回目录 《分布式框架zookeeper》
# QuickStart:
# Install & usage
https://cwiki.apache.org/confluence/display/ZOOKEEPER/Index https://zookeeper.apache.org/doc/current/index.html
https://docs.confluent.io/platform/current/zookeeper/deployment.html
tar zxvf zookeeper-3.4.8.tar.gz
mkdir -p /opt/dependency/zookeeper-3.4.8/zkdata
mkdir -p /opt/dependency/zookeeper-3.4.8/logs
集群配置:
This example is for a 3 node ensemble:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/dependency/zookeeper-3.4.8/zkdata
dataLogDir=/opt/dependency/zookeeper-3.4.8/logs
# the port at which the clients will connect
clientPort=2181
server.1=1.1.1.1:2888:3888
server.2=1.1.1.2:2888:3888
server.3=1.1.1.3:2888:3888
SERVER_JVMFLAGS=-Xmx1024m'
然后在各个节点上分别写入 1 2 3等到myid:
$ echo "1" > /zookeeper/zkdata/myid
好像还有个 zookeeper_server.pid?
?Failed to start and no log Resolved: yum install glibc.i686
./bin/zkServer.sh start-foreground
https://zookeeper.apache.org/doc/r3.3.3/zookeeperStarted.html
bin/zkCli.sh -server 127.0.0.1:2181
[zk: localhost:2181(CONNECTED) 0] help
[zk: localhost:2181(CONNECTED) 0] ls /
[zk: localhost:2181(CONNECTED) 0] get /test
[zk: localhost:2181(CONNECTED) 0] ls /test mywatcher
[zk: localhost:2181(CONNECTED) 0] delete /test
[zk: localhost:2181(CONNECTED) 0] rmr /test
[zk: localhost:2181(CONNECTED) 0] stat /brokers/topics/T-MEMBER
# 编译源码
https://www.cnblogs.com/MangoCai/p/10846187.html
安装ant,设置%ANT_HOME%\bin
Copy ivy.jar到ant lib
根节点 ant eclipse
Eclipse导入普通java project,修改build path jdk和compliance
通过VerGen.java生成Info.java(/org/apache/zookeeper/version)
 Copy到VerGen.java的上一层package里面
Copy到VerGen.java的上一层package里面
然后两种方式生成jar,
命令行和eclipse导出
根目录下执行
ant jar compile-test
或者
Copy conf/zoo.cfg修改 dataDir=C:\Workspace\Repository\zookeeper-release-3.5.6\dataDir
把jar放到根目录下,
运行
/bin/zkServer.cmd /bin/zkCli.cmd
# 管理脚本
readonly PROGNAME=$(basename $0)
readonly PROGDIR=$(readlink -m $(dirname $0))
# source env
L_INVOCATION_DIR="$(pwd)"
L_CMD_DIR="/opt/scripts"
if [ "${L_INVOCATION_DIR}" != "${L_CMD_DIR}" ]; then
pushd ${L_CMD_DIR} &> /dev/null
fi
#source ../set_env.sh
#--------------- Function Definition ---------------#
showUsage() {
echo "Usage:"
echo "$0 zookeeper start|kill"
echo ""
echo "--start or -b: Start zookeeper"
echo "--kill or -k: Stop zookeeper"
echo "--status or -s: Check zookeeper status"
}
#--------------- Main ---------------#
# Parse arguments
while [ "${1:0:1}" == "-" ]; do
case $1 in
--start)
L_FLAG="B"
;;
-b)
L_FLAG="B"
;;
--status)
L_FLAG="S"
;;
-s)
L_FLAG="S"
;;
--kill)
L_FLAG="K"
;;
-k)
L_FLAG="K"
;;
--kafka)
L_FLAG="KAFKA"
;;
*)
echo "Unknown option: $1"
echo ""
showUsage
echo ""
exit 1
;;
esac
shift
done
L_RETURN_FLAG=0 # 0 for success while 99 for failure
BIN_HOME=/opt/zookeeper-3.4.8/bin
pushd ${BIN_HOME} &>/dev/null
if [ "$L_FLAG" == "B" ]; then
echo "Starting zookeeper service..."
./zkServer.sh start
elif [ "$L_FLAG" == "K" ]; then
echo "Stopping zookeeper service..."
./zkServer.sh stop
elif [ "$L_FLAG" == "KAFKA" ]; then
./zkCli.sh ls /brokers/ids
else
echo "Checking zookeeper status..."
