PRIVACY POLICY
Last updated July 24, 2023
This privacy notice for Liu Yue (‘we’, ‘us’, or ‘our’), describes how and why we might collect, store, use, and/or share (‘process’) your information when you use our services (‘Services’), such as when you:
-
Visit our website at lyhistory.com, or any website of ours that links to this privacy notice
-
Engage with us in other related ways, including any sales, marketing, or events
Questions or concerns? Reading this privacy notice will help you understand your privacy rights and choices. If you do not agree with our policies and practices, please do not use our Services. If you still have any questions or concerns, please contact us at lyhistory@gmail.com.
SUMMARY OF KEY POINTS
This summary provides key points from our privacy notice, but you can find out more details about any of these topics by clicking the link following each key point or by using our table of contents below to find the section you are looking for.
What personal information do we process? When you visit, use, or navigate our Services, we may process personal information depending on how you interact with us and the Services, the choices you make, and the products and features you use. Learn more about personal information you disclose to us.
Do we process any sensitive personal information? We do not process sensitive personal information.
Do we receive any information from third parties? We do not receive any information from third parties.
How do we process your information? We process your information to provide, improve, and administer our Services, communicate with you, for security and fraud prevention, and to comply with law. We may also process your information for other purposes with your consent. We process your information only when we have a valid legal reason to do so. Learn more about how we process your information.
In what situations and with which types of parties do we share personal information? We may share information in specific situations and with specific categories of third parties. Learn more about when and with whom we share your personal information.
How do we keep your information safe? We have organisational and technical processes and procedures in place to protect your personal information. However, no electronic transmission over the internet or information storage technology can be guaranteed to be 100% secure, so we cannot promise or guarantee that hackers, cybercriminals, or other unauthorised third parties will not be able to defeat our security and improperly collect, access, steal, or modify your information. Learn more about how we keep your information safe.
What are your rights? Depending on where you are located geographically, the applicable privacy law may mean you have certain rights regarding your personal information. Learn more about your privacy rights.
How do you exercise your rights? The easiest way to exercise your rights is by submitting a data subject access request, or by contacting us. We will consider and act upon any request in accordance with applicable data protection laws.
Want to learn more about what we do with any information we collect? Review the privacy notice in full.
TABLE OF CONTENTS
1. WHAT INFORMATION DO WE COLLECT?
2. HOW DO WE PROCESS YOUR INFORMATION?
3. WHAT LEGAL BASES DO WE RELY ON TO PROCESS YOUR PERSONAL INFORMATION?
4. WHEN AND WITH WHOM DO WE SHARE YOUR PERSONAL INFORMATION?
5. DO WE USE COOKIES AND OTHER TRACKING TECHNOLOGIES?
6. HOW LONG DO WE KEEP YOUR INFORMATION?
7. HOW DO WE KEEP YOUR INFORMATION SAFE?
8. DO WE COLLECT INFORMATION FROM MINORS?
9. WHAT ARE YOUR PRIVACY RIGHTS?
10. CONTROLS FOR DO-NOT-TRACK FEATURES
11. DO UNITED STATES RESIDENTS HAVE SPECIFIC PRIVACY RIGHTS?
12. DO WE MAKE UPDATES TO THIS NOTICE?
13. HOW CAN YOU CONTACT US ABOUT THIS NOTICE?
14. HOW CAN YOU REVIEW, UPDATE, OR DELETE THE DATA WE COLLECT FROM YOU?
1. WHAT INFORMATION DO WE COLLECT?
Personal information you disclose to us
In Short: We collect personal information that you provide to us.
We collect personal information that you voluntarily provide to us when you express an interest in obtaining information about us or our products and Services, when you participate in activities on the Services, or otherwise when you contact us.
Sensitive Information. We do not process sensitive information.
All personal information that you provide to us must be true, complete, and accurate, and you must notify us of any changes to such personal information.
Information automatically collected
In Short: Some information — such as your Internet Protocol (IP) address and/or browser and device characteristics — is collected automatically when you visit our Services.
We automatically collect certain information when you visit, use, or navigate the Services. This information does not reveal your specific identity (like your name or contact information) but may include device and usage information, such as your IP address, browser and device characteristics, operating system, language preferences, referring URLs, device name, country, location, information about how and when you use our Services, and other technical information. This information is primarily needed to maintain the security and operation of our Services, and for our internal analytics and reporting purposes.
Like many businesses, we also collect information through cookies and similar technologies.
The information we collect includes:
-
Log and Usage Data. Log and usage data is service-related, diagnostic, usage, and performance information our servers automatically collect when you access or use our Services and which we record in log files. Depending on how you interact with us, this log data may include your IP address, device information, browser type, and settings and information about your activity in the Services (such as the date/time stamps associated with your usage, pages and files viewed, searches, and other actions you take such as which features you use), device event information (such as system activity, error reports (sometimes called ‘crash dumps’), and hardware settings).
-
Device Data. We collect device data such as information about your computer, phone, tablet, or other device you use to access the Services. Depending on the device used, this device data may include information such as your IP address (or proxy server), device and application identification numbers, location, browser type, hardware model, Internet service provider and/or mobile carrier, operating system, and system configuration information.
-
Location Data. We collect location data such as information about your device’s location, which can be either precise or imprecise. How much information we collect depends on the type and settings of the device you use to access the Services. For example, we may use GPS and other technologies to collect geolocation data that tells us your current location (based on your IP address). You can opt out of allowing us to collect this information either by refusing access to the information or by disabling your Location setting on your device. However, if you choose to opt out, you may not be able to use certain aspects of the Services.
