1.关键概念
keyword: heartbeat,rebalance
Offsets
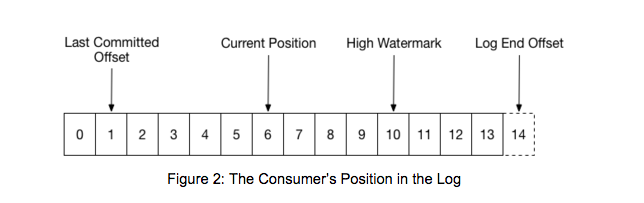
图中last committed log是指consumer消费完之后,自动提交的offset(”then each later rebalance will reset the position to the last committed offset”)
high waterMark和log end offset是上游producer发布的消息offset,其中high watermark是代表全部replicate结束+1,所以consumer最多能读取到high watermark位置-1,
- HWM high watermark the offset of the last successfully replicated message plus one)
-
LEO Log End Offset 当前日志文件中下一条待写入消息的offset。分区ISR集合中的每个副本都会维护自身的LEO,而ISR集合中最小的LEO即为分区的HWM。 这个offset未必在硬盘中,可能目前只在内存中还没有被flush到硬盘。
-
LWM Low Watermark的 代表AR集合(分区中的所有副本统称为 Assigned Replicas)中最小的logStartOffset值。 一般情况下,日志文件的起始偏移量 logStartOffset 等于第一个日志分段的 baseOffset,但这并不是绝对的,旧日志的清理和消息删除都有可能促使LW的增长。
-
LSO Last Stable Offset, 它与kafka 事务Transactional produer有关。对于未完成的事务而言,LSO的值等于事务中的第一条消息所在的位置(firstUnstableOffset);对于已经完成的事务而言,它的值等同于HWM相同。
Kafka的一个消费端的参数——isolation.level,这个参数用来配置消费者的事务隔离级别。字符串类型,有效值为“read_uncommitted”和 “read_committed”,表示消费者所消费到的位置,如果设置为“read_committed”,那么消费者就会忽略事务未提交的消息,即只能消费到 LSO(LastStableOffset)的位置,默认情况下为 “read_uncommitted”,即可以消费到 HWM(High Watermark)处的位置。注意:follower副本的事务隔离级别也为“read_uncommitted”,并且不可修改。
这个LSO还会影响Kafka消费滞后量(也就是Kafka Lag,很多时候也会被称之为消息堆积量)的计算:
a) 如果没有事务 Lag=HWM – ConsumerOffset:
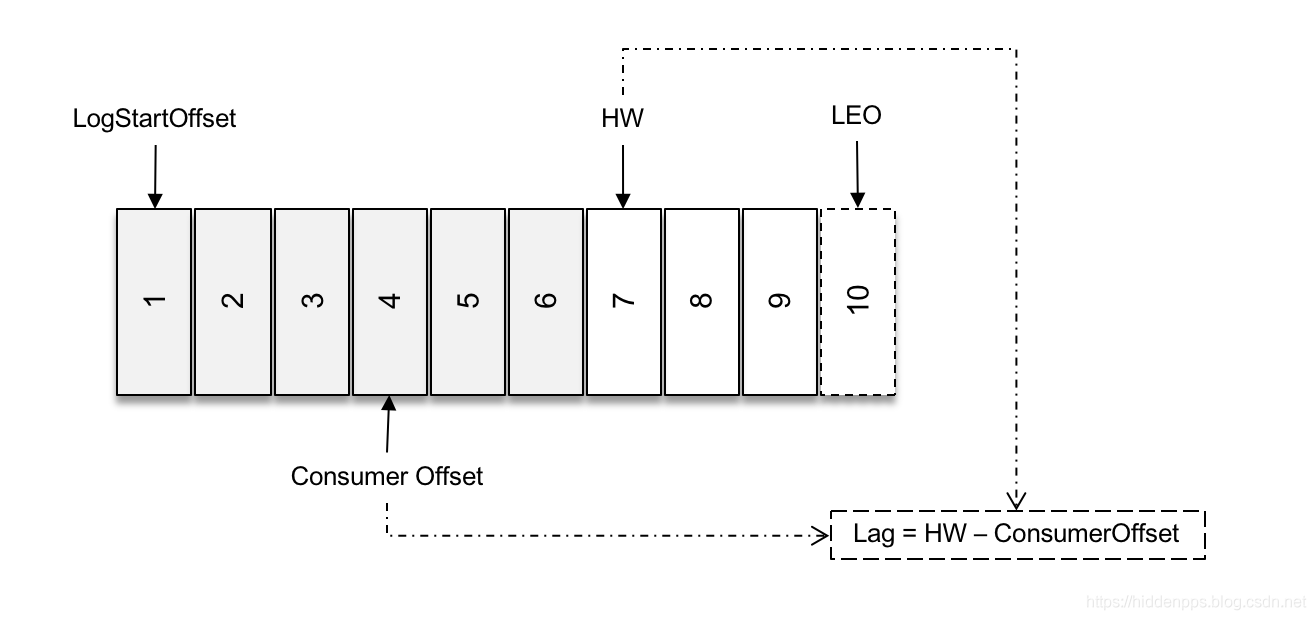
b) 如果为消息引入了事务:
- 如果消费者客户端的 isolation.level 参数配置为“read_uncommitted”(默认),那么 Lag的计算方式不受影响 Lag=HWM – ConsumerOffset
- 如果这个参数配置为“read_committed”,那么 Lag = LSO – ConsumerOffset :
i) 对未完成的事务而言,LSO 的值等于事务中第一条消息的位置 firstUnstableOffset
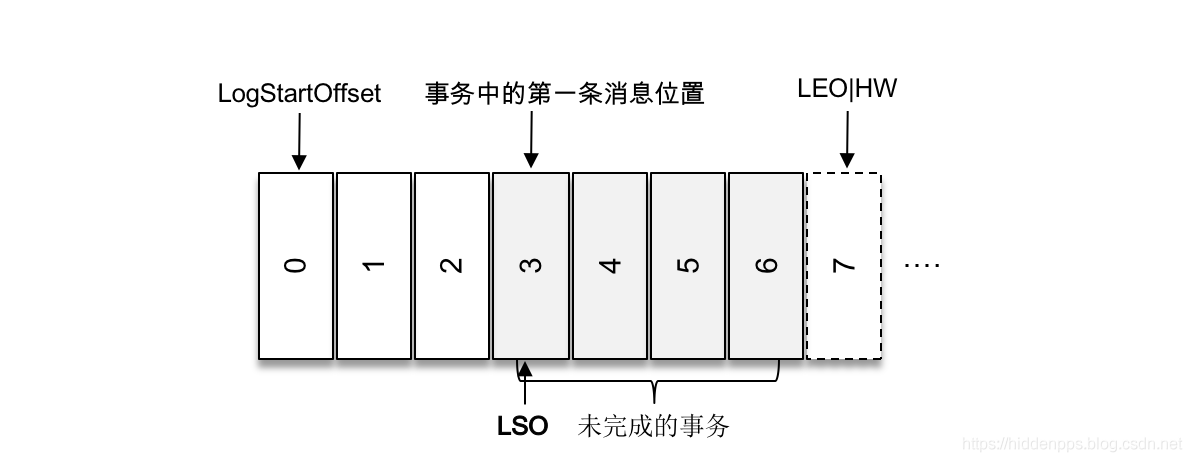 ii) 对已完成的事务而言,它的值同 HWM 相同
ii) 对已完成的事务而言,它的值同 HWM 相同
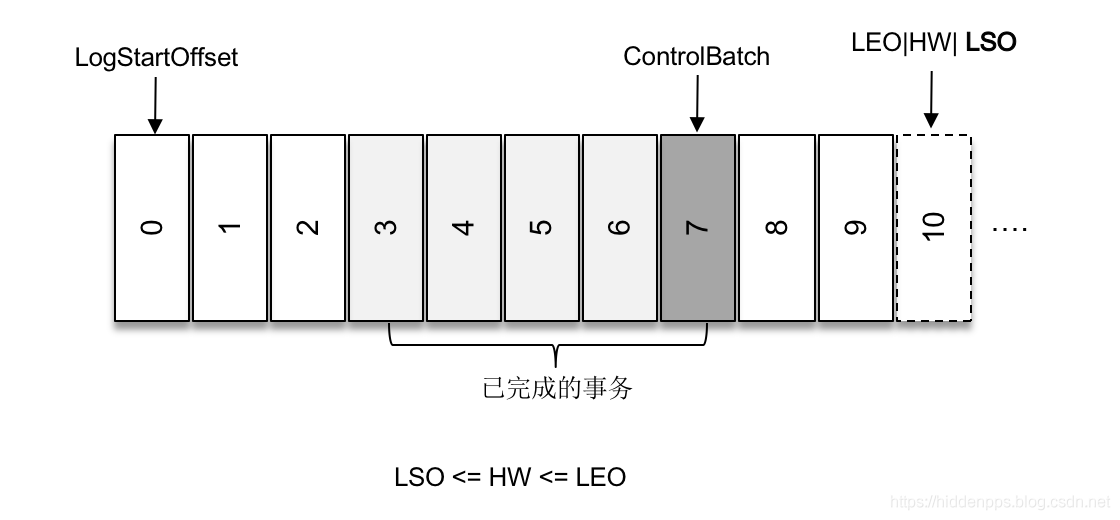 注意,图中的ControlBatch即Control message
注意,图中的ControlBatch即Control message
查看:
./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list xxxx --time -1 --topic xxx
why offsets increment by 2 instead of 1?
