回目录 《python实用基础》
前言
每一个应用程序在未执行的时候,只是一个二进制文件,当被执行的时候,操作系统会创建一个该应用的“活体”,就是进程,只有进程才能执行具体的任务。一个进程包括二进制镜像文件、虚拟内存、�需要访问的内核资源、安全上下文等等,操作系统会为进程分配一个唯一id。 线程是程序运行的最小调度单元,线程包含在进程中,它包括虚拟处理器、�栈、应用程序�状态信息等。 一个进程至少包含一个线程。多线程进程中,理论上每个线程代表单独的任务,多个任务可以同时执行。
在操作系统中两个重要的虚拟化概念是是虚拟内存和虚拟处理器。这两个虚拟化给每个进程一个错觉,就是它们都在独享这个计算机资源。通过虚拟内存,每个进程可以操作的内存地址空间都�被认为是整个内存资源(包括磁盘上的交互内存),然后映射到实际的物理内存上,这样将物理内存访问和应用程序的内存访问隔离开。假如计算机上只有4G内存,你起了10个进程,每个进程都认为自己拥有4G内存的空间可以访问。虚拟处理器,让进程认为它独占处理器资源,运行过程中不用关心是否和其他进程发生争抢,不必去处理实际的资源分配问题。�虚拟处理器模型,可以很�方便的�在多处理器架构上,让多个进程并行执行。 虚拟内存和进程的概念是直接关联的,一个进程中的多个线程共享同一个虚拟内存空间。虚拟处理器和线程是直接关联的,每一个线程是一个独立的调度单元。
Python的多线程�和�其他语言还是有很大区别的,原则上讲是假的多线程。下面的解释引自知乎:
Python代码的执行由Python虚拟机(解释器)来控制。Python在设计之初就考虑要在主循环中,同时只有一个线程在执行,就像单CPU的系统中运行多个进程那样,内存中可以存放多个程序,但任意时刻,只有一个程序在CPU中运行。同样地,虽然Python解释器可以运行多个线程,只有一个线程在解释器中运行。对Python虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同时只有一个线程在运行。在多线程环境中,Python虚拟机按照以下方式执行。
1.设置GIL。 2.切换到一个线程去执行。 3.运行。 4.把线程设置为睡眠状态。 5.解锁GIL。 6.再次重复以上步骤。 对所有面向I/O的(会调用内建的操作系统C代码的)程序来说,GIL会在这个I/O调用之前被释放,以允许其他线程在这个线程等待I/O的时候运行。如果某线程并未使用很多I/O操作,它会在自己的时间片内一直占用处理器和GIL。也就是说,I/O密集型的Python程序比计算密集型的Python程序更能充分利用多线程的好处。
Python的多线程由于全局线程锁的存在并不能实现真正的并行编程,但是Python中的多进程编程模式是可以实现这个目标的。多进程模式下进行上下文切换的损耗要远远大于线程。进程间无法直接共享数据,需要通过Queue、Pipe或则Manager方式做进程间通信
MicroPython MicroPython is a version of the Python programming language for microcontrollers. MicroPython lets you use your Python knowledge to write code to interact with electronics components.