./zkServer.sh status
fi
exit $L_RETURN_FLAG
# 自动启动
[Unit]
Description=The Zookeeper Daemon
Wants=syslog.target
Requires=network.target
After=network.target
[Service]
Environment=PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/jdk/bin
Type=forking
User=root
ExecStart=/bin/zkCli.sh start
[Install]
WantedBy=multi-user.target
# admin
New in 3.5.0: The following options are used to configure the AdminServer (opens new window).
admin.enableServer
(Java system property: zookeeper.admin.enableServer) Set to "false" to disable the AdminServer. By default the AdminServer is enabled.
admin.serverAddress
(Java system property: zookeeper.admin.serverAddress) The address the embedded Jetty server listens on. Defaults to 0.0.0.0.
admin.serverPort
(Java system property: zookeeper.admin.serverPort) The port the embedded Jetty server listens on. Defaults to 8080.
admin.idleTimeout
(Java system property: zookeeper.admin.idleTimeout) Set the maximum idle time in milliseconds that a connection can wait before sending or receiving data. Defaults to 30000 ms.
admin.commandURL
(Java system property: zookeeper.admin.commandURL) The URL for listing and issuing commands relative to the root URL. Defaults to "/commands".
# Things to Avoid
Here are some common problems you can avoid by configuring ZooKeeper correctly:
inconsistent lists of servers
The list of ZooKeeper servers used by the clients must match the list of ZooKeeper servers that each ZooKeeper server has. Things work okay if the client list is a subset of the real list, but things will really act strange if clients have a list of ZooKeeper servers that are in different ZooKeeper clusters. Also, the server lists in each Zookeeper server configuration file should be consistent with one another.
incorrect placement of transaction log
The most performance critical part of ZooKeeper is the transaction log. ZooKeeper syncs transactions to media before it returns a response. A dedicated transaction log device is key to consistent good performance. Putting the log on a busy device will adversely effect performance. If you only have one storage device, put trace files on NFS and increase the snapshotCount; it doesn't eliminate the problem, but it should mitigate it.
incorrect Java heap size
You should take special care to set your Java max heap size correctly. In particular, you should not create a situation in which ZooKeeper swaps to disk. The disk is death to ZooKeeper. Everything is ordered, so if processing one request swaps the disk, all other queued requests will probably do the same. the disk. DON'T SWAP. Be conservative in your estimates: if you have 4G of RAM, do not set the Java max heap size to 6G or even 4G. For example, it is more likely you would use a 3G heap for a 4G machine, as the operating system and the cache also need memory. The best and only recommend practice for estimating the heap size your system needs is to run load tests, and then make sure you are well below the usage limit that would cause the system to swap.