对于 Transactional producer来说,除了写入msg之外,还会写入 abort/commit marker
Finally writes the COMMITTED (or ABORTED) message to transaction log
大家的吐槽:
Consumer Groups
选择模式:
1) Having consumers as part of the same consumer group means providing the“competing consumers” pattern with whom the messages from topic partitions are spread across the members of the group.
2) Having consumers as part of different consumer groups means providing the “publish/subscribe” pattern where the messages from topic partitions are sent to all the consumers across the different groups.
线程安全:
You can’t have multiple consumers that belong to the same group in one thread and you can’t have multiple threads safely use the same consumer. One consumer per thread is the rule. To run multiple consumers in the same group in one application, you will need to run each in its own thread. It is useful to wrap the consumer logic in its own object and then use Java’s ExecutorService to start multiple threads each with its own consumer:
public class ConsumerLoop implements Runnable {
private final KafkaConsumer<String, String> consumer;
private final List<String> topics;
private final int id;
public ConsumerLoop(int id,
String groupId,
List<String> topics) {
this.id = id;
this.topics = topics;
Properties props = new Properties();
props.put(“group.id”, groupId);
props.put(“key.deserializer”, StringDeserializer.class.getName());
props.put(“value.deserializer”, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(props);
}
@Override
public void run() {
try {
consumer.subscribe(topics);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (ConsumerRecord<String, String> record : records) {
Map<String, Object> data = new HashMap<>();
data.put("partition", record.partition());
data.put("offset", record.offset());
data.put("value", record.value());
System.out.println(this.id + ": " + data);
}
}
} catch (WakeupException e) {
// ignore for shutdown
} finally {
consumer.close();
}
}
public void shutdown() {
consumer.wakeup();
}
}
public static void main(String[] args) {
int numConsumers = 3;
String groupId = "consumer-tutorial-group"
List<String> topics = Arrays.asList("consumer-tutorial");
ExecutorService executor = Executors.newFixedThreadPool(numConsumers);
final List<ConsumerLoop> consumers = new ArrayList<>();
for (int i = 0; i < numConsumers; i++) {
ConsumerLoop consumer = new ConsumerLoop(i, topics);
consumers.add(consumer);
executor.submit(consumer);
}
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
for (ConsumerLoop consumer : consumers) {
consumer.shutdown();
}
}
});
}
-- https://www.confluent.io/blog/tutorial-getting-started-with-the-new-apache-kafka-0-9-consumer-client/
Consumer GroupCoordinator
The way consumers maintain membership in a consumer group and ownership of the partitions assigned to them is by sending heartbeats to a Kafka broker designated as the group coordinator (this broker can be different for different consumer groups). As long as the consumer is sending heartbeats at regular intervals, it is assumed to be alive, well, and processing messages from its partitions.
Heartbeats are sent when the consumer polls (i.e., retrieves records) and when it commits records it has consumed.https://www.oreilly.com/library/view/kafka-the-definitive/9781491936153/ch04.html
确定一个 Consumer Group 的 GroupCoordinator 的位置:
- abs (GroupId.hashCode) % NumPartition,NumPartition 就是__consumer_offsets 的分区数
- 计算结果表示了__consumer_offsets 的一个 partition比如
__consumer_offsets-10 - 找到该
__consumer_offsets-10的 leader 所在的 broker如broker id=3,即该consumer group的 GroupCoordinator, - 当该consumer group的GroupCoordinator挂掉时,也就是这个broker挂掉后,其他borkers(保存有
__consumer_offsets-10的replica的节点)会选一个broker如broker id=1作为新的__consumer_offsets-10的leader,然后该broker会load 本机保存的__consumer_offsets-10replica到内存中,完成后,Client端就会discover该broker作为新的GroupCoordinator - 当broker id=3恢复正常后,会抢回broker id=1之前接管的
__consumer_offsets-10,重新作为该topic的leader,然后client端就重新discover broker id=3作为group coordinator,这种抢回的方式可以保证kafka节点任务均衡(注意,broker id=3恢复之后,通过kafka-topics.sh –list 查看,__consumer_offsets-10的leader仍然会是broker id 1,需要等到再接收一条新的kafka消息后,leader才会切换成broker id 3,外部topic也是如此,__transaction_state也是类似,可能是生产一条消息时更新)
2.关键配置
Consumer Client Config
auto.create.topics.enable
Enable auto creation of topic on the server Type: boolean Default: true Valid Values: Importance: high Update Mode: read-only
request.timeout.ms & retries
request.timeout.ms: The configuration controls the maximum amount of time the client will wait for the response of a request. If the response is not received before the timeout elapses the client will resend the request if necessary or fail the request if retries are exhausted.
Type: int Default: 30000 (30 seconds)
retries:
Setting a value greater than zero will cause the client to resend any request that fails with a potentially transient error. It is recommended to set the value to either zero or MAX_VALUE and use corresponding timeout parameters to control how long a client should retry a request.
Type: int Default: 0 Valid Values: [0,…,2147483647] Importance: low
max.poll.interval.ms vs session.timeout.ms
max.poll.interval.ms: The maximum delay between invocations of poll() when using consumer group management. This places an upper bound on the amount of time that the consumer can be idle before fetching more records. If poll() is not called before expiration of this timeout, then the consumer is considered failed and the group will rebalance in order to reassign the partitions to another member. For consumers using a non-null group.instance.id which reach this timeout, partitions will not be immediately reassigned. Instead, the consumer will stop sending heartbeats and partitions will be reassigned after expiration of session.timeout.ms. This mirrors the behavior of a static consumer which has shutdown.
Type: int Default: 300000 (5 minutes) Valid Values: [1,…] Importance: medium
session.timeout.ms: The timeout used to detect client failures when using Kafka’s group management facility. The client sends periodic heartbeats to indicate its liveness to the broker. If no heartbeats are received by the broker before the expiration of this session timeout, then the broker will remove this client from the group and initiate a rebalance. Note that the value must be in the allowable range as configured in the broker configuration by group.min.session.timeout.ms and group.max.session.timeout.ms.
Type: int Default: 45000 (45 seconds) Valid Values: Importance: high
Before KIP-62, there is only session.timeout.ms (ie, Kafka 0.10.0 and earlier). max.poll.interval.ms is introduced via KIP-62 (part of Kafka 0.10.1). KIP-62, decouples heartbeats from calls to poll() via a background heartbeat thread, allowing for a longer processing time (ie, time between two consecutive poll()) than heartbeat interval. Assume processing a message takes 1 minute. If heartbeat and poll are coupled (ie, before KIP-62), you will need to set session.timeout.ms larger than 1 minute to prevent consumer to time out. However, if a consumer dies, it also takes longer than 1 minute to detect the failed consumer. KIP-62 decouples polling and heartbeat allowing to send heartbeats between two consecutive polls. Now you have two threads running, the heartbeat thread and the processing thread and thus, KIP-62 introduced a timeout for each. session.timeout.ms is for the heartbeat thread while max.poll.interval.ms is for the processing thread. Assume, you set session.timeout.ms=30000, thus, the consumer heartbeat thread must sent a heartbeat to the broker before this time expires. On the other hand, if processing of a single message takes 1 minutes, you can set max.poll.interval.ms larger than one minute to give the processing thread more time to process a message. If the processing thread dies, it takes max.poll.interval.ms to detect this. However, if the whole consumer dies (and a dying processing thread most likely crashes the whole consumer including the heartbeat thread), it takes only session.timeout.ms to detect it. The idea is, to allow for a quick detection of a failing consumer even if processing itself takes quite long. https://stackoverflow.com/questions/39730126/difference-between-session-timeout-ms-and-max-poll-interval-ms-for-kafka-0-10
scheduled.rebalance.max.delay.ms
The maximum delay that is scheduled in order to wait for the return of one or more departed workers before rebalancing and reassigning their connectors and tasks to the group. During this period the connectors and tasks of the departed workers remain unassigned
Type: int Default: 300000 (5 minutes)
session.timeout.ms
After every rebalance, all members of the current generation begin sending periodic heartbeats to the group coordinator. As long as the coordinator continues receiving heartbeats, it assumes that members are healthy. On every received heartbeat, the coordinator starts (or resets) a timer. If no heartbeat is received when the timer expires, the coordinator marks the member dead and signals the rest of the group that they should rejoin so that partitions can be reassigned. The duration of the timer is known as the session timeout and is configured on the client with the setting session.timeout.ms. The only problem with this is that a spurious rebalance might be triggered if the consumer takes longer than the session timeout to process messages. You should therefore set the session timeout large enough to make this unlikely. The default is 30 seconds, but it’s not unreasonable to set it as high as several minutes. The only downside of a larger session timeout is that it will take longer for the coordinator to detect genuine consumer crashes.
