回目录 《编解码》
1.Key points
Standard vs implementation Compatible vs non-compatible Space saving encoding/multi-bytes vs performance better/wide chars vs char Code points vs characters(numbers/character in the languages) Binary storage vs hex representation
1.1 Essential about encoding issues
Computers only deal in numbers and not letters, so it’s important that all computers agree on which numbers represent which letters English&non-English letters/numbers/punctuation mark ===> 0101010 0s1s /binary numbers ==> called code point in unicode Everything is stored in hard drive and load in memory in binary format, but display in hex format for human readability, And some apps or cli tools, they will always try to display the loaded binary data in their default or set encoding(or decoding accurately) format, if the ‘display encoding’ is the same or compatible with the encoding used to store them, the characters will be shown in the correct/original character, but if the encoding not compatible, there will be 2 cases:
a) Find the ‘wrong mapping’ (because default encoding standard map the same 0s1s to different character, if the range covered, it will show something else b) But when it’s out of range, then it failed to translate the code points , it will show its ‘original binary’ in hex format
Wrong question, not unicode search but ‘code points’ ——————————————————— https://superuser.com/questions/985570/how-do-i-find-this-characterby-unicode-search-in-notepad-%EF%BB%81-ufec1-and-only https://stackoverflow.com/questions/39258979/notepad-view-hidden-characters
In computing, a code page is a character encoding and as such it is a specific association of a set of printable characters and control characters with unique numbers.
1.2 Unicode standards and the implementations
Unicode defines or standardize code points, but it has more than one code pages https://www.ibm.com/developerworks/library/ws-codepages/index.html
Unicode is a standard, not an implementation, there are many implementations: UCS** & UTF** https://stackoverflow.com/questions/643694/what-is-the-difference-between-utf-8-and-unicode
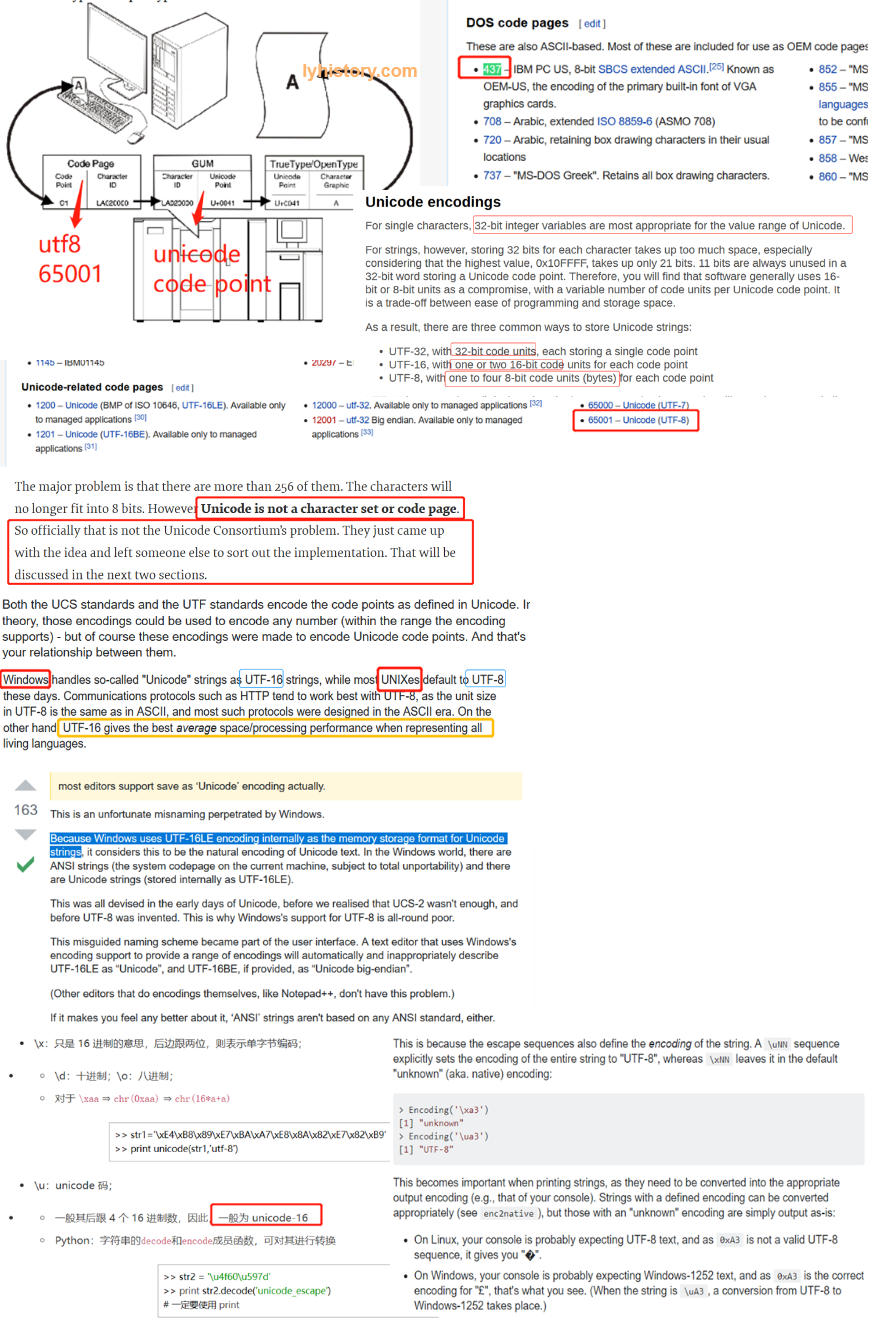
Implementations: 一般宽的performance比较好,因为多字节需要多层查询,另外在做substring切割的时候需要转成宽字节 ● 最通用的UTF-8,包含了(全世界几乎)所有的字符 ● 双字节UTF-16/UCS-2 LE(Little Endian) ● 简体中文:GB18030 > GBK > GB2312 ● 繁体中文:Big5 宽字符widechar(16bit,unicode/utf-16),窄字符(8bit,asicII),多字符multibyte(utf-8,gb2312) MultiByteToWideChar https://www.cnblogs.com/lidabo/p/3317364.html
2. 编码历史
2.1.ASCII
7bits
in the 1960s the American Standards Association created a 7-bit encoding called the American Standard Code for Information Interchange (ASCII)
Tables http://www.asciitable.com/
2.2 Code pages or charsets
8bits
ASCII=>ANSI
