《Kafka Stream》调研:一种轻量级流计算模式 https://yq.aliyun.com/articles/58382 Kafka Streams - Not Looking at Facebook https://timothyrenner.github.io/engineering/2016/08/11/kafka-streams-not-looking-at-facebook.html https://cloud.tencent.com/developer/ask/203192 https://www.codota.com/code/java/methods/org.apache.kafka.streams.kstream.KStream/groupBy http://www.jasongj.com/kafka/kafka_stream/
# 1. Architecture
https://kafka.apache.org/22/documentation/streams/architecture
Stream Partitions and Tasks
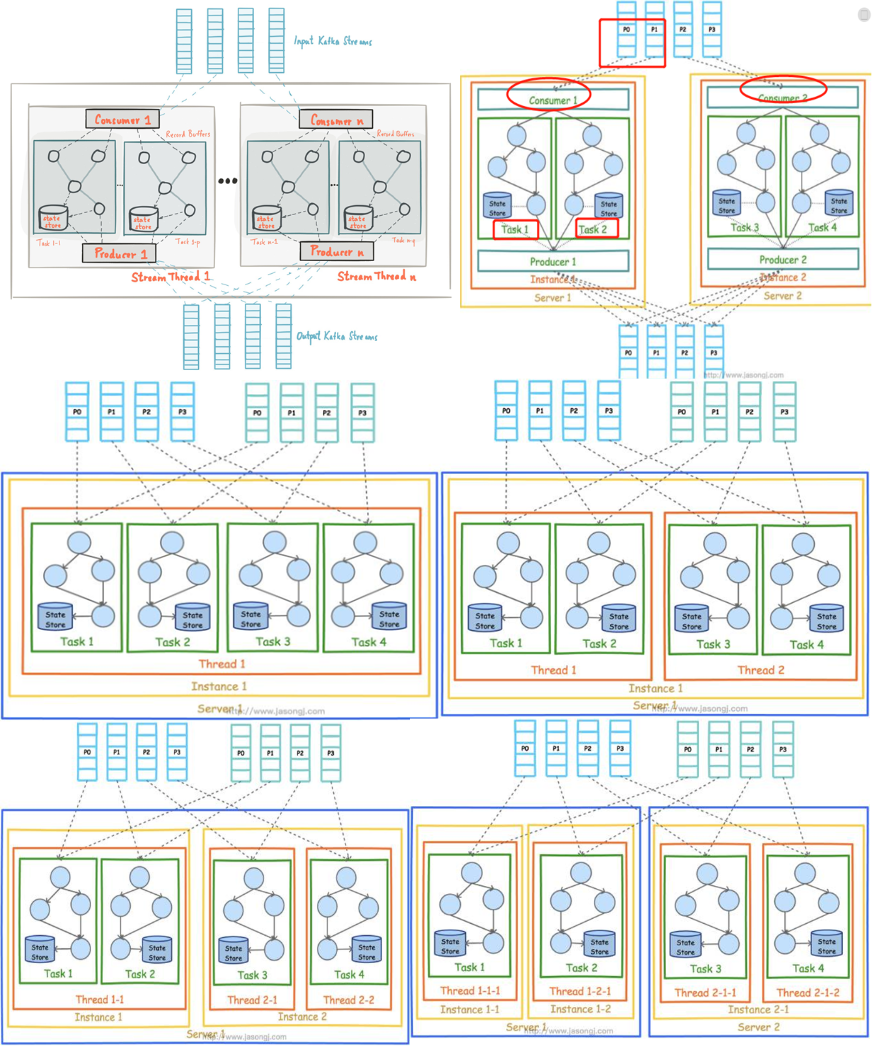
Task(consumer, run topology over one or more partition), Thread can run one or multiple Task, Instance ID is consumer group ID,multiple instance with same group ID belong to one consumer group, 4 partition, 1 instance will start 4 task, (thread quantity is defined by code), now start a new instance, join the consumer group, relocate 4 partition, each instance got 2 partition, so each instance run 2 task Kafka Stream的并行模型中,最小粒度为Task,而每个Task包含一个特定子Topology的所有Processor。因此每个Task所执行的代码完全一样,唯一的不同在于所处理的数据集互补。这一点跟Storm的Topology完全不一样。Storm的Topology的每一个Task只包含一个Spout或Bolt的实例。因此Storm的一个Topology内的不同Task之间需要通过网络通信传递数据,而Kafka Stream的Task包含了完整的子Topology,所以Task之间不需要传递数据,也就不需要网络通信。这一点降低了系统复杂度,也提高了处理效率。
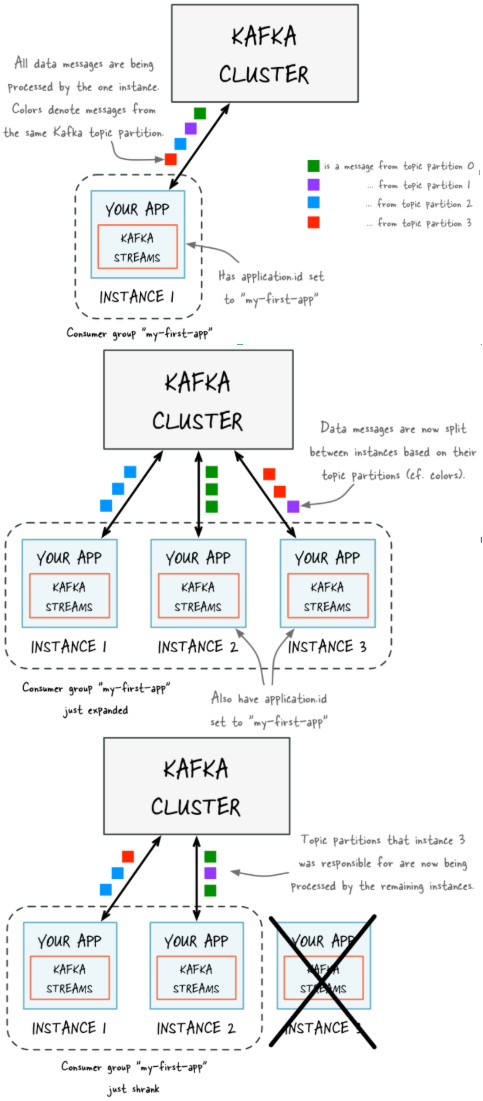
如果某个Stream的输入Topic有多个(比如2个Topic,1个Partition数为4,另一个Partition数为3),则总的Task数等于Partition数最多的那个Topic的Partition数(max(4,3)=4)。这是因为Kafka Stream使用了Consumer的Rebalance机制,每个Partition对应一个Task。 Kafka Stream可被嵌入任意Java应用(理论上基于JVM的应用都可以)中,下图展示了在同一台机器的不同进程中同时启动同一Kafka Stream应用时的并行模型。注意,这里要保证两个进程的StreamsConfig.APPLICATION_ID_CONFIG完全一样。因为Kafka Stream将APPLICATION_ID_CONFI作为隐式启动的Consumer的Group ID。只有保证APPLICATION_ID_CONFI相同,才能保证这两个进程的Consumer属于同一个Group,从而可以通过Consumer Rebalance机制拿到互补的数据集。 https://yq.aliyun.com/articles/222900?spm=5176.10695662.1996646101.searchclickresult.13d4446d1xNbRq
图二:上图中的Consumer和Producer并不需要开发者在应用中显示实例化,而是由Kafka Stream根据参数隐式实例化和管理,从而降低了使用门槛。开发者只需要专注于开发核心业务逻辑,也即上图中Task内的部分。
图三: 两图都是同一个机器,都只有一个instance,都是4个task,分别运行在一个thread和2个thread
