正则表达式 Regex 个人感觉正则表达才是计算机高级语言,超越了人眼的匹配,直追人脑的匹配能力。 我们经常与正则表达打交道,多数情况下我们都是用基本的匹配,比如简单的javascript验证手机\email有效性等,但是遇到复杂的需求,每次都是苦战。 ,去除起来如果是用html parser的匹配有时候又费力又慢,正则用起来很犀利,可是写出来很难,所以建议先用好搜索引擎, 用适当的关键词获取类似的例子,改造一番。然后茶余饭后再阅读本文做进一步的学习理解。
http://www.regexr.com/: This is a really good site where we can get examples and references and test our own expressions to check whether a string matches or not. http://www.regular-expressions.info: This site contains tutorials and examples to learn how to use regular expressions. It also has a useful reference on the particular implementations of the most popular languages and tools. http://www.princeton.edu/~mlovett/reference/Regular-Expressions.pdf (Regular Expressions The Complete Tutorial) by Jan Goyvaerts: As its title states, this is a very complete tutorial on RegEx, including examples in many languages.
# Common used
/([^:]+):.*/ 192.1.1.1:9100 192.1.1.1
常用正则表达式 useful regular expression 10+ Useful JavaScript Regular Expression Functions to improve your web applications efficiency http://ntt.cc/2008/05/10/over-10-useful-javascript-regular-expression-functions-to-improve-your-web-applications-efficiency.html 里面有信用卡的验证 http://www.virtuosimedia.com/dev/php/37-tested-php-perl-and-javascript-regular-expressions
# 1.Tutorial
Basic https://regexone.com/lesson/introduction_abcs
it's always good to be precise, and that applies to coding, talking, and even regular expressions.
For example, you wouldn't write a grocery list for someone to Buy more .* because you would have no idea what you could get back.
<
正则表达式30分钟入门教程 http://www.jb51.net/tools/zhengze.html Essential Guide To Regular Expressions: Tools and Tutorials http://www.smashingmagazine.com/2009/06/01/essential-guide-to-regular-expressions-tools-tutorials-and-resources/
# Basic Regular Expressions
Normally a backslash turns off the special meaning for a character. A period is matched by a "." and an asterisk is matched by a "*". BUt if a backslash is placed before a "<," ">," "{," "}," "(," ")," or before a digit, the backslash turns on a special meaning. This was done because these special functions were added late in the life of regular expressions. Changing the meaning of "{" would have broken old expressions. This is a horrible crime punishable by a year of hard labor writing COBOL programs. Instead, adding a backslash added functionality without breaking old programs. Rather than complain about the unsymmetry, view it as evolution.
# Extended Regular Expressions
Two programs use the extended regular expressions: egrep and awk. With these extensions, those special characters preceded by a backslash no longer have the special meaning: "{" , "}", "<", ">", "(", ")" as well as the "\digit". You can't use the { and } in the extended regular expressions, but if you could, you might consider the "?" to be the same as "{0,1}" and the "+" to be the same as "{1,}".
Well, perhaps the "{...}" and "<...>" could be added to the extended expressions. These are the newest addition to the regular expression family. They could be added, but this might confuse people if those characters are added and the "(...)" are not. And there is no way to add that functionality to the extended expressions without changing the current usage. Do you see why? It's quite simple. If "(" has a special meaning, then "(" must be the ordinary character. This is the opposite of the Basic regular expressions, where "(" is ordinary, and "(" is special. The usage of the parentheses is incompatable, and any change could break old programs.
If the extended expression used "( ..|...)" as regular characters, and "(...|...)" for specifying alternate patterns, then it is possible to have one set of regular expressions that has full functionality. This is exactly what GNU emacs does, by the way.
# 1.1 False positive
we've been writing regular expressions that partially match pieces across all the text. Sometimes this isn't desirable, imagine for example we wanted to match the word "success" in a log file. We certainly don't want that pattern to match a line that says "Error: unsuccessful operation"! That is why it is often best practice to write as specific regular expressions as possible to ensure that we don't get false positives when matching against real world text.
Advance Regex tutorial — A quick cheatsheet by examples https://medium.com/factory-mind/regex-tutorial-a-simple-cheatsheet-by-examples-649dc1c3f285
test https://www.regextester.com/
**Metacharacter **
//metacharacters by using their upper case letters means opposite sets of each of these metacharacters
\d
\w alphanumeric letters and digits [A-Za-z0-9_]
\s the space (␣), the tab (\t), the new line (\n) and the carriage return (\r)
\b which matches the boundary between a word and a non-word character. It's most useful in capturing entire words (pattern \w+\b).
^ (hat)
Start of the line
[^abc] will match any single character except for the letters a, b, or c.
$ (dollar sign)
End of the line
.
? + *
|
[] options
{} range
() match groups
Quantifier ? + * {}
Match groups and nested groups
Imagine for example that you had a command line tool to list all the image files you have in the cloud. You could then use a pattern such as ^(IMG\d+\.png)$ to capture and extract the full filename, but if you only wanted to capture the filename without the extension, you could use the pattern ^(IMG\d+)\.png$ which only captures the part before the period.
Character class
# 1.2 Backtracking / trackback
My Findings
https://github.com/dotnet/docs/issues/8216