2. HOW DO WE PROCESS YOUR INFORMATION?
In Short: We process your information to provide, improve, and administer our Services, communicate with you, for security and fraud prevention, and to comply with law. We may also process your information for other purposes with your consent.
We process your personal information for a variety of reasons, depending on how you interact with our Services, including:
-
To request feedback. We may process your information when necessary to request feedback and to contact you about your use of our Services.
-
To send you marketing and promotional communications. We may process the personal information you send to us for our marketing purposes, if this is in accordance with your marketing preferences. You can opt out of our marketing emails at any time. For more information, see ‘WHAT ARE YOUR PRIVACY RIGHTS?’ below.
-
To deliver targeted advertising to you. We may process your information to develop and display personalised content and advertising tailored to your interests, location, and more.
-
To protect our Services. We may process your information as part of our efforts to keep our Services safe and secure, including fraud monitoring and prevention.
-
To identify usage trends. We may process information about how you use our Services to better understand how they are being used so we can improve them.
-
To determine the effectiveness of our marketing and promotional campaigns. We may process your information to better understand how to provide marketing and promotional campaigns that are most relevant to you.
-
To save or protect an individual’s vital interest. We may process your information when necessary to save or protect an individual’s vital interest, such as to prevent harm.
3. WHAT LEGAL BASES DO WE RELY ON TO PROCESS YOUR INFORMATION?
In Short: We only process your personal information when we believe it is necessary and we have a valid legal reason (i.e. legal basis) to do so under applicable law, like with your consent, to comply with laws, to provide you with services to enter into or fulfil our contractual obligations, to protect your rights, or to fulfil our legitimate business interests.
If you are located in the EU or UK, this section applies to you.
The General Data Protection Regulation (GDPR) and UK GDPR require us to explain the valid legal bases we rely on in order to process your personal information. As such, we may rely on the following legal bases to process your personal information:
-
Consent. We may process your information if you have given us permission (i.e. consent) to use your personal information for a specific purpose. You can withdraw your consent at any time. Learn more about withdrawing your consent.
-
Legitimate Interests. We may process your information when we believe it is reasonably necessary to achieve our legitimate business interests and those interests do not outweigh your interests and fundamental rights and freedoms. For example, we may process your personal information for some of the purposes described in order to:
-
Send users information about special offers and discounts on our products and services
-
Develop and display personalised and relevant advertising content for our users
-
Analyse how our Services are used so we can improve them to engage and retain users
-
Support our marketing activities
-
Diagnose problems and/or prevent fraudulent activities
-
Understand how our users use our products and services so we can improve user experience
-
Legal Obligations. We may process your information where we believe it is necessary for compliance with our legal obligations, such as to cooperate with a law enforcement body or regulatory agency, exercise or defend our legal rights, or disclose your information as evidence in litigation in which we are involved.
-
Vital Interests. We may process your information where we believe it is necessary to protect your vital interests or the vital interests of a third party, such as situations involving potential threats to the safety of any person.
If you are located in Canada, this section applies to you.
We may process your information if you have given us specific permission (i.e. express consent) to use your personal information for a specific purpose, or in situations where your permission can be inferred (i.e. implied consent). You can withdraw your consent at any time.
In some exceptional cases, we may be legally permitted under applicable law to process your information without your consent, including, for example:
-
If collection is clearly in the interests of an individual and consent cannot be obtained in a timely way
-
For investigations and fraud detection and prevention
-
For business transactions provided certain conditions are met
-
If it is contained in a witness statement and the collection is necessary to assess, process, or settle an insurance claim
-
For identifying injured, ill, or deceased persons and communicating with next of kin
-
If we have reasonable grounds to believe an individual has been, is, or may be victim of financial abuse
-
If it is reasonable to expect collection and use with consent would compromise the availability or the accuracy of the information and the collection is reasonable for purposes related to investigating a breach of an agreement or a contravention of the laws of Canada or a province
-
If disclosure is required to comply with a subpoena, warrant, court order, or rules of the court relating to the production of records
-
If it was produced by an individual in the course of their employment, business, or profession and the collection is consistent with the purposes for which the information was produced
-
If the collection is solely for journalistic, artistic, or literary purposes
-
If the information is publicly available and is specified by the regulations
4. WHEN AND WITH WHOM DO WE SHARE YOUR PERSONAL INFORMATION?
In Short: We may share information in specific situations described in this section and/or with the following categories of third parties.
Vendors, Consultants, and Other Third-Party Service Providers. We may share your data with third-party vendors, service providers, contractors, or agents (‘third parties’) who perform services for us or on our behalf and require access to such information to do that work. We have contracts in place with our third parties, which are designed to help safeguard your personal information. This means that they cannot do anything with your personal information unless we have instructed them to do it. They will also not share your personal information with any organisation apart from us. They also commit to protect the data they hold on our behalf and to retain it for the period we instruct. The categories of third parties we may share personal information with are as follows:
-
Data Analytics Services
-
Ad Networks
-
Affiliate Marketing Programs
-
Social Networks
-
Website Hosting Service Providers
-
Performance Monitoring Tools
-
Sales & Marketing Tools
We also may need to share your personal information in the following situations:
-
Business Transfers. We may share or transfer your information in connection with, or during negotiations of, any merger, sale of company assets, financing, or acquisition of all or a portion of our business to another company.
