# Socket '协议'
Note: an abstraction provided by the operating system to allow communication between applications over a network. Sockets can operate over different transport protocols, such as TCP or UDP.
websocket是完整的应用层协议,所以不会访问raw tcp packets,但是常用的socket是可以的,因为它是基于应用层和传输层的抽象接口,并不是一个协议;Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口(API)。我们所说的TCP/IP网站栈是在操作系统内核实现的,而Socket就是操作系统内核提供给应用层的一系列接口,Socket封装了TCP/IP,
通常应用层的协议都是基于这个socket接口进行设计开发的,socket五元组(protocol[TCP/UDP],source IP,source PORT, destination IP, destination PORT),系统调用传给TCP接口,具体参考Socket 系统调用深入研究(TCP协议的整个通信过程) (opens new window):
服务器端三部曲: socket(生成一个用于通信的套接字文件描述符 sockfd) bind listen
客户端 connect 在发起 connect() 之前,连接发起方也需要生成一个 sockfd, 发起 connect 触发 TCP三次握手, 其中第一次握手client端主动向server端发起syn请求建立连接请求,server端收到后将与client端的连接设置为listen状态(半连接状态)并保存到半连接队列/backlog队列。
第三次client向server端发送一个ack响应,告诉server端收到。然后server端收到后将与client端的连接设置为established状态(全连接状态)。同样,全连接状态在server端也需要一个backlog队列存储。这里的backlog队列也叫全连接队列。 backlog其实是一个连接队列,在Linux内核2.2之前,backlog包括半连接状态和全连接状态两种队列。在Linux内核2.2之后,分离为两个backlog来分别限制半连接(SYN_RCVD状态)队列大小和全连接(ESTABLISHED状态)队列大小。服务器端accept: 一旦有客户端尝试建立连接,服务器端就会调用accept函数来接受这个请求,并为这个新的连接创建一个新的套接字专门用于与该客户端的通信,accept函数并不直接对应三次握手的某一步,而是发生在握手过程后,在TCP三次握手成功完成后,服务器端的 accept 调用才会返回,此时服务器得到了一个新的套接字,这个套接字就用于与刚刚完成握手的客户端进行数据传输。 accpet() 函数的作用是读取已完成连接队列中的第一项(读完就从队列中移除),并对此项生成一个用于后续连接的套接字描述符(姑且用 connfd 来表示),有了新的连接套接字,用户进程/线程(称其为工作者)就可以通过这个连接套接字和客户端进行数据传输,而前文所说的监听套接字(sockfd)则仍然被监听者监听。
accept() 函数是由用户空间进程发起,由内核空间消费操作,只要经过 accept() 过的连接,连接将从已完成队列(accept queue)中移除,也就表示 TCP 已经建立完成了,两端的用户空间进程可以通过这个连接进行真正的数据传输了,直到使用 close() 或 shutdown() 关闭连接时的四次挥手,中间再也不需要内核的参与。
经过 accept() 函数后,tcp 连接的套接字从 sockfd 变成了 connfd ,也就是说,经过 accept() 之后,这个连接和 sockfd 套接字已经没有任何关系了。
客户端 和 服务器端互相 send recv 现在计算机A与计算机B建立了Socket连接,这时候计算机A要发送数据给计算机B,不是直接就发送过去,Socket发送数据首先需要经过Socket的读写缓冲区,用户态的数据,要想发送到互联网上,必须先把数据拷贝到内核态,由内核态帮我们把数据发送出去。 因此,计算机每创建一个socket,cpu就会在内存中为它分配一对读写缓冲区,读写缓冲区在内核态,它的大小不随数据大小而改变。 要使用TCP/IP来发送数据,就调用Socket的OutputStream,要使用TCP/IP接收数据,就调用Socket的InputStream, 计算机A想发数据到计算机B,首先计算机A把用户态的数据拷贝到内核态的输出缓冲区,再由把输出缓冲区的数据通过互联网发送到计算机B的输入缓冲区,计算机B把输入缓冲区的数据拷贝到用户态,就完成了一次数据的发送和接收。 由于数据缓冲区的大小有限,如果数据缓冲区里有数据没有发送出去,用户态这时候又有其他数据要发送,数据缓冲区的空间就不够用了,就会造成一系列问题。如果计算机B要接收数据,而一直没有收到计算机A发送过来的数据,导致输入缓冲区一直为空,也会造成问题。 对于上面这些存在的问题,linux有5种解决方案,这就是linux的5大IO模型。具体的工作模型在这里:基础:BIO/NIO/多路复用
所有应用层协议都是基于socket?
Protocols like HTTP, WebSocket, and RPC are built on top of the transport layer (which often uses TCP). They define how data is formatted and transmitted but rely on sockets (and typically TCP) for the underlying transport mechanism.So, while it's accurate to say that these application protocols often utilize sockets, they are not exclusively "built on sockets" but rather built on the transport services provided by protocols like TCP, which are accessed via sockets.
