声明 本文基于网上一些教程资料总结的,知识都是公开的,没有认真参阅计算机专业文献,难免有疏漏,我尝试着复现IO BIO NIO 多路复用 netty的发展历史,并尝试融会贯通了基于TCP/IP协议传输控制层和应用层的抽象--socket“协议”;
# 网卡IO操作
首先IO分为磁盘IO,网卡IO,鼠标键盘IO等各种IO设备,为什么学习netty或者基于TCP协议的各种上层“协议”或抽象或具体实现需要学习IO?
其一:主要是因为通信的数据流是要走网卡的,不知道IO的处理就无法了解这些基于TCP协议的框架的设计思想;
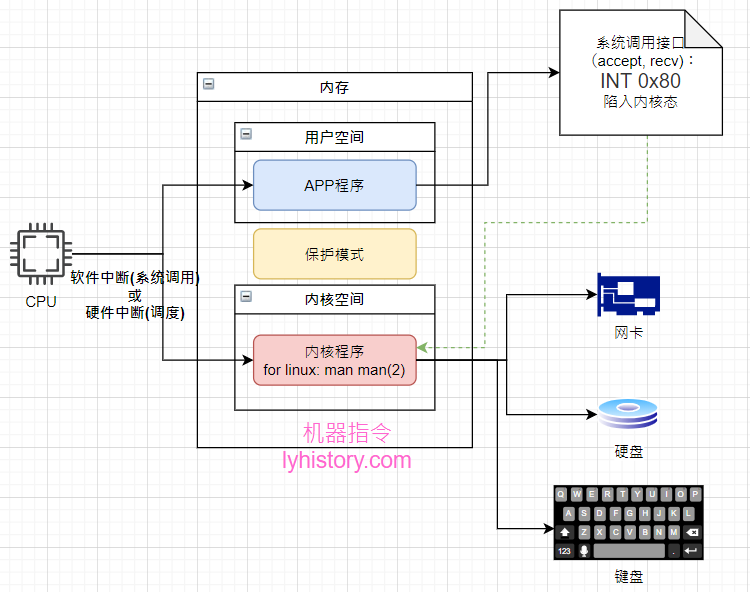
其二:因为IO的相关处理是内核做的,属于系统调用,我们写的应用层的应用在跟用户交互的过程中需要获取客户端连接以及读取连接发送的数据流的时候,都需要转到内核态进行系统调用才能获取网卡IO的数据,至于为啥我们用户程序不可以直接操作这些IO,是因为正常的情况下我们不会重复造轮子写驱动!另外用户空间和内核空间是保护模式隔离开的,用户程序并不可以直接调用内核的程序,系统调用是唯一的方式,由于用户程序不能直接调用内核程序,所以系统调用不是函数调用,系统调用的方式是用户程序设置好参数,然后故意产生一个异常即INT 0x80软件中断,CPU就会切换到内核空间执行内核程序;
要通过 TCP 连接发送出去的数据都先拷贝到 send buffer,可能是从用户空间进程的 app buffer 拷入的,也可能是从内核的 kernel buffer 拷入的,拷入的过程是通过 send() 函数完成的,由于也可以使用 write() 函数写入数据,所以也把这个过程称为写数据,相应的 send buffer 也就有了别称 write buffer。
最终数据是通过网卡流出去的,所以 send buffer 中的数据需要拷贝到网卡中。由于一端是内存,一端是网卡设备,可以直接使用 DMA 的方式进行拷贝,无需 CPU 的参与。也就是说,send buffer 中的数据通过 DMA 的方式拷贝到网卡中并通过网络传输给 TCP 连接的另一端。
当通过 TCP 连接接收数据时,数据肯定是先通过网卡流入的,然后同样通过 DMA 的方式拷贝到 recv buffer 中,再通过 recv() 函数将数据从 recv buffer 拷入到用户空间进程的 app buffer 中。
首先还是要复习下计算机组成原理的基本知识,
机器加电启动,引导程序从磁盘将内核程序装载到受保护的内存区域,假设现在只有一个cpu,cpu执行内核程序,怎么切换执行用户程序呢?
