回目录 《分布式系统开发-从故障容错分布式系统到拜占庭容错分布式账本》
本文发布在 infoq:
分布式系统全景分析:从故障容错到拜占庭容错
https://www.infoq.cn/article/ihxufskmuc3ptlfyrryk
注意:
下面提到的节点根据上下文有不同的含义,说到zookeeper时主要是指注册在zookeeper的不同类型的znode,说到集群时是指集群的不同实例
谈到分布式系统就避免不了CAP理论,可用性、一致性、分区容错三者只能同时满足其中两个,可用性和一致性是我们经常提到的,分区容错可能很多人不太清楚, 其定义是“The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes”, 可见对于分布式系统来说,分区容错并不是一个可选性,如果系统在发送节点之间通信延迟或丢包的情况下就停止工作,就失去了分布式的意义, 多节点因为网络或自身故障引起通信延迟或丢包,从而导致系统分区,只能在一致性和可用性之间选一个,想要保持完全一致,对外服务就只能等待,有可能会服务超时;
对于单机系统来说就不存在上述多节点通信的问题,所以排除P,比如关系型数据库就是取了CA,高可用和强一致性,并且由事务支持延伸出ACID理论;
而在分布式系统实践中,CAP并不是真的非黑即白的不可同时共存,基于大量实践衍生出了BASE理论,从高可用到基本可用 Basically Available,从强一致到最终一致性Eventual Consistency,加上软状态 Soft State, 可见基本上是在追求一种平衡,对于一个系统来说,尤其是分布式系统,如果一直都无法保持一致,基本也是不堪用的了,所以一致性还是基本上都要追求的,只不过一致性根据强弱程度可以进一步细分;
思维比较缜密的读者对于eventual consistency可能会有疑问,这个最终一致性是在什么时间范围内达到一致,换句话说对于外部的client客户端来说,要到什么程度的eventual consistency才能对外提供服务? 这里不得不提另一个理论FLP,即分布式共识的不可能理论,跟CAP类似,但是从另外一个角度解读,包含三点safety, liveness, fault tolerance,刚才的问题就是关于liveness, 用来指示分布式系统内的各个节点必须在合理的时间内达成一致in bounded time,不能一直处于不一致的状态,否则不能够对外提供服务;
# 1.关于一致性
一致性的语义在不同的地方解释千差万别,从不同的角度看也有不同的含义,在谈到单机系统和分布式系统的时候,侧重点略有不同:
首先对于一个单机系统,一致性一般是强调在并发请求的情况下,该系统事务级别和会话级别下根据系统的设置表现出来的读写的一致或冲突,比如两个并发事务的读写冲突, 比如前面说的关系型数据库,不考虑主从数据库部署的情况下,单机部署,读写同一个数据库,根据ACID理论,一致性的表现是会根据数据库的隔离水平设置isolation level有所不同,有兴趣可以自己查阅<Isolation (database systems)>
对于分布式系统,一致性一般是指对于一个集群内部各个节点上面的相关数据保持同步;
本质上其实都是大同小异,只是说一个是宏观从集群角度看,一个是从微观的单机看,分布式系统当成一个整体看对外部系统来说就是一个大的“单机”系统;
分布式系统一致性的分类根据角度的不同有很多分类方式,比如根据强弱简单分为:
- 强一致性 strong consistency
- 最终一致性 eventual consistency
- 弱一致性 weak consistency
Types of Consistency • Consistency with other users: If two users query the database at the same time, will they see the same data? Traditional relational systems would generally try to ensure that they do, while non-relational databases often take a more relaxed stance. • Consistency within a single session: Does the data maintain some logical consistency within the context of a single database session? For instance, if we modify a row and then read it again, do we see our own update? • Consistency within a single request: Does an individual request return data that is internally coherent? For instance, when we read all the rows in a relational table, we are generally guaranteed to see the state of the table as it was at a moment in time. Modifications to the table that occurred after we began our query are not included. • Consistency with reality: Does the data correspond with the reality that the database is trying to reflect? For example, it’s not enough for a banking transaction to simply be consistent at the end of the transaction; it also has to correctly represent the actual account balances. Consistency at the expense of accuracy is not usually acceptable.
还有其他角度更细分的单调读一致性,单调写一致性,会话一致性,读后写一致性,写后读一致性,顺序一致性等, 我还看到有人根据协议进行划分:
- 留言/多播协议 gossip/multicast protocols,包括redis在内的很多集群都是采用gossip
- 共识协议 consensus protocols
为了澄清更多的概念,我引用这个分类方式文ref (opens new window)中的一段话
The former includes things like epidemic broadcast trees, bimodal multicast, SWIM, HyParView, and NeEM. These tend to be eventually consistent and/or stochastic. The latter, which I’ve described in more detail here, includes 2PC/3PC, Paxos, Raft, Zab, and chain replication. These tend to favor strong consistency over availability.
作者也很谨慎的用了tend to,需要说明的是,前者基本上是最终一致没有什么问题, 而后者就要分清上下文了,在传统的分布式系统上这个说法问题不大,因为传统的分布式共识算法是基于故障容错crash fault tolerance,前提是假设系统中只会存在故障节点(消息会丢失,重复), 而在区块链的世界中,共识算法是基于拜占庭容错Byzantine fault tolerance,前提是假设系统中存在恶意节点(会发送假消息),基本都是最终一致,而不是强一致,为了区分,故障容错又称作非拜占庭容错,下面会详细展开;
另外需要再指出一点,通过前面关系型数据库的例子可以看到一个系统的一致性不是固定死的,很多情况下一致性会根据系统的设置或系统的架构不同发生变化,在同一个系统中不同类型的数据也可能有着不同的表现; 单机系统都如此,分布式系统更是复杂,而对于区块链来说,一致性更加有着丰富的表现,比如比特币的6个确认,是中本聪基于泊松分布做的一种类似联合泊松分布的概率计算, 以全网千分之一的算力来做恶意节点得出6个确认之后可以忽略不计,当然随着单节点算力越高,需要的确认也随之增长。
补充:对分布式系统来说有两大难点: 1.guaranteed order of message 2.exactly-once delivery
首先说关于exactly once delivery语义
对于比如支付系统来说,肯定不想发生两种情况:丢失消息(支付方支付成功,收款方没有收到)和重复消息(支付方支付100,收款方收到200),所以要保证系统自始至终exactly once delivery某条消息; 这个语义要实现,前提一般是系统协议需要保证强一致,比如消息队列kafka的zab就是sequential consistency,来支持exactly once语义,这里是支持不是保证,只是说可以在一定条件下实现, 具体是否实现还得看具体业务项目中有没有遵照规则去实现; 因为kafka的sequential consistency,从字面来讲就是保证了消息的顺序性guaranteed order of message,具体请自行研究;
# 2.基于故障容错CFT(Crash fault tolerance或非拜占庭容错)的分布式系统
中心化系统有单点故障的风险,故障有两层含义,一个是自己发生故障,一个是遭受到攻击,所以引入多个节点来抵消单一节点的风险, 故障容错的假设是多节点中可能会存在故障节点,消息会丢失或重复,但是不会有发送假消息的恶意节点,因为都是部署在内网的可控节点;

在这种假设前提下,多个节点协同工作方式有两种思路:主备和一致性状态机
# 2.1 主备方案和一致性状态机
# 2.1.1 主备方案
最直接的办法是指定一个leader,只由leader单节点负责管理竞争资源,然后其他节点作为follower保存副本
- 一致性,客户端写入数据请求都是交由或转发给leader处理,所以单节点维护保持了数据写的一致,所有节点都会接受客户端的读请求;
- 排除单点故障,当某个follower发生故障,leader就将follower从自己的通讯录中剔除或拉黑,如果该follower再次重新恢复上线,leader会将其再加回通讯录;
现在出现两个问题:
1) follower转发写数据请求给leader,如果他们转发的请求互相有冲突呢,比如对同一个数据同时修改
2) 如何动态选出的leader并且当leader节点发送故障如何从follower中选出leader呢
这两个问题都要依赖共识算法解决,比如zookeeper的ZAP(ZooKeeper Atomic Broadcast)协议就是解决这个问题的:
第一个问题解决方法是2PC即两阶段提交协议:
leader直接或间接通过follower收到转发的写操作请求,都会按照FIFO顺序发送proposal给所有follower,如果收到半数以上的follower的ack响应,leader就会发送commit指令给所有follower(注意leader也是自己的follower);
第二个问题解决方法是:
每个节点启动后默认都是looking模式,当leader选出后,其他节点就立即变成follower模式,如果leader崩溃了,则跟followers的心跳连接失败,follower又会变回looking模式,然后leader崩溃后选举新leader原则是采用 “Use a best-effort leader election algorithm that will elect a leader with the latest history from a quorum of servers.”,具体后面算法讲解的leader恢复机制; 每次选举出新的leader都会有自己的标志,有的叫term有的叫epoch,主要是为了防止脑裂,比如挂掉的leader或者分区后的leader突然恢复连接,通过这个标志老leader可以知道自己已经过时了,然后转换成follower听从新的leader;
# 2.1.2 一致性状态机
首先状态机又称有限状态机是表示有限个状态以及在这些状态之间的转移和动作等行为的数学计算模型,所谓状态就是存储关于过去的信息,它反映从系统开始到现在时刻的输入变化, 从软件实现角度最简单的状态机就是大家经常用的switch了,常用在单机系统或者IOT的单机设备上,根据输入条件(event及当前状态)对数据做不同的状态切换, 但是这种处理有两个问题: 一方面switch的条件是一个,这里是两个,处理起来首先要嵌套会比较臃肿; 另一方面在相对复杂系统中有些地方还需要可以灵活自定义特殊处理; 所以一般是要将状态机对象抽象出来,实际上前面“主备方案”中提到的zookeeper本质也是一个状态机模型, 只不过是利用状态机的状态实现了主备方案,而很多分布式状态机也是基于zookeeper构建的,比如Spring Statemachine, 我们再挖掘其本质的话,所谓基于zookeeper的分布式状态机,不过就是将zookeeper作为服务端的客户端程序;
所以从这个角度上,基于zookeeper client api的curator api本身也实现了状态机,其基本逻辑是: 首先抽象出一个ConnectionStateManager,负责维护一个BlockingQueue事件队列,然后CuratorFrameworkImpl作为zookeeper的客户端利用跟服务端的连接情况获取当前连接状态, 并将其状态交由ConnectionStateManager处理,ConnectionStateManager会做几件事情: 1)根据当前状态和前一个状态做分析,并更新本地最新状态 2)notify阻塞在连接状态的线程(因为有些业务逻辑必须阻塞到连接到zookeeper才能展开) 3)发布新状态到事件队列,然后processEvents处理线程会依次获取队列中的事件,并回调用事先向CuratorFramework注册好的listeners 然后刚才说的自定义特殊处理的方式可以有: 1)可以直接继承listener接口,然后向前面的CuratorFramework注册 2)curator已经封装实现了很多接口,比如PathChildrenCache,因为zookeeper是采用推拉的架构,意思是zookeeper服务端会通知client端有nodechange或者datachange,但是具体的change内容还需要client端自己去获取, 因为curator封装了PathChildrenCache等功能类,他们向CuratorFramework注册好了自己的listeners,会在ConnectionStateManager回调的时候,去拉取节点具体变化,然后PathChildrenCache还维护了一个listener列表, 这有我们可以通过复写PathChildrenCache对外提供的listener完成更复杂的逻辑;
上面说的小例子是从一个切面看待基于zookeeper的状态机,而实际上zookeeper本身本质也算是个状态机,下面我们开始从协议的角度来谈不依赖于任何外部框架的基于共识算法的状态机;
而对于分布式系统,如何保证不同节点上的状态都是一致的,可以想到有几个因素:The State Machine Approach (opens new window) 每个节点的输入及对输入的执行顺序都是要保证一致的,返回给客户端的结果也应该是一致的;
在分布式系统上,这些都是依赖于共识算法实现的,一致性状态机原则上不需要选举leader节点来维护一致,不过实际产品很多还是引入了leader来降低一些问题的实现难度(leader维持输入执行顺序,follower复制顺序log即state machine replication), 但是跟前面的主备共识算法的侧重不同的是,主备思路是构建高可用的分布式主备系统,现在是为了构建分布式一致性状态机;
我们首先要从经典问题**“paxos岛兼职议会问题”**说起,这个故障问题的描述:
希腊岛屿Paxos上通过议会的方式来表决通过法律,议员们通过服务员传递纸条的方式交流信息,每个议员都将通过的法律记录在自己的本子上,需要保证大家记下的法律条款都一致; 问题在于议员和服务员都是兼职的,他们随时会因为各种事情离开议会大厅,传递的消息也可能会重复或丢失,并随时可能有新的议员进入议会大厅进行法律表决,使用何种方式能够使得这个表决过程正常进行,且通过的法律不发生矛盾。 注意我们假设议员和服务员都是道德高尚的人,不会恶意发送假消息
而解决这个问题的经典故障容错算法就简称paxos,很多其他的基于故障容错的共识算法都是基于paxos改进发展产生的,paxos本身也有很多变种, 甚至有这种说法:“there is only one consensus protocol, and that’s Paxos — all other approaches are just broken versions of Paxos” . 所以我们只需要理解一下最基础的Basic Paxos这个算法的基本原理,其他的算法都是基于此的演变升级;
引用斯坦福的教学内容Basic Paxos的基本流程图:
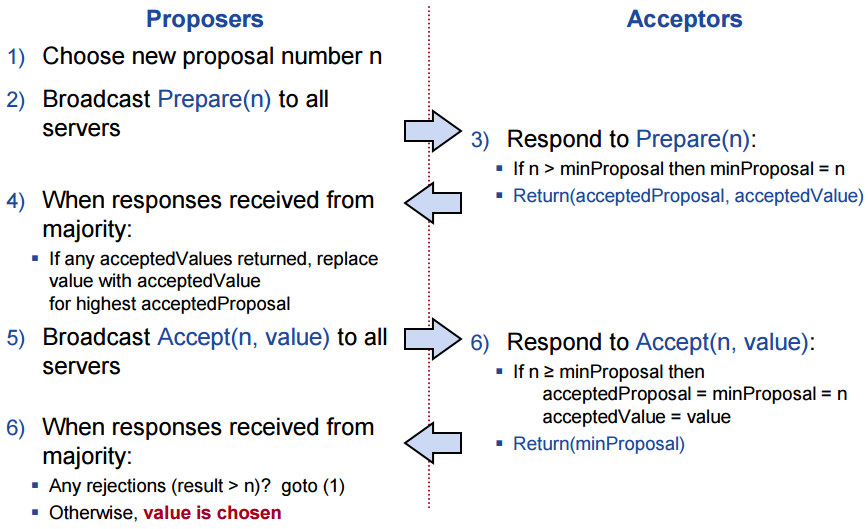
basic paxos是基于2PC两阶段提交协议的,这里首先引入提议者proposer和接受者acceptor作为两阶段的具体实施者,我们用一个机票预订的例子来讲解:
为了简化描述,假设我们只有5个节点Node1|Node2|Node3|Node4|Node5 ,其中Node1和Node2是proposer角色,然后Node3|Node4|Node5都是acceptor角色, 实际上一个节点可以是多种角色,上面引用的图中是说broadcast to all servers,实际上对于一个2F+1的节点配置来说,只需要得到F+1个节点响应即可,我们例子中忽略这些细节,集中分析主要的逻辑, 然后算法主要分两步或两阶段,提议propose和决议commit,第一阶段主要是为了将已经落实的最新决议状态(数据)同步给其他节点(所有proposer),第二阶段主要是挡住旧的决议(并落实新决议)
///////////////////////////////////////////////
A. 基本场景:
Node1收到客户端请求Alice要预订广州到新加坡的scoot100,座位号选择A1,
Node1提议者proposer发起一个写数据的提议proposal:Prepare(【Node1-P-1】),其中P是Proposal,1是编号
(加上标志Node1是因为每个节点都维护自己的编号,如果Node1同步到其他节点Node2的最新编号是100的话,就会重置自己维护的编码并加1变成101)
现在Node3|Node4|Node5这三个acceptor都收到了提议proposal,假设当前三个acceptor上面的minProposal=0,acceptedProposal=null,acceptedValue=null,因为minProposal<1此时三个节点都会更新为
minProposal=1,acceptedProposal=null,acceptedValue=null,并返回【P-OK,acceptedProposal=null,acceptedValue=null】,P-OK代表同意这个Proposal
Node1收到了全部是P-OK,而且收到的acceptedProposal=null,acceptedValue=null跟自己的数据没有冲突,所以开始提出决议commit:Accept(【Node1-C-1,"Alice航班scoot100,座位号A1"】)
现在Node3|Node4|Node5这三个acceptor都收到了决议commit,而且1>=minProposal=1,所以三个节点都会更新
acceptedProposal=minProposal=1,acceptedValue=“Alice航班scoot100,座位号A1”,并且都返回【C-OK,minProposal=1】;
Node1收到了result=1 判断result>n 1>1是false,所以没有问题(注意假设任何一个Acceptor返回的是result>1就证明该Acceptor已经接受了另外一个proposer的更新的一个决议,那么Node1要立即放弃决议,重新回到第一步)
接着上面的场景延伸以下两个场景:
///////////////////////////////////////////////
B. 场景1:
假设接着Node2收到客户端请求Bob要预订同一班次广州到新加坡的scoot100,座位号也是选择A1,
假设Node2上面的计数器没有同步最新的,所以发起一个写数据的提议proposal:Prepare(【Node2-P-1】)
Node3|Node4|Node5这三个acceptor都收到了提议proposal,因为需要n>minProposal=1但是1>1是false,所以会返回【P-FAIL,acceptedProposal=1,acceptedValue="Alice航班scoot100,座位号A1"】
Node2收到任何一个P-FAIL后都会同步最新决议,而且acceptedProposal=1,acceptedValue="Alice航班scoot100,座位号A1",所以跟自己的数据"Bob航班scoot100,座位号A1"有冲突,所以也是要同步最新决议,
注意,在simple paxos算法中,不管P-FAIL还算P-OK,只要任何一个返回中的acceptedValue有值都要立即同步,因为是代表通过的最新的决议,
所以Node2会同步更新本地的value="Alice航班scoot100,座位号A1",并且继续广播决议commit:Accept【Node2-C-1,"Alice航班scoot100,座位号A1"】
看到这里可以感觉是无用功,实际上PAXOS算法却是复杂,而且有很多变种,我们只是讲解基本的逻辑,
实际中可以做各种优化,不过这一步可能还真有用,比如可以同步之前掉线的Acceptor节点,要看具体实现中的考虑;
Node3|Node4|Node5这三个acceptor都收到了决议,更新并返回【C-OK,minProposal=1】;
Node2收到了result=1 判断result>n 1>1是false,所以没有问题
///////////////////////////////////////////////
C. 场景2:
其他跟场景1一样,只是改成Node2已经同步到了最新的ID=1,所以自增ID 1+1=2 发起一个写数据的提议proposal:Prepare(【Node2-P-2】)
Node3|Node4|Node5这三个acceptor都收到了提议proposal,2>1,所以更新minProposal=2,然后返回【P-OK,acceptedProposal=1,acceptedValue="Alice航班scoot100,座位号A1"】
Node2收到了全部的P-OK,而且收到的acceptedProposal=1,acceptedValue="Alice航班scoot100,座位号A1",所以跟自己的数据"Bob航班scoot100,座位号A1"有冲突,
跟场景1中一样“simple paxos算法中,不管P-FAIL还算P-OK,只要任何一个返回中的acceptedValue有值都要立即同步,因为是代表通过的最新的决议”,