socket也常常作为不同主机之间两个进程间通信的“协议”,有个特殊情况是,如果是本机进程间通信,有个特别的所谓socket Unix域套接字(Unix Domain Socket)https://blog.csdn.net/roland_sun/article/details/50266565,例子gitlab server、haproxy
Socket 支持 HTTP 通信原理揭秘 (opens new window)
TCP三次握手最后一个ACK数据包丢失会发生什么? (opens new window)
TCP三次握手后没有数据发送可能有以下几种原因和相应的影响:
- ACK包丢失
如果客户端在第三次握手后丢失了ACK包,服务器会重传SYN+ACK包。重传次数由net.ipv4.tcp_synack_retries内核参数决定。如果重传次数达到最大值,服务器会重置连接。
- 客户端发送数据过早
即使ACK包丢失,客户端在收到SYN+ACK包后也可以发送数据。客户端在发送数据时,需要将ACK标志位置为1。这样,服务端会接收到带有ACK标志的数据报文,并认为收到了最后的确认,从而正常建立连接并接受数据。
- 服务器未进入established状态
如果服务器在收到ACK包后仍处于SYN_RECEIVED状态,它会认为连接未建立成功,并发送RST包(重置连接)给客户端。这种情况下,客户端会收到RST包,连接会关闭。
- SYN Flood攻击
SYN Flood攻击是一种常见的网络攻击,攻击者通过大量发送SYN包使服务器进入SYN_RECEIVED状态并等待不存在的ACK包,导致服务器资源耗尽。这种情况下,即使完成了三次握手,服务器也无法处理正常的TCP请求。
- 服务器资源耗尽
在SYN_RECEIVED状态下,服务器会分配资源(如内存、CPU时间等)用于维护这个未完全建立的连接。如果大量连接处于这种状态,将严重消耗服务器资源,影响正常服务的性能。
应对措施
优化超时重传机制:根据网络状况动态调整net.ipv4.tcp_synack_retries的值,确保既能有效应对丢包问题,又能避免不必要的重传。
增强防御能力:针对SYN Flood攻击,可以采取增加SYN队列长度、启用SYN cookies机制等措施来减轻攻击影响。
资源监控与调优:实时监控服务器资源使用情况,及时发现并处理资源耗尽问题。
客户端重试策略:客户端在发送数据前应确认连接状态,避免在连接未建立时发送数据。同时,合理设置重试间隔和重试次数,以减少对网络的冲击。
通过这些措施,可以有效应对TCP三次握手后没有数据发送的问题。
# 正常的客户端最后一个ACK丢了会发生什么
第三次握手的时候,客户端发送的ack包,如果丢失,没有被服务端收到。那服务端就会重传SYN+ACK包,重传次数由net.ipv4.tcp_synack_retries内核参数决定,达到最大次数之后,还没有收到ACK确认报文,服务端就会重置连接。客户端在接收到服务端的syn+ack包之后,再发送ACK确认,只要服务端收到最后的ACK,那三次握手就会完成,连接链接。
# 如果最后一个ACK丢失,客户端以为已经进入了established状态了,如果它这个时候发送了数据给服务端,服务端接收到数据,会发生什么?
在最后一个ACK丢失的情况,如果客户端没有及时传输数据的情况下,服务端会重传SYN+ACK。但是如果客户端立即发送数据呢?
客户端在接受到服务端的SYN+ACK之后,在发送最后一个ACK报文的时候,其实是可以带上数据的。TCP协议规定,数据报文是需要将ACK标志位置为1。在最后一个ACK丢失的情况下,如果客户端直接发送数据报文,会将ACK标志位置为1,服务端收到这个数据报文之后,同样会认为收到了最后的确认。会正常建立连接,并会正常接受客户端发送过来的数据。
# TCP 粘包 拆包问题
要了解这些框架的原理首先要搞明白TCP本身的原理,最重要的一个问题是: TCP面向字节流,UDP面向报文段,TCP的报文段呢?
问题的关键在于TCP是有缓冲区,作为对比,UDP面向报文段是没有缓冲区的。 TCP发送报文时,是将应用层数据写入TCP缓冲区中,然后由TCP协议来控制发送这里面的数据,而发送的状态是按字节流的方式发送的,跟应用层写下来的报文长度没有任何关系,所以说是流。 作为对比的UDP,它没有缓冲区,应用层写的报文数据会直接加包头交给网络层,由网络层负责分片,所以是面向报文段的。 https://www.zhihu.com/question/34003599/answer/204379413
- UDP Message oriented, you have an API (send/recv and similar) that provide you with the ability to send one datagram, and receive one datagram. 1 send() call results in 1 datagram sent, and 1 recv() call will recieve exactly 1 datagram.
- TCP Stream oriented, you have an API (send/recv and similar) that gives you the ability to send or receive a byte stream. There is no preservation of message boundaries, TCP can bundle up data from many send() calls into one segment, or it could break down data from one send() call into many segments - but that's transparent to applications sitting on top of TCP, and recv() just gives you back data, with no relation to how many send() calls produced the data you get back. TCP vs UDP - Explaining Facts and Debunking Myths (opens new window) TCP - 12 simple ideas to explain the Transmission Control Protocol (opens new window) 所以说TCP本质是一个面向字节流的协议,本质是流式的,如同水流,没有分段,无法得知何时开始结束, 而TCP提供了可靠的流控方式:滑动窗口sliding window (opens new window),简单来说这个滑动窗口跟收发两端的缓存有关,可以控制“流速”;
由于这个滑动窗口的存在,跟发送端和接收端的收发节奏和表现出来的现象形象分为“拆包和粘包”问题:
首先包(Packet)的定义:在包交换网络里,单个消息被划分为多个数据块,这些数据块称为包,它包含发送者和接收者的地址信息。这些包然后沿着不同的路径在一个或多个网络中传输,并且在目的地重新组合。
打个比方,发送端先后发送两个信息 hello和world,接收端正常是期待同样先后收到hello和world, 但是因为tcp流,假设滑动窗口是1024字节,接收端可能会一次收到 helloworld连起来,这叫做“粘包”, 假设滑动窗口很小4个字节,接收端则会收到类似 hell o worl d 这种所谓“拆包”或者 hell owor ld 这种拆包+粘包;
粘包问题的处理一般是加“分隔符”来标志一个包packet结束; 拆包问题则是一般加上长度length字段,让接收方知道这个包的长度,比如10M,接收端可以把这些拆的包合并起来;
很多应用层的协议已经帮我们解决了这些问题,而其他有些则根据不同的实现有些是解决了有些则可能存在偷懒(给出更大的自由度)而没有解决比如netty,所以当问到websocket是否存在粘包问题时,只能说websocket的rfc标准是不需要处理粘包问题的,但是netty也是支持websocket(存在偷懒),但是基于netty的websocket就需要注意粘包问题
粘包 Sticky Packets problem Sticky packets occur when multiple packets are combined or treated as one, causing confusion during the reading of data. This can happen for several reasons:
- Data Stream Nature: TCP is a stream-oriented protocol, meaning it delivers a continuous flow of bytes. When applications read data, they may receive a single read call that retrieves multiple packets' worth of data, leading to a situation where they need to determine where one packet ends and the next begins. the sender uses the optimization method (Nagle algorithm) in order to send multiple packets to the receiver more efficiently. Combine data with small intervals and small data volume into one large data block, and then perform packetization. In this way, the receiving end is difficult to distinguish, and a scientific unpacking mechanism must be provided. That is, stream-oriented communication is border-less with message protection.