-
When we use Google Maps Platform APIs. We may share your information with certain Google Maps Platform APIs (e.g. Google Maps API, Places API). We obtain and store on your device (‘cache’) your location. You may revoke your consent anytime by contacting us at the contact details provided at the end of this document.
-
Affiliates. We may share your information with our affiliates, in which case we will require those affiliates to honour this privacy notice. Affiliates include our parent company and any subsidiaries, joint venture partners, or other companies that we control or that are under common control with us.
-
Business Partners. We may share your information with our business partners to offer you certain products, services, or promotions.
5. DO WE USE COOKIES AND OTHER TRACKING TECHNOLOGIES?
In Short: We may use cookies and other tracking technologies to collect and store your information.
We may use cookies and similar tracking technologies (like web beacons and pixels) to access or store information. Specific information about how we use such technologies and how you can refuse certain cookies is set out in our Cookie Notice.
6. HOW LONG DO WE KEEP YOUR INFORMATION?
In Short: We keep your information for as long as necessary to fulfil the purposes outlined in this privacy notice unless otherwise required by law.
We will only keep your personal information for as long as it is necessary for the purposes set out in this privacy notice, unless a longer retention period is required or permitted by law (such as tax, accounting, or other legal requirements).
When we have no ongoing legitimate business need to process your personal information, we will either delete or anonymise such information, or, if this is not possible (for example, because your personal information has been stored in backup archives), then we will securely store your personal information and isolate it from any further processing until deletion is possible.
7. HOW DO WE KEEP YOUR INFORMATION SAFE?
In Short: We aim to protect your personal information through a system of organisational and technical security measures.
We have implemented appropriate and reasonable technical and organisational security measures designed to protect the security of any personal information we process. However, despite our safeguards and efforts to secure your information, no electronic transmission over the Internet or information storage technology can be guaranteed to be 100% secure, so we cannot promise or guarantee that hackers, cybercriminals, or other unauthorised third parties will not be able to defeat our security and improperly collect, access, steal, or modify your information. Although we will do our best to protect your personal information, transmission of personal information to and from our Services is at your own risk. You should only access the Services within a secure environment.
8. DO WE COLLECT INFORMATION FROM MINORS?
In Short: We do not knowingly collect data from or market to children under 18 years of age.
We do not knowingly solicit data from or market to children under 18 years of age. By using the Services, you represent that you are at least 18 or that you are the parent or guardian of such a minor and consent to such minor dependent’s use of the Services. If we learn that personal information from users less than 18 years of age has been collected, we will deactivate the account and take reasonable measures to promptly delete such data from our records. If you become aware of any data we may have collected from children under age 18, please contact us at lyhistory@gmail.com.
9. WHAT ARE YOUR PRIVACY RIGHTS?
In Short: In some regions, such as the European Economic Area (EEA), United Kingdom (UK), and Canada, you have rights that allow you greater access to and control over your personal information. You may review, change, or terminate your account at any time.
In some regions (like the EEA, UK, and Canada), you have certain rights under applicable data protection laws. These may include the right (i) to request access and obtain a copy of your personal information, (ii) to request rectification or erasure; (iii) to restrict the processing of your personal information; and (iv) if applicable, to data portability. In certain circumstances, you may also have the right to object to the processing of your personal information. You can make such a request by contacting us by using the contact details provided in the section ‘HOW CAN YOU CONTACT US ABOUT THIS NOTICE?’ below.
We will consider and act upon any request in accordance with applicable data protection laws.
If you are located in the EEA or UK and you believe we are unlawfully processing your personal information, you also have the right to complain to your Member State data protection authority or UK data protection authority.
If you are located in Switzerland, you may contact the Federal Data Protection and Information Commissioner.
Withdrawing your consent: If we are relying on your consent to process your personal information, which may be express and/or implied consent depending on the applicable law, you have the right to withdraw your consent at any time. You can withdraw your consent at any time by contacting us by using the contact details provided in the section ‘HOW CAN YOU CONTACT US ABOUT THIS NOTICE?’ below.
However, please note that this will not affect the lawfulness of the processing before its withdrawal nor, when applicable law allows, will it affect the processing of your personal information conducted in reliance on lawful processing grounds other than consent.
Cookies and similar technologies: Most Web browsers are set to accept cookies by default. If you prefer, you can usually choose to set your browser to remove cookies and to reject cookies. If you choose to remove cookies or reject cookies, this could affect certain features or services of our Services.
If you have questions or comments about your privacy rights, you may email us at lyhistory@gmail.com.
10. CONTROLS FOR DO-NOT-TRACK FEATURES
Most web browsers and some mobile operating systems and mobile applications include a Do-Not-Track (‘DNT’) feature or setting you can activate to signal your privacy preference not to have data about your online browsing activities monitored and collected. At this stage no uniform technology standard for recognising and implementing DNT signals has been finalised. As such, we do not currently respond to DNT browser signals or any other mechanism that automatically communicates your choice not to be tracked online. If a standard for online tracking is adopted that we must follow in the future, we will inform you about that practice in a revised version of this privacy notice.
11. DO UNITED STATES RESIDENTS HAVE SPECIFIC PRIVACY RIGHTS?
In Short: If you are a resident of California, Connecticut, Colorado or Virginia, you are granted specific rights regarding access to your personal information.
What categories of personal information do we collect?