http://www.differencebetween.net/technology/web-applications/difference-between-ansi-and-ascii/
https://en.wikipedia.org/wiki/Code_page
Teleprinters and stock tickers were quite happy sending 7 bits of information to each other. But the new fangled microprocessors of the 1970s preferred to work with powers of 2. They could process 8 bits at a time and so used 8 bits (aka a byte or octet) to store each character, giving 256 possible values.
The PHP function chr does a similar thing to Javascript’s String.fromCharCode, when the client side/browser request for this php page, php interpreter will for example interprete chr(224) and embeds the number 224 into the Web page reponse before sending it to the browser.
2.3.Summary Circa 1990
This is the situation in about 1990. Documents can be written, saved and exchanged in many languages, but you need to know which character set they use. There is also no easy way to use two or more non-English alphabets in the same document, and alphabets with more than 256 characters like Chinese and Japanese have to use entirely different systems, for example gd2312
2.4.Unicode To The Rescue
Starting in the late 1980s, a new standard was proposed – one that would assign a unique number (officially known as a code point) to every letter in every language, one that would have way more than 256 slots. It was called Unicode. It is now in version 6.1 and consists of over 110,000 code points. If you have a few hours to spare you can watch them all whiz past. The first 128 Unicode code points are the same as ASCII. The range 128-255 contains currency symbols and other common signs and accented characters (aka characters with diacritical marks), and much of it is borrowed ISO-8859-1. After 256 there are many more accented characters. After 880 it gets into Greek letters, then Cyrillic, Hebrew, Arabic, Indic scripts, and Thai. Chinese, Japanese and Korean start from 11904 with many others in between. The major problem is that there are more than 256 of them. The characters will no longer fit into 8 bits. However Unicode is not a character set or code page. So officially that is not the Unicode Consortium’s problem. They just came up with the idea and left someone else to sort out the implementation. computers have advanced since the 1970s. An 8 bit microprocessor is a bit out of date. New computers now have 64 bit processors, A lot of software is written in C or C++, which supports a “wide character”. This is a 32 bit character called wchar_t. It is an extension of C’s 8 bit char type. Internally, modern Web browsers use these wide characters (or something similar) and can theoretically quite happily deal with over 4 billion distinct characters. This is plenty for Unicode. So - internally, modern Web browers use Unicode.