图四:左图一台机器,两个instance,4个task分别属于两个instance;而右图是部署两台机器上
Threading Model
Kafka Streams work allocation https://medium.com/@andy.bryant/kafka-streams-work-allocation-4f31c24753cc
https://www.slideshare.net/ConfluentInc/robust-operations-of-kafka-streams

Local State Stores
Fault Tolerance
# 2. Concepts
https://kafka.apache.org/22/documentation/streams/core-concepts Task ⇔ 一个consumer可以包含多个task,consumer本身是隐式管理 Task vs thread https://stackoverflow.com/questions/48106568/kafka-streams-thread-number
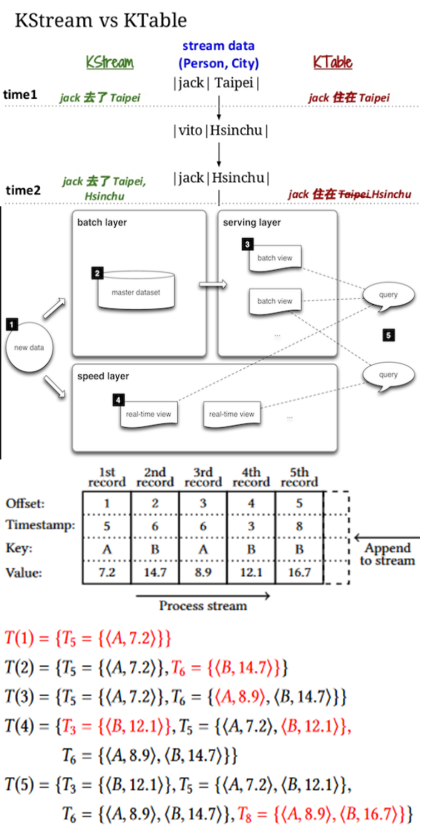
Kstream ktable
https://www.slideshare.net/vitojeng/streaming-process-with-kafka-connect-and-kafka-streams-80721215 Stream Processing Topology Kafka Streams DSL Processor API Time Event time Processing time Ingestion time Stream time, wall-clock time Aggregation
Windowing Late arriving records Duality of Stream and table
States
Processing guarantees
Lambda Architecture http://lambda-architecture.net/
Out-of-order handling For stateless operations, out-of-order data will not impact processing logic since only one record is considered at a time, without looking into the history of past processed records; for stateful operations such as aggregations and joins, however, out-of-order data could cause the processing logic to be incorrect.
Physical order = offset order Logical order = timestamp order https://dl.acm.org/citation.cfm?id=3242155
Since timestamps, in contrast tooffsets, are not necessarily unique, we use the record offsetas “tie breaker” [15] to derive a logical order that isstrictandtotalover all records. In theKafka Streams DSL, there are two first-class abstractions:aKStreamand aKTable. AKStreamis an abstraction ofa record stream, while a KTable is an abstraction of both a table changelog stream and its corresponding materializedtables in the Dual Streaming Model. In addition, users of theDSL can query a KTable’s materialized state in real-time. Whenever a record is received from the source Kafka topics,it will be processed immediately by traversing through