We have collected the following categories of personal information in the past twelve (12) months:
Category
Examples
Collected
A. Identifiers
Contact details, such as real name, alias, postal address, telephone or mobile contact number, unique personal identifier, online identifier, Internet Protocol address, email address, and account name
NO
B. Protected classification characteristics under state or federal law
Gender and date of birth
NO
C. Commercial information
Transaction information, purchase history, financial details, and payment information
NO
D. Biometric information
Fingerprints and voiceprints
NO
E. Internet or other similar network activity
Browsing history, search history, online behaviour, interest data, and interactions with our and other websites, applications, systems, and advertisements
YES
F. Geolocation data
Device location
YES
G. Audio, electronic, visual, thermal, olfactory, or similar information
Images and audio, video or call recordings created in connection with our business activities
NO
H. Professional or employment-related information
Business contact details in order to provide you our Services at a business level or job title, work history, and professional qualifications if you apply for a job with us
NO
I. Education Information
Student records and directory information
NO
J. Inferences drawn from collected personal information
Inferences drawn from any of the collected personal information listed above to create a profile or summary about, for example, an individual’s preferences and characteristics
NO
K. Sensitive personal information
NO
L. Personal information as defined in the California Customer Records statute
Name, contact information, education, employment, employment history, and financial information
NO
We will use and retain the collected personal information as needed to provide the Services or for:
We may also collect other personal information outside of these categories through instances where you interact with us in person, online, or by phone or mail in the context of:
-
Receiving help through our customer support channels;
-
Participation in customer surveys or contests; and
-
Facilitation in the delivery of our Services and to respond to your inquiries.
How do we use and share your personal information?
Learn about how we use your personal information in the section, ‘HOW DO WE PROCESS YOUR INFORMATION?’
We collect and share your personal information through:
More information about our data collection and sharing practices can be found in this privacy notice.
Will your information be shared with anyone else?
We may disclose your personal information with our service providers pursuant to a written contract between us and each service provider. Learn more about who we disclose personal information to in the section, ‘WHEN AND WITH WHOM DO WE SHARE YOUR PERSONAL INFORMATION?’
We may use your personal information for our own business purposes, such as for undertaking internal research for technological development and demonstration. This is not considered to be ‘selling’ of your personal information.
We have disclosed the following categories of personal information to third parties for a business or commercial purpose in the preceding twelve (12) months:
The categories of third parties to whom we disclosed personal information for a business or commercial purpose can be found under ‘WHEN AND WITH WHOM DO WE SHARE YOUR PERSONAL INFORMATION?’
We have sold or shared the following categories of personal information to third parties in the preceding twelve (12) months:
The categories of third parties to whom we sold personal information are:
The categories of third parties to whom we shared personal information with are:
California Residents
California Civil Code Section 1798.83, also known as the ‘Shine The Light’ law, permits our users who are California residents to request and obtain from us, once a year and free of charge, information about categories of personal information (if any) we disclosed to third parties for direct marketing purposes and the names and addresses of all third parties with which we shared personal information in the immediately preceding calendar year. If you are a California resident and would like to make such a request, please submit your request in writing to us using the contact information provided below.
If you are under 18 years of age, reside in California, and have a registered account with the Services, you have the right to request removal of unwanted data that you publicly post on the Services. To request removal of such data, please contact us using the contact information provided below and include the email address associated with your account and a statement that you reside in California. We will make sure the data is not publicly displayed on the Services, but please be aware that the data may not be completely or comprehensively removed from all our systems (e.g. backups, etc.).
CCPA Privacy Notice
This section applies only to California residents. Under the California Consumer Privacy Act (CCPA), you have the rights listed below.
The California Code of Regulations defines a ‘resident’ as:
(1) every individual who is in the State of California for other than a temporary or transitory purpose and
(2) every individual who is domiciled in the State of California who is outside of the State of California for a temporary or transitory purpose
All other individuals are defined as ‘non-residents’.
If this definition of ‘resident’ applies to you, we must adhere to certain rights and obligations regarding your personal information.
Your rights with respect to your personal data
Right to request deletion of the data — Request to delete
You can ask for the deletion of your personal information. If you ask us to delete your personal information, we will respect your request and delete your personal information, subject to certain exceptions provided by law, such as (but not limited to) the exercise by another consumer of his or her right to free speech, our compliance requirements resulting from a legal obligation, or any processing that may be required to protect against illegal activities.
Right to be informed — Request to know
Depending on the circumstances, you have a right to know:
-
whether we collect and use your personal information;
-
the categories of personal information that we collect;
-
the purposes for which the collected personal information is used;
-
whether we sell or share personal information to third parties;
-
the categories of personal information that we sold, shared, or disclosed for a business purpose;
-
the categories of third parties to whom the personal information was sold, shared, or disclosed for a business purpose;
-
the business or commercial purpose for collecting, selling, or sharing personal information; and
-
the specific pieces of personal information we collected about you.
In accordance with applicable law, we are not obligated to provide or delete consumer information that is de-identified in response to a consumer request or to re-identify individual data to verify a consumer request.
Right to Non-Discrimination for the Exercise of a Consumer’s Privacy Rights
We will not discriminate against you if you exercise your privacy rights.
Right to Limit Use and Disclosure of Sensitive Personal Information
We do not process consumer’s sensitive personal information.