metadata.max.age.ms
不是订阅某个topic 而是订阅某种pattern repeat subscribe() Kafka pattern subscription. Rebalancing is not being triggered on new topic
Broker Config
to do
3.客户端关键API及源码解读
poll
public ConsumerRecords<K,V> poll(long timeoutMs)
The poll API returns fetched records based on the current position.
poll的行为:
On each poll, consumer will try to use the last consumed offset as the starting offset and fetch sequentially. The last consumed offset can be manually set through seek(TopicPartition, long) or automatically set as the last committed offset for the subscribed list of partitions 即如果不显示调用 seek来设置其位置,将会自动使用interal offset来定位其最后一次消费的位置。
更完整的:
When the group is first created, the position will be set according to the reset policy (which is typically either set to the earliest or latest offset for each partition defined by the auto.offset.reset). Once the consumer begins committing offsets, then each later rebalance will reset the position to the last committed offset. The parameter passed to poll controls the maximum amount of time that the consumer will block while it awaits records at the current position. The consumer returns immediately as soon as any records are available, but it will wait for the full timeout specified before returning if nothing is available.
具体的:
第一次(触发reblance)poll的行为:
The poll loop does a lot more than just get data. The first time you call poll() with a new consumer, it is responsible for finding the GroupCoordinator, joining the consumer group, and receiving a partition assignment.[注意:只是subscribe topic并不能立即引发rebalance,可以在subscribe之后第一次poll,从而立即引发rebalance] If a rebalance is triggered, it will be handled inside the poll loop as well. And of course the heartbeats that keep consumers alive are sent from within the poll loop. For this reason, we try to make sure that whatever processing we do between iterations is fast and efficient.
KIP-62, decouples heartbeats from calls to poll() via a background heartbeat thread, allowing for a longer processing time (ie, time between two consecutive poll()) than heartbeat interval.
第二次之后poll的行为:
从上一次的fetch positions继续往下拉取
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) {
acquireAndEnsureOpen();
try {
if (this.subscriptions.hasNoSubscriptionOrUserAssignment()) {
throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions");
}
do {
client.maybeTriggerWakeup();
if (includeMetadataInTimeout) {
if (!updateAssignmentMetadataIfNeeded(timer)) {
return ConsumerRecords.empty();
}
} else {
while (!updateAssignmentMetadataIfNeeded(time.timer(Long.MAX_VALUE))) {
log.warn("Still waiting for metadata");
}
}
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer);
if (!records.isEmpty()) {
if (fetcher.sendFetches() > 0 || client.hasPendingRequests()) {
client.pollNoWakeup();
}
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
} while (timer.notExpired());
return ConsumerRecords.empty();
} finally {
release();
}
}
boolean updateAssignmentMetadataIfNeeded(final Timer timer) {
if (coordinator != null && !coordinator.poll(timer)) {
return false;
}
return updateFetchPositions(timer);
}
1.Polling coordinator for updates — ensure we’re up-to-date with our group’s coordinator.
2.Updating fetch positions — ensure every partition assigned to this consumer has a fetch position. If it is missing then consumer uses auto.offset.reset value to set it (set it to earliest, latest or throw exception).
Kafka maintains a numerical offset for each record in a partition. This offset acts as a unique identifier of a record within that partition, and also denotes the position of the consumer in the partition. For example, a consumer which is at position 5 has consumed records with offsets 0 through 4 and will next receive the record with offset 5. There are actually two notions of position relevant to the user of the consumer:
-
The position of the consumer gives the offset of the next record that will be given out. It will be one larger than the highest offset the consumer has seen in that partition. It automatically advances every time the consumer receives messages in a call to poll(Duration). The position of the consumer == consumed position == current position
-
The committed position is the last offset that has been stored securely. Should the process fail and restart, this is the offset that the consumer will recover to. The consumer can either automatically commit offsets periodically; or it can choose to control this committed position manually by calling one of the commit APIs (e.g. commitSync and commitAsync). The committed position == last committed offset
This distinction gives the consumer control over when a record is considered consumed.
endoffsets
- Get the end offsets for the given partitions. In the default {@code read_uncommitted} isolation level, the end
- offset is the high watermark (that is, the offset of the last successfully replicated message plus one). For
- {@code read_committed} consumers, the end offset is the last stable offset (LSO), which is the minimum of
- the high watermark and the smallest offset of any open transaction. Finally, if the partition has never been
- written to, the end offset is 0.
How to get the msg of lastoffset?
Solution: seek(endOffsets()-n) then poll, 对于普通的消息n=1,但是涉及到事务 transactional msg n=2
ConsumerRebalanceListener
onPartitionsRevoked && onPartitionsAssigned
It is guaranteed that all the processes in a consumer group will execute their
onPartitionsRevoked(Collection)callback before any instance executes itsonPartitionsAssigned(Collection)callback.
<=kafka2.3 Stop the World:
发生rebalance时,kafka会保证所有之前的consumer无法继续消费消息(连heartbeat都停止了,提示消息 Attempt to heartbeat failed since group is rebalancing),然后会先通过 onPartitionsRevoked 回调所有的consumer,待所有consumer的onPartitionsRevoked完成之后,才会继续回调onPartitionsAssigned(笔者测试到一种情况,就是consumergroup有服务A和B,A因为网络问题,导致kafka集群决定将所有partition分配给B,所以kafka集群发送revoke给A和B,因为A有网络问题,B就没有等待A完成revoke,直接启动了,而过了两分钟,A才收到kafka集群的消息,后面exactly once笔者给出了场景图示)
>=kafka2.4 Incremental rebalance
4. Exactly-Once 场景分析
理解角度:
- kafka本身的保证
- nothing to guarantee
- at-least-once Messages are never lost but may be redelivered.
- at-most-once Messages may be lost but are never redelivered.
- exactly-once This is what people actually want, each message is delivered once and only once.
- 基于kafka的用户代码的保证 业务处理逻辑和offset维护逻辑
具体场景:
上游(consume topic 1-transform-produce to topic 2)->下游(consume topic 2….)
目标:
对上游和下游都实现 atomic-read-process-write
4.1 上游(consume topic 1) -依赖consumer internal offset
先来看比较简单的场景就是只有 consumer topic,不通过 seek来设置位置直接poll,自动使用interal offset来定位其最后一次消费的位置,注意下面的两个使用方法 at-least-once 至少一次当然可能会重复消费,但是也可能丢失信息
4.1.1 自动提交offset,at-least-once
Setting enable.auto.commit means that offsets are committed automatically with a frequency controlled by the config auto.commit.interval.ms.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
When a partition gets reassigned to another consumer in the group, the initial position is set to the last committed offset. If the consumer in the example above suddenly crashed, then the group member taking over the partition would begin consumption from offset 1. In that case, it would have to reprocess the messages up to the crashed consumer’s position of 6.
The diagram also shows two other significant positions in the log. The log end offset is the offset of the last message written to the log. The high watermark is the offset of the last message that was successfully copied to all of the log’s replicas. From the perspective of the consumer, the main thing to know is that you can only read up to the high watermark. This prevents the consumer from reading unreplicated data which could later be lost.
4.1.2 手动提交offset,at-least-once
Instead of relying on the consumer to periodically commit consumed offsets, users can also control when records should be considered as consumed and hence commit their offsets. This is useful when the consumption of the messages is coupled with some processing logic and hence a message should not be considered as consumed until it is completed processing.
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "false");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
final int minBatchSize = 200;
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
insertIntoDb(buffer);
consumer.commitSync();
buffer.clear();
}
}
In this example we will consume a batch of records and batch them up in memory. When we have enough records batched, we will insert them into a database. If we allowed offsets to auto commit as in the previous example, records would be considered consumed after they were returned to the user in poll. It would then be possible for our process to fail after batching the records, but before they had been inserted into the database.
To avoid this, we will manually commit the offsets only after the corresponding records have been inserted into the database. This gives us exact control of when a record is considered consumed. This raises the opposite possibility: the process could fail in the interval after the insert into the database but before the commit (even though this would likely just be a few milliseconds, it is a possibility). In this case the process that took over consumption would consume from last committed offset and would repeat the insert of the last batch of data. Used in this way Kafka provides what is often called “at-least-once” delivery guarantees, as each record will likely be delivered one time but in failure cases could be duplicated.