- Buffering Issues: Network buffers may store packets, and when data is read from a buffer, it can include parts of multiple packets. This can lead to application-level issues if the application is not designed to handle such cases. When the length of the sender buffer is greater than the MTU of the network card, TCP will split the data sent this time into several data packets and send it out. MTU is the abbreviation of Maximum Transmission Unit. It means the largest packet transmitted on the network. The unit of MTU is a byte. Most network devices have an MTU of 1500. If the MTU of the machine is larger than the MTU of the gateway, large packets will be disconnected and transmitted, which will generate a lot of packet fragmentation
拆包 Unpacking Packets Unpacking packets refers to the process of extracting individual packets from a data stream. Since TCP does not preserve message boundaries, applications must implement their own logic to parse the incoming data. This typically involves:
Defining Protocol Structure: Knowing the structure of the packets being sent (headers, payload size) allows the application to correctly identify where each packet starts and ends.
Handling Partial Data: When reading from the stream, the application may need to handle cases where it receives only part of a packet and must wait for more data to arrive.
Solutions To address sticky packets and unpacking issues, developers often use several techniques:
Length Prefixing: Prepend a fixed-size header to each packet that indicates its length. This helps the receiver know how many bytes to read.
Delimiter-Based Protocols: Use special characters to signify the end of a packet, similar to how HTTP headers work.
State Machines: Implementing a state machine to track the state of the incoming data and correctly assemble packets.
Note: The extra header you're referring to is part of the application data and not the TCP protocol headers.
Example: http
Message Boundaries HTTP is a request-response protocol with well-defined message boundaries. Each HTTP message is separate and includes headers that indicate the start and end of the message. This structure helps the receiving application know when one message ends and another begins.
Content-Length Header When sending data, HTTP includes a Content-Length header in the request or response. This header specifies the exact size of the payload, allowing the receiving application to read the specified number of bytes, thereby avoiding issues with sticky packets.
Chunked Transfer Encoding For cases where the content length is not known in advance, HTTP can use chunked transfer encoding. In this method, data is sent in chunks, each preceded by its size, allowing the receiver to identify the end of each chunk and assemble the complete message.
Connection Management HTTP/1.1 uses persistent connections by default, allowing multiple requests and responses to be sent over a single TCP connection. This design helps manage the flow of data without causing confusion between messages.
Standardized Parsing Libraries Most programming languages and frameworks provide robust HTTP libraries that handle parsing and managing HTTP messages, abstracting away the complexities of sticky packets and unpacking issues. These libraries ensure that applications receive data in the correct format.
现在回答问题: 客户端通过TCP和UDP发三个包,服务端会收到多少个包 (opens new window)
发数据端:
应用程序-->>操作系统内核调用-->>socket-->>TCP/UDP传输层-->IP网络层-->MAC数据链路层-->网卡驱动-->>网卡物理层-->互联网
收数据端:
互联网-->>网卡物理层-->>网卡驱动-->MAC数据链路层-->IP网络层-->TCP/UDP传输层-->socket-->内核-->应用层
当通过TCP发送数据时,即使调用了三次send()或sendto()函数,TCP并不会保证将这三次调用视为三个独立的“包”。TCP可能会将多次调用合并成一个或多个段(segment),也可能将单次调用分割成多个段,这取决于TCP的拥塞控制算法、窗口大小等因素。 因此,服务端接收到的TCP段数量可能少于、等于或多于客户端调用send()的次数。但是,服务端最终会接收到完整且按序的数据,即使这些数据被分割成了多个段。(发送数据调用send函数返回成功,并不代表数据已经发送到互联网,这一步只是表示数据从应用层拷贝到了内核中维护的发送缓冲区,至于内核什么时候发送就是由TCP/IP协议栈决定,应用程序是无法控制的,既不能控制它在什么时间发送,也不能控制它分为几个segment发送。)
当通过UDP发送数据时,每次调用sendto()函数都会发送一个独立的数据报(datagram)。因此,如果调用了三次sendto(),理论上服务端应该能够接收到三个独立的UDP数据报,前提是这些数据报在网络中没有丢失。
然而,由于UDP的不可靠性质,数据报可能会丢失、重复或乱序到达,所以服务端实际接收到的数据报数量可能少于发送的数量。
UDP发送3次,服务端可能收到的情况是0次,1次,2次,3次。
这里可能会有朋友问道:UDP发送数据,如果超过了MTU,IP层会分片,那么服务端收到的次数可能大于3次。
这里就是一个误解,IP的分片,和TCP的分段,是完全不同的两个概念:
IP层属于网络层,TCP层属于传输层。当使用UDP协议发送数据时,如果数据长度超过了网络层(IP层)的MTU,那么IP层确实会对UDP数据报进行分片。
MTU是指在特定的网络链路上可以传输的最大的数据单元大小,包括头部信息。典型的以太网MTU是1500字节。
当一个UDP数据报的大小超过了MTU,IP层会将其分割成多个较小的分片,每个分片都有自己的IP头部,其中包含一个分片偏移字段和标志位,以便接收端能够识别和重组这些分片。
然而,从服务端的视角看,它通常不会看到这些分片,而是看到一个完整的UDP数据报。这是因为分片的重组是在网络层完成的,通常在到达UDP层之前就已经由接收端的操作系统内核完成了。这意味着,即便UDP数据报在传输过程中被分成了多个IP分片,到达UDP层时,这些分片已经被重新组合成原始的UDP数据报。
因此,服务端通常只会看到一个完整的UDP数据报,而不是它在网络层被分片的细节。
# 案例
linux的TCP连接数量最大不能超过65535个,那服务器是如何应对百万千万的并发的? (opens new window) 想要支持百万长连接,需要调优哪些参数? (opens new window)
- 文件描述符限制 系统级别限制:操作系统会设置一个全局的文件描述符限制,控制整个系统能同时打开的最大文件数 用户级别限制:每个用户会有一个文件描述符的限制,控制这个用户能够同时打开的最大文件数 进程级别限制:每个进程也会有一个文件描述符的限制,控制单个进程能够同时打开的最大文件数
- 服务器 TCP 连接数量上限 一个服务端的 TCP 网络应用,理论上可以支持的最大连接数量是多少?