Verification process
Upon receiving your request, we will need to verify your identity to determine you are the same person about whom we have the information in our system. These verification efforts require us to ask you to provide information so that we can match it with information you have previously provided us. For instance, depending on the type of request you submit, we may ask you to provide certain information so that we can match the information you provide with the information we already have on file, or we may contact you through a communication method (e.g. phone or email) that you have previously provided to us. We may also use other verification methods as the circumstances dictate.
We will only use personal information provided in your request to verify your identity or authority to make the request. To the extent possible, we will avoid requesting additional information from you for the purposes of verification. However, if we cannot verify your identity from the information already maintained by us, we may request that you provide additional information for the purposes of verifying your identity and for security or fraud-prevention purposes. We will delete such additionally provided information as soon as we finish verifying you.
Other privacy rights
-
You may object to the processing of your personal information.
-
You may request correction of your personal data if it is incorrect or no longer relevant, or ask to restrict the processing of the information.
-
You can designate an authorised agent to make a request under the CCPA on your behalf. We may deny a request from an authorised agent that does not submit proof that they have been validly authorised to act on your behalf in accordance with the CCPA.
You can opt out from the selling or sharing of your personal information by disabling cookies in Cookie Preference Settings and clicking on the Do Not Sell or Share My Personal Information link on our homepage.
To exercise these rights, you can contact us by submitting a data subject access request, or by referring to the contact details at the bottom of this document. If you have a complaint about how we handle your data, we would like to hear from you.
Colorado Residents
This section applies only to Colorado residents. Under the Colorado Privacy Act (CPA), you have the rights listed below. However, these rights are not absolute, and in certain cases we may decline your request as permitted by law.
-
Right to be informed whether or not we are processing your personal data
-
Right to access your personal data
-
Right to correct inaccuracies in your personal data
-
Right to request deletion of your personal data
-
Right to obtain a copy of the personal data you previously shared with us
-
Right to opt out of the processing of your personal data if it is used for targeted advertising, the sale of personal data, or profiling in furtherance of decisions that produce legal or similarly significant effects (‘profiling’)
We sell personal data to third parties or process personal data for targeted advertising. You can opt out from the selling of your personal data, targeted advertising, or profiling by disabling cookies in Cookie Preference Settings. To submit a request to exercise any of the other rights described above, please email lyhistory@gmail.com or submit a data subject access request.
If we decline to take action regarding your request and you wish to appeal our decision, please email us at lyhistory@gmail.com. Within forty-five (45) days of receipt of an appeal, we will inform you in writing of any action taken or not taken in response to the appeal, including a written explanation of the reasons for the decisions.
Connecticut Residents
This section applies only to Connecticut residents. Under the Connecticut Data Privacy Act (CTDPA), you have the rights listed below. However, these rights are not absolute, and in certain cases we may decline your request as permitted by law.
-
Right to be informed whether or not we are processing your personal data
-
Right to access your personal data
-
Right to correct inaccuracies in your personal data
-
Right to request deletion of your personal data
-
Right to obtain a copy of the personal data you previously shared with us
-
Right to opt out of the processing of your personal data if it is used for targeted advertising, the sale of personal data, or profiling in furtherance of decisions that product legal or similarly significant effects (‘profiling’)
We sell personal data to third parties or process personal data for targeted advertising. You can opt out from the selling of your personal data, targeted advertising, or profiling by disabling cookies in Cookie Preference Settings. To submit a request to exercise any of the other rights described above, please email lyhistory@gmail.com or submit a data subject access request.
If we decline to take action regarding your request and you wish to appeal our decision, please email us at lyhistory@gmail.com. Within sixty (60) days of receipt of an appeal, we will inform you in writing of any action taken or not taken in response to the appeal, including a written explanation of the reasons for the decisions.
Virginia Residents
Under the Virginia Consumer Data Protection Act (VCDPA):
‘Consumer’ means a natural person who is a resident of the Commonwealth acting only in an individual or household context. It does not include a natural person acting in a commercial or employment context.
‘Personal data’ means any information that is linked or reasonably linkable to an identified or identifiable natural person. ‘Personal data’ does not include de-identified data or publicly available information.
‘Sale of personal data’ means the exchange of personal data for monetary consideration.
If this definition ‘consumer’ applies to you, we must adhere to certain rights and obligations regarding your personal data.
Your rights with respect to your personal data
-
Right to be informed whether or not we are processing your personal data
-
Right to access your personal data
-
Right to correct inaccuracies in your personal data
-
Right to request deletion of your personal data
-
Right to obtain a copy of the personal data you previously shared with us
-
Right to opt out of the processing of your personal data if it is used for targeted advertising, the sale of personal data, or profiling in furtherance of decisions that produce legal or similarly significant effects (‘profiling’)
We sell personal data to third parties or process personal data for targeted advertising. Please see the following section to find out how your can opt out from further selling or sharing of your personal data for targeted advertising or profiling purposes.
Exercise your rights provided under the Virginia VCDPA
You can opt out from the selling of your personal data, targeted advertising, or profiling by disabling cookies in Cookie Preference Settings. You may contact us by email at lyhistory@gmail.com or submit a data subject access request.
If you are using an authorised agent to exercise your rights, we may deny a request if the authorised agent does not submit proof that they have been validly authorised to act on your behalf.
Verification process
We may request that you provide additional information reasonably necessary to verify you and your consumer’s request. If you submit the request through an authorised agent, we may need to collect additional information to verify your identity before processing your request.