Publicly accessible deployment
A ZooKeeper ensemble is expected to operate in a trusted computing environment. It is thus recommended to deploy ZooKeeper behind a firewall.
# 工具/日志排查
./bin/zkServer.sh start-foreground
https://zookeeper.apache.org/doc/r3.3.2/zookeeperAdmin.html
工具集合:
https://github.com/apache/zookeeper/blob/master/zookeeper-docs/src/main/resources/markdown/zookeeperTools.md
# Application Log
zkServer.sh start的log默认是在:
/bin/zookeeper.out
使用/conf/log4j.properties 设置为 zookeeper.log
https://stackoverflow.com/questions/28691341/zookeeper-log-file-not-created-inside-logs-directory
https://stackoverflow.com/questions/26612908/why-does-zookeeper-not-use-my-log4j-properties-file-log-directory
实例:
发现某个节点
netstat -anp|grep :2181 以及
netstat -anp|grep :2888 (ensemble节点互通端口)
出现大量的time_wait tcp连接,来自于各个节点,
最后通过查看
tail -f /bin/zookeeper.out 发现:
2021-04-06 20:58:23,958 [myid:1] - WARN [QuorumPeer[myid=1]/0.0.0.0:2181:Follower@89] - Exception when following the leader
java.io.IOException: Permission denied
at java.io.UnixFileSystem.createFileExclusively(Native Method)
at java.io.File.createNewFile(File.java:1012)
at org.apache.zookeeper.server.quorum.Learner.syncWithLeader(Learner.java:436)
at org.apache.zookeeper.server.quorum.Follower.followLeader(Follower.java:82)
at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:846)
2021-04-06 20:58:23,959 [myid:1] - INFO [QuorumPeer[myid=1]/0.0.0.0:2181:Follower@166] - shutdown called java.lang.Exception: shutdown Follower
at org.apache.zookeeper.server.quorum.Follower.shutdown(Follower.java:166)
at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:850)
2021-04-06 20:58:23,959 [myid:1] - INFO [QuorumPeer[myid=1]/0.0.0.0:2181:FollowerZooKeeperServer@140] - Shutting down
然后通过permission denied判断是权限问题,因为启动的时候是用的普通user,发现
find zookeeper/ -group root
发现了zkdata下面的文件都是root的,修改权限即可
https://stackoverflow.com/questions/54087210/kafka-create-too-many-time-wait-tcp-connection/66969946#66969946
其他类似案例:https://www.cnblogs.com/duanxz/p/3768454.html
# Data Log
https://stackoverflow.com/questions/17894808/how-do-one-read-the-zookeeper-transaction-log
--- 3.6 之前版本
具体log4j版本可以在zookeeper目录下/lib里面去看
java -cp /zookeeper-3.4.8/zookeeper-3.4.8.jar:lib/log4j-1.2.16.jar:lib/slf4j-log4j12-1.6.1.jar:lib/slf4j-api-1.6.1.jar org.apache.zookeeper.server.LogFormatter /zookeeper-3.4.8/logs/version-2/log.100000001 > /home/test/zookeeper
--- 3.6后版本
For transaction log:
bin/zkTxnLogToolkit.sh --dump /datalog/version-2/log.f3aa6
For snapshots:
./zkSnapShotToolkit.sh -d /data/zkdata/version-2/snapshot.fa01000186d