上面at-least-once 也不是绝对的,也可能丢数据(nothing to guarantee):
Note: Using automatic offset commits can also give you “at-least-once” delivery, but the requirement is that you must consume all data returned from each call to poll(long) before any subsequent calls, or before closing the consumer. If you fail to do either of these, it is possible for the committed offset to get ahead of the consumed position, which results in missing records. The advantage of using manual offset control is that you have direct control over when a record is considered “consumed.”
The above example uses commitSync to mark all received records as committed. In some cases you may wish to have even finer control over which records have been committed by specifying an offset explicitly. In the example below we commit offset after we finish handling the records in each partition.
try {
while(running) {
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
System.out.println(record.offset() + ": " + record.value());
}
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
} finally {
consumer.close();
}
Note: The committed offset should always be the offset of the next message that your application will read. Thus, when calling commitSync(offsets) you should add one to the offset of the last message processed.
4.2 上游(consume topic 1-transform-produce to topic 2) - 手动提交/producer提交 at-most-once
idempotent producer:
Prior to 0.11.0.0, if a producer failed to receive a response indicating that a message was committed, it had little choice but to resend the message. This provides at-least-once delivery semantics since the message may be written to the log again during resending if the original request had in fact succeeded. Since 0.11.0.0, the Kafka producer also supports an idempotent delivery option which guarantees that resending will not result in duplicate entries in the log. To achieve this, the broker assigns each producer an ID and deduplicates messages using a sequence number that is sent by the producer along with every message.
4.3 上游(consume topic 1-transform-produce to topic 2) - 手动提交/producer提交 exactly-once
Also beginning with 0.11.0.0, the producer supports the ability to send messages to multiple topic partitions using transaction-like semantics: i.e. either all messages are successfully written or none of them are. The main use case for this is exactly-once processing between Kafka topics
接着看上游比较完整的 consumer-transform-produce 场景
4.3.1 依赖 interal offset,exactly-once
重点: 前面的”上游(consume topic 1) -依赖internal offset” 是依赖 consumer提交offset,而对于atomic-read-process-write需要Producer提交offset,Producer#sendOffsetsToTransaction
example 1:
public class KafkaTransactionsExample {
public static void main(String args[]) {
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerConfig);
// Note that the ‘transactional.id’ configuration _must_ be specified in the
// producer config in order to use transactions.
KafkaProducer<String, String> producer = new KafkaProducer<>(producerConfig);
// We need to initialize transactions once per producer instance. To use transactions,
// it is assumed that the application id is specified in the config with the key
// transactional.id.
//
// This method will recover or abort transactions initiated by previous instances of a
// producer with the same app id. Any other transactional messages will report an error
// if initialization was not performed.
//
// The response indicates success or failure. Some failures are irrecoverable and will
// require a new producer instance. See the documentation for TransactionMetadata for a
// list of error codes.
producer.initTransactions();
while(true) {
ConsumerRecords<String, String> records = consumer.poll(CONSUMER_POLL_TIMEOUT);
if (!records.isEmpty()) {
// Start a new transaction. This will begin the process of batching the consumed
// records as well
// as an records produced as a result of processing the input records.
//
// We need to check the response to make sure that this producer is able to initiate
// a new transaction.
producer.beginTransaction();
// Process the input records and send them to the output topic(s).
List<ProducerRecord<String, String>> outputRecords = processRecords(records);
for (ProducerRecord<String, String> outputRecord : outputRecords) {
producer.send(outputRecord);
}
// To ensure that the consumed and produced messages are batched, we need to commit
// the offsets through
// the producer and not the consumer.
//
// If this returns an error, we should abort the transaction.
sendOffsetsResult = producer.sendOffsetsToTransaction(getUncommittedOffsets());
// Now that we have consumed, processed, and produced a batch of messages, let's
// commit the results.
// If this does not report success, then the transaction will be rolled back.
producer.endTransaction();
}
}
}
}
example 2:
KafkaProducer producer = createKafkaProducer(
“bootstrap.servers”, “localhost:9092”,
“transactional.id”, “my-transactional-id”);
producer.initTransactions();
KafkaConsumer consumer = createKafkaConsumer(
“bootstrap.servers”, “localhost:9092”,
“group.id”, “my-group-id”,
"isolation.level", "read_committed");
consumer.subscribe(singleton(“inputTopic”));
while (true) {
ConsumerRecords records = consumer.poll(Long.MAX_VALUE);
producer.beginTransaction();
for (ConsumerRecord record : records)
producer.send(producerRecord(“outputTopic”, record));
producer.sendOffsetsToTransaction(currentOffsets(consumer), group);
producer.commitTransaction();
}
4.3.2 不依赖interal offset,自己维护offset exactly-once
The consumer application need not use Kafka’s built-in offset storage, it can store offsets in a store of its own choosing, example usage:
- If the results of the consumption are being stored in a relational database, storing the offset in the database as well can allow committing both the results and offset in a single transaction. Thus either the transaction will succeed and the offset will be updated based on what was consumed or the result will not be stored and the offset won’t be updated.
- If the results are being stored in a local store it may be possible to store the offset there as well. For example a search index could be built by subscribing to a particular partition and storing both the offset and the indexed data together. If this is done in a way that is atomic, it is often possible to have it be the case that even if a crash occurs that causes unsync’d data to be lost, whatever is left has the corresponding offset stored as well. This means that in this case the indexing process that comes back having lost recent updates just resumes indexing from what it has ensuring that no updates are lost.