2.5.UTF-8 To The Rescue
Universal Character Set Transformation Format 8 bit So if browsers can deal with Unicode in 32 bit characters, where is the problem? The problem is in the sending and receiving, and reading and writing of characters.
The problem remains because:
- A lot of existing software and protocols send/receive and read/write 8 bit characters
- Using 32 bits to send/store English text would quadruple the amount of bandwidth/space required UTF-8 is a clever. It works a bit like the Shift key on your keyboard. Normally when you press the H on your keyboard a lower case “h” appears on the screen. But if you press Shift first, a capital H will appear.
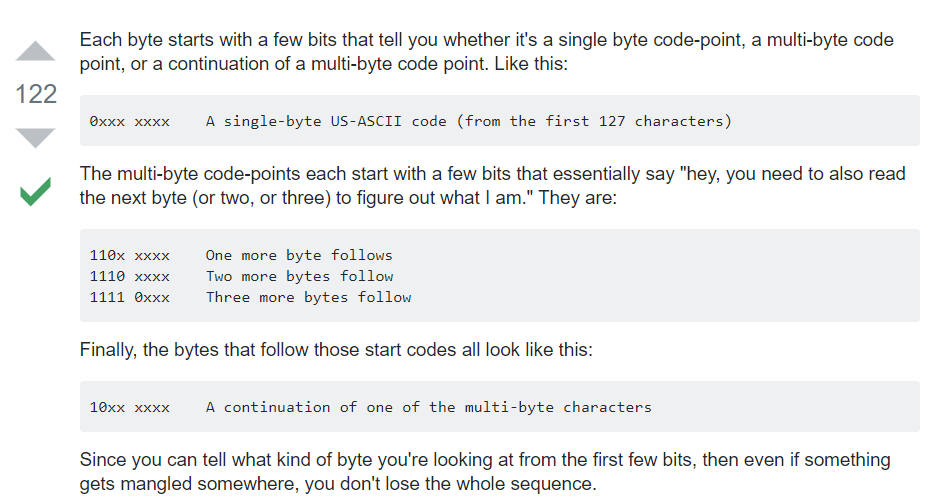
UTF-8 treats numbers 0-127 as ASCII, 192-247 as Shift keys, and 128-192 as the key to be shifted. For instance, characters 208 and 209 shift you into the Cyrillic range. 208 followed by 175 is character 1071, the Cyrillic Я. The exact calculation is (208%32)*64 + (175%64) = 1071. Characters 224-239 are like a double shift. 226 followed by 190 and then 128 is character 12160: ⾀. 240 and over is a triple shift.
UTF-8 is therefore a multi-byte variable-width encoding. Multi-byte because a single character like Я takes more than one byte to specify it. Variable-width because some characters like H take only 1 byte and some up to 4.
Best of all it is backward compatible with ASCII. Unlike some of the other proposed solutions, any document written only in ASCII, using only characters 0-127, is perfectly valid UTF-8 as well - which saves bandwidth and hassle.
PHP embeds the 6 numbers mentioned above into an HTML page: 72, 208, 175, 226, 190, 128. The browser interprets those numbers as UTF-8, and internally converts them into Unicode code points. Then Javascript outputs the Unicode values.
2.6.其他编码
Usually when we talk about all the above utf-8 gb2312, normally we don’t talk about decode, we only say encoding in such ** format, because the decode process is automatically done: Nodepad++ display human readable characters for files stored in binary format on the disk; Memory viewer or traffic viewer display hex format for the binary data loaded or transferred; Web server interprete responding asp/php files requested and encoding the response using format defined in headers, and then browser receive the http response and decode it into html language file(human readable, inspect the source file) and then render it to the real web pages. And for the other kind of encoding algorithm used for higher level, for example URL ENCODE/HTML ENCODE/HASH/BINARY TRANSFER ENCODE(BASE64), we have to decode it manually or programmatically.