中断是个重要的概念,电脑运行中有两种中断:硬件中断和软件中断;
顾名思义,硬件中断是硬件产生的,比如鼠标键盘硬盘等,比如鼠标移动、键盘输入等操作引起的I/O中断,还有一种特殊的中断是由晶振引起的中断叫做时钟中断,大概意思是CPU大部分时间都是蒙头按顺序执行指令,假如有一个CPU,多个程序,怎么调度呢?就是通过晶振按周期产生时钟中断,然后CPU开始保存现场,寄存器压栈,然后CPU开始查中断向量表然后跳到相应的地址,比如执行系统调用的调度程序;
而软件中断自然是软件产生的,软件通过系统调用接口,INT 0x80产生软件中断,陷入到内核态,保存现场,通过系统调用号在系统调用表获取相应的服务例程,调用系统调用例程,最后使用特定指令从系统调用返回用户态; 由于通过软件中断的方式发起系统调用性能很差,所以比较新的cpu和内核支持使用sysenter, syscall等新的方式;
简单来说,用户程序和内核的交互是主要是通过系统调用实现的,系统调用可以是基于软件中断或者其他方式实现的,所以系统调用并不等同软件中断,而内核与外部设备之间主要是通过硬件中断交互;
“你可以把内核看做是不断对请求进行响应的服务器,这些请求可能来自在CPU上执行的进程,也可能来自发出中断的外部设备。老板的请求相当于中断,而顾客的请求相当于用户态进程发出的系统调用”
《深入理解Linux内核-第五章》
在查阅资料的过程中,发现很多地方概念还是要理清楚,我前面写道中断分为硬件中断和软件中断实际不是很准确,应该是说分为“硬中断”和“软中断”,把“件”字要去掉,原因是:
中断又常被分为同步中断和异步中断:
同步中断又称为异常,通常说的就是通过INT 0x80引发的异常,意思是基于这种INT 0x80异常实现的系统调用称之为软件中断,当陷入内核态后,内核代码运行在进程上下文中,所以注意到对于系统调用来说,是切换到同进程的内核态上下文,结束后会回到同进程的用户态上下文;
异步中断通常简称中断,可以看出这才是真正的中断,是由I/O设备产生的中断,可以看到这是硬件中断,它会触发中断服务例程的执行,并往往伴随着软中断(注意不是软件中断)的执行,此时,CPU运行在中断上下文中,软中断和系统调用(不管是基于异常的软件中断还是新的syscall sysenter)一样,都是CPU停止掉当前用户态上下文,保存工作现场,然后陷入到内核态继续工作,二者的唯一区别是系统调用是切换到同进程的内核态上下文,而软中断是则是切换到了另外一个内核进程ksoftirqd上;
我们这里主要是关注系统调用,就拿软件中断INT 0x80举例,草图如下:
开始正式讲解BIO NIO 多路复用
# BIO
我们首先采用的是最基本的
java.io java.net.ServerSocket java.net.Socket
代码逻辑是
java程序启动,肯定有个主线程,然后当然一般还有其他的gc线程等辅助线程;