TCP 四元组 = 客户端IP+客户端port+服务端IP+服务端port
其中服务端 IP、服务端 Port 已经固定了 (就是监听的 TCP 程序),所以理论的连接数量上限就取决于 (客户端 IP * 客户端 Port) 的组合数量了。
客户端IP * 客户端port = 2^32*2^16
当然如果服务端程序监听 1 ~ 65535 的所有端口号,理论的连接数量上限就变为:
2^32*2^16*2^16
当然实际情况下肯定达不到这样的上限数量,原因有三:
IP 地址中有分类地址 (A, B, C 类)、内网地址、保留地址 (D, E 类),其中后两者无法用于公网通信 某些端口会被保留,仅供专门程序使用,例如 DNS (53), HTTPS (443) 服务器内存大小有上限,一个 TCP 套接字会关联内存缓冲区、文件描述符等资源 综上所述,一个服务端的 TCP 网络应用,可以支持的最大连接数量主要取决于其内存大小 (内核参数都已经调优的情况下)。
如何测试? 在测试设备不充足的情况下,如何测试百万连接数量场景?核心思路:突破 TCP 四元组限制即可。
客户端配置多个 IP, 这样每个 IP 地址就有大约 64K 个端口号可以使用,向服务端发起连接之前,绑定不同的 IP 地址 即可 服务端监听多个端口号,客户端只需要连接不同的服务端号口即可
# Troubleshooting
# 一次排查send-q
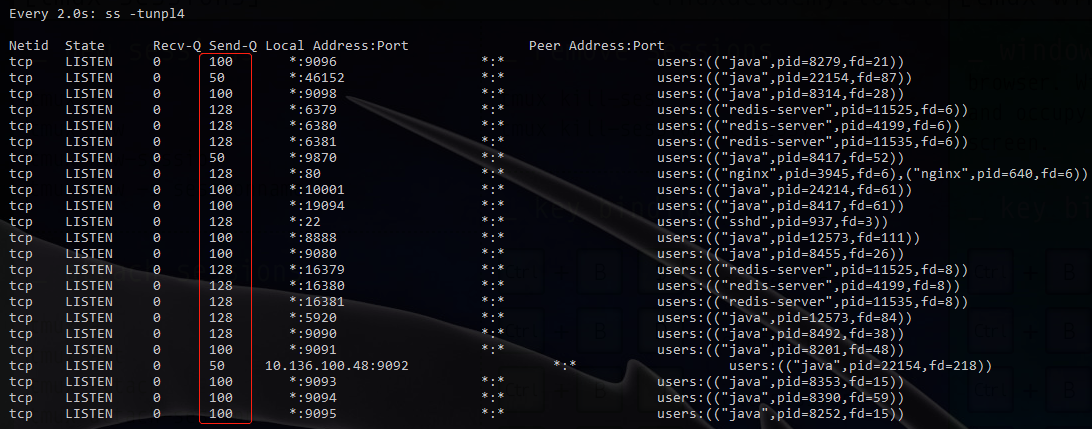
可以看到有 50 100 128 根据网上资料,排查系统参数
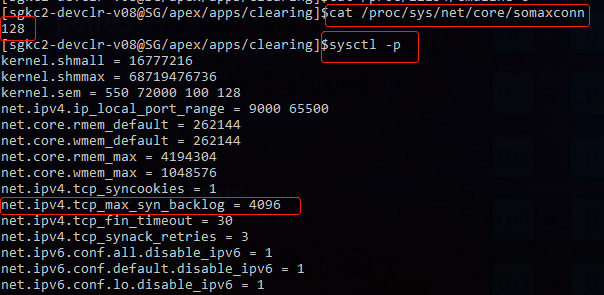
可以看到128是因为这里的设置限制 然后 google了下50,看到
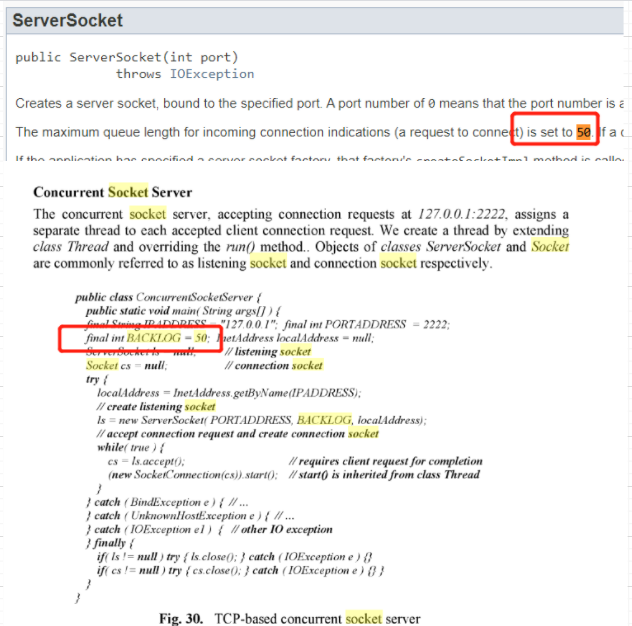
但是实际上我根据cat /proc/
虽然这里没有写默认是多少,大概可以先猜测一下,java应该都是统一的默认50;
所以我在quickfix java提了个proposal https://github.com/quickfix-j/quickfixj/issues/248
同样的
cat /proc/<PID>/cmdline
查到了100的对应程序之一是我们的一个继承了spring-boot-starter-web程序,然后搜了下貌似tomcat默认就是100,所以查了下dependency,
这里确实是spring-boot-starter-web依赖于tomcat;
然后想到既然都是java程序受各种限制,比如socket默认的50以及tomcat默认的100,那么128又是怎么来的,搜了下,果然,比如websocket,这里是用了netty,然后有自定义的config
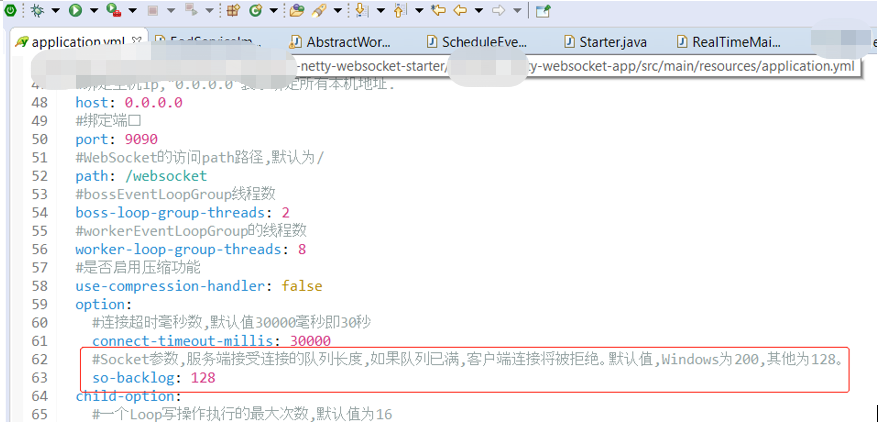
然后再查到其他的一些程序,比如kafka和zookeeper默认50 然后可以看到显示出来的redis-server和nginx都是128
再后来遇到另外一个问题:
the ESTAB tcp connection remains even after closed initiator (opens new window) 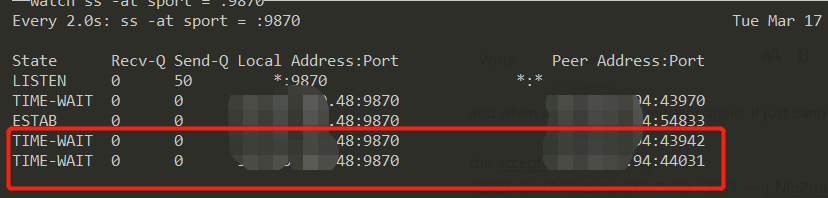 我配错了heartbeat,然后导致了一个神奇的现象,客户端连接服务端,由于他这个协议里面是客户端主动发起heartbeat,所以我配错了之后,即使客户端断掉(连接之后过二十分钟再断),服务端就认为连接一直在,
所以会一直保持这个ESTABLISHED连接,除非重启服务端,然后因为quickfix不允许同一个配置的initiator多次连接,所以再连接都变成了TIME_WAIT;
我配错了heartbeat,然后导致了一个神奇的现象,客户端连接服务端,由于他这个协议里面是客户端主动发起heartbeat,所以我配错了之后,即使客户端断掉(连接之后过二十分钟再断),服务端就认为连接一直在,
所以会一直保持这个ESTABLISHED连接,除非重启服务端,然后因为quickfix不允许同一个配置的initiator多次连接,所以再连接都变成了TIME_WAIT;