更新自己的value="Alice航班scoot100,座位号A1",并且继续广播决议commit:Accept【Node2-C-2,"Alice航班scoot100,座位号A1"】
Node3|Node4|Node5这三个acceptor都收到了决议,更新并返回【C-OK,minProposal=2】;
Node2收到了result=2 判断result>n 2>2是false,所以没有问题
///////////////////////////////////////////////
D. 场景3:
接着场景2,因为bob因为座位被抢所以订票失败,他又选了个新位置A2,
这次又是Node2收到了客户端请求,所以自增ID 2+1=3 并发起一个写数据的提议proposal:Prepare(【Node2-P-3】)
Node3|Node4|Node5这三个acceptor都收到了提议proposal,会返回【P-OK,acceptedProposal=2,acceptedValue="Alice航班scoot100,座位号A1"】
Node2收到了全部的P-OK,而且acceptedProposal=2,acceptedValue="Alice航班scoot100,座位号A1",再次强调“simple paxos算法中,不管P-FAIL还算P-OK,只要任何一个返回中的acceptedValue有值都要立即同步,因为是代表通过的最新的决议”,
而此时本地的数据状态为:{"Alice航班scoot100,座位号A1","Bob航班scoot100,座位号A2"},所以无冲突,同步的结果是没有变化,
Node2继续广播决议commit:Accept【Node2-C-3,"Bob航班scoot100,座位号A2"】
现在Node3|Node4|Node5这三个acceptor都收到了决议commit,而且3>=minProposal=2,所以三个节点都会更新
acceptedProposal=minProposal=3,acceptedValue="Bob航班scoot100,座位号A2",此时本地数据完整状态为:{"Alice航班scoot100,座位号A1","Bob航班scoot100,座位号A2"}
并且都返回【C-OK,minProposal=3】;
Node2收到了result=3 判断result>n 3>3是false,所以没有问题
这些场景都是假设节点正常运作,paxos算法的意义就是可以在某些节点崩溃及通信延迟的情况下仍然可以达到最终一致的效果,所以你可以自行想一下如果proposer节点或者acceptor节点掉线会不会影响系统稳定,比较显然不再赘述, 这里需要多提一个概念叫做活锁livelock
Node1发起一个写数据的提议proposal:Prepare(【Node1-P-1】),假设Node1已经完成了Prepre,意思是Node3|4|5都返回了,现在开始提交决议【Node1-C-1,Value】
此时Node2发起一个写数据的提议proposal:Prepare(【Node2-P-2】),根据前面的分析,Node3|4|5收到后会更新minimalProposal=2,从而会拒绝Node1的决议【Node1-C-1,Value】,
再根据前面的分析,Node1会从头开始重新提议【Node1-P-3】,
然后刚刚Node2完成了提议,开始提交决议【Node2-C-2,Value】,但是Node3|4|5已经收到了Node1的新提议【Node1-P-3】,所以minimalProposal=3,所以会拒绝Node2的决议【Node2-C-2,Value】,
所以Node2也只好放弃重头开始重新提议【Node2-P-4】...如此循环,谁也无法成功实现决议
解决上面的活锁问题有两种方法,一个是在每次重头开始提新提议的时候加一个随机的delay延迟,这样会可以给机会让其中一个proposer成功完成提议和决议; 另一种比较更多采用的做法就是从proposer中选一个leader出来,由leader统一提议决议,避免冲突。
说到这里,还有一个问题,上面说了对于2F+1个节点,只需要F+1个节点达成一致就可以move forward,即对外部提供服务了,所以paxos为了满足FLP理论的liveness要求,引入了一个learner的概念,
Learners act as the replication factor for the protocol. Once a Client request has been agreed upon by the Acceptors, the Learner may take action (i.e.: execute the request and send a response to the client). To improve availability of processing, additional Learners can be added. Model application as a deterministic state machine
Acceptor接受决议后会通知给每一个learner节点,learner在判断已经有F+1个节点达成共识后就可以返回给客户端以及同步给其他Acceptor节点, 当然paxos算法本身并不保证liveness,只是引入learner可以改善liveness。
PAXOS很经典但是也是比较臭名昭著的复杂,RAFT是其实现的简化版本,RAFT主要包含选举leader election和日志拷贝log replication:
其leader election也是利用心跳和过半数选举的机制,并且leader也是有第几代leader的term标志,ZAP用的是epoch,simple paxos没有leader概念; 然后log replication跟simple paxos的2PC些许类似,首先所有客户端的写请求都会转发给leader来处理,然后leader写入日志,状态是uncommitted,通过心跳发给所有followers, follower收到后也写入自己的日志,状态是uncommitted,leader等得到过半数的followers的ack响应后将状态改为committed,然后再通知所有follower,follower收到后也更新数据更改状态为committed, 注意写日志的时候,leader是将请求变成entry,然后每个entry都有一个index值用来保持操作的有序性,类似于ZAP协议中的leader广播message赋值的单调递增monotonically increasing unique id的zxid,paxos中则类似每个proposer使用的Ballot Number; 除了系统上线第一次leader election,后续各种原因触发的重新选举都需要一个recovery protocol,term+index,epoch+zxid是为了在leader选举的时候选择有着最完美日志的节点作为leader进行恢复,
下面拿RAFT协议来举例完善一下前面没详细说的分区容错partition tolerance,
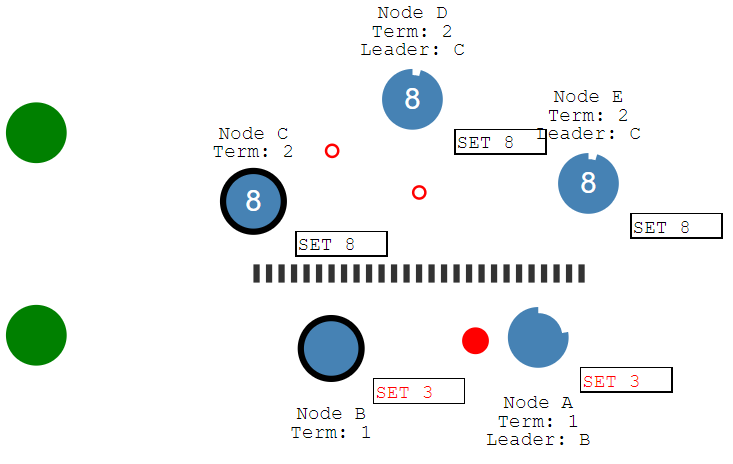
可以看到网络分为两个分区,两个leader,他们的时代是不同的一个是term=1一个是term=2,互相不知道彼此,但是由于term=1在更改数据的时候无法得到超过半数的响应, 所以所有数据更改都会处于uncommit未提交状态;而反之在另一边term=2这里,是可以达成共识的; 最后一旦网络恢复正常,term=1的分区就会发现自己全部过时了,就会放弃自己的uncommit日志,同步term=2的提交日志; 由此可见在网络分区的情况下分布式状态机一样可以实现一致性;
前面说zookeeper本质也是一种状态机,其ZAP协议又有不同的考虑,分为3个阶段,Discovery,Sync,Boradcast,跟前面这些协议都是大同小异,就不展开细节,只需要说下不同点:
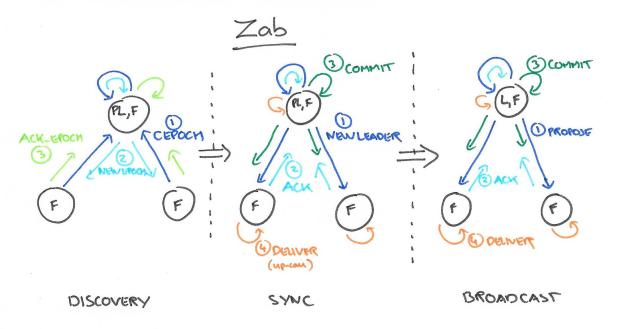
和raft的有序性不同,ZAP协议有序性(znode节点操作)不仅体现在采用的FIFO先进先出队列,还有重新选举恢复的时候需要Sync,
Upon a change of primary, a quorum of processes has to execute a synchronization phase before the new primary broadcasts new transactions. Executing this phase guarantees that all transactions broadcast in previous epochs that have been or will be chosen are in the initial history of transactions of the new epoch.
比如leader在崩溃之前广播出去的数据(proposal和commit)不会丢失,由leader产生但没有广播出去的proposal和commit则跳过,但是如果该leader之后重新被再次选举为新leader,其上没有提交的事务需要根据判断其epoch是否小于当前的epoch,是则丢弃,如果相同则还会被提交;
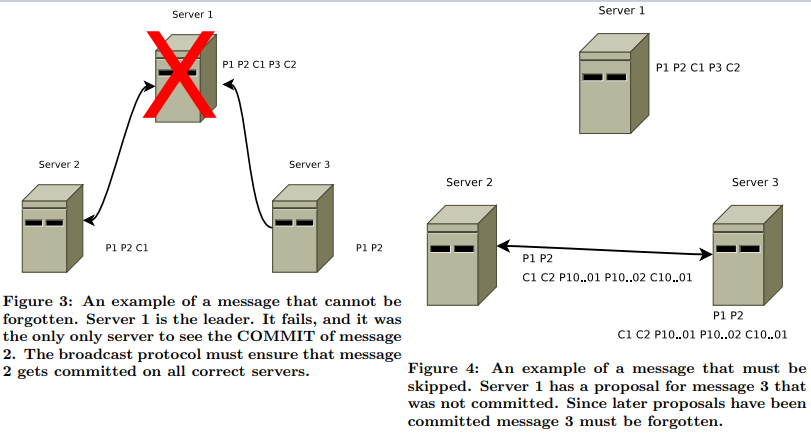
“Before proposing any new messages a newly elected leader first makes sure that all messages that are in its transaction log have been proposed to and committed by a quorum of followers” A simple totally ordered broadcast protocol (opens new window)
这也是zookeeper可以作为分布式框架保证primary order基本顺序的信心保证;
RAFT没有ZAP的sync这个阶段,而是靠AppendEntries RPC同步纠正, 具体参考阿里云栖的这篇分析文章ref (opens new window); 而paxos算法本身没有保证有序性paxos run (opens new window);
# 2.2 分布式产品和zookeeper
前面讲了很多理论,现在我们落实到市面上的各种分布式产品,看看具体大家都是如何实现的
分布式服务框架 zookeeper的ZAP协议
分布式消息队列集群Kafka
分布式计算 spark, storm以及Hadoop mapreduce2.0
分布式存储系统:hbase基于zookeeper, 而ETCD采用RAFT协议
分布式任务调度:Elastic-Job等
挑几个产品看看它们的架构图
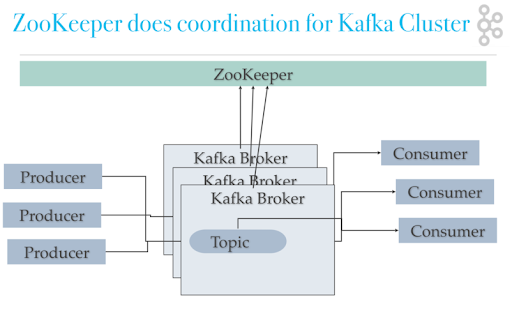
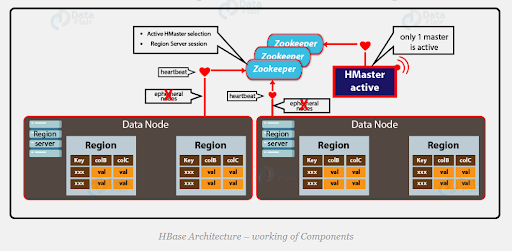
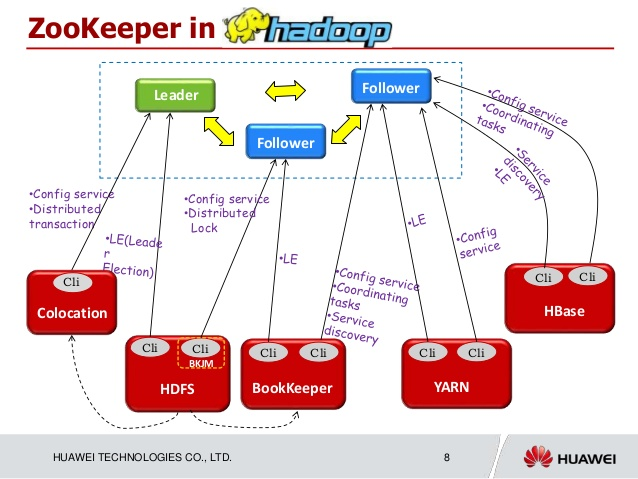
Since Hadoop 2.0, ZooKeeper has become an essential service for Hadoop clusters, providing a mechanism for enabling high-availability of former single points of failure, specifically the HDFS NameNode and YARN ResourceManager.ref (opens new window)
观察可以发现一个问题,为啥很多产品都需要依赖分布式框架zookeeper??