https://stackoverflow.com/questions/33706215/why-do-w-and-s-handle-backtracking-differently/33706273 https://docs.microsoft.com/en-us/dotnet/standard/base-types/backtracking-in-regular-expressions
Image there are two cursor pointers for regex expression and test string respectively, Namingly: cursor1 for regex expression, cursor2 for test string; Example regex: \S+: The basic rules are: At a new pos(except start points), if cursor1 not at the beginning of regex meaning the position is at :, it will always traceback first to the first pattern \S+ If these adjacent partial patterns have overlap abilities, then when the later pattern find a mismatch it will ask its previous pattern to spit out characters one by one to do backtrack matching; Similarly, if the outside pattern is repetition of the inside pattern, example (x+x+)+y, then the inside iteration, the second x+ need to give up some x also to match (x+x+)(x+x+)..., example
Runaway Regular Expressions: Catastrophic Backtracking https://www.regular-expressions.info/catastrophic.html
attack using backtrack Regular Expression Denial of Service (ReDoS) and Catastrophic Backtracking https://snyk.io/blog/redos-and-catastrophic-backtracking
Back reference many systems allow you to reference your captured groups by using \0 (usually the full matched text), \1 (group 1), \2 (group 2), etc. This is useful for example when you are in a text editor and doing a search and replace using regular expressions to swap two numbers, you can search for "(\d+)-(\d+)" and replace it with "\2-\1" to put the second captured number first, and the first captured number second for example. 回溯引用、前后查找、嵌入条件 https://blog.csdn.net/wzzfeitian/article/details/8867888
# 2.Application
# 2.1 Linux
# Vim Regex
http://vimregex.com/
用 \< 和 \> 分别表示单词的开头和结尾,例如查找单词 i 而不是字母 i ,在正常模式下,按下 / 启动搜索模式,输入 \<i\> ,敲击回车即可
使用 \( 和 \) 包围住表达式使其成为一个原子,并根据原子所处位置顺序使用\1,\2
\(\[506]\)
# Grep Regex
https://www.digitalocean.com/community/tutorials/using-grep-regular-expressions-to-search-for-text-patterns-in-linux
grep -E "searchtext" log.txt
-i ignore case ; -n show linenumber; -c count;
#Anchoring
grep -E "^startby" log.txt
grep -E "endby$" log.txt
grep -E "\<w" log.txt//find by words not by line, find words start with 'w'
#boundary
grep -E '\bwholeword\b' log.txt
grep -E '\Babc\B' log.txt
#Character Classes
grep -E "^[ab]" log.txt //start with a or b
grep -E "T[^o]M" log.txt //exclude ToM
#Interval Expressions
grep -E "T[o]{1,2}M" log.txt //map to ToM or TooM
#Escaping character
grep -E "\.$" log.txt //以.号结尾的
https://www.howtogeek.com/661101/how-to-use-regular-expressions-regexes-on-linux/