1. Setup
1.1 Env
Common \Python37-32\Lib\site-packages %AppData%\Local\Programs\Python\Python37-32\Lib\site-packages
Linux: Which python
Windows Powershell: where python pip list -v
Windows path: ;%PYTHON_HOME%\; %PYTHON_HOME%\Scripts\ (for PIP etc)
Virtualenv
#sudo apt-get install python-virtualenv
#source py2/bin/activate
virtualenvwrapper (based on python-virtualenv)
https://virtualenvwrapper.readthedocs.io/en/latest/
pip install virtualenvwrapper
vi .bashrc
export WORKON_HOME=~/Envs
source /usr/local/bin/virtualenvwrapper.sh
source .bashrc
mkvirtualenv --python=/usr/bin/python3 bitcoin
PIP package manager
pip install packagename
pip show packagename
path: /usr/lib/python3/dist-packages/
1.2 IDE - VSCode(Visual Studio Code)
ctrl+shift+P
Python:select-interpreter
Ctrl+shift+`
python -m pip install ****
python -m pip install scrapy
选择python版本及找不到安装包问题请查看我在stackoverflow的回答: Why do I get a “ModuleNotFoundError” in VS Code despite the fact that I already installed the module? VS Code does not change python environment
note 1:mind the terminals the terminal you installed the pip package may be different from the terminal you debug/run the python, example one is powershell and another is bash, better config to use the same terminal type or make sure they are using the same python and pip (verify by python -V and pip -V / pip list -v) note 2: python and pip make sure the python version you are using consistent with pip, example sometimes people pip install to %AppData%\Local\Programs\Python\Python310 and run python in %AppData%\Local\Programs\Python\Python312 note 3: VS Code does not change python environment sometimes vscode may not work, I mean someone encountered when you try to choose the python interpreter version, they thought they did but vscode failed to take what they selected, refer to this topic to solve the issue so in the end, it’s very simple, calm down and check where your packages installed to, make sure it’s consistent with python version you are using during debug/run
2. Python Usage
python2 to 3 convert:
2to3-2.7 <Dir> -w -n -o <OutputDir>
2.1 Run scripts
Nohup Run it in session (eg. use Screen) Run in daemon
http://code.activestate.com/recipes/278731/ How to make a Python script run like a service or daemon in Linux https://stackoverflow.com/questions/1603109/how-to-make-a-python-script-run-like-a-service-or-daemon-in-linux
Run Python script as systemd service https://gist.github.com/ewenchou/be496b2b73be801fd85267ef5471458c
What is the reason for performing a double fork when creating a daemon? https://stackoverflow.com/questions/881388/what-is-the-reason-for-performing-a-double-fork-when-creating-a-daemon How do you create a daemon in Python? https://stackoverflow.com/questions/473620/how-do-you-create-a-daemon-in-python
Redirect stdout to a file in Python? https://stackoverflow.com/questions/4675728/redirect-stdout-to-a-file-in-python
python myscript.py >> myfile$(date "+%b_%d_%Y").txt
python myscript.py 2>&1 1>>myfile$(date "+%b_%d_%Y").txt
python myscript.py 2>&1 > /dev/null
nohup python myscript.py
Jobs -l https://www.cnblogs.com/baby123/p/6477429.html
publish Package executable
pip install pyinstaller
pyinstaller –onefile
3. Python Basics
PEP 8 - Python 编码风格指南 https://drafts.damnever.com/2015/EPE8-style-guide-for-python-code.html
python2 to python3
pip install 2to3
2to3 . -w
3.1 syntax
https://www.w3schools.com/python/default.asp