简单回答,不要重复造轮子,前面提到zookeeper基于ZAP协议的有序状态更改strong guarantee使其可以用于集群管理,只不过有些可以脱离zookeeper单机部署,有些则是只支持集群模式,跟zookeeper耦合紧密, Quartz就是支持单机版也支持集群,但是其集群基于数据库锁,严重耦合,所以看到有人也将其改造成为基于zookeeper集群管理的模式,当然我们谈的是分布式系统,所以这里不讨论单机版本
举一个例子来说明zookeeper:
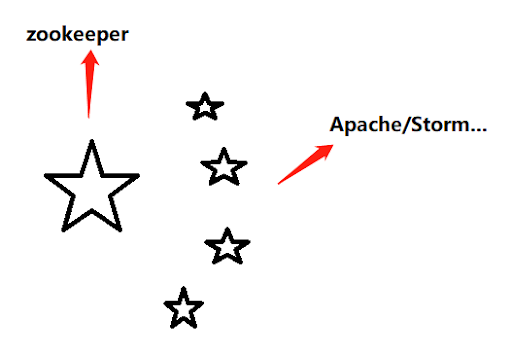 中央就是zookeeper,本身是集群,政治协商,一个挂掉还会迅速选一个,中央的主要工作是做集群管理,具体的生产生活还要交由Apache/Storm这些地方政府节点来做,
地方节点之间也是一个集群,比如分布式商务系统集群(商务部是集群的leader,向中央注册),分布式农业系统集群等
中央就是zookeeper,本身是集群,政治协商,一个挂掉还会迅速选一个,中央的主要工作是做集群管理,具体的生产生活还要交由Apache/Storm这些地方政府节点来做,
地方节点之间也是一个集群,比如分布式商务系统集群(商务部是集群的leader,向中央注册),分布式农业系统集群等
Zookeeper适用的场景:ref (opens new window)
统一命名服务(Name Service)
配置管理(Configuration Management)
集群管理(Group Membership)
共享锁(Locks):共享锁在同一个进程中很容易实现,但是在跨进程或者在不同Server之间就不好实现了,依赖zookeeper这样的分布式框架实现大大降低难度
# 2.3 动手写一个简单的分布式系统
说了这么多,来动手写一个简单的分布式系统,假设我们需要创建一个分布式任务调度,不采用市面上的分布式任务调度产品,从零开始写,假设这些任务集中存在某关系型数据库
首先我们肯定需要一些干活的workers,负责执行具体任务,想象一下我们创建了一个java程序执行具体的任务逻辑作为woker;
对于java程序,正常情况下,除非是定制了class loader否则一个进程就是跑在一个单独的jvm实例当中, 所以分布式部署的情况下,每个worker都会在一个独立的jvm实例中,多个互相独立的jvm实例之间需要协商分配这些任务, 同时去读写数据库的任务列表会造成冲突,显然如果我们不采用共识算法,处理起来会毫无头绪,共识算法相对复杂,我们还是使用zookeeper来简化问题, 最直接简单的想法就是通过zookeeper注册从中找一个worker作为leader来单独管理数据, 你可能会说不引入zookeeper,自己写一个单独的leader程序不行吗,确实可以,不过leader程序也要做成集群式的,不可以引入单点故障, 所以为了简单,直接让这些workers都注册zookeeper,不同的java程序微服务之间通过zookeeper的watcher监听模式实现同步节点信息, 这样每个worker都可以保存一份同步的worker list,怎么从worker list中选出一个leader呢,要不然是配置要不是竞争,配置的缺点是
可以简单设计一些规则来实现选举,比如通过配置文件定义好是否是leader候选人,然后选的时候就通过排序找到第一个活着的候选人即可;
基于zookeeper 的临时节点实现选举,zookeeper除了手动才能删除的持久节点,还有一种ephemeral临时节点,如果临时节点的创建者客户,失去zookeeper连接,临时节点就会自动删除, 所有注册的客户端都抢注比如/leader子节点,然后子节点根据排序选leader,这种方式的缺陷很明显,因为zookeeper只支持最简单的推拉消息,对某个node path的节点包括其data的监听都只会通知有变化, 具体的变化还需要客户端去拉取,所以每个客户端同步节点信息是有时间差的,在时间差内容易产生脑裂;
这种方式比较低级,其实可以通过curator高级API封装好的leader election recipes,curator利用zookeeper的EPHEMERAL_SEQUENTIAL实现分布式锁加观察模式封装了两种leader选举,leader latch和leader election, 默认都是普通worker,在抢到leadership的时候激活为leader,不过这种方式有个缺点,其他普通的worker无法得知选举结果,所以在某些场景下,worker需要向leader汇报情况,需要额外再做点处理, 例如在take leadership的时候,通过rpc通知其他节点自己是leader,或者也可以将自己的id注册在zookeeper的一个特定的path上,比如/leader/result, 这样其他节点就可以通过监听获取到leader选举结果;分布式计算引擎Spark采用了curator的leader latch方式选举leader;
现在还没有结束,现在有了动态选举的leader和一群worker,leader要怎么分发任务给worker,他们是互不想干的独立进程,可能部署在不同的机器上,两种思路:
i)轻量级处理:
假设worker在zookeeper上面注册为/task/worker-00000001,/task/worker-00000002,leader分发任务时可以将任务的信息setData给某个worker,然后worker监听到getData变化, 则去获取具体任务加载执行,执行完成后再setData执行结果给当前的znode,然后leader可以监听获取结果,从而完成交互; 但是前提是setData不可以超过1MB的限制,并且如果有任务之间还有依赖的话,完全通过zookeeper处理会比较复杂; 参考例子代码 (opens new window)
ii)重量级处理:
由于轻量级处理方式的限制,我们可以引入rpc通信协议,让leader和worker可以直接通信,相比较基于HTTP的web service,基于TCP的rpc性能更优,然后结合proxy代理模式对调用方法接口进行封装, 可以让微服务在调用远程方法的时候就像调用自身方法一样透明; 然后因为所有worker及leader节点都保存了一份节点列表,所以leader分发任务的时候就可以采取一定的策略,比如round robin或load balance方式rpc调用worker分发任务; 至于worker节点,虽然也保存了一份节点列表但一般只需要跟leader通信,当然如果leader挂掉,worker变成leader才会用到这个列表;
总结画个架构图:
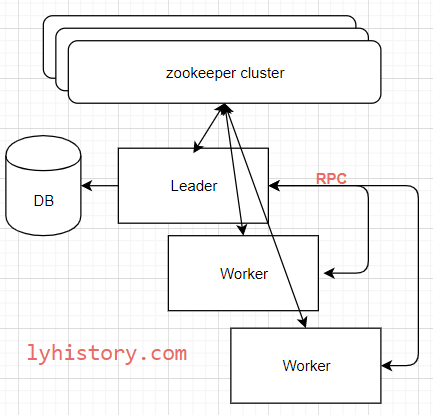
还需要思考的问题:
i. leader不干活: 上面不管是直接通过使用zookeeper的临时节点还是使用curator recipes进行选举,都无法避免一种场景的出现,比如选举出的leader无法连接数据库获取任务, 针对这种异常场景,需要额外增加监控逻辑,比如心跳检测leader跟数据库的连接,一旦出现问题就断开跟zookeeper的连接,下线故障leader,去主动触发重新选举;
ii.脑裂问题, 前面这个问题的一个类似场景是,leader断开了跟zookeeper的连接,但是还保持跟数据库及其他节点的连接,由于他已经断开了zookeeper的连接,无法通过观察者模式获取新leader的选举, 他还认为自己是leader,这个场景比较容易解决,可以在通过监控跟zookeeper的心跳连接情况,一旦断开就直接剥夺leader的头衔并下线机器, 但是在剥夺之前的时间窗口内还是存在多个leader问题,从而会产生下游任务重复触发的问题,所以应该还要从下游做更多控制,比如从具体任务执行层面,通过任务名+时间来挡重复指令,精度不要放太高, 比如放秒级或者分钟级,这样可以通过检查该秒或分钟内是否该任务已经触发来挡住重复的触发命令
iii.数据丢失, 如何在leader宕机的瞬间保持数据不丢失,新leader如何恢复旧leader宕机之前的状态,还要从业务角度去考虑,如果真的很严重,也只能采取共识算法的多阶段提交策略保存每一步的操作日志及状态;