https://www.gnu.org/software/findutils/manual/html_node/find_html/Regular-Expressions.html#Regular-Expressions
# 2.2 notepad++
1.multiple line to single line
Wrong!: [\R\s]
Correct: (\h*\R)+ \x20
https://notepad-plus-plus.org/community/topic/14791/how-to-make-all-data-in-one-line/2
2.complicated case
(?<="author_name": ")((?:(?!" ").)*?)[:"]
\nhttps://shopee.tw/\1\n
Step1:
inspect -> network -> xhr -> right click (copy link address)
change tw to com
https://shopee.com/api/v1/comment_list/?item_id=25679461&shop_id=4788349&offset=0&limit=10&flag=1&type=5&filter=0
Step2:
ctrl+f author_name
Step3:
https://shopee.tw/bb601211
https://shopee.com/shop/44094574/rating/api/?&rating_type=0&offset=0&limit=20
https://superuser.com/questions/477628/export-all-regular-expression-matches-in-textpad-or-notepad-as-a-list https://stackoverflow.com/questions/43218000/use-regex-to-search-for-a-specific-word-between-an-exact-string-and-the-first-oc https://stackoverflow.com/questions/16878829/notepad-regex-how-do-i-replace-what-is-found-with-the-same-value-but-with-a-sp
A Few Tricks in Notepad++ a PHP-developer Should Know https://tournasdimitrios1.wordpress.com/2012/09/01/a-few-tricks-in-notepad-a-php-developer-should-know-2/ Notepad++ tips and tricks https://www.youtube.com/watch?v=PzjPu5F9K9Y
1. find {} pairs
find->Mark(bookmark line, regular expression) \{.*?\}
Search -> bookmark -> copy /delete unmarked lines
2. find everything after }, for each line
\},.*
questions: how to remove everything unmarked text Answer:
Workaround
https://superuser.com/questions/477628/export-all-regular-expression-matches-in-textpad-or-notepad-as-a-list
find:(modificationTime=\d+)
Replace with: \n\1\n

# 2.3 Codes
JavaScript RegExp Reference http://www.w3schools.com/jsref/jsref_obj_regexp.asp js常用正则表达式表单验证代码 http://wenku.baidu.com/link?url=H6XlUOl26kNCD6HuUxVBbXX5hXf-4_9BrWAYXAh4WBslNtaZHBqui9TdvTaA3gFg4G-CVCSPeB4vqo5--WhnfytCY7Ab8wBgDZnEx6XgT8i
C# http://www.rexegg.com/regex-csharp.html Regular Expression Language - Quick Reference http://msdn.microsoft.com/en-us/library/az24scfc(v=vs.110).aspx Best Practices for Regular Expressions in the .NET Frameworkhttp://msdn.microsoft.com/en-us/library/gg578045(v=vs.110).aspx
java
Pattern.compile("<\?xml[^>]>.?</(Saa:)?DataPDU>", Pattern.DOTALL)
The regex string
<\\?xml[^>]*>.*?</(Saa:)?DataPDU>
Because it’s inside a Java string, \? really means ? in the regex itself: In Java, strings and regex both have their own escaping rules:
In a Java string literal, \ is the escape character.
So to represent a single backslash in the actual string, you must write \\.
In a regex, ? is a special character (it means zero or one).
To literally match the character ?, you must escape it as \?.
So the real regex is:
<\?xml[^>]*>.*?</(Saa:)?DataPDU>
(\\+\\d{4}|\\-\\d{4})
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.TimeZone;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class MyClass {
public static void main(String args[]) {
SimpleDateFormat isoFormat = new SimpleDateFormat("yyyyMMddHHmmssZZZZ");
Pattern p = Pattern.compile("(\\+\\d{4}|\\-\\d{4})");
Matcher m = p.matcher("20180900-0500");
if (m.find()) {
System.out.println(m.group(1));
}else{
throw new IllegalArgumentException("not Generlized Time");
}
}
}
http://www.mkyong.com/regular-expressions/how-to-extract-html-links-with-regular-expression/ http://www.mkyong.com/regular-expressions/10-java-regular-expression-examples-you-should-know/
look ahead regex
import java.util.*;
public class SplitXmlExample {
public static void main(String[] args) {
String input = "<?xml version=\"1.0\" encoding=\"xxx\"?><A></A>\n"
+ "<?xml version=\"1.1\" encoding=\"yyy\"?><B></B>";
// Split by "<?xml ", but keep the delimiter by adding it back later
String[] parts = input.split("(?=<\\?xml )");
for (String xml : parts) {
xml = xml.trim();
if (!xml.isEmpty()) {
System.out.println("One XML block:");
System.out.println(xml);
System.out.println("----");
}
}
}
}
python
#python 3.5.2
import re
msg = ‘[test] : ddd’
m = re.search(r’(\[test\])’, msg)
pos = msg.replace(m.group(0), ‘’).replace(‘:’, ‘’)
pos = re.sub(‘[\s+]’, ‘’, pos)
result = re.sub(‘,.*’, ‘’, pos)
Regular Expression HOWTO https://docs.python.org/2/howto/regex.html A collection of useful regular expressions http://nbviewer.ipython.org/github/rasbt/python_reference/blob/master/tutorials/useful_regex.ipynb
ref:
图文并茂讲解:
- Matching a Username 匹配用户名