allthe connected operators specified in the Kafka Streams DSL until it has been materialized to some result KTable, or writ-ten back to a sink Kafka topic. During the processing, therecord’s timestamp will be maintained/updated according toeach operator’s semantics as defined in Section 4 Handling out-of-order records injoins requires several strategies. For stream-table joins, out-of-order records do not require special handling. However,out-of-order table updates could yield incorrect join results, ifnot treated properly. Assume that the table update in Figure 6from⟨A,a,2⟩to⟨A,a′,5⟩is delayed. Stream record⟨A,α′,6⟩would join with the first table version and incorrectly emit⟨A,α′▷◁a,6⟩. To handle this case, it is required to buffer record stream input record in the stream-table join operatorand re-trigger the join computation for late table updates.Thus, if a late table update occurs, corresponding updaterecords are sent downstream to “overwrite” previously emit-ted join records. Note, that the result of stream-table joinsis not a record stream but a regular data stream because itmight contain update records.
Record stream , normal data stream Time window , session window
https://kafka.apache.org/22/documentation/streams/developer-guide/
# 3. Basic usage
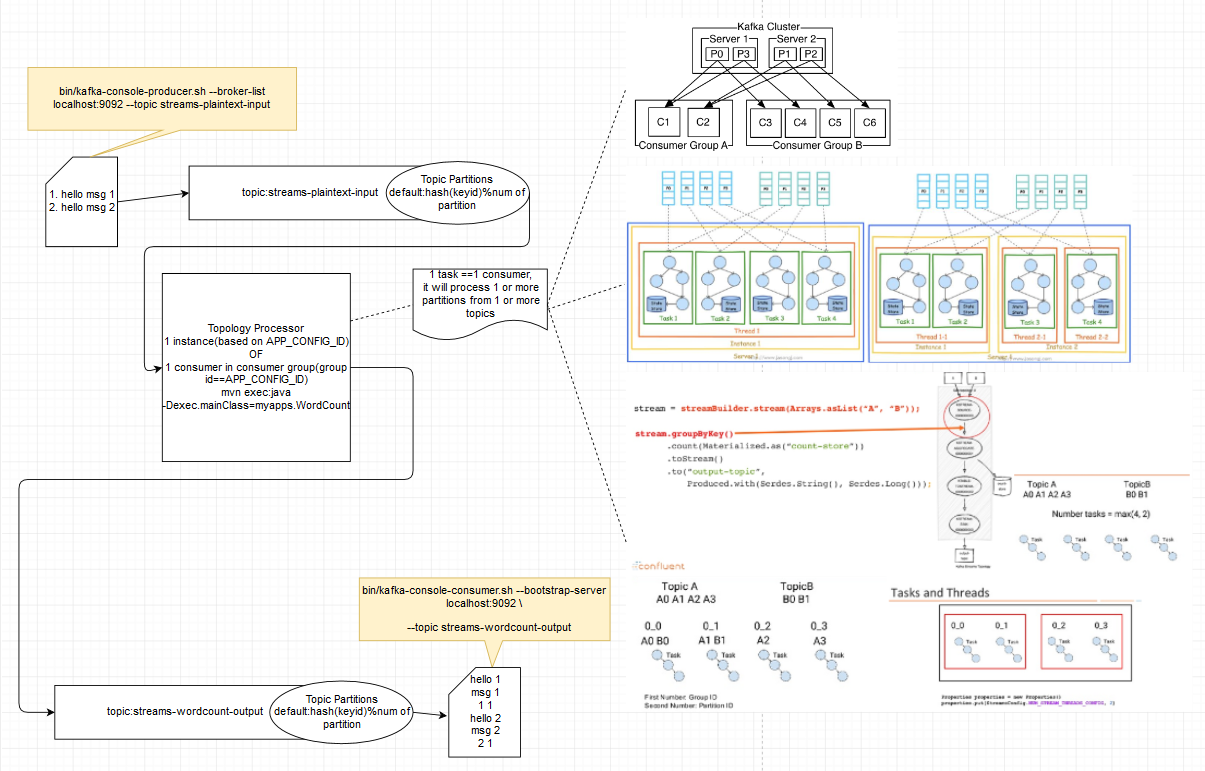

mvn clean package
mvn exec:java -Dexec.mainClass=myapps.WordCount
bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-plaintext-input
bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-wordcount-output \
--config cleanup.policy=compact
bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe
bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic my_topic_name
bin/kafka-run-class.sh myapps.WordCount
/home/test/workspace/kafka/kafka_2.12-2.2.0/bin/kafka-run-class.sh myapps.WordCount
mvn exec:java -Dexec.mainClass=myapps.WordCount
bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
https://kafka.apache.org/22/documentation/streams/tutorial https://github.com/apache/kafka/tree/2.2/streams/examples