iv.工作分配,前面只是简单说leader会做任务分发,但是没有说谁会来判断任务触发是否满足条件,比如一种方式是leader来判断所有事件依赖以及是否满足触发条件,然后如果满足才会分发下去, 另一种方式是,leader将任务直接简单的根据比如round robin策略分发出去,由具体的worker来判断依赖关系及等待其达到触发条件后再执行; 后一种方式的问题是,如果某个任务的依赖任务分发给了另外一个worker,这些worker需要频繁的请求leader中心节点同步任务状态, 所以第二种做法更简单的处理是分发任务时将一组有依赖关系的任务都分发给同一个worker,这样就避免了多节点之间的任务依赖,前面引用的一个用quartz基于zookeeper的实现架构就是第二种做法; 不管是哪一种做法,都要考虑到一种情况的处理:当worker挂掉之后,如何继续分配挂掉的worker上面未完成的任务
v.不用数据库,上面是假设数据都是放到数据库的,而且只允许leader单节点去维护,设想一下数据分布在每个节点上,比如每个节点都有完整的数据备份,同步起来就只能采取共识算法;
# 3.基于拜占庭容错BFT(Byzantine fault tolerance)的分布式账本技术
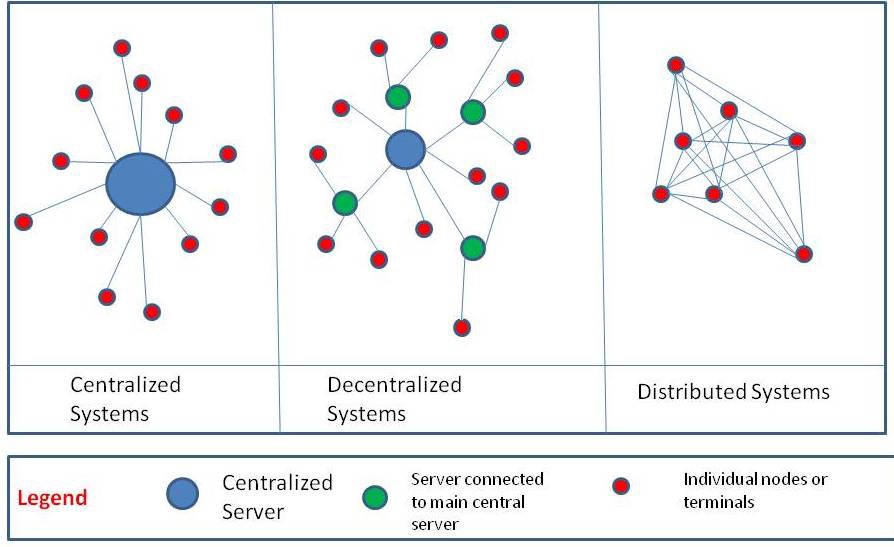
我们前面谈到的不管是zookeeper的ZAP,paxos还是raft都不能算是真正的分布式,因为基本都是要选举出leader来主持大局,真正的分布式节点是完全平等的,不存在谁是leader, 所以基本都只能算是多中心系统; 而且我们看到实际的分布式产品大多是基于zookeeper,zookeeper本身也不是真正的分布式框架,因为其本身集群也是有leader和follower的,所以基于zookeeper的分布式系统也会不是真的分布式;
其实这里还隐含着另外一个问题,我们前面的分布式产品都是部署在内网中,不管是私有云公有云还是自己的机房,都不会给外界暴露端口,一般更不会允许外面的节点随便连进来,属于关在笼子里面的内部系统, 一切的根源都在于以上前提假设都是基于故障容错的,都是假设不会有恶意节点,因为都是公司内网可控的内部节点;
所以区块链技术,尤其是比特币作为区块链的第一应用,到目前为止平稳运行了十多年,才算是真正意义上的去中心化分布式技术,不管是手机,普通电脑,还是矿机,都可以运行一个比特币节点,随时加入退出, 甚至你可以恶意篡改比特币源码的节点都没关系,只要算力不超过51%,都不会影响比特币的正常运行,那么他的共识算法跟以上的共识算法有什么区别呢? 下面我开始给大家介绍下区块链技术的入门知识:
区块链技术又被称作分布式账本技术Distributed Ledger Technology,简称DLT, 单纯从技术上来说区块链分为permissioned 和 permissionless blockchain,前者是私有链和联盟链,后者是公链; 如果从去中心化角度来说只有公链技术才算区块链,当然这个涉及到关于中心化的辩论,属于哲学问题,不予讨论;
# 3.1 区块链分类简介
私有链基本上没有任何意义,唯一用武之处就是用来教学演示,对于正常的普通企业用传统的办法更高效,如果真的要搞行业级别的集成自然是选择联盟链, 我就以IBM的hyperledger fabric为代表来讲解下联盟链:
直接看核心流程图,我只是简略说主要内容,不会讲解他的会员系统(节点的加入都是要经过审核后配置到系统中),也不会细分peer节点的类型
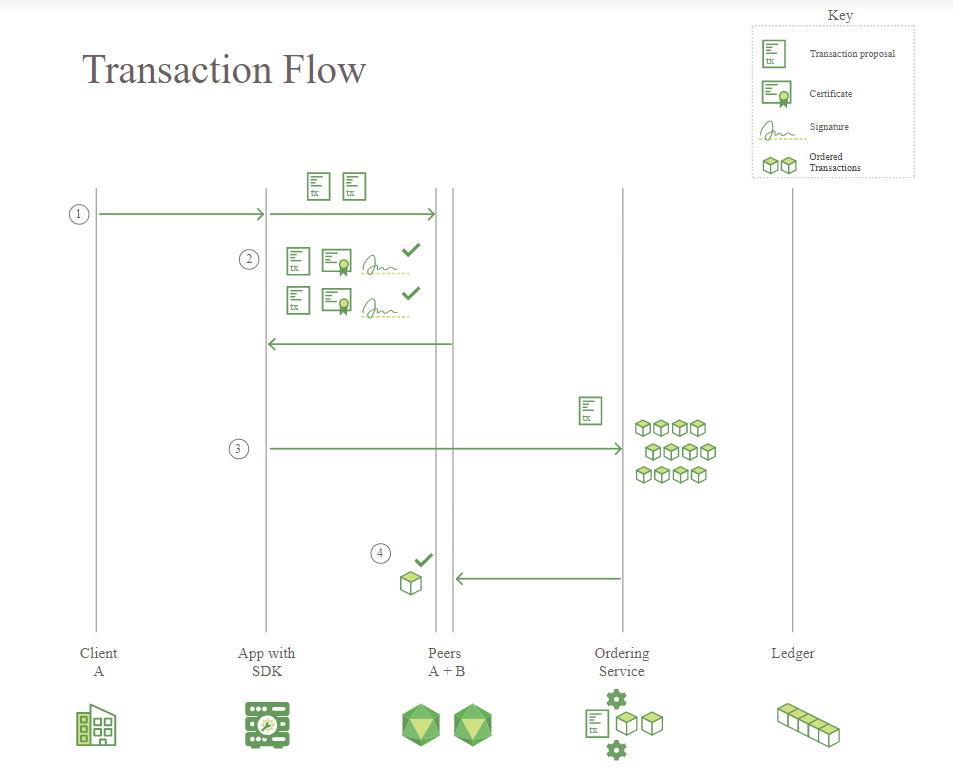 客户端发一个transaction请求,实现了hyperledger sdk的客户端程序接收请求,验证后发给peers节点,peers节点验证并进行endorse签名然后返回结果给客户端,
客户端收到一定数量(一定数量决定于事前设定的policy,比如半数以上)的endorse之后就发起提交请求,将transaction及endorsement一起发给ordering service,又是一种2PC两阶段提交,
ordering service排序打包交易到一个区块再发给peers,peers会验证区块中的每个交易,然后更新账本;
客户端发一个transaction请求,实现了hyperledger sdk的客户端程序接收请求,验证后发给peers节点,peers节点验证并进行endorse签名然后返回结果给客户端,
客户端收到一定数量(一定数量决定于事前设定的policy,比如半数以上)的endorse之后就发起提交请求,将transaction及endorsement一起发给ordering service,又是一种2PC两阶段提交,
ordering service排序打包交易到一个区块再发给peers,peers会验证区块中的每个交易,然后更新账本;
不过等等,这里的ordering service听起来像是一个单节点,不像peers那样有多个节点,难道是个中心化的排序服务吗?然后我们看IBM文档的说法如下:

看到没,关键的ordering service可以是一个单节点或者kafka集群,单节点不用说了,kafka集群仍然是基于故障容错的分布式产品; 不过共识这块hyperledger是可以插拔自定义的,实际上V1.4版本引入了RAFT算法,当然也是基于故障容错的;
近期hyperledger的另外一个产品Sawtooth开始推出PBFT,据说跟fabric不同,Sawtooth可以支持permissionless网络,有兴趣的读者可以自行研究;
公链有两大代表:区块链第一应用比特币及支持智能合约的超级计算机以太坊,当然还有EOS,BTS等等其他公链,他们的共识算法都是基于解决拜占庭将军问题的算法, 注意这里并非特指拜占庭容错算法BFT或PBFT,而是泛指,区块链的共识算法也经常被称作trustless consensus,意思是无信任共识,换句话说跟前面那些故障容错算法的假设不同,对于无信任共识来说节点之间是不可以相互信任的, 会有好节点和坏节点,坏节点会恶意发送假信息,我们开始具体聊聊这些基础知识
# 3.2 拜占庭将军问题和实用拜占庭容错算法PBFT
# 拜占庭将军问题
东罗马帝国也就是拜占庭帝国国王准备攻打一座城堡, 拜占庭军队的多个军区驻扎在城外,每个军区都有一个将军Generals, 由于这些将军相距很远只能通过信使messengers传递消息, 现在军队必须在撤退和进攻两个命令中达成一致并且同时行动,否则就会被击败;
归纳为规则A和B:
A.All loyal generals decide upon the same plan of action. 叛徒可以任意而为,但是忠诚的将军必须达成一致的计划agreement(进攻或撤退),所有节点不仅要达成共识而且是要合理的共识agreement
B.A small number of traitors cannot cause the loyal generals to adopt a bad plan. 我们无须考虑什么是bad plan,只需要确认忠诚的将军节点如何做出决定decision
假设v(i)代表第i个将军发送的信息,那么n个将军的信息就是v(1),...v(n) 所以满足A很简单,只需要所有节点按照同一个方法将收到的v(1),...v(n)转成行动,输入一样则输出一样;
而对于B,假设最终的决定只有进攻和撤退两种,那么第i个将军的决定可以基于最多的投票, 如果叛徒节点多到刚好让诚实的节点平均分成攻击和撤退两个阵营则第i个将军无法做出决定
A的前提可以归纳为条件1:
condition1:每个节点都收到同样的v(1),...v(n), 但是有可能所有的诚实节点都是发送进攻的消息,但是一部分叛徒会导致诚实节点发送retreat
为了满足B归纳出条件2:
condition2:如果第i个节点是忠诚的,那么发送的v(i)必须被每个忠诚的节点使用
结合condition2,我们可以重写condition1变成condition1':任意两个忠诚的节点都使用相同的v(i)
至此,condition1'和condition2都是基于第i个将军发送的信息v(i),所以到这里我们可以把问题转化成:一个将军节点如何发送信息给其他节点;我们重新组织语言,将问题转化归纳为:
将军节点如何发送命令给他的lieutenants副官们,具体来说是一个将军节点如何发送命令给他的n-1个副官节点,并且满足以下两个条件:
IC1. 所有的忠诚副官节点都遵守同一个命令
IC2. 如果将军是诚实的,每一个诚实副官都应该遵守将军发送的命令
IC1和IC2统称为interactive consistency conditions交互型一致条件
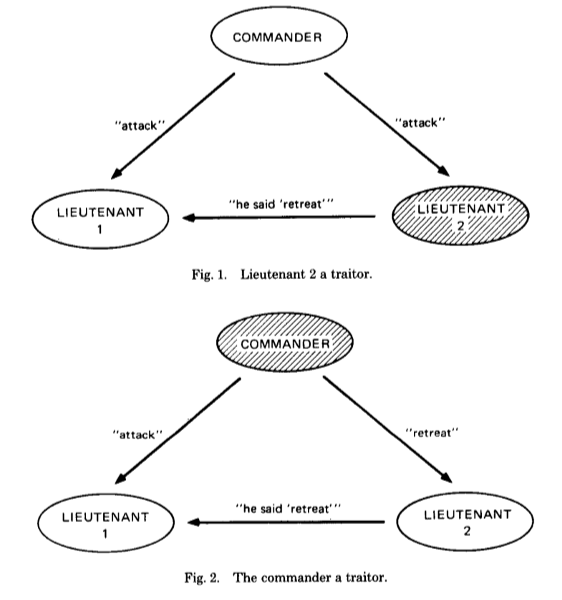
fig2违背了IC1,所以3个节点中有一个叛徒是无解的,我们由此就证明了对付m个叛徒至少要3m+1个节点,黑人问号,什么时候证明的?
The proof is by contradiction,很简单,上面3个节点1个叛徒无解,设m=1,3m=3个节点无解,所以反正法结束!