比如存储offset到自己维护的一个topic T-SNP 作为增量数据主题
消费时:
Configure enable.auto.commit=false
因为每条record 都携带其offset信息根据模型
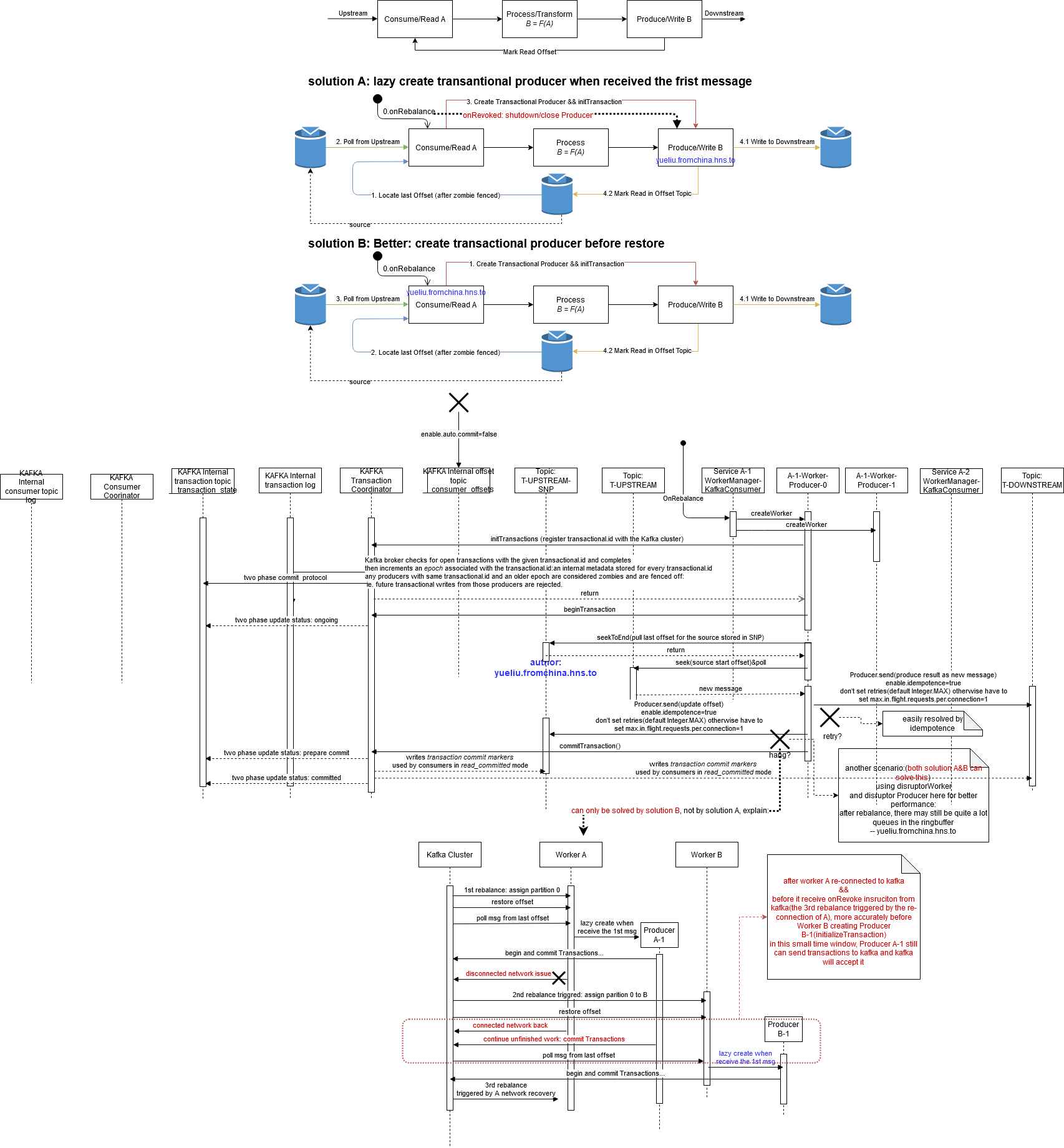 ,将write和mark read(Use the offset provided with each
,将write和mark read(Use the offset provided with each ConsumerRecord to save your position)作为一个transaction提交;
启动或“重启”时:
则找到最后一个消息,即存储的最后一个offset,方法:
endOffsets(返回the offset of the upcoming message, i.e. the offset of the last available message + 1. 所以-1就是到了last available message的位置,还要再-1才能再后面poll到这条消息) –> assign —> seek(不能用seekToEnd,用了则poll不到任何消息,只能等待新消息) —> poll
,然后通过获取的offset定位恢复restore到上一次这个topic的position处理位置 seek(TopicPartition, long),然后再poll
注意:
- 如果想要zombie fence生效,除了用对transaction.id,这个顺序也很重要,要先去initTransaction注册 transaction.id(形象的说就是争取到合法身份先),然后才是去restore(读取增量快照做恢复),否则,如果你先去restore,再去注册(创建Transactional Producer并initTransactions),有可能restore的时候读取到增量快照是 1000,旧的Producer仍然可以继续写入kafka:
- case 1:遇到过一次disruptor ringbuffer在rebalance之后继续工作重复落库的事情,解决办法:onrevoke的时候关闭producer
- case 2:case 1只适用于单实例模式,如果是多活模式,在网络抖动的时间窗内,仍然有机会产生该问题 ,因此等到 去注册(争取合法身份)的时候,增量快照可能已经到了2000,然后因为你先做的restore,你会定位到1000,将1001开始的都当做新消息:
每个consumer group中的服务rebalance的正确启动顺序应该是:
- 先根据 kafka分配的partition创建好worker(主要是Transactional Producer),这个做完后,会立即让fence生效,不用再担心 其他服务上仍在等待shutdown的disruptorWorker继续消费ringbuffer的缓存消息
- 读取增量快照进行restore,由于第1步做完,我们完全相信kafka可以履行zombie fence,所以这里可以100%确定可以拿到准确的 last offset,从而准确的恢复
-
有一个缺点是,虽然我们启动时可以判断,比如[0,1000]是之前处理过的,1001开始是新的数据,但是为了使内存恢复到之前的状态,仍然需要对[0,1000]这个区间的数据进行计算(只不过不进行任何事务处理比如落数据库,只是单纯为了restore memory),所以一个改进策略就是,增加全量快照,系统停止之前或定期将内存序列化存起来,注意存的时候同时存下当时的offset,比如1000,然后在增量快照中记录下这个全量快照的位置(当然还有我们要保存的offset)即可,由于为了记录下全量快照的kafka位置,需要等待kafka send的回调,所以记录到增量快照没有办法跟保存全量快照作为一个事务处理,不过没关系:
比如主题T-TARGET ,现在处理到了offset=1000,决定做一次全量快照,此时全量快照中保存下内存状态和start offset=1000,kafka send全量快照到 T-QuanLiang中,然后在callback时,可以获取到全量快照在T-QuanLiang的 quanliang offset比如=0,T-TARGET进来新的消息(或者之前做全量快照的指令本身就是条消息),继续事务性的记录增量快照 T-ZengLiang,此时最新记录的增量消息的内容是 quanliang offset=0&&end offset=1001
恢复的时候,先 找到T-ZengLiang最后一个消息 ,获取到quanliang offset=0&&end offset=1001,然后通过quanliang offset=0去seek(T-QuanLiang, 0) 拿到 start offset=1000和当时的内存数据,从而恢复内存数据,然后从1000开始(1000,1001],只需要重新计算下1001这条数据更新下内存即可,从1002开始往后都是新的消息
4.4 上游(produce to topic 2)->下游(consume topic 2) - isolation.level
we can indicate with *isolation.level* that we should wait to read transactional messages until the associated transaction has been committed:
consumerProps.put("isolation.level", "read_committed");
在消费端有一个参数isolation.level,设置为“read_committed”,表示消费端应用不可以看到尚未提交的事务内的消息。如果生产者开启事务并向某个分区值发送3条消息 msg1、msg2 和 msg3,在执行 commitTransaction() 或 abortTransaction() 方法前,设置为“read_committed”的消费端应用是消费不到这些消息的,不过在 KafkaConsumer 内部会缓存这些消息,直到生产者执行 commitTransaction() 方法之后它才能将这些消息推送给消费端应用。反之,如果生产者执行了 abortTransaction() 方法,那么 KafkaConsumer 会将这些缓存的消息丢弃而不推送给消费端应用。
kafka isolation level implications
Troubleshooting
网络故障 / kafka集群有节点挂掉(不是正常停节点,而是broker节点所在服务器网络断开或暴力停机)
造成kafka client端程序读取 metadata 超过默认 30s 抛错
public java.util.Map<TopicPartition,java.lang.Long> endOffsets(java.util.Collection
TimeoutException - if the offset metadata could not be fetched before the amount of time allocated by request.timeout.ms expires
异常日志分析:
场景1:
现在dev上3个节点配置 borker 0 1 2:
offsets.topic.replication.factor=3
min.insync.isr=2
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=2
default.replication.factor=3
正常挂掉1个是没问题的,但是居然挂掉2个居然都能启动client端(能成功join group,kafka成功rebalance):
这个比较诡异,就是测试的时候其实只有两个活着的节点,broker 0不知道被谁用root更改了几个kafka-logs文件权限,造成borker 0停了,
,然后测试断开broker 2的网络,只有broker 1一个可用节点,client端居然能够启动并且订阅topic,只不过恢复的时候(onPartitionAssign内部进一步访问kafka读取快照数据)抛错,比如可能是恢复的时候创建临时consumer,kafka服务端向zookeeper注册的时候出现超时(下面有zookeeper问题的log),
2022-03-12 18:33:29.793 [31mERROR[m [35m15732GG[m [TEST-MANAGER] [36mo.a.k.c.c.i.ConsumerCoordinator[m : [Consumer clientId=consumer-2, groupId=TEST-TRADEFRONT-SZL] User provided listener com.lyhistory.core.boot.SimpleWorkBalancer failed on partition assignment
com.lyhistory.core.exception.RecoveryException: Failed Recovery Worker
at com.lyhistory.core.boot.SimpleWorkBalancer.onPartitionsAssigned(SimpleWorkBalancer.java:54)
at org.apache.kafka.clients.consumer.internals.ConsumerCoordinator.onJoinComplete(ConsumerCoordinator.java:292)
at org.apache.kafka.clients.consumer.internals.AbstractCoordinator.joinGroupIfNeeded(AbstractCoordinator.java:410)
at org.apache.kafka.clients.consumer.internals.AbstractCoordinator.ensureActiveGroup(AbstractCoordinator.java:344)
at org.apache.kafka.clients.consumer.internals.ConsumerCoordinator.poll(ConsumerCoordinator.java:342)
at org.apache.kafka.clients.consumer.KafkaConsumer.updateAssignmentMetadataIfNeeded(KafkaConsumer.java:1226)
at org.apache.kafka.clients.consumer.KafkaConsumer.poll(KafkaConsumer.java:1191)
at org.apache.kafka.clients.consumer.KafkaConsumer.poll(KafkaConsumer.java:1176)
at com.lyhistory.core.boot.SimpleWorkerManager.doServe(SimpleWorkerManager.java:96)
at com.lyhistory.core.boot.AdministrableService.serve(AdministrableService.java:98)
at com.lyhistory.core.boot.AdministrableService.start(AdministrableService.java:36)
at com.lyhistory.core.boot.Starter$$Lambda$826/315805187.run(Unknown Source)
at java.lang.Thread.run(Thread.java:745)
Caused by: com.lyhistory.core.exception.RecoveryException: Failed Recovery Worker
at com.lyhistory.core.boot.SimpleWorkBalancer.getWorkState(SimpleWorkBalancer.java:64)
at com.lyhistory.core.boot.SimpleWorkBalancer$$Lambda$872/1231621690.apply(Unknown Source)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:512)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:502)
at java.util.stream.ForEachOps$ForEachOp.evaluateSequential(ForEachOps.java:151)
at java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateSequential(ForEachOps.java:174)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:418)
at com.lyhistory.core.boot.SimpleWorkBalancer.onPartitionsAssigned(SimpleWorkBalancer.java:52)
... 12 more
Caused by: java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.TimeoutException: Failed to get offsets by times in 30000ms
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at com.lyhistory.core.boot.SimpleWorkBalancer.getWorkState(SimpleWorkBalancer.java:62)
... 22 more
Caused by: org.apache.kafka.common.errors.TimeoutException: Failed to get offsets by times in 30000ms
但是正常不应该能够订阅topic,应该抛出错误类似:
1 partitions have leader brokers without a matching listener (因为factor=2,挂了2台了肯定有节点的leader不在了)
或者
insufficient isr (min.isr=2>live broker=1)
从而导致client无法join group:
Group coordinator XXXX:9092 (id: 2147483647 rack: null) is unavailable or invalid, will attempt rediscovery
猜测1: broker 0并非真的挂,只是因为kafka log文件权限为root,造成kafka服务处于异常状态(还可以跟其他机器沟通),所以此时仍然满足min.isr=2的要求
否定:根据broker 0上面的日志,可以看到kafka根本没有对应时间段的任何日志
猜测2: 虽然broker 2网络断开,此时 broker 2 对于 broker 1 来说属于假死状态,尚未更新metadata,所以没有检测出insufficient isr
验证:发现断网后出现如下错误 Opening socket connection to server sgkc2-devclr-v07/x.x.x.47:2181. Will not attempt to authenticate using SASL (unknown error)
比较可靠的猜测:猜测2基本对的,不过不是假死,而是本身就已经成了孤立节点,又无法与broker 0和2的zookeeper通信更新信息,从而造成kafka服务端异常,产生了绕过min.isr限制的假象
[2022-03-14 08:59:39,144] WARN Client session timed out, have not heard from server in 4002ms for sessionid 0x17862f2bedc0004 (org.apache.zookeeper.ClientCnxn)
[2022-03-14 08:59:39,145] INFO Client session timed out, have not heard from server in 4002ms for sessionid 0x17862f2bedc0004, closing socket connection and attempting reconnect (org.apache.zookeeper.ClientCnxn)
[2022-03-14 08:59:39,826] INFO Opening socket connection to server sgkc2-devclr-v07/x.x.x.47:2181. Will not attempt to authenticate using SASL (unknown error) (org.apache.zookeeper.ClientCnxn)
[2022-03-14 08:59:41,829] WARN Client session timed out, have not heard from server in 2583ms for sessionid 0x17862f2bedc0004 (org.apache.zookeeper.ClientCnxn)
[2022-03-14 08:59:41,829] INFO Client session timed out, have not heard from server in 2583ms for sessionid 0x17862f2bedc0004, closing socket connection and attempting reconnect (org.apache.zookeeper.ClientCnxn)
[2022-03-14 08:59:42,820] INFO Opening socket connection to server sgkc2-devclr-v05/x.x.x.45:2181. Will not attempt to authenticate using SASL (unknown error) (org.apache.zookeeper.ClientCnxn)
[2022-03-14 08:59:42,821] INFO Socket error occurred: sgkc2-devclr-v05/x.x.x.45:2181: Connection refused (org.apache.zookeeper.ClientCnxn)
[2022-03-14 09:00:00,597] INFO [ReplicaFetcher replicaId=1, leaderId=2, fetcherId=0] Error sending fetch request (sessionId=2095832195, epoch=8913816) to node 2: java.io.IOException: Connection to 2 was disconnected before the response was read. (org.apache.kafka.clients.FetchSessionHandler)
[2022-03-14 09:00:00,598] WARN [ReplicaFetcher replicaId=1, leaderId=2, fetcherId=0] Error in response for fetch request (type=FetchRequest, replicaId=1, maxWait=500, minBytes=1, maxBytes=10485760, fetchData={}, isolationLevel=READ_UNCOMMITTED, toForget=, metadata=(sessionId=2095832195, epoch=8913816)) (kafka.server.ReplicaFetcherThread)
java.io.IOException: Connection to 2 was disconnected before the response was read
at org.apache.kafka.clients.NetworkClientUtils.sendAndReceive(NetworkClientUtils.java:100)
at kafka.server.ReplicaFetcherBlockingSend.sendRequest(ReplicaFetcherBlockingSend.scala:100)
at kafka.server.ReplicaFetcherThread.fetchFromLeader(ReplicaFetcherThread.scala:193)
at kafka.server.AbstractFetcherThread.processFetchRequest(AbstractFetcherThread.scala:280)
at kafka.server.AbstractFetcherThread.$anonfun$maybeFetch$3(AbstractFetcherThread.scala:132)
at kafka.server.AbstractFetcherThread.$anonfun$maybeFetch$3$adapted(AbstractFetcherThread.scala:131)
at scala.Option.foreach(Option.scala:274)
at kafka.server.AbstractFetcherThread.maybeFetch(AbstractFetcherThread.scala:131)
at kafka.server.AbstractFetcherThread.doWork(AbstractFetcherThread.scala:113)
at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:82)
。。。
[2022-03-14 09:00:32,612] INFO [ReplicaFetcher replicaId=1, leaderId=2, fetcherId=0] Error sending fetch request (sessionId=2095832195, epoch=INITIAL) to node 2: java.net.SocketTimeoutException: Failed to connect within 30000 ms. (org.apache.kafka.clients.FetchSessionHandler)
[2022-03-14 09:00:32,612] WARN [ReplicaFetcher replicaId=1, leaderId=2, fetcherId=0] Error in response for fetch request (type=FetchRequest, replicaId=1, maxWait=500, minBytes=1, maxBytes=10485760, fetchData={T-TRADE-CHK-0=(fetchOffset=0, logStartOffset=0, maxBytes=1048576, currentLeaderEpoch=Optional[0]), T-EOD-SNP-1=(fetchOffset=86, logStartOffset=86, maxBytes=1048576, currentLeaderEpoch=Optional[0]), T-DBMS-CHK-0=(fetchOffset=2002, logStartOffset=1992, maxBytes=1048576, currentLeaderEpoch=Optional[0]), T-CAPTURE-2=(fetchOffset=2002, logStartOffset=1992, maxBytes=1048576, currentLeaderEpoch=Optional[0])}, isolationLevel=READ_UNCOMMITTED, toForget=, metadata=(sessionId=2095832195, epoch=INITIAL)) (kafka.server.ReplicaFetcherThread)
java.net.SocketTimeoutException: Failed to connect within 30000 ms
at kafka.server.ReplicaFetcherBlockingSend.sendRequest(ReplicaFetcherBlockingSend.scala:96)
at kafka.server.ReplicaFetcherThread.fetchFromLeader(ReplicaFetcherThread.scala:193)
at kafka.server.AbstractFetcherThread.processFetchRequest(AbstractFetcherThread.scala:280)
at kafka.server.AbstractFetcherThread.$anonfun$maybeFetch$3(AbstractFetcherThread.scala:132)
at kafka.server.AbstractFetcherThread.$anonfun$maybeFetch$3$adapted(AbstractFetcherThread.scala:131)
at scala.Option.foreach(Option.scala:274)
at kafka.server.AbstractFetcherThread.maybeFetch(AbstractFetcherThread.scala:131)
at kafka.server.AbstractFetcherThread.doWork(AbstractFetcherThread.scala:113)
at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:82)
场景2:类似上面场景
现在dev上3个节点配置 borker 0 1 2:
offsets.topic.replication.factor=3
min.insync.replicas=1
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=1
default.replication.factor=3
同时断开了broker 0 和 2的网络,然后启动kafka client,此时kafka client端所在的网络分区内只能连接到 borker 1,同样出现了场景1中的情形,
可以正常subscribe topic并且kafka server端borker 1正常进行了rebalance,但是接下来client端在onPartitionAssigned内进一步访问kafka获取一些快照数据时产生超时错误
不过跟场景1不太一样的是,后来broker 2恢复了,并且broker 1成功连接了broker 2(以及其同一机器上的zookeeper),只不过过程中fetch的时候出错
虽然 18:09:48,061 连接上了,但是后面fetch io错误
[2022-03-12 18:10:07,087] INFO Opening socket connection to server vm-v01/x.x.x.x:2181. Will not attempt to authenticate using SASL (unknown error) (org.apache.zookeeper.ClientCnxn)
[2022-03-12 18:10:07,089] INFO Socket connection established to vm-v01/x.x.x.x:2181, initiating session (org.apache.zookeeper.ClientCnxn)
[2022-03-12 18:10:07,093] INFO Session establishment complete on server vm-v01/x.x.x.x:2181, sessionid = 0x27b6bf74fac000e, negotiated timeout = 6000 (org.apache.zookeeper.ClientCnxn)
[2022-03-12 18:10:07,093] INFO [ZooKeeperClient] Connected. (kafka.zookeeper.ZooKeeperClient)
注意到关键词:Shrinking
[2022-03-12 18:10:07,139] INFO [Partition __consumer_offsets-43 broker=3] Shrinking ISR from 3,1,4 to 3. Leader: (highWatermark: 115, endOffset: 120). Out of sync replicas: (brokerId: 1, endOffset: 115) (brokerId: 4, endOffset: 116). (kafka.cluster.Partition)
紧接着又expand?