然后主线程中新建一个ServerSocket,监听某个端口,三部曲:socket、bind、listen(查看系统调用:man 2 socket/bind/listen/accept),然后死循环daemon开始监听新客户端连接,accept会阻塞线程,所以每次当获取一个新的客户端连接比如11,就new一个新的线程(也是通过系统调用fork或clone获得的轻量级进程),新开的这个线程负责recv 11这个客户端的数据流,当然recv也会阻塞等待;
注意: 如果我们代码写的更简单,可以完全只用一个主线程来处理accept和recv,但是缺陷就是,如果accept之后走到了11的recv,而11一直没有数据发送过来,就一直阻塞,无法走回到accept去获取新的连接! 简单的解决办法就是,当主线程来处accept之后就会返回/产生一个新的线程负责数据传输;
负责跟客户端三次握手以及分手的可以是主线程或者一个单独的线程: which socket is used for the third stage of TCP three-way handshake? (opens new window)
还需要注意的是,IO读写之后数据通常会hand off传给其他的工作线程进行业务处理,此时要注意线程安全问题 multithreading with non-blocking sockets (opens new window)
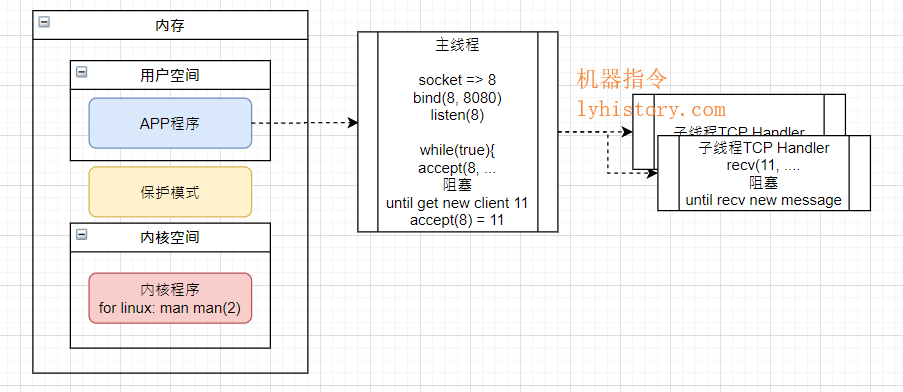
优点:一个连接一个线程,可以接受很多连接,连接数只是受backlog限制;
缺点:一个连接一个线程,也意味着内存浪费;另外每次accept和recv调用都是一次系统调用,意味着每次都要进行用户态内核态的切换,意味着cpu调度的消耗;
# NIO
随着内核发展:Socket引入SOCK_NONBLOCK,IO读取可以得到改善;
NIO有两层含义,从操作系统级别,即内核的角度,就是引入的non blocking socket,而从java的应用层角度,就是JDK1.7这些新版本基于新内核的new IO;
java.nio.ByteBuffer java.nio.channels
代码逻辑对照BIO时代的更改就是,accept可以不再阻塞了,因为可以设置超时返回-1,代表没有新连接,然后同样recv也不再阻塞,可以返回-1代表没有新的输入,这样就完全一个主线程即可做完所有事情,不再需要新开线程,看起来挺美;
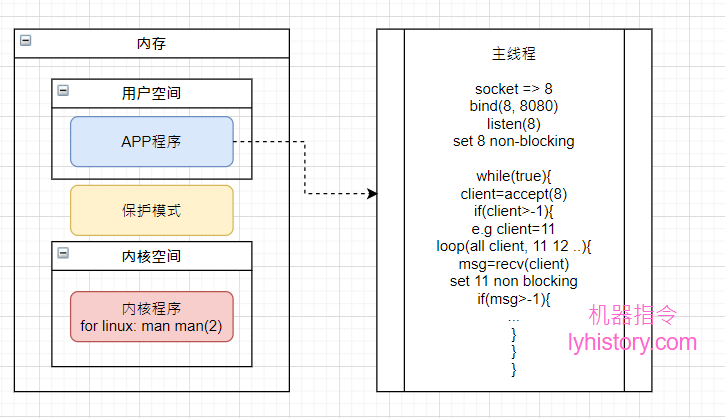
优点:不需要多线程,单线程即可处理
缺点:C10k problem,一万个连接,不管有没有新的信息进来,每次循环都要进行1万次的系统调用,这个不是普通的用户空间循环,而是每次都要陷入内核态的循环,O(N)复杂度且浪费资源,其实并没有解决BIO的问题,纯粹减少了用户态的内存浪费;
# 多路复用 Multiplexing
引入同步多路复用器synchronous I/O multiplexing,selector:
java.nio.Selector (对应到具体操作系统的可能是select poll epoll)