Language level encode decode
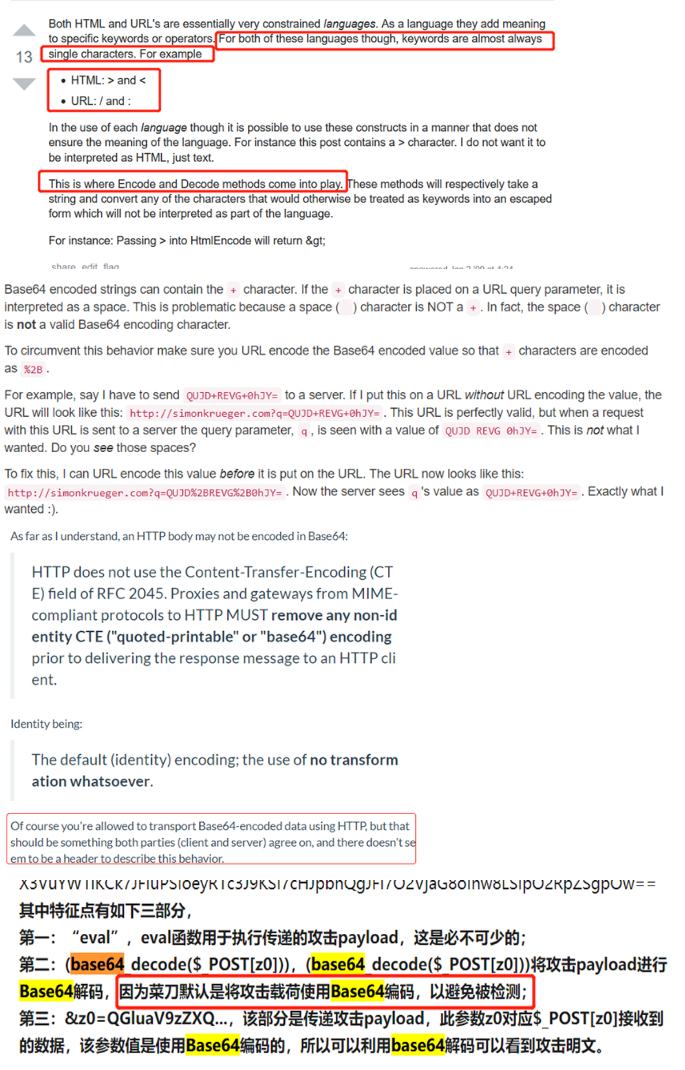
Url编码 base64 Http请求中的编码,先base64再urlencode(因为base64包括+/,这两个符号在url中都有特殊含义) https://www.simonkrueger.com/2014/07/10/always-url-encode-your-base64-encoded-query-parameters.html
base64 将二进制转成base64(2^6)数字加字符表示,将原有二进制按照每6位对应到base64一个字符或数字; 一般用于加密后的数据(主流的加密算法都是面向二进制的),或者有时候需要将二进制放入json字符串内传输,需要先base64一下,否则直接放进去会乱码;
https://www.imperva.com/blog/the-catch-22-of-base64-attacker-dilemma-from-a-defender-point-of-view/
Btc use base58

Application level encode decode
Md5 sha256
Keccak256 ecrecover
Base64
UTF-8 is a text encoding - a way of encoding text as binary data. Base64 is in some ways the opposite - it’s a way of encoding arbitrary binary data as ASCII text. when you hae some binary data that you want to ship across a network, you generally don’t do it by just streaming the bits and bytes over the wire in a raw format. why? beause some media are made for streaming text. You never know – some protocols may interpret your binary data as control characters(like a modem), or your binary data could be screwed up because the underlying protocol might think that you’e entered a speical character combination (like how FTP translates line endings). so to get around this, people encode the binary data into characters.Base64 is one of these types of encodings.
3.characters garbled / garbled text
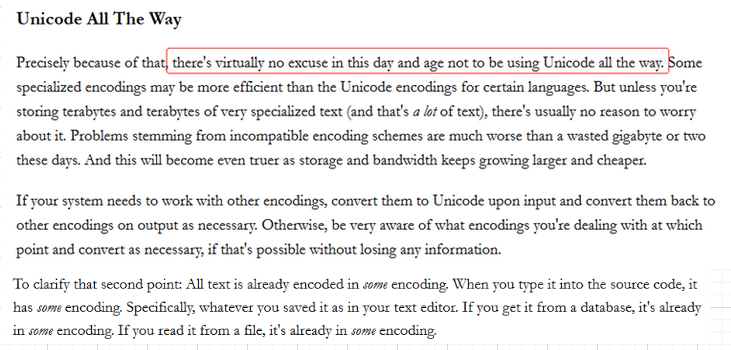
best practice: unicode all the way!