参考:记一次惊心的网站TCP队列问题排查经历https://zhuanlan.zhihu.com/p/36731397 https://juejin.im/post/5d8488256fb9a06b065cad98 https://cloud.tencent.com/developer/article/1143712
# 大量TIME_WAIT状态的TCP 连接
https://mp.weixin.qq.com/s/t1ZUXvAUKlIt5UtiZFh1VQ
这个跟前面开篇介绍的TCP三次握手和端口有关,
在高并发的场景中,会出现批量的 TIME_WAIT 的 TCP 连接,短时间后,所有的 TIME_WAIT 全都消失,被回收,端口包括服务,均正常。即,在高并发的场景下,TIME_WAIT 连接存在,属于正常现象。
如果是持续的高并发场景:
- 一部分
TIME_WAIT连接被回收,但新的TIME_WAIT连接产生; - 一些极端情况下,会出现大量的
TIME_WAIT连接。
这个对业务有何影响,如果服务器上是用nginx作为反向代理,意思是,客户端是请求到nginx,然后nginx再作为客户端请求到具体的程序或后台服务,比如java spring mvc程序,websocket等,get post请求mvc程序执行速度比较快,所以不好观察,除非是想办法模拟高并发,我觉着用websocket举例更容易,可以看到
[vm2-devclr-v08@SG/opt/haproxy-2.2.1]$netstat -anp|grep :80
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 3945/nginx: master
tcp 0 0 x.x.x.48:80 10.30.30.94:25748 ESTABLISHED 15394/nginx: worker
tcp 0 0 127.0.0.1:80 127.0.0.1:10693 ESTABLISHED 15394/nginx: worker
tcp 0 0 127.0.0.1:10693 127.0.0.1:80 ESTABLISHED 25613/haproxy
这个10693的端口是做什么的先不用管,是我测试的haproxy;
我们主要看这个10.30.30.94:25748是客户端的连接,访问x.x.x.48:80,即nginx的监听的80端口,然后nginx立马会转发产生跟本地的websocket服务器也就是x.x.x.48:19090的连接,所以会占用一个nginx的端口,比如13576,下面可以看到,这里有两个连接,占用了两个nginx的端口13576和18973,因为是双向连接,所以还有反过来的连接
[vm2-devclr-v08@SG/opt/haproxy-2.2.1]$netstat -anp|grep :19090
tcp 0 0 0.0.0.0:19090 0.0.0.0:* LISTEN 3136/java
tcp 0 0 x.x.x.48:13576 x.x.x.48:19090 ESTABLISHED 15394/nginx: worker
tcp 0 0 x.x.x.48:19090 x.x.x.48:13576 ESTABLISHED 3136/java
tcp 0 0 x.x.x.48:18973 x.x.x.48:19090 ESTABLISHED 15394/nginx: worker
tcp 0 0 x.x.x.48:19090 x.x.x.48:18973 ESTABLISHED 3136/java
所以Nginx 作为反向代理时,大量的短链接,可能导致 Nginx 上的 TCP 连接处于 time_wait 状态:
- 每一个 time_wait 状态,都会占用一个「本地端口」,上限为
65535(16 bit,2 Byte); - 当大量的连接处于
time_wait时,新建立 TCP 连接会出错,address already in use : connect 异常
统计:各种连接的数量
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
TCP 本地端口数量,上限为 65535(6.5w),这是因为 TCP 头部使用 16 bit,存储「端口号」,因此约束上限为 65535。
大量的 TIME_WAIT 状态 TCP 连接存在,其本质原因是什么?