Admin https://zookeeper.apache.org/doc/current/zookeeperAdmin.html
troubleshooting https://cwiki.apache.org/confluence/display/ZOOKEEPER/Troubleshooting
somoktest latency https://cwiki.apache.org/confluence/display/ZOOKEEPER/ServiceLatencyOverview
Jmx https://zookeeper.apache.org/doc/current/zookeeperJMX.html#
vim bin/zkServer.sh
找到ZOODAMIN="" 添加 -Djava.rmi.server.hostname=$JMXHOSTNAME
到conf下面添加java.env:
JMXHOSTNAME=''
JMXPORT=2182
?Failed to resolve hostname, malformed url
edit /etc/hosts,add 127.0.0.1
jconsole Four letter words https://zookeeper.apache.org/doc/r3.4.13/zookeeperAdmin.html#sc_zkCommands
echo dump | nc localhost 2181
Baseline https://cwiki.apache.org/confluence/display/ZOOKEEPER/ServiceLatencyOverview
# 开发 programming
https://cwiki.apache.org/confluence/display/ZOOKEEPER/ErrorHandling https://zookeeper.apache.org/doc/current/zookeeperProgrammers.html
# 原理解读
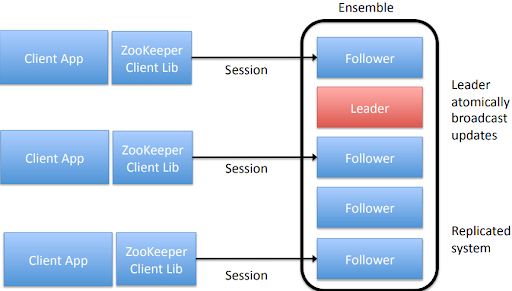
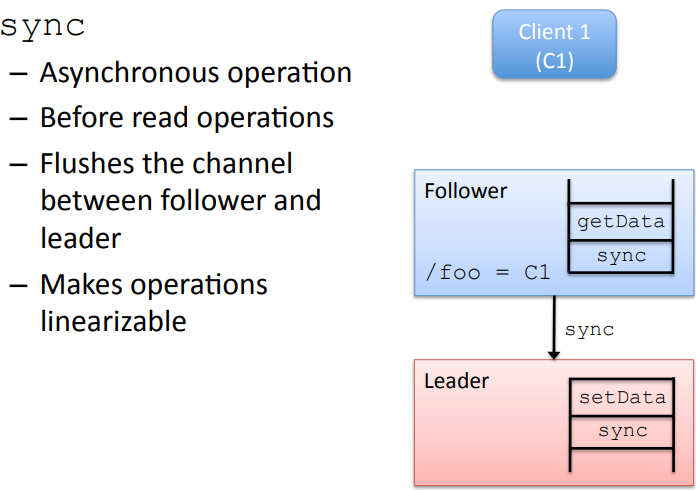
 Semaphores
Queues
Leader election
Group membership
Barriers
Configuration
Semaphores
Queues
Leader election
Group membership
Barriers
Configuration
ZooKeeper has a built-in sanity check of 1M, to prevent it from being used as a large data store, but in general it is used to store much smaller pieces of data. zxid (ZooKeeper Transaction Id). Each update will have a unique zxid 分布式协调,通过观察者模式,rpc通知客户端节点变化,默认的客户端有: 自带的zkCli.sh以及org.apache.zookeeper 客户端lib jar包 还有curator高级开发API zookeeper事件触发是通过推拉的方式,先通知watcher客户端节点变动,然后客户端再去pull下来新增或变化的节点信息; Watcher机制/观察者模式 https://www.jianshu.com/p/4c071e963f18
# 源码解读
Apache ZooKeeper Watcher 机制源码解释 https://www.ibm.com/developerworks/cn/opensource/os-cn-apache-zookeeper-watcher/index.html Zookeeper源码分析之客户端源码解密 https://www.jianshu.com/p/06e859181cc0 Zookeeper源码分析之curator客户端 https://www.jianshu.com/p/bc5e24e4f614
# server端代码
server下面的FinalRequestProcessor是终极请求处理类,所有server收到的请求最终都是流向这里,下面看看如果triggerWatcher的流程:
 然后进去看watcher 的process
然后进去看watcher 的process
可以看到zookeeper server“调用客户端”的watch通知是通过跟客户端的socket连接直接返回response,然后客户端收到请求后会反序列化调用自己实现的watch接口方法 zookeeper/zookeeper-server/src/main/java/org/apache/zookeeper/server/NIOServerCnxn.java 这里的NIOServerCnxn间接继承自Watcherzookeeper/zookeeper-server/src/main/java/org/apache/zookeeper/server/ServerCnxn.java public abstract class ServerCnxn implements Stats, Watcher { 记住这里的ServerCnxn,后面会讲解client端对应的ClientCnxn
# Zookeeper client端代码
Client由三个主要模块组成:Zookeeper, WatcherManager, ClientCnxn Zookeeper是ZK Client端的接口, WatcherManager,管理ZK Client绑定的所有Watcher。 ClientCnxn是管理所有网络IO的模块,所有和ZK Server交互的信息和数据都经过这个模块
zookeeper/zookeeper-server/src/main/java/org/apache/zookeeper/ZooKeeper.java clientWatchManager用于存储管理客户端连过来的watcher
首先是zookeeper server自带的cli工具: zookeeper/zookeeper-server/src/main/java/org/apache/zookeeper/ZooKeeperMain.java