定义口头信息算法Oral Message algorithms OM(m), ∀m∈N, m>0,将军向n-1个副官发送命令,定义函数 majority(v1 ,…,vn-1)的值两种取法:
假设数值是二元的则取少数服从多数,比如多数是进攻则进攻,否则默认值为撤退;
假设数值是一个可排序序列则选择中位数;
执行方法是:OM(m)调用n-1次OM(m-1)算法,每一个算法OM(m-1)再分别调用n-2次的OM(m-2),如此直至m=0。
下面假设m=1,3m+1=4
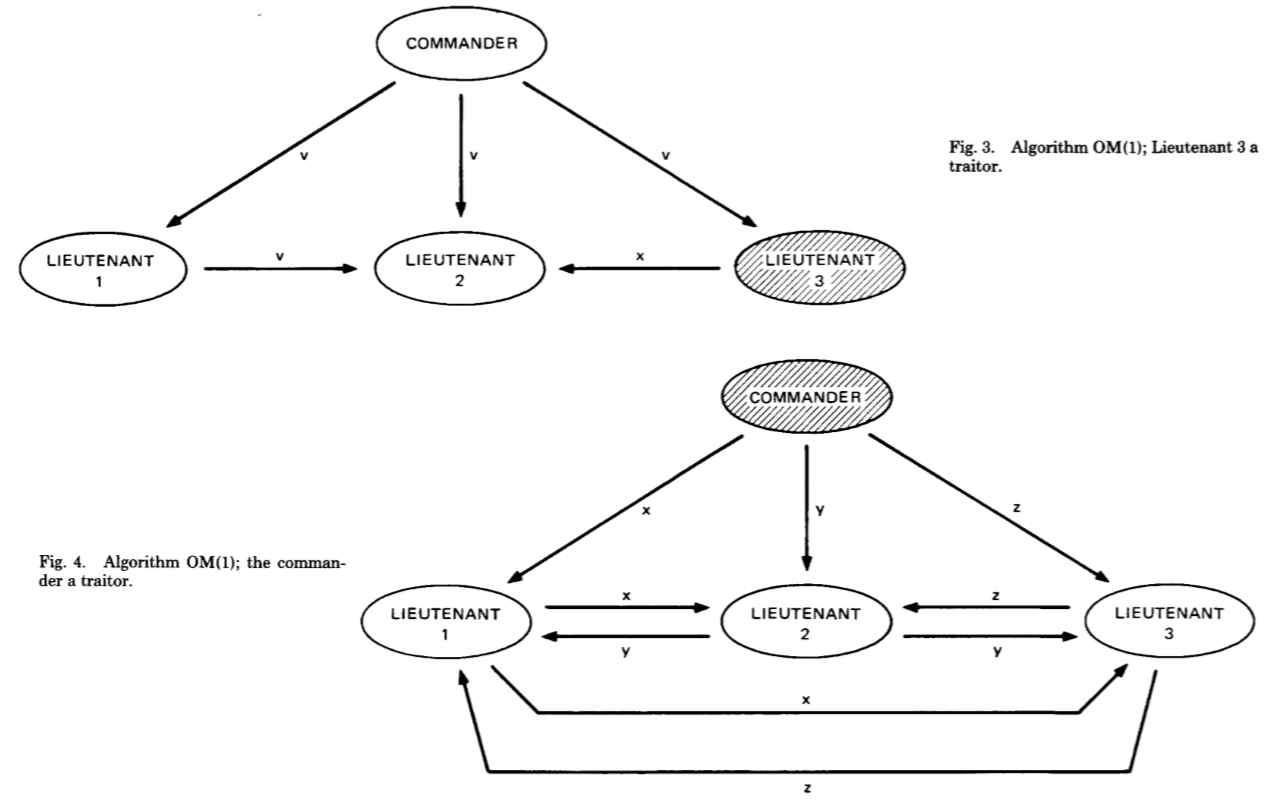
fig3,OM(m=1)将军首先发送v给所有节点,然后OM(m=0)副官1发送v给副官2,副官3发送x给副官2,副官2有v1=v2=v,v3=x,v=majority(v,v,x),其他副官同理; 同时还可以判断出副官3是叛徒
fig4,OM(m=1)将军首先分别发送x,y,z给副官1,2,3,OM(m=0),副官1发送x给副官2,副官3发送z给副官2,副官2收到(x,y,z),同理所以每个副官都收到(x,y,z), 可以判断将军是叛徒
# 实用拜占庭容错算法PBFT
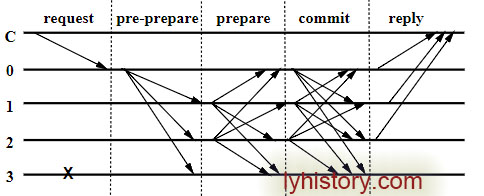
主节点 p = v mod |R|。v:视图编号(类似前面提到的term),|R|节点个数,p:主节点编号 现在R=4,v=0,p=0
1>.client c客户端发送请求<REQUEST, o, t, c>给主节点0:
REQUEST包含消息内容m,以及消息摘要d(m),客户端对请求进行签名; o: 请求的具体操作,t: 请求时客户端追加的时间戳,c:客户端标识;
2>.主节点0预准备pre-prepare:
主节点校验消息签名并拒绝非法请求; 校验通过则分配编号n,用于对客户端请求的排序; 然后多播消息<<PRE-PREPARE, v=0, n, d>, m>给其他副本节点: d为客户端消息摘要,m为消息内容,n是要在范围区间内的[h, H],用于垃圾回收; 对<PRE-PREPARE, v, n, d>签名。
3>.副本节点发送PREPARE:
副本节点1、2、3收到主节点0的PRE-PREPARE消息,校验并拒绝非法请求: 主节点PRE-PREPARE消息签名; 当前副本节点是否已经收到了一条在同一v=0下并且编号也是n,但是签名不同的PRE-PREPARE信息; d与m的摘要是否一致; n是否在区间[h, H]内;
然后副本节点都向其他节点发送prepare消息<PREPARE, v=0, n, d, i>,i是当前副本节点编号; 节点i对<PREPARE, v, n, d, i>进行签名; PRE-PREPARE和PREPARE消息写入log,用于View Change时恢复未完成的操作;
4>.全部节点COMMIT:
所有节点收到PREPARE消息,校验并拒绝非法请求: 节点PREPARE消息签名是否正确; 当前节点是否已经收到了同一视图v下的n; n是否在区间[h, H]内; d是否和当前已收到PRE-PPREPARE中的d相同;
节点i等待2f+1个验证通过的PREPARE消息(对于副本节点来说包括自己)则进入prepared状态并向其他节点发送commit消息<COMMIT, v=0, n, D(m), i>, 节点i对<COMMIT, v, n, d, i>签名; COMMIT消息写入日志,用于View Change时恢复未完成的操作
5>.全部节点REPLY:
所有节点收到COMMIT消息,校验并拒绝非法请求: 节点COMMIT消息签名是否正确; 当前节点是否已经收到了同一视图v下的n; d与m的摘要是否一致; n是否在区间[h, H]内;
节点i等待2f+1个验证通过的COMMIT消息(包括自己),进入commit状态,说明当前网络中的大部分节点已经达成共识,运行客户端的请求操作o,并返回<REPLY, v, t, c, i, r>给客户端, r是请求操作结果
6>.客户端client c等待f+1个reply 如果收到f+1个相同的REPLY消息,说明请求已经达成全网共识,否则客户端需要判断是否重新发送请求给主节点; 记录节点发送的COMMIT消息到log中。
算法其他细节:垃圾回收,视图更改请自行查阅,不是讨论重点;
几个问题:
i.为什么需要一个primary节点 PBFT的理论之一primary-backup [Alsberg and Day 1976] 跟paxos和raft类似的思想,用leader节点可以避免多个proposer的冲突,以及排序client端的请求,降低算法实现难度,比如恢复,在PBFT的概念里epoch或term变成了view,然后leader叫做primary,其他的follower叫做backups, 主节点负责将来自Client的请求给排好序,然后按序发送给备份节点; 如果主节点可能会是恶意节点,比如给不同的请求编上相同的编号或者不分配编号或者编号跳跃不连续,备份节点会动检查这些序号的合法性,如果有发现问题,备份节点就会触发view change协议来选举出新的主节点,当然备份节点也会通过timeout心跳检查主节点是不是挂掉;
ii.主节点如果是恶意节点,是否可以通过篡改消息来作恶呢,如果是的话又会怎样 首先,肯定是可以的,但是要分两方面来说,如果是篡改客户端发来的消息,这个是行不通的,会被备份节点通过检查签名发现问题,注意一般单纯用pbft的都是封闭系统,客户端也是要经过注册的, 当然主节点可以完全用自己的私钥来签名发起一个恶意的消息,客户端通过公钥验证是肯定通过的,这种情况从算法角度看是无法解决的;
iii.为什么prepare和commit是等待2f+1不是f+1个消息, 对于paxo或raft等基于CFT算法f+1个消息就能少数服从多数过半数确定下一步,但是为什么PBFT需要2f+1才能确定下一步呢? PBFT的理论之一quorum replication [Gifford 1979] 假设节点总数为|R|的共识系统中选择|Q|个节点作为一个仲裁机制,需要保证这任意两个Q必须至少得有一个节点交集,不然可能会导致不一样的共识结果,根据韦恩图的计算法则: 2|Q| - |R| >= 1 => |Q| >= (|R| + 1) / 2, 对于CFT,|R| = 2 f + 1 => |Q| >= f + 1 这是针对CFT的情况,对于BFT交集还得容纳f个恶意节点 2|Q| - |R| >= 1 + f => |Q| >= (|R| + f + 1) / 2, |R| = 3 f + 1 => |Q| >= 2f + 1
举个例子,假设f=2,3*2+1=7个节点的情况下,i=0,1,2,3,4,5,6 其中5,6是坏节点,假设prepare阶段,极端情况每个节点0 1 2 3 4都先收到了5和6的假消息及f个假消息,加上各自节点自己的1个消息, 是f+1个,可见,这种情况下就达成共识就是错误的结果或者达不成共识,取决于具体实现,比如至少不应该进入下一步; 对于CTF的f+1,是因为挂掉的节点无法发消息,所以f+1是为了假设半数发的是旧消息proposer,所以用过半来做判断确认半数认为这个消息是可以共识的;
- iv.为什么client是等待f+1个reply 前面说了根据qurom理论,任意两个Q至少一个交集,并且允许容纳f个恶意节点,所以f+1隐含的意思是即使有f个都是恶意节点,至少一个节点的reply是诚实的,有一个诚实节点隐含着客户端的操作已经达成共识操作完成;
拜占庭容错算法有着很多限制:
- A.需要保证网络上不超过1/3的节点作恶,
1/3的来源是前面拜占庭将军问题的反证法,另外根据前面的quorum理论也能证明, 对于一个permissioned network比如公司内网或者类似类似hyperledger这有的联盟链来说比较容易监控, 但是对于一个开放式的网络,每分钟都可能有节点加入退出,根本无从监控和得知某个时间范围内到底有多少恶意节点,简单的数学模型是无法解决这个问题的,
- B.节点数过多会影响PBFT节点达成共识的速度,我们简单计算下互相发送的信息数量就大概知道随着节点增多这种共识方式是不实际的
pre-prepare的消息数是接收者排除主节点自己1*(3f+1-1)=3f
prepare是【2f3f,3f3f】: 最少:发送者排除主节点和坏节点:3f+1-1-f=2f,接收者排除自己3f+1-1=3f 最多:发送者排除主节点:3f+1-1=3f,接收者排除自己3f+1-1=3f
commit是【(3f+1-f)(3f+1),(3f+1)3f】; 最少:发送者排除坏节点:3f+1-f=2f+1,接收者排除自己:3f+1-1=3f 最多:发送者:3f+1,接收者排除自己3f+1-1=3f
repy是【2f+1,3f+1】
- C.拜占庭容错算法本身是易于被Sybil attack (opens new window), 因为默认情况下一个节点不需要花费任何代价就很容易伪造多个身份,由上面我们可以看到节点的区分只是序号i,
当然我们看到除了i之外还有签名,签名就涉及用公钥验证,如果我们可以保证这些节点是可以“中心化”去管理公私钥配置的就可以防止sybil attack,不过代价是又变回了封闭式的系统,hyerledger, 对于一个closed system只要加上类似的身份控制就可以避免sybil attack,sybil attack只针对"decentralized and permissionless peer to peer network";
在实际项目中pbft经常是跟其他算法一起使用,比如Zilliqa就是结合pbft和POW,另外PBFT看起来感觉跟paxos有几分相似,确实,实际上paxos可以升级成BFT paxos,也有raft版本的BFT raft;
从故障容错到拜占庭容错,我们算是跳跃了一步,允许有恶意节点,但是限制为不超过全网1/3的恶意节点, 我们接下来还要再跳跃更大的一步,因为我们要面向全网,不做任何限制:不限制节点数,无法得知恶意节点数,节点可以任意时刻加入退出,同时我们还要保证节点达成正确的共识结果, 下面我们看下比特币是如何做到的
# 3.3 比特币共识算法
1.第一步 共识的门票:创造随机事件
首先,比特币的业务比较简单(其实可以通过bitcoin script制造很多复杂的场景,具体可以学习Mastering Bitcoin (opens new window)), 基本场景就是Alice给bob转一定数目的bitcoin,
现在问题是,这么简单的一项业务功能,Alice转给bob 0.1个btc,验证,打包,落库(发布到链上,即大部分节点同意把新区块放到各自的本地最长的区块链头上),整过过程是谁发起的呢?