- 大量的短连接存在
- 特别是 HTTP 请求中,如果
connection头部取值被设置为close时,基本都由「服务端」发起主动关闭连接 - 而,
TCP 四次挥手关闭连接机制中,为了保证ACK 重发和丢弃延迟数据,设置time_wait为 2 倍的MSL(报文最大存活时间)
TIME_WAIT 状态:
- TCP 连接中,主动关闭连接的一方出现的状态;(收到 FIN 命令,进入 TIME_WAIT 状态,并返回 ACK 命令)
- 保持 2 个
MSL时间,即,4 分钟;(MSL 为 2 分钟)
解决上述 time_wait 状态大量存在,导致新连接创建失败的问题,一般解决办法:
1、客户端,HTTP 请求的头部,connection 设置为 keep-alive,保持存活一段时间:现在的浏览器,一般都这么进行了 2、服务器端,
- 允许
time_wait状态的 socket 被重用 - 缩减
time_wait时间,设置为1 MSL(即,2 mins)
更多细节,参考:
- https://www.cnblogs.com/yjf512/p/5327886.html
几个核心要点
1、 time_wait 状态的影响:
- TCP 连接中,「主动发起关闭连接」的一端,会进入 time_wait 状态
- time_wait 状态,默认会持续
2 MSL(报文的最大生存时间),一般是 2x2 mins - time_wait 状态下,TCP 连接占用的端口,无法被再次使用
- TCP 端口数量,上限是 6.5w(
65535,16 bit) - 大量 time_wait 状态存在,会导致新建 TCP 连接会出错,address already in use : connect 异常
2、 现实场景:
- 服务器端,一般设置:不允许「主动关闭连接」
- 但 HTTP 请求中,http 头部 connection 参数,可能设置为 close,则,服务端处理完请求会主动关闭 TCP 连接
- 现在浏览器中, HTTP 请求
connection参数,一般都设置为keep-alive - Nginx 反向代理场景中,可能出现大量短链接,服务器端,可能存在
3、 解决办法:服务器端,
- 允许
time_wait状态的 socket 被重用 - 缩减
time_wait时间,设置为1 MSL(即,2 mins)
# 端口占用冲突 Ephemeral ports
某应用程序监听端口9001,但是发现该端口已经被本地一个client端占用
An ephemeral port is a communications endpoint of a transport layer protocol of the Internet protocol suite that is used for only a short period of time for the duration of a communication session. 除了给常用服务保留的Well-known Port numbers之外,给客户端的端口号通常是动态分配的,称为ephemeral port(临时端口),在Linux系统上临时端口号的取值范围是通过这个内核参数定义的:net.ipv4.ip_local_port_range (/proc/sys/net/ipv4/ip_local_port_range),端口号动态分配时并不是从小到大依次选取的,而是按照特定的算法随机分配的。
We need to change ephemeral ports range in linux server to avoid port clash with application ports. Instructions below.
1. Show current ephemeral port range using command below
$ sysctl net.ipv4.ip_local_port_range
2. Add the following configuration to /etc/sysctl.conf to change this to the preferred range (32768 61000)
net.ipv4.ip_local_port_range = 32768 61000
3. Activate the new settings with command below
$ sysctl -p
4. Verify settings using command below
$ sysctl net.ipv4.ip_local_port_range
# final_wait-1 final_wait-2,大量 time_wait
统计连接状态:
netstat -nat | awk '{print $6}' | sort | uniq -c
统计连接数:
netstat -anp|wc -l
netstat -anp|grep ESTABLISHED|wc -l
Active UNIX domain sockets (servers and established)
Active Internet connections (servers and established)
计算每秒最大连接数
$ sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range = 32768 61000
$ sysctl net.ipv4.tcp_fin_timeout
net.ipv4.tcp_fin_timeout = 60
This basically means your system cannot consistently guarantee more than (61000 - 32768) / 60 = 470 sockets per second.
https://stackoverflow.com/questions/410616/increasing-the-maximum-number-of-tcp-ip-connections-in-linux
为什么这里只考虑 final wait 没有考虑time wait:
> A socket in TIME-WAIT will gladly accept a new connection from a device using the same 5 tuple (protocol, source IP, source port, destination IP, destination port) providing that the Initial Sequence Number (ISN) of the new connection is higher than the last sequence number seen on the previous connection. As per RFC 1122:
> When a connection is closed actively, it MUST linger in TIME-WAIT state for a time 2xMSL (Maximum Segment Lifetime). **However, it MAY accept a new SYN from the remote TCP to reopen the connection directly from TIME-WAIT state**, if it:...
> https://superuser.com/questions/1179009/ephemeral-port-collision
- 优化1: 缩短FIN_WAIT_2 即fin_timeout 或者扩大 ephemeral port range
fin_timeout 作用 https://blog.csdn.net/qq_45859054/article/details/106885630 https://sean22492249.medium.com/tcp-%E7%9A%84%E9%97%9C%E9%96%89%E5%8B%95%E4%BD%9C-1469750cd099
优化2:time_wait TCP 状态 https://sean22492249.medium.com/tcp-%E7%9A%84%E9%97%9C%E9%96%89%E5%8B%95%E4%BD%9C-1469750cd099 为什么 TCP 协议有 TIME_WAIT 状态 https://draveness.me/whys-the-design-tcp-time-wait/
- shorten time wait缩短时间
$ sysctl net.ipv4.tcp_tw_timeout - disable socket lingering;
- 直接复用 recycleThis allows fast cycling of sockets in time_wait state and re-using them. But before you do this change make sure that this does not conflict with the protocols that you would use for the application that needs these sockets. Make sure to read post "Coping with the TCP TIME-WAIT" (opens new window) from Vincent Bernat to understand the implications. The net.ipv4.tcp_tw_recycle option is quite problematic for public-facing servers as it won’t handle connections from two different computers behind the same NAT device, which is a problem hard to detect and waiting to bite you. Note that net.ipv4.tcp_tw_recycle has been removed from Linux 4.12.
$ sysctl net.ipv4.tcp_tw_recycle=1 $ sysctl net.ipv4.tcp_tw_reuse=1
- shorten time wait缩短时间
https://serverfault.com/questions/962874/how-to-reach-1m-concurrent-tcp-connections https://serverfault.com/questions/660237/hitting-ephemeral-tcp-port-exhaustion https://serverfault.com/questions/10852/what-limits-the-maximum-number-of-connections-on-a-linux-server https://stackoverflow.com/questions/10085705/load-balancer-scalability-and-max-tcp-ports
# 半连接队列溢出
很简单的场景就是 syn scan,比如使用nmap扫端口 client->syn server->syn+ack client->RST
# 全连接队列溢出
使用dubbo时请求超过问题 (opens new window) 采用的是dubbo服务,这是个稳定成熟的RPC框架。但是我们在某些应用中会发现,只要这个应用一发布(或者重启),就会出现请求超时的问题,而且都是第一笔请求会报错,之后就再也没有问题了
直接讲结论:
在server端连接数过多, linux系统有个连接队列溢出了。溢出的连接被丢弃,但是client端不知道,仍然给此server发送消息。连接没有建立自然发送不成功。client发第一笔消息超时,相当于探活失败,client端于是重新建立连接。连接成功建立后开始正常的通信,所以后面都成功了。
怎么来解决这个问题呢?四个思路。
第一个是队列溢出了,那就说明队列太小。可以把队列值改大。dubbo使用的是一个写死的默认值:50。可以修改dubbo源码把值改大或者干脆动态获取队列值。
第二个是队列数不变,实际连接数减少。减少server端的连接方,比如有些client端其实没有实际业务调用这个server端了,就双方聊聊把无用的依赖去掉。
第三个是可以让服务端在丢弃连接的同时给client端通知一下,linux有个系统参数/proc/sys/net/ipv4/tcp_abort_on_overflow,默认为0。不会给client端发通知,但是设置为1时会给server端发一个reset请求,客户端收到会重连。
第四个是让client端定时心跳探测。探测发现超时了马上重连,超时的那笔只是探测请求,不影响业务。
提到溢出的队列到底是什么队列?