Python does not have built-in support for Arrays, but Python Lists can be used instead. https://www.w3schools.com/python/python_json.asp
coerce https://python-reference.readthedocs.io/en/latest/docs/functions/coerce.html
Lamda https://stackoverflow.com/questions/15712210/python-3-2-lambda-syntax-error
https://www.python.org/dev/peps/pep-3113/
import
__import__
Search path
List comprehensions https://docs.python.org/2/tutorial/datastructures.html#list-comprehensions
Config https://hackernoon.com/4-ways-to-manage-the-configuration-in-python-4623049e841b
https://stackoverflow.com/questions/25470844/specify-format-for-input-arguments-argparse-python
def valid_date(s):
try:
return datetime.strptime(s, "%Y-%m-%d")
except ValueError:
msg = "Not a valid date: '{0}'.".format(s)
raise argparse.ArgumentTypeError(msg)
self in Python class https://www.geeksforgeeks.org/self-in-python-class/
3.2 libaray
Struct pack unpack https://www.reddit.com/r/learnpython/comments/tewfl/can_someone_explain_pack_and_unpack_to_me/
numpy pandas
https://www.w3cschool.cn/hyspo/
https://pandas.pydata.org/docs/getting_started/intro_tutorials/01_table_oriented.html
Python之DataFrame常用方法小结 https://blog.csdn.net/a786150017/article/details/78573055
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html
https://www.youtube.com/watch?v=6FXQJ-aK5MU
df = pd.DataFrame({‘B’: [0, 1, 2, 3, 4]})
import pandas as pd
from sqlalchemy import create_engine
import pymysql
import csv
from sqlalchemy.sql import select
sqlEngine1 = create_engine('mysql+pymysql://USERNAME:PASSWORD@IP1/DB')
dbConnection1 = sqlEngine1.connect()
sqlEngine2 = create_engine('mysql+pymysql://USERNAME:PASSWORD@IP1/DB')
dbConnection2 = sqlEngine2.connect()
df1 = pd.read_sql('select * from TABLE', dbConnection1)
df1_target=df1[["COL1","COL2","COL3"]]
df2 = pd.read_sql('select * from TABLE', con=dbConnection2)
df2_target=df2[["COL1","COL2","COL3"]]
#result = df1_target[~df1_target.apply(tuple, 1).isin(df2_target.apply(tuple, 1))]
#print "db1.TABLE records not in db2.TABLE"
#print result
#result = df2_target[~df2_target.apply(tuple, 1).isin(df1_target.apply(tuple, 1))]
#print "db2.TABLE records not in db1.TABLE"
#print result
result = df1_target.merge(df2_target, indicator=True, how='outer').loc[lambda v:v['_merge'] != 'both'].replace({'_merge':'left_only'},'db1 only').replace({'_merge':'right_only'},'db2 only')
print result
dbConnection1.close()
dbConnection2.close()
Pymongo
Bulk wirte http://api.mongodb.com/python/current/examples/bulk.html Map reduce https://docs.mongodb.com/manual/reference/method/db.collection.mapReduce/#mapreduce-finalize-mtd https://blog.mozilla.org/webdev/2011/08/17/knowing-what-you-want-pymongo/ How can I select a number of records per a specific field using mongodb? https://stackoverflow.com/questions/16067288/how-can-i-select-a-number-of-records-per-a-specific-field-using-mongodb https://www.youtube.com/watch?v=5B7mJtiwbMg https://groups.google.com/forum/#!msg/mongodb-user/UPz1bnaYS8Q/6PQiPMn7J9IJ
Selenium
similar products: Greasemonkey TAmpermonkey
python api
http://selenium-python.readthedocs.io/getting-started.html https://media.readthedocs.org/pdf/selenium-python-test/latest/selenium-python-test.pdf
example: https://www.hongkiat.com/blog/automate-create-login-bot-python-selenium/
Wait for page loading https://stackoverflow.com/questions/26566799/how-to-wait-until-the-page-is-loaded-with-selenium-for-python