开始,Alice通过自己喜欢的比特币钱包或者命令行(或者自己编写的比特币钱包)生成交易,钱包通过P2P协议把签名好的交易广播出去,接下来的问题是谁来验证打包?
我们前面谈了那么多复杂的算法,基本都是要选一个leader出来做事情,而比特币的目的是节点之间大家都是平等的,没有leader worker之分,参与节点都有打包的权利, 首先为什么有人想要打包,这是因为有incentive激励机制,打包成功可以获取若干比特币作为奖励,还可以获取区块中每笔交易的费用,继续打包权利游戏, 比特币为此创造了一个猜谜游戏,我们称作工作量证明POW,简单来说,这个游戏就是定一个目标:打包好的区块的区块头取SHA256哈希值需要小于二进制01000000即64的数值即0到63之间的任何值, 而且找到后要立即全网广播,
区块头包含版本号,上一个区块的哈希值,默克尔树根哈希,时间戳,难度目标,随机值nonce,其中默克尔树根的哈希简单来说就是以交易作为叶子节点的哈希树的树根,哈希的哈希, 可见这里面很多变量,所以最终获取一个小于目标01000000的哈希值是很不容易的事情,找不到就需要调整Nonce值,再不行就需要调整区块中的交易,总之是一个很激烈的随机数寻找游戏, 至于难度值,简单理解,如果调高,比如目标变成00100000,前面0多了一个,可选的就剩下0到31,缩了一半,靶子越小越难打,如果全网算力提高,比特币会动态调整难度,保持平均每10分钟出一个区块的速度,
一轮游戏就是代表一个区块的产生,游戏又称挖矿,参与竞争的节点也叫矿工节点;
比特币创造的这个随机游戏,为后面泊松分布的证明写下了伏笔;
另外由于比特币创造性的使用了脚本技术也保证了交易本身无法被篡改,比如最基础的P2PKH (pay to public key hash):
保险箱scriptPubKey: OP_DUP OP_HASH160
解锁scriptSig:<Sig><PubKey>

虎符拼起来:<Sig><PubKey> OP_DUP OP_HASH160
OP_DUP(PubKey)=PubKey
OP_HASH160(PubKey) = PubKeyHash
OP_EQUALVERIFY(PubKeyHash,PubKeyHash)==TRUE
OP_CHECKSIG(Sig)==TRUE
就是这么简洁优美
当然还有其他的比如P2SH(pay to script hash),在以后区块链的文章里会再解析,这里不赘述;
还有一个概念是utxo即未花费输出unspent transaction output,在比特币的世界中,比特币是以utxo的形式存在的,每个比特币,准确说是每个fraction of bitcoin, 或者每个satoshi(比特币最小单位)都是以utxo的形式存在脚本保险箱中,只有私钥的持有者才可以打开保险箱取出utxo使用; 因此解决了拜占庭将军传递假消息的问题,除了私钥拥有者,没有人能够伪造或者篡改交易,从而可以让交易通过不安全的网络传输,不管是公网还是蓝牙设置卫星通信都可以;
好像讲到这里漏了点什么,对的,我前面说了POW工作量证明的原理以及这个游戏规则,那么可能会有很多节点几乎同时或者先后找到小于目标值的谜底并广播出去, 那么这一轮到底谁算获胜者呢,第一个找到谜底的人?第一个找到并广播出去的人?
这里不得不说很多人将POW和POS误解为共识算法,我在另外一篇文章是专门讲了这个问题解密挖矿与共识的误解 (opens new window),
至于谁是某一轮游戏的获胜者,还要各位往下接着看
2.第二步 长链胜出:泊松分布的胜利
揭晓谜底,我们假设当前区块高度是666666,区块高度就是目前链上的区块数,假设我们就一条干干净净的链,从第一块算起,现在是第666666个区块, 先假设一个极端情况只有M1 M2 M3这3个节点参与挖矿,M1率先打包了一个新的区块并满足条件,然后迅速广播出去, 其他节点收到消息之后full validate block and activate best chain,即验证区块中每笔交易的合法性,如果有不合法的则区块失效, 所以所有节点最开始在接收到交易的时候就应该做验证,否则后面打包无效交易也是浪费自己的算力, 如果区块合法,M2和M3就立即connect to the tip并激活best chain,就是将M1打包的区块作为第666667个区块加到链的顶端;
那么寻找第666667个区块的游戏的胜出者就是M1吗,M1可以立即拿到矿工奖励吗? 答案是未必,因为现实世界是在M1出包的同时,还有可能上千个其他节点也出包了,甚至是别的节点出包落后,但是网络比M1的快,更快的覆盖全网最多的节点, 所以实际上在每个出包的时候,全网节点上的区块链一般都是处于分叉状态,有的同步到M1,有的同步到比如M100,所以第666667个区块现在可能有两个, 那么就要看下一轮第666668个区块是谁挖的,假设666668这个区块是M2挖的,刚好M2又是支持M1的,即666668个区块是基于M1挖到的666667个区块之上挖的, 我们说666667这个区块现在有了2个确认,全网其他节点假设他们上面还是停留在M100的666667个区块高度,那么随着M2的666668的广播,他们会迅速切换到最长链上, 此刻就是以M2为首的666668个区块;
退一步说再假设区块666668这个高度的时候,刚好M2挖到的时候又有M200挖到第666668个区块并且M200是基于M100的第666667挖的,此刻全网仍然是两条链不分伯仲,随着游戏的继续进行,总会分出胜负, 在实际情况下,一般都是一两个区块的临时分叉,不太会有更多的区块分叉,除非是全球网络刚好因为灾害导致长时间物理隔离成了多个分区,那么各自分区肯定是各自的长链, 随着网络恢复,肯定还会选出一个最长链,一个区块是10分钟,而且前面提到的奖励确实是挖到新区块就产生的,但是这个奖励需要100个确认才能被使用,意思是100×10分钟=16个多小时, 全球网络断开16多个小时除了世界大战我是想不到还有什么会造成这个状况,所以小概率事件可以忽略;
说到这里基本原理都说完了,但是还是缺点东西,因为前面说的都是正常的节点竞争,我们现在谈的是基于拜占庭将军问题的共识,自然少不了恶意节点, 前面又说了因为密码学保证了恶意节点无法篡改现有交易,但是恶意节点还可以干另外一件事情:
通过前面分析,我们大概知道比特币这条链因为竞争挖矿时刻处于一两个区块的分叉之中,不过一般我们说等待6个确认就可以认为交易成功了,为什么是6个确认? 我们先说恶意节点可以做的一件坏事就是尝试双花攻击double spent,恶意节点首先做一笔交易从evil比特币账号卖给Alice 20个比特币,完全合法的交易,并且Alice的比特币钱包确实也收到了, 显示目前是一个确认,然后又等了一会变成2个确认,Alice开心的通知第三方平台把押金释放给evil的银行帐号, 其实恶意节点在广播给Alice20个比特币之前就悄悄生成了另一笔交易,将那20个比特币转给自己的另外一个比特币地址,并且已经悄悄打包好了一个甚至是多个区块,Alice不是看到了2个确认吗, 恶意节点准备了3个区块,立马广播出去,变成最长链,Alice看到的两个确认的区块作废,被全网抛弃,全部切换为更长的链,恶意节点一毛钱没花,还挣了3个区块的矿工奖励,额外还有Alice的银行资金;
上面这个理论是成立的,概率有多大呢,跟6个确认又有啥关系呢?
在《Bitcoin: A Peer-to-Peer Electronic Cash System》里有着清晰的证明,泊松分布提供了理论依据:

泊松分布比较简单就不再介绍,当n趋向无穷,及把离散事件变成连续事件,可以推导出泊松分布公式也不难,至于泊松密度,我的数学也是半桶水,所以就给了比较简单的注释:
k>z,每一次随机事件中攻击者都会得逞,所以是这里的泊松密度是1, 而k<=z,攻击者需要z-k个区块才能追上诚实节点,然后每一个区块成功的可能是q/p,每次都是独立的,所以是(q/p)^(z-k);
由图上面的计算可见只要单节点的算力不高,超过5个确认之后,恶意节点成功的概率都会很低,如果觉着数学难,再来一张比较直觉的图
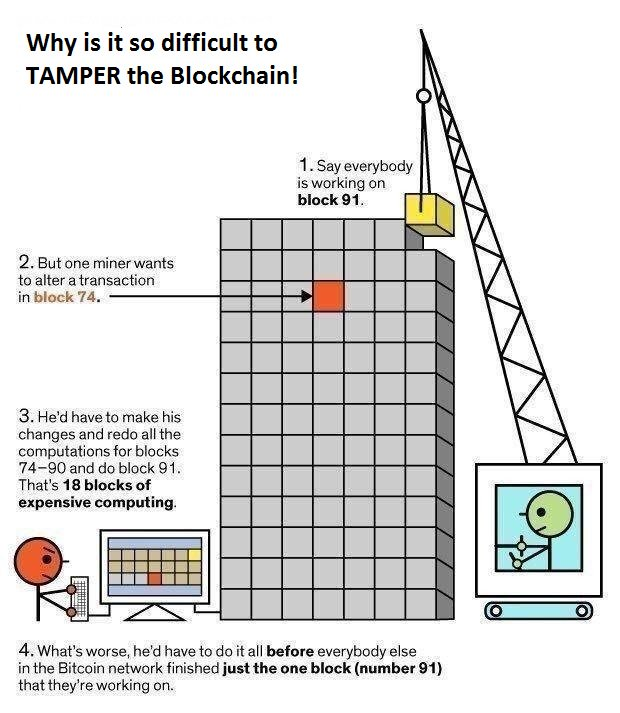
实际上比特币作为一个史无前例的社会实验,是密码学、软件、经济、哲学的混合产物,
destroying the Bitcoin system will also undermine the effectiveness of his own wealth
所以对于理性的节点来说,利益驱使下去正常挖矿获得收益也比想办法作弊恶意攻击的收益大的多;
综上所述,这些理论的总和就构成了nakamoto consensus中本聪共识算法, 至此我们相对完整的从故障容错讲到拜占庭容错,从传统的分布式系统讲到新兴的区块链技术, 希望对大家有所帮助,话题有点大,难免有所疏漏,欢迎批评指正
ref:
Zab in words (opens new window)
Paxos lecture (Raft user study) (opens new window)
Paxos Made Simple (opens new window)
Paxos By Example (opens new window)
图解分布式一致性协议Paxos (opens new window)
Visualizations Raft: Understandable Distributed Consensus (opens new window)
基于quartz和zookeeper的分布式调度设计 (opens new window)
Hyperledger Fabric (opens new window)
Optimizing and Implementing Paxos (opens new window)
Analyzing Bitcoin Security (opens new window)
Practical Byzantine Fault Tolerance (opens new window)
From Distributed Consensus Algorithms to the Blockchain Consensus Mechanism (opens new window)
Implementing PBFT in Blockchain (opens new window)
pBFT— Understanding the Consensus Algorithm (opens new window)
Practical Byzantine Fault Tolerance and Proactive Recovery (opens new window)
The Byzantine Generals Problem (opens new window)
BITCOIN WHITEPAPER (opens new window)
Clustering by Consensus (opens new window)
Additional info: pbft notes (opens new window)
Suppose you have N replicas, f of which might crash (non-Byzantine failure)
What quorum size Q do you need to guarantee liveness and safety?