Upon receiving your request, we will respond without undue delay, but in all cases, within forty-five (45) days of receipt. The response period may be extended once by forty-five (45) additional days when reasonably necessary. We will inform you of any such extension within the initial 45-day response period, together with the reason for the extension.
Right to appeal
If we decline to take action regarding your request, we will inform you of our decision and reasoning behind it. If you wish to appeal our decision, please email us at lyhistory@gmail.com. Within sixty (60) days of receipt of an appeal, we will inform you in writing of any action taken or not taken in response to the appeal, including a written explanation of the reasons for the decisions. If your appeal if denied, you may contact the Attorney General to submit a complaint.
12. DO WE MAKE UPDATES TO THIS NOTICE?
In Short: Yes, we will update this notice as necessary to stay compliant with relevant laws.
We may update this privacy notice from time to time. The updated version will be indicated by an updated ‘Revised’ date and the updated version will be effective as soon as it is accessible. If we make material changes to this privacy notice, we may notify you either by prominently posting a notice of such changes or by directly sending you a notification. We encourage you to review this privacy notice frequently to be informed of how we are protecting your information.
13. HOW CAN YOU CONTACT US ABOUT THIS NOTICE?
If you have questions or comments about this notice, you may email us at lyhistory@gmail.com or contact us by post at:
Liu Yue
__________
Singapore, Singapore
Singapore
14. HOW CAN YOU REVIEW, UPDATE, OR DELETE THE DATA WE COLLECT FROM YOU?
Based on the applicable laws of your country, you may have the right to request access to the personal information we collect from you, change that information, or delete it. To request to review, update, or delete your personal information, please fill out and submit a data subject access request.
]]>