Pattern:
/^[a-z0-9_-]{3,16}$/
Description:
We begin by telling the parser to find the beginning of the string (^), followed by any lowercase letter (a-z), number (0-9), an underscore, or a hyphen. Next, {3,16} makes sure that are at least 3 of those characters, but no more than 16. Finally, we want the end of the string ($).
扩展思考:想下中文用户名怎么写?
- Matching a Password 匹配密码

Pattern:/^[a-z0-9_-]{6,18}$/
Description:
Matching a password is very similar to matching a username. The only difference is that instead of 3 to 16 letters, numbers, underscores, or hyphens, we want 6 to 18 of them ({6,18}).
扩展思考:如何检测密码强度(是否有大写结合+特殊字符+数字)
3.Matching a Hex Value 匹配十六进制

Pattern:/^#?([a-f0-9]{6}|[a-f0-9]{3})$/
Description:
We begin by telling the parser to find the beginning of the string (^). Next, a number sign is optional because it is followed a question mark. The question mark tells the parser that the preceding character — in this case a number sign — is optional, but to be "greedy" and capture it if it's there. Next, inside the first group (first group of parentheses), we can have two different situations. The first is any lowercase letter between a and f or a number six times. The vertical bar tells us that we can also have three lowercase letters between a and f or numbers instead. Finally, we want the end of the string ($).
The reason that I put the six character before is that parser will capture a hex value like #ffffff. If I had reversed it so that the three characters came first, the parser would only pick up #fff and not the other three f's.
4.Matching a Slug 匹配短标签

Pattern:/^[a-z0-9-]+$/
Description:
You will be using this regex if you ever have to work with mod_rewrite and pretty URL's. We begin by telling the parser to find the beginning of the string (^), followed by one or more (the plus sign) letters, numbers, or hyphens. Finally, we want the end of the string ($).
5.Matching an Email 匹配邮箱