https://www.draw.io/#G13TFIxfbM3VN9R5Pg7nFwNguUUNUXKChO
?# Windowed
bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-plaintext-input
bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-windowed-wordcount-output \
--config cleanup.policy=compact
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-windowed-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
# 4. kafka stream VS storm (wordcount)
Kafka wordcount是stateful operation,因为每个task/consumer完全独立跑完整的topology,每个consumer处理某一个partition,所以要借助data store来存储ktable“中间”状态,data store也是多个consumer/task“协作”的结果 而storm wordcount是stateless operation,因为一个topology是分成sprout,bolt,每个sprout/bolt会开启一个或多个task,这些task在work process中执行,这些work process可能位于不同的机器,所以第一步是split bolt,然后将这些单词进行partition发送至相应的tasks,比如the这个单词会一直发送到某个特定的task进行count,所以对于最后一步count是很简单的,不需要reduce操作,每个count task都只统计相应的单词,互相之间没有重叠,不像kafka那样因为partition比较早,所以不同的parttion之间是有重叠的单词的,所以必须借助一个第三者存储来统计
# 5. Advance
Ktables vs global ktables Kafka has several features for reducing the need to move data on startup
- Standby Replicas
- Disk Checkpoints
- Compacted topics Command and Query Responsibility Segregation (CQRS) pattern [with event sourcing]

Using an event-streaming approach, we can materialize the data locally via the Kafka Streams API. We define a query for the data in our grid: “select * from orders, payments, customers where…” and Kafka Streams executes it, stores it locally, keeps it up to date. This ensures highly available should the worst happen and your service fails unexpectedly (this approach is discussed in more detail here). To combat the challenges of being stateful, Kafka ships with a range of features to make the storage, movement, and retention of state practical: notably standby replicas and disk checkpointsto mitigate the need for complete rebuilds, and compacted topics to reduce the size of datasets that need to be moved.
State store, global or local? Ktable, globalktable
Kafka Stream有一些关键东西没有解决,例如在join场景中,需要保证来源2个Topic数据Shard个数必须是一定的,因为本身做不到MapJoin等技术