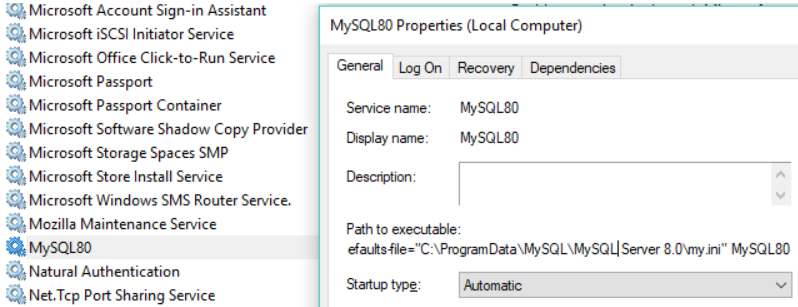
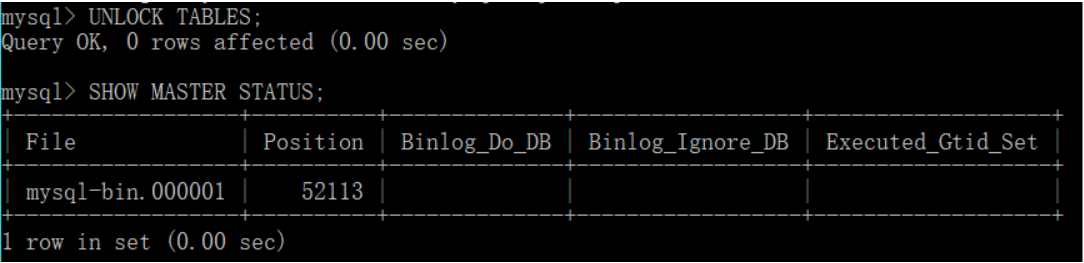
 Slave: mysql8.0
Slave: mysql8.0



 open storm ui portal and click on the port number to debug, obviously the full link of it isn’t correct, so I just extract the relative path and check it manually
open storm ui portal and click on the port number to debug, obviously the full link of it isn’t correct, so I just extract the relative path and check it manually
 check the log content
vim /apache-storm-1.2.2/logs/workers-artifacts/wordcount-1-1558059690/6702/worker.log
then I found an exception ::Error on initialization of server mk-worker
check the log content
vim /apache-storm-1.2.2/logs/workers-artifacts/wordcount-1-1558059690/6702/worker.log
then I found an exception ::Error on initialization of server mk-worker
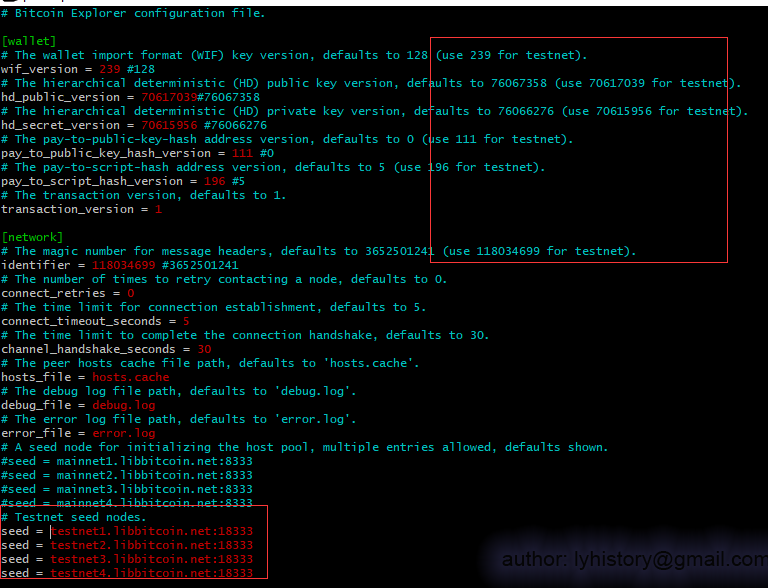 3> Python
pip install python-bitcoinrpc
https://github.com/jgarzik/python-bitcoinrpc
bip32utils
https://github.com/lyndsysimon/bip32utils
4> Others
BTC-Fiat exchange rate API
https://blockchain.info/tobtc?currency=CNY&value=1
BTC transaction fees API
https://bitcoinfees.21.co/api
3> Python
pip install python-bitcoinrpc
https://github.com/jgarzik/python-bitcoinrpc
bip32utils
https://github.com/lyndsysimon/bip32utils
4> Others
BTC-Fiat exchange rate API
https://blockchain.info/tobtc?currency=CNY&value=1
BTC transaction fees API
https://bitcoinfees.21.co/api The website app uses xpub(m/44’/1’/0’/0)[tpubDFCmqNxHDiBWw9e8XUEhkHqcw1i4drCe2mwwpR83eA2Arfmq8hJkUeVYY7hYaQWEo4HZDQ86FiRYj8Lr3e9UT8bYi7yLvbNbXgqyJeqLYii] for user topup address generation;
The scheduler service uses xprv(m/44’/1’/0’/0)[tprv8iWjgxv35LVr3gcLdpa7LtBWMzC8UX1jTUMAXu5kDtDn2BX4WJVAJ9sgMzFjuoiWjhUdamEeB7sxPS6uzkmcEAAXNAevuaRWYQFMwX713mP] to aggregate and transfer btc from topup address to internal address(semi-cold and cold wallet, in this demo, we simply aggregate and transfer into addr(m/44’/1’/1’/0/0)[muz1awk6YXQkP29dt1tdRpBTonmqAqwdst]).
The website app uses xpub(m/44’/1’/0’/0)[tpubDFCmqNxHDiBWw9e8XUEhkHqcw1i4drCe2mwwpR83eA2Arfmq8hJkUeVYY7hYaQWEo4HZDQ86FiRYj8Lr3e9UT8bYi7yLvbNbXgqyJeqLYii] for user topup address generation;