然后是zookeeper client端代码: 客户端收到消息后,会调用 ClientCnxn 的 SendThread.readResponse 方法来进行统一处理,如果响应头 replyHdr 中标识的 Xid 为 02,表示是 ping,如果为-4,表示是验证包,如果是-1,表示这是一个通知类型的响应,然后进行反序列化、处理 chrootPath、还原 WatchedEvent、回调 Watcher 等步骤,其中回调 Watcher 步骤将 WacthedEvent 对象交给 EventThread 线程,在下一个轮询周期中进行 Watcher 回调; 补充:ClientCnxnSocket会读取socket连接,发现connected信息也将交由SendThread的onconnected处理 zookeeper/zookeeper-server/src/main/java/org/apache/zookeeper/ClientCnxn.java
SendThread 接收到服务端的通知事件后,会通过调用 EventThread 类的 queueEvent 方法将事件传给 EventThread 线程,queueEvent 方法根据该通知事件,从 ZKWatchManager 中取出所有相关的 Watcher 客户端在识别出事件类型 EventType 之后,会从相应的 Watcher 存储中删除对应的 Watcher,获取到相关的 Watcher 之后,会将其放入 waitingEvents 队列,该队列从字面上就能理解是一个待处理队列,线程的 run 方法会不断对该该队列进行处理,这就是一种异步处理思维的实现
# Curator api封装代码
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.leader.LeaderSelector;
import org.apache.curator.framework.recipes.leader.LeaderSelectorListenerAdapter;
import org.apache.curator.retry.ExponentialBackoffRetry;
public class LeaderElectionExample {
private static final String ZK_CONNECTION_STRING = "localhost:2181";
private static final String LEADER_PATH = "/leader";
public static void main(String[] args) throws Exception {
CuratorFramework curatorFramework = CuratorFrameworkFactory.newClient(
ZK_CONNECTION_STRING,
new ExponentialBackoffRetry(1000, 3)
);
curatorFramework.start();
LeaderSelector leaderSelector = new LeaderSelector(curatorFramework, LEADER_PATH,
new LeaderSelectorListenerAdapter() {
@Override
public void takeLeadership(CuratorFramework curatorFramework) throws Exception {
System.out.println("Node " + curatorFramework.getClientId() + " has become the leader.");
// Implement logic for when this node becomes the leader
Thread.sleep(3000); // Example: Perform leader activities
System.out.println("Node " + curatorFramework.getClientId() + " is relinquishing leadership.");
}
@Override
public void stateChanged(CuratorFramework curatorFramework, org.apache.curator.framework.state.ConnectionState connectionState) {
if (connectionState == org.apache.curator.framework.state.ConnectionState.SUSPENDED) {
System.out.println("Node " + curatorFramework.getClientId() + " lost connection to ZooKeeper");
} else if (connectionState == org.apache.curator.framework.state.ConnectionState.RECONNECTED) {
System.out.println("Node " + curatorFramework.getClientId() + " reconnected to ZooKeeper");
} else if (connectionState == org.apache.curator.framework.state.ConnectionState.LOST) {
System.out.println("Node " + curatorFramework.getClientId() + " lost connection and session with ZooKeeper");
// Implement logic for handling loss of session, e.g., shutdown gracefully
}
}
});
leaderSelector.autoRequeue(); // Ensure requeueing of participants upon relinquishing leadership
leaderSelector.start();
// Example: Keep the application running indefinitely to observe leader changes