一次握手:
一开始client端和server端都处于closed状态(未建立连接状态)。client端主动向server端发起syn请求建立连接请求,server端收到后将与client端的连接设置为listen状态(半连接状态)。问题来了,server端怎么保存与client端的状态呢?总需要有地方存呀,存的地方就是队列。连接队列又叫backlog队列。到这里,server端与client端的半连接建立了。这里的backlog队列也叫半连接队列。
二次握手:
server端返回ack应答+syn请求给client,意思是:ack我收到了你的请求,syn你收到我的了没?client端收到server端响应,将自己的状态设置为established状态(连接状态)。
三次握手:
client向server端发送一个ack响应,告诉server端收到。然后server端收到后将与client端的连接设置为established状态(全连接状态)。同样,全连接状态在server端也需要一个backlog队列存储。这里的backlog队列也叫全连接队列。
半连接队列:
队列长度由/proc/sys/net/ipv4/tcp_max_syn_backlog指定,默认为2048。
全连接队列:
队列长度由/proc/sys/net/core/somaxconn和使用listen函数时传入的参数,二者取最小值。默认为128。
在Linux内核2.4.25之前,是写死在代码常量 SOMAXCONN ,在Linux内核2.4.25之后,在配置文件/proc/sys/net/core/somaxconn中直接修改,或者在 /etc/sysctl.conf 中配置 net.core.somaxconn = 128 。
到底是全连接队列还是半连接队列溢出导致了超时?
server端与client端进行二次握手的前提是server端认为自己与client建立连接是没有任何问题的。如果server端半连接队列溢出了,自己这边都没有处于半连接状态,自然不会发送ack+syn给client端。client端做的应该是重新尝试建立连接,不是发送数据。请求会发送到已经建立好连接的server端(server端是多机器多活部署的)不会造成请求超时。
而二次握手一旦完成,进行三次握手时,如果全连接队列已满,服务器收到客户端发来的ACK, 不会将该连接的状态从SYN_RCVD变为ESTABLISHED。但是客户端已经认为连接建立好了开始发送数据了,这时候是有可能造成超时的。
全连接队列满了之后server端是怎么处理的呢?
当全连接队列已满时,则根据 tcp_abort_on_overflow 的值来执行相应动作。
tcp_abort_on_overflow = 0 处理:
则服务器建立该连接的定时器,这个定时器是一个服务器的规则是从新发送syn+ack的时间间隔成倍的增加,比如从新了第二次握手,进行了5次,这五次的时间分别是 1s, 2s,4s,8s,16s,这种倍数规则叫“二进制指数退让”(binary exponential backoff)。
给客户端定时从新发回SYN+ACK即重新进行第二次握手,(如果客户端设定的超时时间比较短就很容易出现异常)服务器重新进行第二次握手的次数由/proc/sys/net/ipv4/tcp_synack_retries 这个linux系统参数决定。
tcp_abort_on_overflow = 1 处理: 当 tcp_abort_on_overflow 等于1 时,发送一个reset请求重置连接。客户端收到可以尝试再次从第一次握手开始建立连接或者其他处理。
怎么验证确实是backlog队列溢出呢?
ss 是 Socket Statistics 的缩写。ss 命令可以用来获取 socket 统计信息。ss -l 是显示listen状态的数据
在LISTEN状态,其中 Send-Q 即为全连接队列的最大值,Recv-Q 则表示全连接队列中等待被server段处理的数量。数量为0,说明处理能力很够;Send-Q =Recv-Q ,满了,再来就丢弃掉了。
但是这是一个实时的数据,一段时间有拥塞,过一会儿就好了怎么查呢?
可以使用netstat -s 可以查看被全连接队列丢弃的数据。
# netstat -s | grep "times the listen queue of a socket overflowed"
半连接队列很多文章叫做SYN QUEUE队列。全连接队列很多文章叫做ACCEPT QUEUE队列。这是一些研究linux源码的同学根据源码的命名来叫的。
除了字面理解里提到的四种思路,前因后果里还提到了重新进行第二次握手的次数由/proc/sys/net/ipv4/tcp_synack_retries 这个linux系统参数决定。
分别来分析一下各个方案的可行性和优缺点:
方案1:把队列值调大
这个队列值是指全连接队列,调大之后,client端的二次握手就在这个队列里排队等待server端真正建立连接。假设队列值调到上限65535。第65535号请求在排队的过程,client端是established状态,数据可能会发送过来,服务端还没有established状态,还不能处理。
到什么时候能处理呢?65535个请求全部处理完需要13s的样子。对一般的服务来说妥妥的超时。所以nginx和redis都是使用的511,让响应时间在100ms内完成。
方案2:减少连接数
只要能减少的下来,这是理想的法子。现在server端都过载了,可想而知,接入的client端不再少数,推动他们一个个去梳理和改造,就算大家执行力很强,把改下的下了。可想而知,废弃的也一般不会有多少。不展开了啊,现在已经三千多字了,争取五千字内结束。
还有没有别的方法减少连接数呢?最简单的就是使用分治法。
划分子集
跟同事讨论请教的时候,他给我提供了一个划分子集的思路。让client端只和server端一部分服务器建立连接。有两种分配谁跟谁连接的算法,一个是随机算法。但是server端服务器我最多见过几千台组成一个集群的。对随机(虽然连接数是服务器台数的n倍)来说,样本是很少的,会很不均匀;另外一个是确定性算法,思路也很简单。连接的client端及数量是确定的,那就排个序,按照server端数量分配一下。这样连接数是均匀的,但是就没办法做到请求级别的流量均匀。
粘滞连接
尽可能让客户端总是向同一提供者发起调用,除非该提供者挂了,再连另一台。<dubbo:protocol name="dubbo" sticky="true" />。如果每个client端都只和一个server端建立连接。那server端压力就是原来的(1/机器台数)。不够加机器就行了,横向可扩展。
这种做法最大的问题是高可用和并发请求的问题,对于可用性要求不高、请求量不高的服务(比如后台定时任务定时拉取可重试)其实是可以用的。但是这需要client端的自觉性,而对维护这个client端的人员来讲,他们自身是没有好处的,因为原本也就是只是重启时发生一次超时嘛。所以客户端在可以的情况下愿不愿意这样做就看格局了。
方案3:服务端通知
服务端通知上面前因后果中有提到可以设置
/proc/sys/net/ipv4/tcp_synack_retries
重新进行几次进行第二次握手。但是这个阶段,client端可能会发数据包过来造成超时;另外,可以设置
/proc/sys/net/ipv4/tcp_abort_on_overflow=1
整个握手直接断掉,client端是closed状态,它会找其他established状态的连接进行数据包发送,不会造成超时。事实上,调研了一些大厂,
tcp_abort_on_overflow=1是作为默认配置的。
方案4:客户端探测
客户端探测想自己做的话比较麻烦,比如说把,客户端调了n个服务,每个服务建立了n个连接。资源开销大,还必须要复用这些已经建立的连接,复杂度高。
其实provider 和consumer 有双向心跳(探测)的,那为什么没检测出并进行重连?