* Liveness: (or pseudo-liveness, i.e., avoiding stuck states)
There must be a non-failed quorum (*quorum availability*)
Hence: Q <= N - f
* Safety: Any two quorums must intersect at one or more nodes
Otherwise, two quorums could independently accept operations, diverge
This property is often known as the *quorum intersection* property
Hence: 2Q - N > 0
So: N < 2Q <= 2(N - f)
Note highest possible f: N < 2N-2f; f < N/2
And if N = 2f + 1, smallest Q is 2Q > 2f + 1; Q = f + 1
Now say we throw in Byzantine failures. One view...
Say you have N nodes, f of which might experience Byzantine failure.
First, how can Byzantine failures be worse than non-Byzantine?
Byzantine nodes can vote for both a statement and its contradiction
Make different statements to different nodes
Consequences
Risks driving non-failed nodes into divergent states
Risks driving non-failed nodes into "stuck states"
E.g., cause split vote on seemingly irrefutable statement
Paxos example: You think majority aborted some ballot b v
You vote to commit b' v' (where b' > b, v' != v)
Can't convince other nodes it is safe to vote for b'
What quorum size Q do we need in Byzantine setting?
* Liveness: Q <= N - f
As in non-Byzantine case, failed nodes might not reply
* Safety: Quorum intersection must contain one non-faulty node
Idea: out of f+1 nodes, at most one can be faulty
Hence: 2Q - N > f (since f could be malicious)
So: N + f < 2Q <= 2(N - f)
Highest f: N+f < 2N-2f; 3f < N; f < N/3
And if N = 3f + 1, the smallest Q is:
N + f < 2Q; 3f + 1 + f < 2Q; 2f + 1/2 < Q; Q_min = 2f + 1
So how does PBFT protocol work?
Number replica cohorts 1, 2, 3, ..., 3f+1
Number requests with consecutive sequence numbers (not viewstamps)
System goes through a series of views
In view v, replica number v mod (3f+1) is designated the primary
Primary is responsible for selecting the order of operations
Assigns an increasing sequence number to each operation
In normal-case operation, use two-round protocol for request r:
Round 1 (pre-prepare, prepare) goal:
Ensure at least f+1 honest replicas agree that
If request r executes in view v, will execute with sequence no. n
Round 2 (commit) goal:
Ensure at least f+1 honest replicas agree that
Request r has executed in view v with sequence no. n
Protocol for normal-case operation
Let c be client
r_i be replica i, or p primary, b_i backup i
R set of all replicas
c -> p: m = {REQUEST, o, t, c}_Kc
p -> R: {PRE-PREPARE, v, n, d}_Kp, m (note d = H(m))
b_i -> R: {PREPARE, v, n, d, i}_K{r_i}
[Note all messages signed, so will omit signatures and use < > henceforth.]
replica r_i now waits for PRE-PREPARE + 2f matching PREPARE messages
puts these messages in its log
then we say prepared(m, v, n, i) is TRUE
Note: If prepared(m, v, n, i) is TRUE for honest replica r_i
then prepared(m', v, n, j) where m' != m FALSE for any honest r_j
So no other operation can execute with view v sequence number n
Are we done? Just reply to client? No
Just because some other m' won't execute at (v,n) doesn't mean m will
Suppose r_i is compromised right after prepared(m, v, n, i)
Suppose no other replica received r_i's prepare message
Suppose f replicas are slow and never even received the PRE-PREPARE
No other honest replica will know the request prepared!
Particularly if p fails, request might not get executed!
So we say operation doesn't execute until
prepared(m, v, n, i) is TRUE for f+1 non-faulty replicas r_i
We say committed(m, v, n) is TRUE when this property holds
So how does a replica *know* committed(m, v, n) holds?
Add one more message:
r_i -> R: <COMMIT, v, n, d, i> (sent only after prepared(m,v,n,i))
replica r_i waits for 2f+1 identical COMMIT messages (including its own)
committed-local(m, v, n, i) is TRUE when:
prepared(m, v, n, i) is TRUE, and
r_i has 2f+1 matching commits in its log
Note: If committed-local(m, v, n, i) is TRUE for any non-faulty r_i
Then means committed(m, v, n) is TRUE.
r_i knows when committed-local is TRUE
So committed-local is a replica's way of knowing that committed is TRUE
r_i replies to client when committed-local(m, v, n, i) is TRUE
Client waits for f+1 matching replies, then returns to client
Why f+1 and not 2f+1?
Because of f+1, at least one replica r_i is non-faulty
So client knows committed-local(m, v, n, i)
Which in turn implies committed(m, v, n)
Note tentative reply optimization:
r_i can send tentative reply to client after prepared(m, v, n, i)
Client can accept result after 2f+1 matching tentative replies. Why?
f+1 of those replies must be from honest nodes
And at least 1 of those f+1 will be part of 2f+1 forming a new view
So that 1 node will make sure operation makes it to new view
Garbage collecting the message log
make periodic checkpoints
Broadcast <CHECKPOINT, n, d, i>, where d = digest of state
When 2f+1 signed CHECKPOINTs received
restrict sequence numbers are between h and H
h = sequence number of last stable checkpoint
H = h + k (e.g., k might be 2 * checkpoint interval of 100)
delete all messages below sequence number of stable checkpoint
View changes
When client doesn't get an answer, broadcasts message to all replicas
If a backup notices primary is slow/unresponsive:
- broadcast <VIEW-CHANGE v+1, n, C, P, i>
C is 2f+1 signed checkpoint messages for last stable checkpoint
P = {P_m} where each P_m is signed PRE-PREPARE + 2f signed PREPARES
i.e., P is set of all PREPAREd messages since checkpoint
+ proof that the messages really are prepared
When primary of view v+1 sees 2f signed VIEW-CHANGE messages from others
- New primary broadcasts <NEW-VIEW, v+1, V, O>
V is set of at lesat 2f+1 VIEW-CHANGE messages (including by new primary)
O is a set of pre-prepare messages, for operations that are:
- after last stable checkpoint
- appear in the set P of one of the VIEW-CHANGE messages
O also contains dummy messages to fill in sequence number gaps
Replicas may optain any missing state from each other
(e.g., stable checkpoint data, or missing operation, since
reissued pre-prepare messages only contain digest of request)
What happens if primary creates incorrect O in NEW-VIEW message?
E.g., might send null requests for operations that prepared
Other replicas can compute O from V, and can reject NEW-VIEW message
What happens if primary sends different V's to different backups?
Still okay, because any committed operation will be in 2f+1 VIEW-CHANGE msgs
of which f+1 must be honest, so at least one member of V will have operation
So new primary cannot cause committed operations to be dropped
Only operations for which client has not yet seen the answer
Discussion
what problem does BFS solve?
- is IS going to run BFS to deal with byzantine failures?
- what failures are we talking about?
compromised servers
- what about compromised clients?
authentication and authorization
how can we extend the system to allow for more than (n-1)/3
failures over its lifetime?
- detect failed replicas using proactive recovery
- recover the system periodically, no matter what
- makes bad nodes good again
- tricky stuff
- an attacker might steal compromised replica's keys
- with how many replicas will BFS work reasonably well?
Eventual consistency is a consistency model used in distributed computing to achieve high availability that informally guarantees that, if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value.[1] Eventual consistency is widely deployed in distributed systems, often under the moniker of optimistic replication,[2] and has origins in early mobile computing projects.[3] A system that has achieved eventual consistency is often said to have converged, or achieved replica convergence.[4] Eventual consistency is a weak guarantee - most stronger models, like linearizability are trivially eventually consistent, but a system that is merely eventually consistent doesn't usually fulfill these stronger constraints.
Eventually consistent services are often classified as providing BASE (Basically Available, Soft state, Eventual consistency) semantics, in contrast to traditional ACID (Atomicity, Consistency, Isolation, Durability)guarantees.[5][6] Eventual consistency is sometimes criticized[7] as increasing the complexity of distributed software applications. This is partly because eventual consistency is purely a liveness guarantee (reads eventually return the same value) and does not make safety guarantees: an eventually consistent system can return any value before it converges.
In order to ensure replica convergence, a system must reconcile differences between multiple copies of distributed data. This consists of two parts:
exchanging versions or updates of data between servers (often known as anti-entropy);[8] and
choosing an appropriate final state when concurrent updates have occurred, called reconciliation.
The most appropriate approach to reconciliation depends on the application. A widespread approach is "last writer wins".[1] Another is to invoke a user-specified conflict handler.[4] Timestamps and vector clocks are often used to detect concurrency between updates.
Reconciliation of concurrent writes must occur sometime before the next read, and can be scheduled at different instants:[3][9]
Read repair: The correction is done when a read finds an inconsistency. This slows down the read operation.
Write repair: The correction takes place during a write operation, if an inconsistency has been found, slowing down the write operation.
Asynchronous repair: The correction is not part of a read or write operation.
Whereas EC is only a liveness guarantee (updates will be observed eventually), Strong Eventual Consistency (SEC) adds the safety guarantee that any two nodes that have received the same (unordered) set of updates will be in the same state. If, furthermore, the system is monotonic, the application will never suffer rollbacks. Conflict-free replicated data types are a common approach to ensuring SEC.[10]