python Message: unknown error: Element is not clickable at point
executor.executeScript("arguments[0].click();", firstbutton);
https://stackoverflow.com/questions/37879010/selenium-debugging-element-is-not-clickable-at-point-x-y Single result and multi result https://stackoverflow.com/questions/42216174/selecting-a-button-list-object-has-no-attribute-click-python-selenium?rq=1
Override click https://stackoverflow.com/questions/36882983/override-click-method-of-webelement-in-selenium-using-python Monitor event firing https://searchcode.com/codesearch/view/51336554/
Locating elements http://selenium-python.readthedocs.io/locating-elements.html
Xpath selector Note: special type ‘type’ cannot use it compelete: https://www.guru99.com/xpath-selenium.html https://blog.csdn.net/huiseqiutian/article/details/73739707 Find_element_by_css_selector By.cssSelector
New tab, switch tab https://gist.github.com/lrhache/7686903 https://stackoverflow.com/questions/28715942/how-do-i-switch-to-the-active-tab-in-selenium
Fireevent https://www.youtube.com/watch?v=OZ_XIgxbyiY
Get svg https://codeday.me/bug/20181211/453475.html
inspect on disappering element,有些元素是鼠标mouse hover才显示,所以直接用开发者工具inspect是不行的, 需要在相关的parent上面右键设置一个Break on->subtree modifications
总结: 1.clickable li .click() ActionChain, execute 2.get parent/child by xpath, dot . 3.wait and time.sleep 4.stale / not attached, re-query again 5.Selenium Element not visible exception或者selenium.common.exceptions.ElementClickInterceptedException: Message: element click intercepted(刚好页面上某个按钮的位置被某个漂浮的比如feedback icon挡住) the html element is created from JavaScript, that is why webdriver cannot see it, use driver.execute_script(“javascript code here”)
chrome webdriver
download: https://sites.google.com/chromium.org/driver/
https://chromedriver.storage.googleapis.com/index.html
note: Check chrome version first(chrome may auto upgrading)
chromedriver.exe put in C:\Users\XXX\AppData\Local\Programs\Python\Python37-32\Scripts\
issue:python selenium chrome webdriver giving me data; page https://stackoverflow.com/questions/46143639/python-selenium-chrome-webdriver-giving-me-data-page https://www.reddit.com/r/learnpython/comments/6cfzov/trouble_with_selenium_and_chrome_webdriver/
other issues: https://stackoverflow.com/questions/49162667/unknown-error-call-function-result-missing-value-for-selenium-send-keys-even
firefox webdriver
download: https://github.com/mozilla/geckodriver/releases
compatibility: geckodriver releases, and required versions of Selenium and Firefox: https://firefox-source-docs.mozilla.org/testing/geckodriver/Support.html
issue: our Firefox profile cannot be loaded. It may be missing or inaccessible unsolved: about:profiles
3.3 GUI
http://pyqt.sourceforge.net/Docs/PyQt5/
4.Frameworks and Use Cases
4.1 Crawler - Scrapy
Search engine Web crawlers are a central part of search engines, and details on their algorithms and architecture are kept as business secrets. When crawler designs are published, there is often an important lack of detail that prevents others from reproducing the work. There are also emerging concerns about “search engine spamming”, which prevent major search engines from publishing their ranking algorithms.
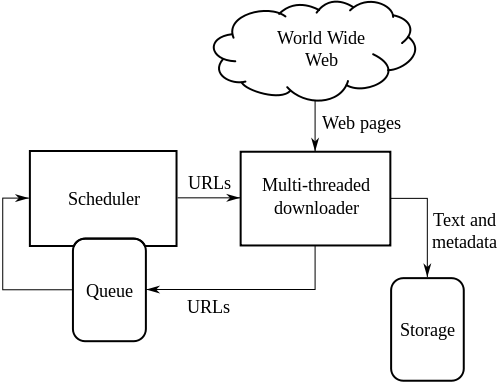
Scrapy Architecture
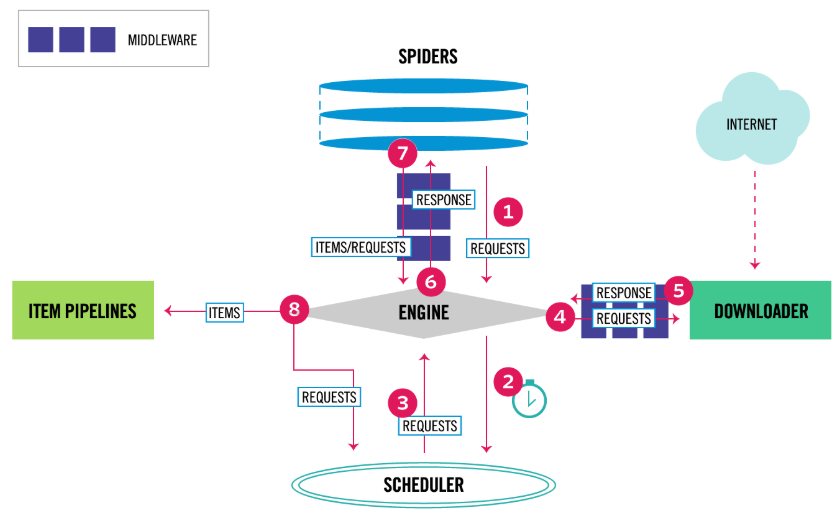
https://docs.scrapy.org/en/latest/intro/tutorial.html
- The Engine gets the initial Requests to crawl from the Spider.