Pattern:/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/
Description:
We begin by telling the parser to find the beginning of the string (^). Inside the first group, we match one or more lowercase letters, numbers, underscores, dots, or hyphens. I have escaped the dot because a non-escaped dot means any character. Directly after that, there must be an at sign. Next is the domain name which must be: one or more lowercase letters, numbers, underscores, dots, or hyphens. Then another (escaped) dot, with the extension being two to six letters or dots. I have 2 to 6 because of the country specific TLD's (.ny.us or .co.uk). Finally, we want the end of the string ($).
- Matching a URL 匹配URL
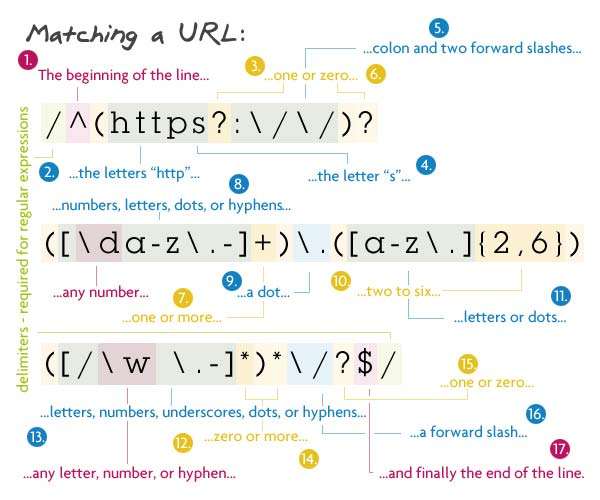
Pattern:/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
Description:
This regex is almost like taking the ending part of the above regex, slapping it between "http://" and some file structure at the end. It sounds a lot simpler than it really is. To start off, we search for the beginning of the line with the caret.
The first capturing group is all option. It allows the URL to begin with "http://", "https://", or neither of them. I have a question mark after the s to allow URL's that have http or https. In order to make this entire group optional, I just added a question mark to the end of it.
Next is the domain name: one or more numbers, letters, dots, or hypens followed by another dot then two to six letters or dots. The following section is the optional files and directories. Inside the group, we want to match any number of forward slashes, letters, numbers, underscores, spaces, dots, or hyphens. Then we say that this group can be matched as many times as we want. Pretty much this allows multiple directories to be matched along with a file at the end. I have used the star instead of the question mark because the star says zero or more, not zero or one. If a question mark was to be used there, only one file/directory would be able to be matched.
Then a trailing slash is matched, but it can be optional. Finally we end with the end of the line.
- Matching an IP Address 匹配IP地址
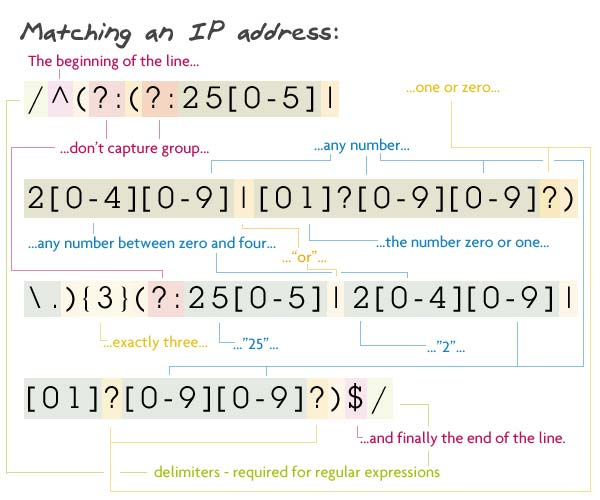
Pattern:/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
Description:
Now, I'm not going to lie, I didn't write this regex; I got it from here. Now, that doesn't mean that I can't rip it apart character for character.
The first capture group really isn't a captured group because(?:(?:was placed inside which tells the parser to not capture this group (more on this in the last regex). We also want this non-captured group to be repeated three times — the {3} at the end of the group. This group contains another group, a subgroup, and a literal dot. The parser looks for a match in the subgroup then a dot to move on.
The subgroup is also another non-capture group. It's just a bunch of character sets (things inside brackets): the string "25" followed by a number between 0 and 5; or the string "2" and a number between 0 and 4 and any number; or an optional zero or one followed by two numbers, with the second being optional.
After we match three of those, it's onto the next non-capturing group. This one wants: the string "25" followed by a number between 0 and 5; or the string "2" with a number between 0 and 4 and another number at the end; or an optional zero or one followed by two numbers, with the second being optional.
We end this confusing regex with the end of the string.
8.Matching an HTML Tag 匹配HTML标签

Pattern:/^<([a-z]+)([^<]+)*(?:>(.*)<\/\1>|\s+\/>)$/
Description:
One of the more useful regexes on the list. It matches any HTML tag with the content inside. As usually, we begin with the start of the line.
First comes the tag's name. It must be one or more letters long. This is the first capture group, it comes in handy when we have to grab the closing tag. The next thing are the tag's attributes. This is any character but a greater than sign (>). Since this is optional, but I want to match more than one character, the star is used. The plus sign makes up the attribute and value, and the star says as many attributes as you want.
Next comes the third non-capture group. Inside, it will contain either a greater than sign, some content, and a closing tag; or some spaces, a forward slash, and a greater than sign. The first option looks for a greater than sign followed by any number of characters, and the closing tag. \1 is used which represents the content that was captured in the first capturing group. In this case it was the tag's name. Now, if that couldn't be matched we want to look for a self closing tag (like an img, br, or hr tag). This needs to have one or more spaces followed by "/>".
The regex is ended with the end of the line.
扩展思考:如何匹配带有attribute的html标签,以及如何匹配多层嵌套的html标签?
免费书籍: Regular Expressions Google Analytics.pdf Regular Expressions Cookbook.pdf regular expression pocket reference second edition.pdf Regular Expressions the complete tutorial.pdf
免费工具: 在线工具: 专业工具 https://regex101.com/ 站长简单工具 http://tool.chinaz.com/regex/ http://tool.oschina.net/regex 免费软件:正则表达式工具绿色版 收费软件: http://www.regular-expressions.info/tutorial.html