Thread.sleep(Long.MAX_VALUE);
leaderSelector.close();
curatorFramework.close();
}
}
七张图彻底讲清楚ZooKeeper分布式锁的实现原理 https://juejin.im/post/5c01532ef265da61362232ed Zookeeper使用之curator https://leokongwq.github.io/2018/06/17/zookeeper-curator.html Curator分布式锁 https://blog.csdn.net/xuefeng0707/article/details/80588855 Zookeeper Curator 事件监听 - 秒懂 https://www.cnblogs.com/crazymakercircle/p/10228385.html
# curator leader election代码解析
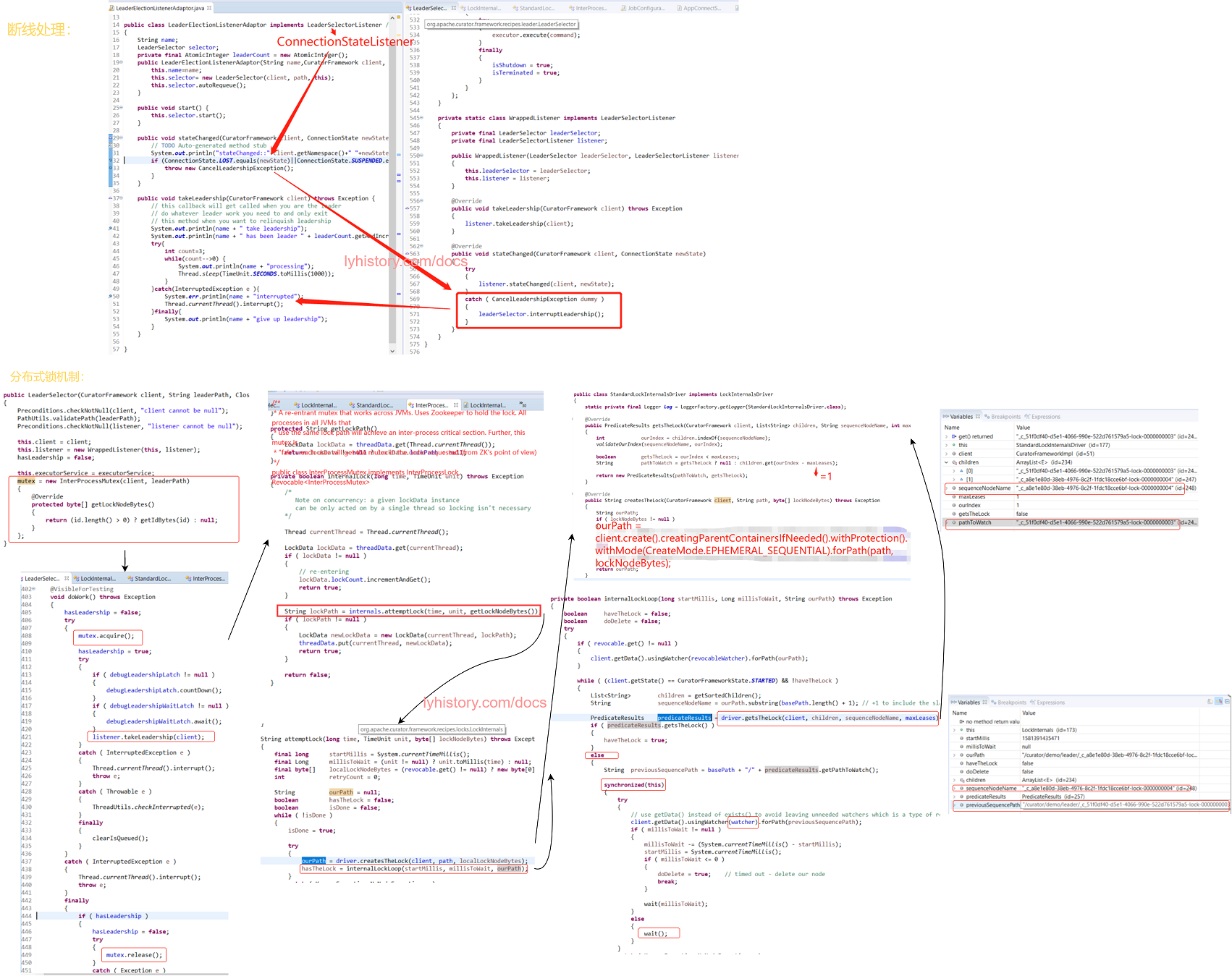 图示上半部分为跟zookeeper断线之后的逻辑,
图示上半部分为跟zookeeper断线之后的逻辑,
断线处理很简单,LeaderSelectorListener继承了ConnectionStateListener, 然后这个listener注册到了CuratorFrameworkImpl维护的listener容器, 当断线时回调这个listener wrapper,wrapper再回调statechange,然后可以在statechange里面抛出异常从而触发 leaderSelector.interruptLeadership,其内部就是获取“执行takeleadership的doWorkLoop所在的线程executorService”这个task,然后调用其cancel(boolean java.util.concurrent.Future.cancel(boolean mayInterruptIfRunning))方法中断操作
额外指出,从架构设计上欣赏的curator的监听器管理,CuratorFrameworkImpl将这些ConnectionStateListener交由ConnectionStateManager来统一管理,当监测到状态变化, ConnectionStateManager调用注册好的listener的StateChange来通知变化,这是典型的一个抽象出来的状态机管理实现;
下半部分是选举的分布式锁机制,主要的逻辑基石就是zookeeper保证了sequence ephemeral节点的生成,然后后一个节点监听前一个节点,只有前一个节点删除后才会通过watcher去唤醒后面一个等待的节点
curator封装的InterProcessMutex注释:
/**
* A re-entrant mutex that works across JVMs. Uses Zookeeper to hold the lock. All processes in all JVMs that
* use the same lock path will achieve an inter-process critical section. Further, this mutex is
* "fair" - each user will get the mutex in the order requested (from ZK's point of view)
*/
public class InterProcessMutex implements InterProcessLock, Revocable
- 首先还是要考虑同一个application,即同一个jvm进程中多线程的竞争问题,所以引入了大量的synchronized方法和synchronized(this)方法块,
- 跨JVMs主要就是利用了StandardLockInternalsDriver的getsTheLock,利用ephemeral sequential先获取当前leader下面注册了多少child,然后当前的node就去pathToWatch前面一个node(children.get(ourIndex - maxLeases),maxLeases=1)
# PathChildrenCache解析: zookeeper推拉消息
如果我们直接使用zookeeper client开发,只能自定义各种watcher,然后向zookeeper也就是zookeeper client端接口注册,然后最终注册到zookeeper服务端, 然后服务端的变化通知watcher,由于watcher是一次性的,所以每次getChildren或getData时都要设置参数项watcher为true,才可以继续监听zknode变化。
而使用Curator封装好的NodeCache PathChildrenCache等类,我们只需要创建实现一个继承了curator相关listener接口的listener,即可实现‘实时’监听zknode变化,不需要再写繁杂的watcher代码;
看看封装好的这个PathChildrenCache,
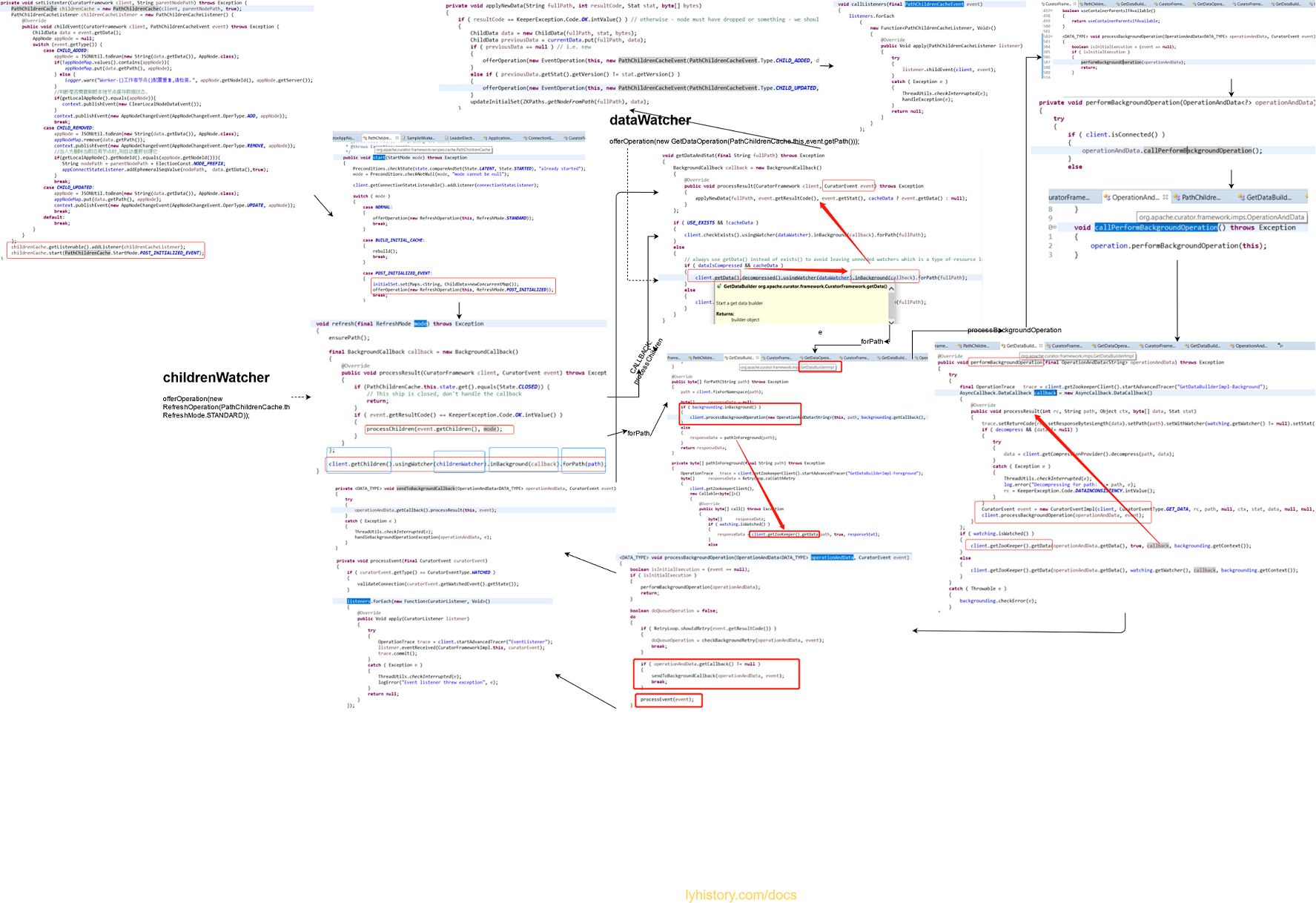
我们自定义了listener,并向PathChildrenCache提供的listenerContainer注册,然后启动start
启动后,实际上PathChildrenCache并没有将我们自定义的listener注册到curatorFramework client(实际类为CuratorFrameworkImpl),而是自己注册了一个自己的ConnectionStateListener, 不过这个主要是管理跟zookeeper服务端的连接情况, 然后OfferOperation会调用refresh(), 先向curatorFramework注册一个childWatcher,然后第一次比如节点创建后回调callback方法processResult调用processChildren,然后调用getDataAndStat, 这里又会注册一个dataWatcher, 当然这两个watcher都是最终是层层转接注册到前面说的zookeeper服务端的,下面我们就先看看到底是怎么层层转到zookeeper client接口的;