[2022-03-12 18:10:07,381] INFO [Partition __consumer_offsets-43 broker=3] Expanding ISR from 3 to 3,4 (kafka.cluster.Partition)
但是fetch错误
[2022-03-12 18:10:07,471] INFO [ReplicaFetcher replicaId=3, leaderId=4, fetcherId=0] Shutting down (kafka.server.ReplicaFetcherThread)
[2022-03-12 18:10:07,471] INFO [ReplicaFetcher replicaId=3, leaderId=4, fetcherId=0]
Error sending fetch request (sessionId=346995240, epoch=1677663) to node 4:
java.io.IOException: Client was shutdown before response was read. (org.apache.kafka.clients.FetchSessionHandler)
[2022-03-12 18:10:07,471] INFO [ReplicaFetcher replicaId=3, leaderId=4, fetcherId=0] Stopped (kafka.server.ReplicaFetcherThread)
[2022-03-12 18:10:07,471] INFO [ReplicaFetcher replicaId=3, leaderId=4, fetcherId=0] Shutdown completed (kafka.server.ReplicaFetcherThread)
可见网络还是不稳定或者broker 1 和 2之间的通信同步出现错误
场景3:
既然前面两个场景中都是有两个节点不正常,再测试一次:
broker 0 1 2,断网broker 2(以及其服务器上面的zookeeper节点)
同样启动kafka-client,仍然跟前面类似,client端能够启动并且订阅topic,只不过恢复的时候(onPartitionAssign内部进一步访问kafka读取快照数据)抛错;
但是再试了几次发现这个错误有点意思,刚开始的时候,每次都会随机成功某几个partition,直到2小时后才稳定的成功(后面再测试几轮实际是随机成功和失败)
程序的main consumer subscribe topic基本都没有问题 (中间只有一次出现了场景5中的无法启动的问题),
然后onPartitionAssign内部进一步访问kafka读取快照数据的时候不稳定
读取快照自然用的不是subscribe而是
TopicPartition topicPartition = new TopicPartition(config.getSnapshotTopic(), partition);
Consumer<String, Snapshot> consumer = createConsumer(partition);
long lastOffset = consumer.endOffsets(Collections.singleton(topicPartition)).get(topicPartition) - 2;
if (lastOffset < 0) {
lastOffset = 0;
}
consumer.assign(Collections.singleton(topicPartition));
consumer.seek(topicPartition, lastOffset);
ConsumerRecords<String, Snapshot> records = consumer.poll(Duration.ofMillis(10_000L));
Snapshot snapshot = null;
for (ConsumerRecord<String, Snapshot> record : records) {
snapshot = record.value();
}
consumer.close();
通过加日志,发现错误都是发生在endOffsets这里,默认的timeout应该是30s, 这个问题就是读取metadata出现问题, 最终反复测试确定根源: 如果某个broker节点是直接杀死,只要该节点网络通的,client端读取metadata就不会超时, 但是如果某个broker节点所在服务器网络断开,client端的kafka cluster配置中仍有该broker的信息,那么client端读取metadata的时候可能会尝试连接有问题的节点由于网络重试造成超时
所以解决方案:
1)修改 consumer.properties.bootstrap.servers,移除坏节点 2)修改api调用,增加timeout时间到5分钟(实测超时在2分钟左右):consumer.endOffsets(Collections.singleton(topicPartition),Duration.ofMillis(300000)).get(topicPartition) 3)修改配置 consumer.properties.request.timeout.ms=300000
场景4:
1. broker 0 1 2 都启动
2.停 broker 2,启动kafka client端服务正常,expected
3.停broker 0,无法启动kafka client端服务,expected
4.恢复broker2,无法启动kafka client端服务,报错,unexpected
client端仍然是报错跟3一样,[Consumer clientId=consumer-2, groupId=TEST-SZL] 1 partitions have leader brokers without a matching listener, including [T-TRADE-1],
kafka服务端报错:
[2022-03-16 10:58:02,825] TRACE [Controller id=1] Leader imbalance ratio for broker 2 is 0.1282051282051282 (kafka.controller.KafkaController)
[2022-03-16 10:58:02,825] INFO [Controller id=1] Starting preferred replica leader election for partitions T-TEST-SNP-2,T-TEST-0,T-TRADE-SNP-2,T-TRADE-1,T-CAPTURE-1 (kafka.controller.KafkaController)
[2022-03-16 10:58:02,836] ERROR [Controller id=1] Error completing preferred replica leader election for partition T-TEST-0 (kafka.controller.KafkaController)
kafka.common.StateChangeFailedException: Failed to elect leader for partition T-TEST-0 under strategy PreferredReplicaPartitionLeaderElectionStrategy
at kafka.controller.PartitionStateMachine.$anonfun$doElectLeaderForPartitions$9(PartitionStateMachine.scala:390)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at kafka.controller.PartitionStateMachine.doElectLeaderForPartitions(PartitionStateMachine.scala:388)
at kafka.controller.PartitionStateMachine.electLeaderForPartitions(PartitionStateMachine.scala:315)
at kafka.controller.PartitionStateMachine.doHandleStateChanges(PartitionStateMachine.scala:225)
at kafka.controller.PartitionStateMachine.handleStateChanges(PartitionStateMachine.scala:141)
at kafka.controller.KafkaController.kafka$controller$KafkaController$$onPreferredReplicaElection(KafkaController.scala:649)
at kafka.controller.KafkaController.$anonfun$checkAndTriggerAutoLeaderRebalance$6(KafkaController.scala:1008)
at scala.collection.immutable.Map$Map3.foreach(Map.scala:195)
at kafka.controller.KafkaController.kafka$controller$KafkaController$$checkAndTriggerAutoLeaderRebalance(KafkaController.scala:989)
at kafka.controller.KafkaController$AutoPreferredReplicaLeaderElection$.process(KafkaController.scala:1020)
at kafka.controller.ControllerEventManager$ControllerEventThread.$anonfun$doWork$1(ControllerEventManager.scala:94)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at kafka.metrics.KafkaTimer.time(KafkaTimer.scala:31)
at kafka.controller.ControllerEventManager$ControllerEventThread.doWork(ControllerEventManager.scala:94)
at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:82)
[2022-03-16 10:58:02,837] WARN [Controller id=1] Partition T-TEST-0 failed to complete preferred replica leader election to 2. Leader is still 0 (kafka.controller.KafkaController)
原因分析:应该是由于操作频率过快,启停kafka borker的时候没有给足时间做failover,可见kafka服务本身可以看到他的健壮性有问题了,居然无法选举新leader
重新设计连续测试场景:
-----------------------------------
--- borker 0 1 2 alive
-----------------------------------
start kafka client
test kafka client
-----------------------------------
--- kill 2(both zookeeper&kafka), borker 0 1 alive
-----------------------------------
test kafka client
restart kafka client
test kafka client
-----------------------------------
--- resume 2, borker 0 1 2 alive
-----------------------------------
test kafka client
restart kafka client
test kafka client
-----------------------------------
--- shutdown network for borker 2, borker 0 1 alive
-----------------------------------
test kafka client
restart kafka client
test kafka client
场景5:跟前面类似,只不过这次是kafka客户端启停太快
断开 borker 2网络, borker 0 1 alive
第一次重启kafka client端(stop then start)失败!
2022-03-16 17:14:21.728 INFO 370GG [main] o.a.k.c.u.AppInfoParser$AppInfo : Kafka version: 2.2.0
2022-03-16 17:14:21.728 INFO 370GG [main] o.a.k.c.u.AppInfoParser$AppInfo : Kafka commitId: 05fcfde8f69b0349
2022-03-16 17:15:21.737 INFO 370GG [main] ConditionEvaluationReportLoggingListener :
Error starting ApplicationContext. To display the conditions report re-run your application with 'debug' enabled.
2022-03-16 17:15:21.767 ERROR 370GG [main] o.s.b.SpringApplication : Application run failed
org.apache.kafka.common.errors.TimeoutException: Timeout expired while fetching topic metadata
2022-03-16 17:15:21.808 INFO 370GG [main] o.s.s.c.ExecutorConfigurationSupport : Shutting down ExecutorService 'applicationTaskExecutor'
2022-03-16 17:15:21.809 INFO 370GG [main] o.a.k.c.p.KafkaProducer : [Producer clientId=producer-1] Closing the Kafka producer with timeoutMillis = 9223372036854775807 ms.
2022-03-16 17:15:21.816 INFO 370GG [main] c.a.d.p.DruidDataSource : {dataSource-1} closing ...