The scheduler service uses xprv(m/44’/1’/0’/0)[tprv8iWjgxv35LVr3gcLdpa7LtBWMzC8UX1jTUMAXu5kDtDn2BX4WJVAJ9sgMzFjuoiWjhUdamEeB7sxPS6uzkmcEAAXNAevuaRWYQFMwX713mP] to aggregate and transfer btc from topup address to internal address(semi-cold and cold wallet, in this demo, we simply aggregate and transfer into addr(m/44’/1’/1’/0/0)[muz1awk6YXQkP29dt1tdRpBTonmqAqwdst]).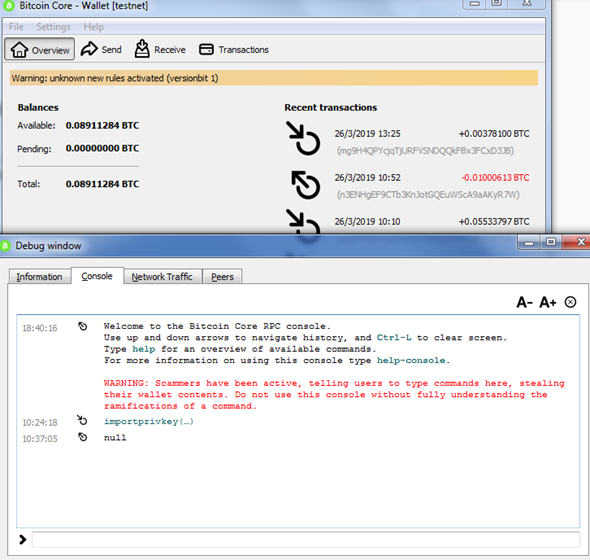 4> host btc node demon
vim ~/.bitcoin/bitcoin.conf
4> host btc node demon
vim ~/.bitcoin/bitcoin.conf
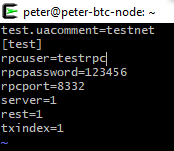 bitcoind -testnet -printtoconsole/-daemon
And then import our internal account:
bitcoin-cli -testnet importprivkey cVHBtHK7kzze7yqF5En4Psbw2ZZdUEJ8jF4KAMXhLpuSwUf4fZAU “internal0” true
bitcoind -testnet -printtoconsole/-daemon
And then import our internal account:
bitcoin-cli -testnet importprivkey cVHBtHK7kzze7yqF5En4Psbw2ZZdUEJ8jF4KAMXhLpuSwUf4fZAU “internal0” true
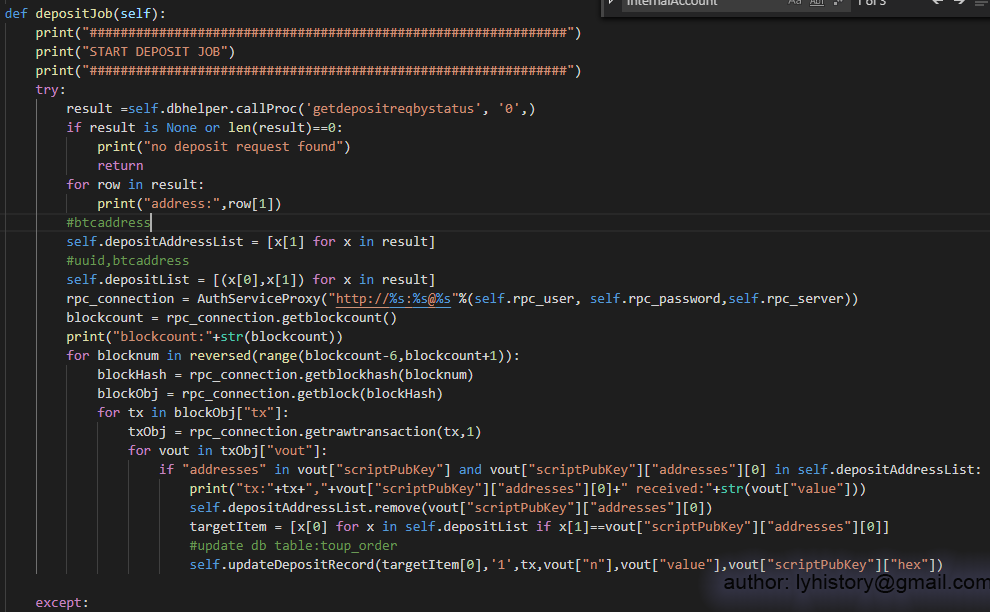
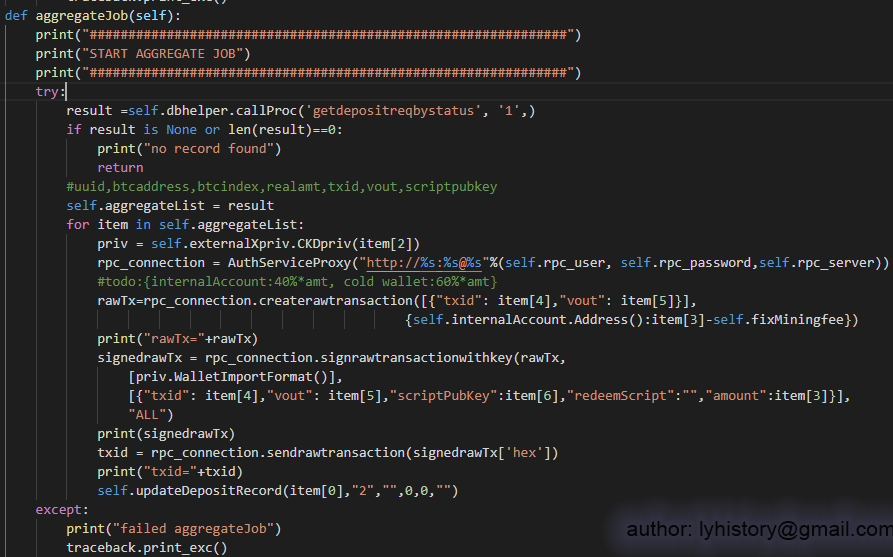
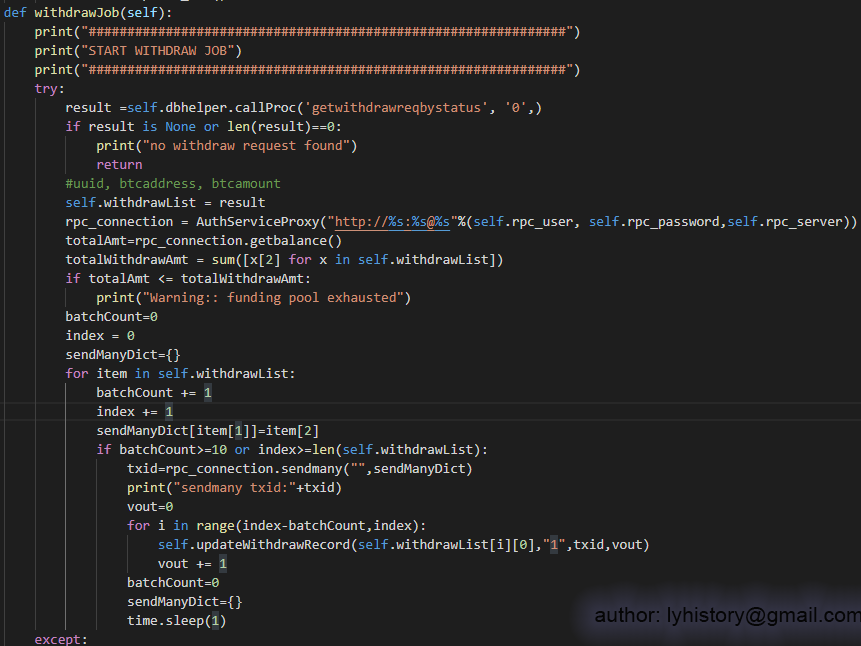 Note:For withdraw btc from semi-cold wallet, I find it’s not feasible to use signtransactionwithkey, because that requires knowledge of all the utxo of the semi-cold wallet, and keep track of all the utxo requires lots of work and sophisticated design, so in this demo, I choose an easier way, as we already importprivkey of the internal account to bitcoin core upfront, just straightforward use sendmany to transfer BTC, so the bitcoin core wallet will do the dirty work for us
Note:For withdraw btc from semi-cold wallet, I find it’s not feasible to use signtransactionwithkey, because that requires knowledge of all the utxo of the semi-cold wallet, and keep track of all the utxo requires lots of work and sophisticated design, so in this demo, I choose an easier way, as we already importprivkey of the internal account to bitcoin core upfront, just straightforward use sendmany to transfer BTC, so the bitcoin core wallet will do the dirty work for us