上面说了watcher的注册,watcher的作用就是接收zookeeper服务端zknode节点及数据变化,接收的参数WatchedEvent,只是会知道变化的类型: public enum EventType { None (-1), NodeCreated (1), NodeDeleted (2), NodeDataChanged (3), NodeChildrenChanged (4); 然后具体变化还要主动去拉取, 所以粗略的逻辑是,curatorFramework把收到的watcher注册请求都注册给zookeeper,zookeeper服务端通知客户端watcher,然后curator在PathChildrenCache的watcher再去拉取数据;
这两个watcher注册的地方都是创建者模式builder pattern的fluent API流畅连写: client.getChildren().usingWatcher(childrenWatcher).inBackground(callback).forPath(path); client.getData().usingWatcher(dataWatcher).inBackground(callback).forPath(fullPath);
下面就以dataWatcher这个来说明:
注意这里的getData()是调用的curatorFramework的,所以实际是拿到dataBuilder,对应的实现类是getDataBuilderImpl,然后最后是落脚在forPath,实际就是调用了 getDataBuilderImpl的forPath方法,我们就看下这个的forPath方法:
可以看到,有前台和后台执行两种模式,前台执行很直接,调用zookeeper的getdata, 继续看后台执行的模式,而后台跑则调用curatorFramework的processBackgroundOperation: 此时CuratorEvent==null,则isInitialExecution==true,所以只会调用performBackgroundOperation,然后最终是调用接口BackgroundOperation.performBackgroundOperation, 即最终调用回该接口的引用getDataBuilderImpl的performBackgroundOperation,
if ( watching.isWatched() )
{
client.getZooKeeper().getData(operationAndData.getData(), true, callback, backgrounding.getContext());
}
else
{
client.getZooKeeper().getData(operationAndData.getData(), watching.getWatcher(), callback, backgrounding.getContext());
}
真香,可以看到最终肯定还是调用zookeeper client的getdata,然后注意到其定义的callback里面组装了一个CuratorEvent
CuratorEvent event = new CuratorEventImpl(client, CuratorEventType.GET_DATA, rc, path, null, ctx, stat, data, null, null, null);
client.processBackgroundOperation(operationAndData, event);
然后看到其callback里面再次调用curatorFramework的processBackgroundOperation,这一次event!=null了,所以走到下面的
if ( operationAndData.getCallback() != null )
{
sendToBackgroundCallback(operationAndData, event);
break;
}
processEvent(event);
这个callback是啥,回过头查一下就知道这个是一开始在PathChildrenCache里面注册的:
void getDataAndStat(final String fullPath) throws Exception
{
BackgroundCallback callback = new BackgroundCallback()
{
@Override
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception
{
applyNewData(fullPath, event.getResultCode(), event.getStat(), cacheData ? event.getData() : null);
}
};
if ( USE_EXISTS && !cacheData )
{
client.checkExists().usingWatcher(dataWatcher).inBackground(callback).forPath(fullPath);
}
else
{
// always use getData() instead of exists() to avoid leaving unneeded watchers which is a type of resource leak
if ( dataIsCompressed && cacheData )
{
client.getData().decompressed().usingWatcher(dataWatcher).inBackground(callback).forPath(fullPath);
}
else
{
client.getData().usingWatcher(dataWatcher).inBackground(callback).forPath(fullPath);
}
}
}
回到前面,所以整个意思是调用zookeeper client接口获取的data要封装成curatorEvent再调用回PathChildrenCache的callback,callback调用applyNewData:
if ( previousData == null ) // i.e. new
{
offerOperation(new EventOperation(this, new PathChildrenCacheEvent(PathChildrenCacheEvent.Type.CHILD_ADDED, data)));