man 2 select/poll
select和poll是一类,epoll是另一类,下面分类讲解
# select poll
代码逻辑更改大概是,select或者poll一次将所有文件描述符传给内核,不需要遍历传递,第一次是传server socket 8,后面假设有新的连接需要监听的新的文件描述符(意思是new 新的socket来监听新端口,产生新的文件描述符,比如起了http服务)比如11,就传(8,11)
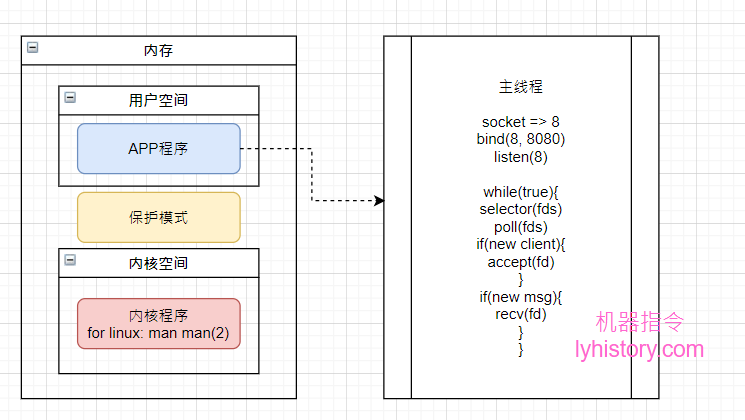
优点:通过一次系统调用,把所有文件描述符传递给内核,然后内核再进行遍历,这种遍历跟上面的不同,完全是在内核态进行;
缺点:每次循环都要重复传递之前传递过的文件描述符;而且每次内核都也要遍历所有文件描述符,这个涉及到软中断callback等深层知识,大概也是资源浪费;整个过程没有办法用到多核的优势,从用户态切换到内核态,都是同步操作,需要等待;
# epoll
man 2 epoll_create / epoll_ctl / epoll_wait
epoll引入了内核空间,当创建server socket的时候获得文件描述符8,然后epoll create为8开辟内核空间=>假设是fd88,然后在内核空间fd88中注册epoll ctl 8的accept操作,放入到interest list,当获取到新的连接比如11,将11的read操作也注册epoll ctl到内核空间fd88的interest list,此时interest list就有8 和 11,如果有新的连接或者11有新的输入流,其他的cpu就可以异步将相应的8或11放到ready list,然后用户空间只需要系统调用epoll wait就会获取到IO发生变化的文件描述符,否则就是超时返回-1,可以看到这里就发挥了多核的优势,可以异步处理;
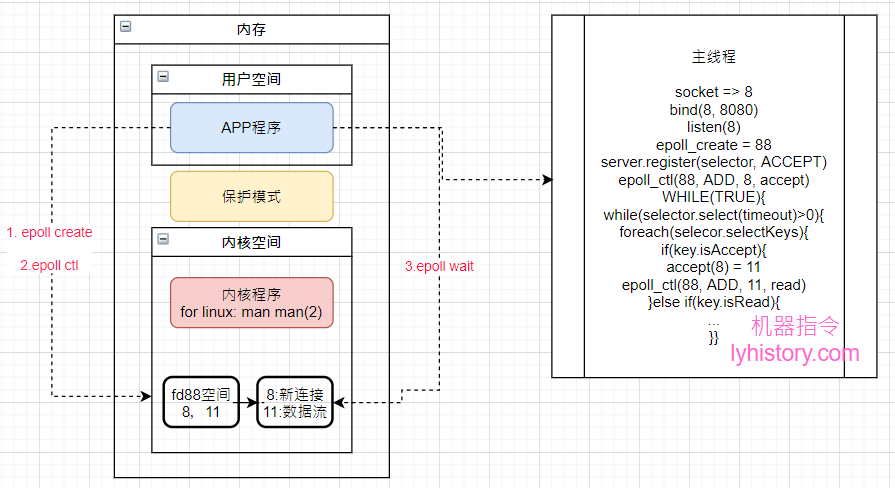
图中,如果是epoll,server.register就是系统调用epoll ctl,selector.select(timeout)就是系统调用epoll wait,可以看到基本解决了前面谈到的所有问题;
唯一的可以改进之处在于,一个主线程既要处理连接又要处理数据流,因为都是同步IO模型,假设某个连接有大量的数据请求,会影响到其他连接,所以改进就是剥离开,一个线程只负责处理连接,新开其他线程处理连接数据流,这个思路就是下面讲到的netty的框架设计模型;
# 基于epoll的框架和产品:netty redis haproxy等
# netty
netty vs jetty
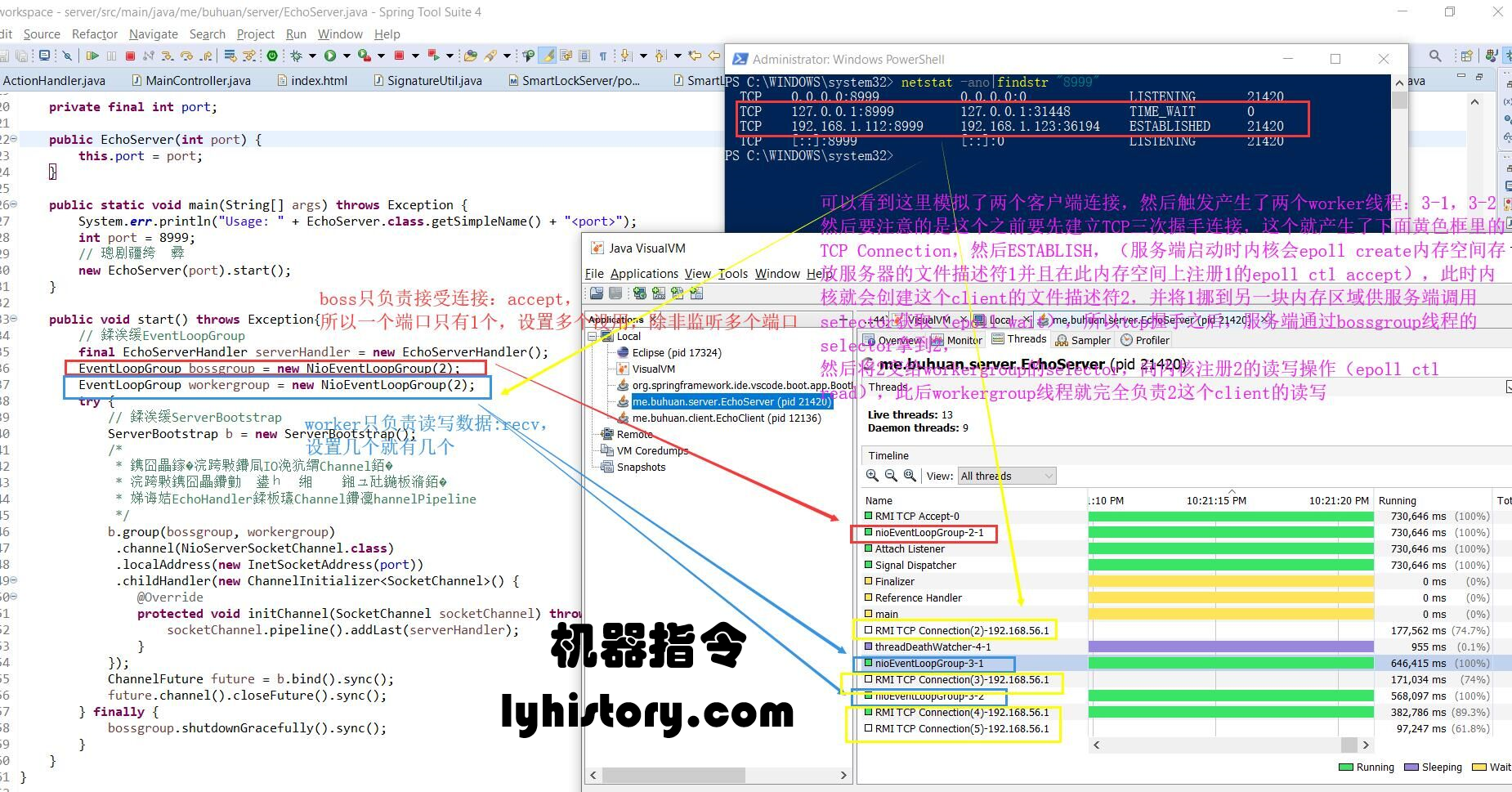
tools: \jdk1.8\bin\jvisualvm.exe
可以看到,bossgroup就是前面说的负责处理连接的线程组(实际上一个端口只会有一个线程,设置多个是无效的),workergroup就是负责处理连接数据流的线程组,详细图解:
服务端启动时系统调用内核会epoll create内核内存空间,然后在其上调用epoll ctl注册server socket fd=1的accept,注册到interest list;
客户端发起tcp连接,会产生图中黄色的TCP connection线程,内核创建新client的fd=2,并将server socket fd从interest list挪到ready list,然后服务端通过bossgroup线程的selector(epoll wait)获取到fd=2,然后accept,此时握手成功,状态变成established,注意accept之后就立马epoll ctl注册fd=2的read操作,同样是放入到interest list,如果fd=2上有数据流进来,就会挪到ready list, 要注意到数据的读写是由产生的两个worker线程:3-1,3-2来负责的;
从JAVA 1.4起,JDK支持NIO(New IO, 采用 os non blocking 的工作方式), 使用JDK原生的API开发NIO比较复杂,需要理解 Selector、Channel、ByteBuffer三大组件,所以有了mina,netty的封装,很多产品dubbo、spark、zookeeper、elasticSearch都使用netty作为底层通信IO框架支持;
多提一个角度,常常有比较tomcat和netty,说netty的性能远远超过tomcat,原因大致是因为协议,tomcat走http,netty走tcp,这是一方面,另一个方面就是虽然两者都支持NIO,都是采用jdk的nio,但是由于tomcat受制于servlet的规范,不能充分发挥NIO的优势,莫非这就是tomcat8以上推高性能apr的原因(随便猜测一下)?通过前面的分析也可以知道,上层的应用程序本质受制于内核的进化,即使内核进化的很优化,应用程序没有实现好同样无法发挥优势的;
# redis
redis支持多种多路I/O复用机制,包括 select、poll、epoll、kqueue等,其中epoll是linux系统下性能最好的一种机制
本文发布公众号专辑软件开发 (opens new window)
辅助工具:
strace -ff -o prefix
jdk工具:jvisualvm
https://www.xiaolincoding.com/os/8_network_system/selete_poll_epoll.html#%E5%A4%9A%E7%BA%BF%E7%A8%8B%E6%A8%A1%E5%9E%8B
图解通用网络IO底层原理、Socket、epoll、用户态内核态······ (opens new window)
Socket和TCP连接过程解析 (opens new window) Socket 系统调用深入研究(TCP协议的整个通信过程) (opens new window)