2022-03-16 17:15:21.831 INFO 370GG [main] c.a.d.p.DruidDataSource : {dataSource-1} closed
possible reason:
停掉 kafka client大概是在:
2022-03-16 17:13:51.918 ^[[32m INFO^[[m ^[[35m30256GG^[[m [QFJ Timer] ^[[36mc.q.c.f.f.s.AbstractApplication^[[m : fix server toAdmin: [8=FIX.4.4|9=60|35=0|34=683|49=EXEC|52=20220316-09:13:51.918|56=EXCHANGE_FS|10=167|]
然后很快启动了 kafka client:
2022-03-16 17:14:17.944 ^[[32m INFO^[[m ^[[35m370GG^[[m [main] ^[[36mo.s.b.StartupInfoLogger^[[m : Starting TradeFrontMain v1.1.0-SNAPSHOT using Java 1.8.0_40 on XXXX with PID 370 (/lyhistory/kafka client.jar started by xxx in /lyhistory)
2022-03-16 17:14:17.955 ^[[32mDEBUG^[[m ^[[35m370GG^[[m [main] ^[[36mo.s.b.StartupInfoLogger^[[m : Running with Spring Boot v2.4.5, Spring v5.3.6
2022-03-16 17:14:17.956 ^[[32m INFO^[[m ^[[35m370GG^[[m [main] ^[[36mo.s.b.SpringApplication^[[m : The following profiles are active: dev
2022-03-16 17:14:19.821 ^[[32m INFO^[[m ^[[35m370GG^[[m [main] ^[[36mo.s.b.w.e.t.TomcatWebServer^[[m : Tomcat initialized with port(s): 10102 (http)
2022-03-16 17:14:19.835 ^[[32m INFO^[[m ^[[35m370GG^[[m [main] ^[[36mo.a.j.l.DirectJDKLog^[[m : Initializing ProtocolHandler ["http-nio-10102"]
2022-03-16 17:14:19.836 ^[[32m INFO^[[m ^[[35m370GG^[[m [main] ^[[36mo.a.j.l.DirectJDKLog^[[m : Starting service [Tomcat]
2022-03-16 17:14:19.836 ^[[32m INFO^[[m ^[[35m370GG^[[m [main] ^[[36mo.a.j.l.DirectJDKLog^[[m : Starting Servlet engine: [Apache Tomcat/9.0.45]
对应的group coordinator在broker 1上:
[2022-03-16 17:14:07,063] INFO [GroupCoordinator 1]: Member consumer-2-f852e86d-7db8-4943-b378-097fe08415f8 in group TEST-SZL has failed, removing it from the group (kafka.coordinator.group.GroupCoordinator)
[2022-03-16 17:14:07,064] INFO [GroupCoordinator 1]: Preparing to rebalance group TEST-SZL in state PreparingRebalance with old generation 1 (__consumer_offsets-43) (reason: removing member consumer-2-f852e86d-7db8-4943-b378-097fe08415f8 on heartbeat expiration) (kafka.coordinator.group.GroupCoordinator)
[2022-03-16 17:14:07,065] INFO [GroupCoordinator 1]: Group TEST-SZL with generation 2 is now empty (__consumer_offsets-43) (kafka.coordinator.group.GroupCoordinator)
[2022-03-16 17:15:54,415] INFO [GroupMetadataManager brokerId=1] Group TEST-SZL transitioned to Dead in generation 2 (kafka.coordinator.group.GroupMetadataManager)
可以看到在kafka client启动的时候,刚好是group coordinator在处理remove之前的kafka client consumer的时候,所以造成读取offset时间超时!
经验总结:
1. 遇到网络故障,即使自动恢复了,也最好要启停一下zookeeper和kafka
2. 启停kafka服务操作时不要动作太快
3. 启停kafka客户端操作时也不要动作太快
这些异常情况可能也是kafka最终抛弃zookeeper的原因!
造成kafka client端程序poll自己维护的offset topic出现问题
结合前面 4.3.2 不依赖interal offset,自己维护offset exactly-once public ConsumerRecords<K,V> poll(java.time.Duration timeout)
This method returns immediately if there are records available. Otherwise, it will await the passed timeout. If the timeout expires, an empty record set will be returned.
consumer.seek(topicPartition, snpoffset);
ConsumerRecords<String, SimpleSnapshot> records = consumer.poll(Duration.ofMillis(10_000L));
if(records!=null) {
System.out.println("records not null, count=" + String.valueOf(records.count()));
}
和前面情况类似,经过实际测试,发现这个10s的设置,指定的offset有时候能返回正确的message,有时候返回empty record!, 然后改成 30000 即5分钟则没有问题
kafka consumer.seek 之后立即 poll 可能拉不到消息
造成kafka client端程序读取 metadata 超过默认 1分钟 抛错
public java.util.List
TimeoutException - if the offset metadata could not be fetched before the amount of time allocated by default.api.timeout.ms expires.
This member will leave the group because consumer poll timeout has expired
[36m.c.i.AbstractCoordinator$HeartbeatThread^[[m : [Consumer clientId=consumer-1, groupId=TEST-SZL] This member will leave the group because consumer poll timeout has expired. This means the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time processing messages. You can address this either by increasing max.poll.interval.ms or by reducing the maximum size of batches returned in poll() with max.poll.records. [[36mo.a.k.c.c.i.AbstractCoordinator^[[m : [ Consumer clientId=consumer-1, groupId=TEST-SZL] Member consumer-1-7f40d109-cd66-4554-82a9-376f1922c1b5 sending LeaveGroup request to coordinator x.x.x.x:9092 (id: 2147483647 rack: null)
分析: 首先报错的意思是程序处理一批kafka消息(max.poll.records 默认500条)的时间超过了max.poll.interval.ms,所以直观的看来就是降低max.poll.records或者提高max.poll.interval.ms,不过我们这里的场景并没有这么简单,因为我们出错的时候还没有开始获取并处理kafka消息,而是第一次poll触发的rebalance的过程中出现的错误;
该程序的主要逻辑:
private void start(ApplicationContext context) {
if (managerThread == null) {
workerManager = new SimpleWorkerManager(workContext);
managerThread = new Thread(workerManager::start);
managerThread.setDaemon(true);
managerThread.setName(config.getTaskType() + "-MANAGER");
managerThread.start();
}
}
SimpleWorkerManager的构造方法中调用了kafka的消息订阅
this.kafkaConsumer.subscribe(Collections.singleton(context.getConfig().getTaskTopic()), new SimpleWorkBalancer(context.getRestorer(), this::removeWorker, this::addWorker));
然后strat()方法是去poll消息
ConsumerRecords<String, Info> records = kafkaConsumer.poll(pollDuration);
After subscribing to a set of topics, the consumer will automatically join the group when poll(Duration) is invoked.
所以问题出在第一次poll引起的rebalance的处理时间过长,超过了max.poll.interval.ms,然后我们查一下这个配置:
The maximum delay between invocations of poll() when using consumer group management. This places an upper bound on the amount of time that the consumer can be idle before fetching more records. If poll() is not called before expiration of this timeout, then the consumer is considered failed and the group will rebalance in order to reassign the partitions to another member. For consumers using a non-null group.instance.id which reach this timeout, partitions will not be immediately reassigned. Instead, the consumer will stop sending heartbeats and partitions will be reassigned after expiration of session.timeout.ms. This mirrors the behavior of a static consumer which has shutdown. Type: int Default: 300000 (5 minutes) Valid Values: [1,…] Importance: medium
此时我想到了前面的另外一个bug做的修复 request.timeout.ms 我设置成了5分钟,然后应该是在reblance的过程中,我们程序的逻辑会去从kafka中恢复我们自己管理的快照,但是由于所有topic已经删除,所以读取的时候可能会等待5分钟,然后 max.poll.interval.ms 默认也是5分钟,自然就timeout了,所以修复办法是延长 max.poll.interval.ms到更长的时间
注意:
Also as part of KIP-266, the default value of request.timeout.ms has been changed to 30 seconds. The previous value was a little higher than 5 minutes to account for maximum time that a rebalance would take. Now we treat the JoinGroup request in the rebalance as a special case and use a value derived from max.poll.interval.ms for the request timeout. All other request types use the timeout defined by request.timeout.ms Notable changes in 0.10.2.1 The default values for two configurations of the StreamsConfig class were changed to improve the resiliency of Kafka Streams applications. The internal Kafka Streams producer retries default value was changed from 0 to 10. The internal Kafka Streams consumer max.poll.interval.ms default value was changed from 300000 to Integer.MAX_VALUE. The new Java Consumer now supports heartbeating from a background thread. There is a new configuration max.poll.interval.ms which controls the maximum time between poll invocations before the consumer will proactively leave the group (5 minutes by default). The value of the configuration request.timeout.ms (default to 30 seconds) must always be smaller than max.poll.interval.ms(default to 5 minutes), since that is the maximum time that a JoinGroup request can block on the server while the consumer is rebalance. Finally, the default value of session.timeout.ms has been adjusted down to 10 seconds, and the default value of max.poll.records has been changed to 500.
KIP-568: Explicit rebalance triggering on the Consumer
TIMEOUTS IN KAFKA CLIENTS AND KAFKA STREAMS
| [nothing to guarantee=>at-most-once | at-least-once => exactly-once](https://kafka.apache.org/documentation/#design) |