}
else if ( previousData.getStat().getVersion() != stat.getVersion() )
{
offerOperation(new EventOperation(this, new PathChildrenCacheEvent(PathChildrenCacheEvent.Type.CHILD_UPDATED, data)));
}
可以看到这里封装了PathChidrenCacheEvent,再最终回调一开始开头注册好的监听方法 listener.childEvent(client, event); 然后看到前面CuratorFramework还调用了processEvent,继续查到里面是调用CuratorListener, 我们事先并没有注册任何CuratorListener,而是调用的PathChildrenCacheListener,所以这个processEvent这里没有起到任何作用;
# 深入解读
https://cwiki.apache.org/confluence/display/ZOOKEEPER/ZooKeeperPresentations Sometimes developers mistakenly assume one other guarantee that ZooKeeper does not in fact make. This is: * Simultaneously Consistent Cross-Client Views* : ZooKeeper does not guarantee that at every instance in time, two different clients will have identical views of ZooKeeper data. Due to factors like network delays, one client may perform an update before another client gets notified of the change. Consider the scenario of two clients, A and B. If client A sets the value of a znode /a from 0 to 1, then tells client B to read /a, client B may read the old value of 0, depending on which server it is connected to. If it is important that Client A and Client B read the same value, Client B should should call the sync() method from the ZooKeeper API method before it performs its read. So, ZooKeeper by itself doesn't guarantee that changes occur synchronously across all servers, but ZooKeeper primitives can be used to construct higher level functions that provide useful client synchronization. (For more information, see the ZooKeeper Recipes. [tbd:..]).
CAP理论,zookeeper是CP模型,保证sequential consistency (opens new window), 比eventual consistency强一些,但是不是strong consistency,因为我们前面说了,zookeeper是采用推拉模式, 所以每个客户端看的的view都可能由于网络的原因不一样, Zookeeper is not A, and can't drop P. So it's called CP apparently. In terms of CAP theorem, "C" actually means linearizability.But, Zookeeper has Sequential Consistency - Updates from a client will be applied in the order that they were sent. (opens new window)
然后又由于zookeeper是基于CP模型,所以有人提出: zookeeper 的 CP 模型不适合注册中心 https://segmentfault.com/a/1190000021356988
丢失watcher的原因:
//连续修改会‘丢失’nodeChanged event的原因是,每次获取到nodechanged之后curator的nodecache实际上还要再次重设watch,因为watch是一次性的; //客户端set 111 , 服务端处理set //客户端注册watch,服务端注册watch //客户端set 222, 服务端处理set,服务端刚才的watch刚注册好 //客户端注册watch,服务端通知client端变化 //客户端set 333, 服务端处理set //客户端收到变化通知打印,然后还要去服务端拉取,此时最新值是333 //但是实际上setDAta应该都是成功的,因为zookeeper是顺序处理 client.setData().forPath(nodePath, "111".getBytes()); client.setData().forPath(nodePath, "222".getBytes());
所以要用对zookeeper还是要学习下其他产品,比如: kafka 中 zookeeper 具体是做什么的? (opens new window)
ref: https://www.cnblogs.com/duanxz/p/3783266.html
Zookeeper集群"脑裂"问题 - 运维总结 https://www.cnblogs.com/kevingrace/p/12433503.html