。。。。。。。。。。。。。。。。。。。。。。。。。
}
return true;
}
}
统计在线人数,虽然是局部变量但是引用了全局的httpsession,每个请求进来 servlet就会新建一个线程拦截处理(调用service),那么自然这里就存在线程安全问题了,改成线程安全的set就行了
# 迭代器Iterator与ConcurrentModificationException详解
https://www.cnblogs.com/lixuwu/p/7990141.html#/ https://github.com/alibaba/fastjson/issues/2528#/