3.1 PHP
multi-byte aware fashion

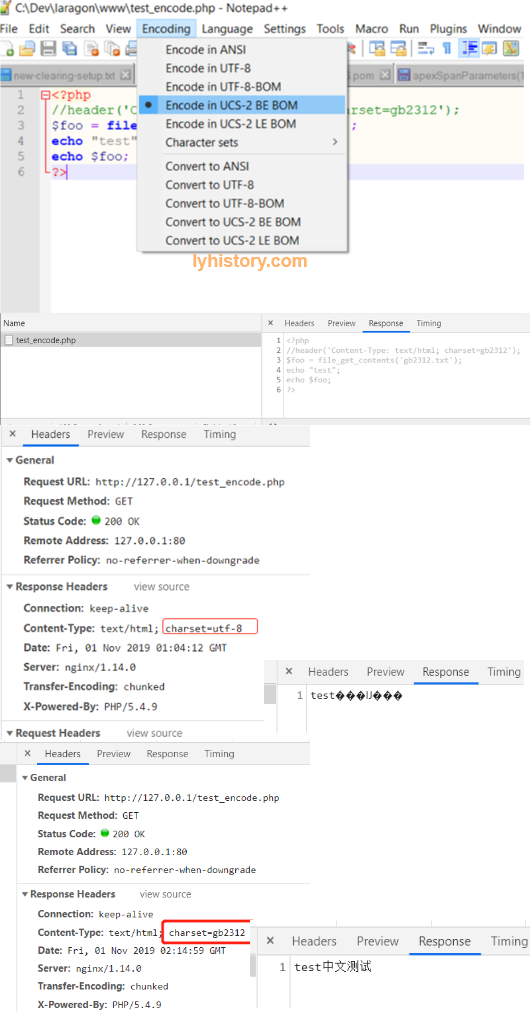
下面做一个测试 test_encode.php
<?php
//header('Content-Type: text/html; charset=gb2312');
$foo = file_get_contents('gb2312.txt');
echo "test";
echo $foo;
?>
gb2312.txt内容是:中文测试 Both files are stored in binary bytes, all 0s 1s, only different is the encoding of the file itself. Php doesn’t give a shift of what encoding gb2312.txt and other files it operates on or the database it operates on. PHP Interpreter only cares about the php file encoding itself, as long as it’s utf-8 compatible, it can interpret the php grammar and translate into html response back to the client, and the html response encoding is subject to the response header setting(default utf-8).
如果php文件选择非utf-8 compatible的编码,则解释器无法解释,直接返回浏览器整个php内容,浏览器无法识别所以白页; 如果php文件编码选择utf-8或utf-8兼容,但是其读取的gb2312.txt的编码跟http请求的编码(header)不一致,则乱码; 如果php文件编码选择utf-8或utf-8兼容,而且读取的gb2312.txt跟http请求头部编码一致则完美无乱码;
3.2 Python
Python3 参考小象爬虫课程的讲解
3.3 bash/terminal
Windows chcp(change code page) https://docs.microsoft.com/en-us/windows-server/administration/windows-commands/chcp 437 English 65001 UTF-8
https://www.cnblogs.com/jinhengyu/p/7516413.html file -bi in.txt
BASH Fix Display and Console Garbage and Gibberish on a Linux / Unix / macOS https://www.cyberciti.biz/tips/bash-fix-the-display.html “\033c” https://en.wikipedia.org/wiki/ANSI_escape_code
3.4 Java redisTemplate default jdkserializer
很多\xac这样的乱码

This looks like binary data held in a Python bytes object. Loosely, bytes that map to printable ASCII characters are presented as those ASCII characters. All other bytes are encoded \x** where ** is the hex representation of the byte. https://stackoverflow.com/questions/26802581/can-anyone-identify-this-encoding https://www.cnblogs.com/chen-lhx/p/7559834.html
https://www.smashingmagazine.com/2012/06/all-about-unicode-utf8-character-sets/ As long as everybody is speaking UTF-8, this should all work swimmingly. If they aren’t, then characters can get mangled.
?#web site example: user comment on a blog post
- A Web page displays a comment form
- The user types a comment and submits.
- The comment is sent back to the server and saved in a database.
- The comment is later retrieved from the database and displayed on a Web page Refer: http://kunststube.net/encoding/ https://www.joelonsoftware.com/2003/10/08/the-absolute-minimum-every-software-developer-absolutely-positively-must-know-about-unicode-and-character-sets-no-excuses/