- The Engine schedules the Requests in the Scheduler and asks for the next Requests to crawl.
- The Scheduler returns the next Requests to the Engine.
- The Engine sends the Requests to the Downloader, passing through the Downloader Middlewares (see process_request()).
- Once the page finishes downloading the Downloader generates a Response (with that page) and sends it to the Engine, passing through the Downloader Middlewares (see process_response()).
- The Engine receives the Response from the Downloader and sends it to the Spider for processing, passing through the Spider Middleware (see process_spider_input()).
- The Spider processes the Response and returns scraped items and new Requests (to follow) to the Engine, passing through the Spider Middleware (see process_spider_output()).
- The Engine sends processed items to Item Pipelines, then send processed Requests to the Scheduler and asks for possible next Requests to crawl.
- The process repeats (from step 1) until there are no more requests from the Scheduler.
scrapy startproject clothing_factory
scrapy genspider b2b.11467 b2b.11467.com
python -m pip install pypiwin32
scrapy crawl b2b.11467
scrapy shell
scrapy genspide --list
Integrate with selenium
Selenium without display: pip install pyvirtualdisplay
4.2 Data Analysis
https://www.tutorialspoint.com/python/python_cgi_programming.htm Numpy https://docs.scipy.org/doc/numpy-dev/user/quickstart.html 10 Minutes to pandas https://pandas.pydata.org/pandas-docs/stable/10min.html
basic set up tips recommend: Anaconda + pycharm (change interpreter to python.exe under anaconda folder) I installed Anaconda3.0 version with python version 3.6.3, now I want to use lower version 2.7, so I can do this:
- open up ‘Anaconda prompt’ window
- run: conda create -n py27 python=2.7 anaconda (now if you run: conda info –envs, you can see there is new extra env called py27)
- run: activate py27
- check python version: python –version, done!
- if later you want to switch back to python3, all you need to do is running: deactivate PS: folder= \Anaconda%\envs numpy.random.uniform cumprod histogram
Refer Overview of Exploratory Data Analysis With Python https://hackernoon.com/overview-of-exploratory-data-analysis-with-python-6213e105b00b
4.3 Machine Learning
Collaborative Filtering - RDD-based API https://spark.apache.org/docs/latest/mllib-collaborative-filtering.html
A Hands-On Introduction to Neural Networks https://hackernoon.com/a-hands-on-introduction-to-neural-networks-6a03afb468b1 初探机器学习检测 PHP Webshell https://paper.seebug.org/526/
API
FASTAPI https://fastapi.tiangolo.com/
5. troubleshooting
?#taberror inconsistent use of tabs and spaces in indentation Open the file with Vim. type :retab , and :x . Run the file again https://stackoverflow.com/questions/48735671/use-vim-retab-to-solve-taberror-inconsistent-use-of-tabs-and-spaces-in-indentat
Package install ?# fatal error: pyconfig.h: No such file or directory#include “pyconfig.h”^ compilation terminated.error: command ‘gcc’ failed with exit status 1 Install python development tool https://stackoverflow.com/questions/6230444/how-to-install-python-developer-package
?#issue: install lxml failed on win10 https://www.lfd.uci.edu/~gohlke/pythonlibs/
https://python-forum.io/Thread-Where-lxml-for-Python-3-6-2-for-windows-10?pid=21585 https://ask.hellobi.com/question/25374
?#issue: SSLError: HTTPSConnectionPool(host=’files.pythonhosted.org’, port=443): Max retries exceeded with url:
pip install –trusted-host pypi.org –trusted-host files.pythonhosted.org
?#issue: install mysqlclient on win10
[error] Microsoft Visual C++ 14.0 is required
https://stackoverflow.com/questions/47044149/unable-to-install-mysqlclient-python-package-on-windows/54830728#54830728 download mysqlclient from http://www.lfd.uci.edu/~gohlke/pythonlibs/#mysql-python pip install wheel pip install mysqlclient‑1.4.2‑cp37‑cp37m‑win_amd64.whl
https://www.zhihu.com/question/23474039/answer/269526476