这个首先面临的问题:client端认为连接成功了,但server端认为没有成功。那么server端 是不会发送心跳给 client端的。
client端是不是应该发心跳给server端呢?是的,原来使用dubbo2.5.3版本时3分钟client端会发送一个探测,之后把问题连接closed掉。只是dubbo 2.6.9使用了netty4。他们强强联手搞出来一个bug,探测机制楞没生效! 心跳有个条件,就是lastRead 和 lastWrite 不为空。那就需要看哪里设置了这两个参数。通过代码查到client端连接成功和server端连接成功的时候都会设置。这里只考虑client端情况,对比netty3发现netty4里少了
NettyServerHandler的handler链处理。这个handler链处理就是用来初始化那两个值的。
除了改client端源码,有没有别的方法让client端探测生效呢?其实什么都不用TCP就有keepalive(探活)机制。默认是7200秒,也就是2小时。可以修改:
/proc/sys/net/ipv4/tcp_keepalive_time 单位是秒
https://cloud.tencent.com/developer/article/1558493
# 其他解决方案 -多线程间接缓解全连接队列溢出
1.快速响应连接:通过多线程,应用程序可以更快地响应新的连接请求,及时从全连接队列中取出连接进行处理,从而减少了队列中等待处理的连接数量。
2.平衡负载:在多线程环境下,可以根据连接的数量和类型动态地分配线程资源,使得负载更加均衡。这有助于防止某些线程过载而其他线程空闲的情况,从而提高了整体的处理能力。
3.减少处理时间:多线程可以并行处理多个任务,因此可以缩短每个任务的处理时间。在网络编程中,这意味着可以更快地处理每个连接请求,减少了连接在全连接队列中的等待时间。
假设有一个网络服务器应用程序,它最初是以单线程模式运行的,负责接受客户端的连接请求,并处理这些连接上的数据。随着客户端数量的增加,服务器的全连接队列(即保存ESTABLISHED状态的连接队列)开始溢出,导致新的连接请求被拒绝,因为队列已满。
为了解决这个问题,可以将服务器应用程序从单线程模式改为多线程模式。以下是一个简化的例子来说明这一点:
单线程服务器(伪代码)
while (true) {
connection = accept_connection(); // 从全连接队列中取出连接
if (connection != null) {
process_connection(connection); // 处理连接
}
}
在这个单线程模型中,服务器只能一次处理一个连接。如果处理一个连接需要很长时间(例如,因为I/O等待或复杂的数据处理),那么新的连接请求可能会在队列中等待很长时间,甚至导致队列溢出。
多线程服务器(伪代码)
// 创建一个线程池来处理连接
thread_pool = create_thread_pool(num_threads);
while (true) {
connection = accept_connection(); // 从全连接队列中取出连接
if (connection != null) {
// 将连接处理任务提交给线程池
thread_pool.submit(process_connection, connection);
}
}
// 处理连接的函数
function process_connection(connection) {
// 在这里处理连接上的数据
}
在这个多线程模型中,服务器接受连接请求后,会立即将连接处理任务提交给一个线程池。线程池中的线程会并行处理这些任务,从而提高了服务器的处理能力。由于多个线程可以同时处理连接,因此新的连接请求不太可能在全连接队列中等待很长时间,从而减少了队列溢出的风险。
需要注意的是,这个例子是简化的,并且省略了很多细节(如错误处理、线程同步等)。在实际应用中,你可能需要使用更复杂的机制来管理线程池和连接处理任务。
此外,虽然多线程可以提高服务器的处理能力,但它也可能引入新的问题,如线程同步和互斥、死锁、资源竞争等。因此,在设计多线程服务器时,需要仔细考虑这些问题,并采取适当的措施来避免它们。
最后,需要强调的是,将应用程序从单线程改为多线程并不总是解决全连接队列溢出的最佳方法。在某些情况下,可能需要结合其他方法(如增加服务器数量、优化网络配置、调整TCP参数等)来共同解决问题。
# passive connections rejected because of time stamp
netstat -s 包含:xxx passive connections rejected because of time stamp
Linux tcp_tw_recycle/tcp_timestamps设置导致的问题。 因为在linux kernel源码中发现tcp_tw_recycle/tcp_timestamps都开启的条件下,60s内同一源ip主机(nat之后的主机可能是负载均衡器或者防火墙)的socket connect请求中的timestamp必须是递增的。
linux系统收到SYN但不回SYN+ACK问题排查 (opens new window)
# PING通 vs tcp通?
能ping通,TCP就一定能连通吗? (opens new window)
https://datatracker.ietf.org/doc/html/rfc9293
https://www.baeldung.com/cs/tcp-active-vs-passive

浅谈Linux内核UDP收包效率低的问题,如何优化? (opens new window)
TCP/IP协议栈的心跳、丢包重传、连接超时机制实例详解 (opens new window)
TCP流量控制和拥塞控制 (opens new window)
TCP socket buffer (opens new window)