基本概念
步骤一:编译器:
首先需要编译器将高级的.java程序文件编译成.class类文件,内容即byte code字节码指令/jvm指令(这段.class文件是一段包含着虚拟机指令、程序和数据片段的二进制文件,即字节码,为什么叫字节码?因为这种类型的代码以一个字节8bit为最小单位储存), 然后聚合类文件、相关元数据和资源到同一个文件,以.jar为扩展名
java代码编译-->java class
字节码引擎对应jvm指令:Java bytecode instruction listings
步骤二:解释器:
字节码经过JVM(解释器)的处理后生成电脑可以直接执行的机器码(JDK安装的JVM翻译成对应操作系统的机器码),至此java程序才能得以正确运行。 JVM,java虚拟机,只是给字节码byte code提供解释翻译加载运行的一个工具(通常编程打包的程序都是直接到机器码,比如exe文件是windows的机器码可执行文件,Java语言设计只默认编译成中间语言byte code字节码,不编译成最终的机器码,然后jvm就会去解释执行),实际上不只是java语言,任何语言只要能转成bytecode 字节码都可以交由jvm加载,jvm会找到主程序并根据当前的操作系统解释成机器码运行;
Tips:
工具hsdis打印汇编指令;
反过来:
javap java.class 可以把汇编指令/机器码反编译成jvm指令/字节码指令;
JVM 的线程是用户态线程还是内核态线程?
【解析】 JVM 自己本身有一个线程模型。在 JDK 1.1 的时候,JVM 自己管理用户级线程。这样做缺点非常明显,操作系统只调度内核级线程,用户级线程相当于基于操作系统分配到进程主线程的时间片,再次拆分,因此无法利用多核特性。
为了解决这个问题,后来 Java 改用线程映射模型,因此,需要操作系统支持。在 Windows 上是 1 对 1 的模型,在 Linux 上是 n 对 m 的模型。顺便说一句,Linux 的PThreadAPI 创建的是用户级线程,如果 Linux 要创建内核级线程有KThreadAPI。映射关系是操作系统自动完成的,用户不需要管。
在JVM中运行的线程与Linux内核之间的关系是一个复杂但重要的概念。首先,需要澄清的是,JVM管理的线程(即Java线程)与操作系统(如Linux)的线程之间并不是完全隔离的,它们之间存在紧密的交互。
JVM线程与操作系统线程的关系 一对一模型:
在许多现代JVM实现中,特别是HotSpot JVM,Java线程与操作系统的本地线程(在Linux中通常是轻量级进程)之间存在一对一的映射关系。这意味着每当在Java中创建一个新线程时,JVM都会请求操作系统创建一个新的本地线程12。 在这种模型下,Java线程的调度、创建、销毁以及上下文切换等操作都是由操作系统内核来管理的。JVM本身并不直接进行这些操作,而是依赖于操作系统提供的API和机制12。 线程创建与销毁:
当Java程序创建一个新线程时,JVM会调用操作系统的API(如Linux中的pthread_create)来创建一个新的本地线程。这个过程中,操作系统会为线程分配必要的资源,如内存和堆栈空间12。 类似地,当Java线程结束时,JVM会请求操作系统销毁相应的本地线程,并回收其占用的资源3。 线程调度:
线程的调度(即决定哪个线程在何时运行)完全由操作系统内核负责。Java线程的优先级设置可能会反映为底层操作系统线程的优先级设置,但这不是一个严格的一一对应关系4。 在Java中,线程的调度通常是基于抢占式的,这意味着优先级更高的线程更可能被操作系统选中执行,但它并不能保证一定会被执行3。 上下文切换:
当操作系统需要从一个线程切换到另一个线程时(例如,由于时间片用完、等待I/O操作等),它会保存当前线程的状态(如寄存器值和程序计数器值),并加载另一个线程的状态3。 这个过程称为上下文切换,它涉及到用户态和内核态之间的切换,因此可能会消耗一定的处理器时间3。 同步与互斥:
Java提供了自己的同步机制(如synchronized关键字和java.util.concurrent包中的高级同步结构),但这些机制在底层通常是由操作系统的线程同步机制实现的4。 例如,Java中的锁(如ReentrantLock)在底层可能使用操作系统的互斥量(Mutex)来实现。 总结 因此,可以说JVM中的线程并不是完全由JVM管理的,而是与操作系统线程紧密相关。JVM依赖于操作系统提供的线程管理机制来实现Java线程的创建、销毁、调度和同步等操作。这种关系使得Java程序能够充分利用操作系统的多线程特性,同时也带来了与操作系统交互的开销。
需要注意的是,虽然JVM和操作系统之间的交互是不可避免的,但JVM通过其高级抽象和优化机制(如JIT编译、垃圾回收等)为Java程序提供了跨平台的一致性和高性能。因此,在编写Java程序时,开发者通常不需要关心底层操作系统线程的具体实现细节。
线程阻塞 当Java线程执行到某个阻塞点时(如执行了阻塞的I/O操作、调用了线程的sleep方法、等待某个条件变量的满足等),JVM会向操作系统发出请求,将当前线程的状态从运行状态(RUNNABLE)切换到阻塞状态(BLOCKED或WAITING等)。这个过程中,JVM会调用操作系统的API来实现线程的阻塞。
操作系统层面:在操作系统层面,线程的状态变化是通过修改线程的状态标志(如Linux中的task_struct结构体中的状态字段)来实现的。当线程进入阻塞状态时,操作系统会将其从运行队列中移除,并可能将其添加到等待队列中(对于需要等待某个事件或资源的线程)。此时,线程将不再参与CPU的调度,直到被唤醒1。
内核态与用户态切换:线程的阻塞和唤醒过程通常涉及用户态和内核态之间的切换。用户态是用户程序运行的环境,而内核态是操作系统内核运行的环境。当线程需要执行阻塞操作时,JVM会发起系统调用(如Linux中的read系统调用),这会导致CPU从用户态切换到内核态,执行相应的内核代码来处理阻塞请求。内核代码会使用当前进程的内核栈来保存上下文信息,并在处理完成后将CPU切换回用户态2。
线程唤醒 当线程被唤醒时(如等待的I/O操作完成、调用了线程的interrupt方法、其他线程调用了notify/notifyAll方法等),操作系统会接收到相应的通知,并将线程从等待队列中移除,重新添加到运行队列中。此时,线程将有机会再次参与CPU的调度,并执行其后续任务。
唤醒机制:唤醒机制通常依赖于操作系统的中断机制和事件通知机制。例如,在Linux中,当硬件中断发生时(如I/O操作完成),中断处理程序会执行相应的中断服务例程,并通过回调函数或信号量等方式通知等待的线程。线程被唤醒后,其task_struct结构体中的状态字段会被修改为TASK_RUNNING,并重新参与CPU的调度1。
性能影响:线程的阻塞和唤醒操作会消耗一定的系统资源,包括CPU时间和内存空间。特别是当线程频繁地进行阻塞和唤醒操作时,这种开销会更加明显。因此,在编写多线程程序时,需要合理设计线程之间的同步和通信机制,以减少不必要的阻塞和唤醒操作,提高程序的性能和响应速度
jvm运行原理
类型:hotspot vm / OpenJ9
JVM是一份本地化的程序,本质上是可执行的文件-/jre/bin/server/jvm.dll,是静态的概念。
程序运行起来成为进程,是动态的概念。java程序是跑在JVM上的,严格来讲,是跑在JVM实例上的,一个JVM实例其实就是JVM跑起来的进程,二者合起来称之为一个JAVA进程。各个JVM实例之间是相互隔离的。
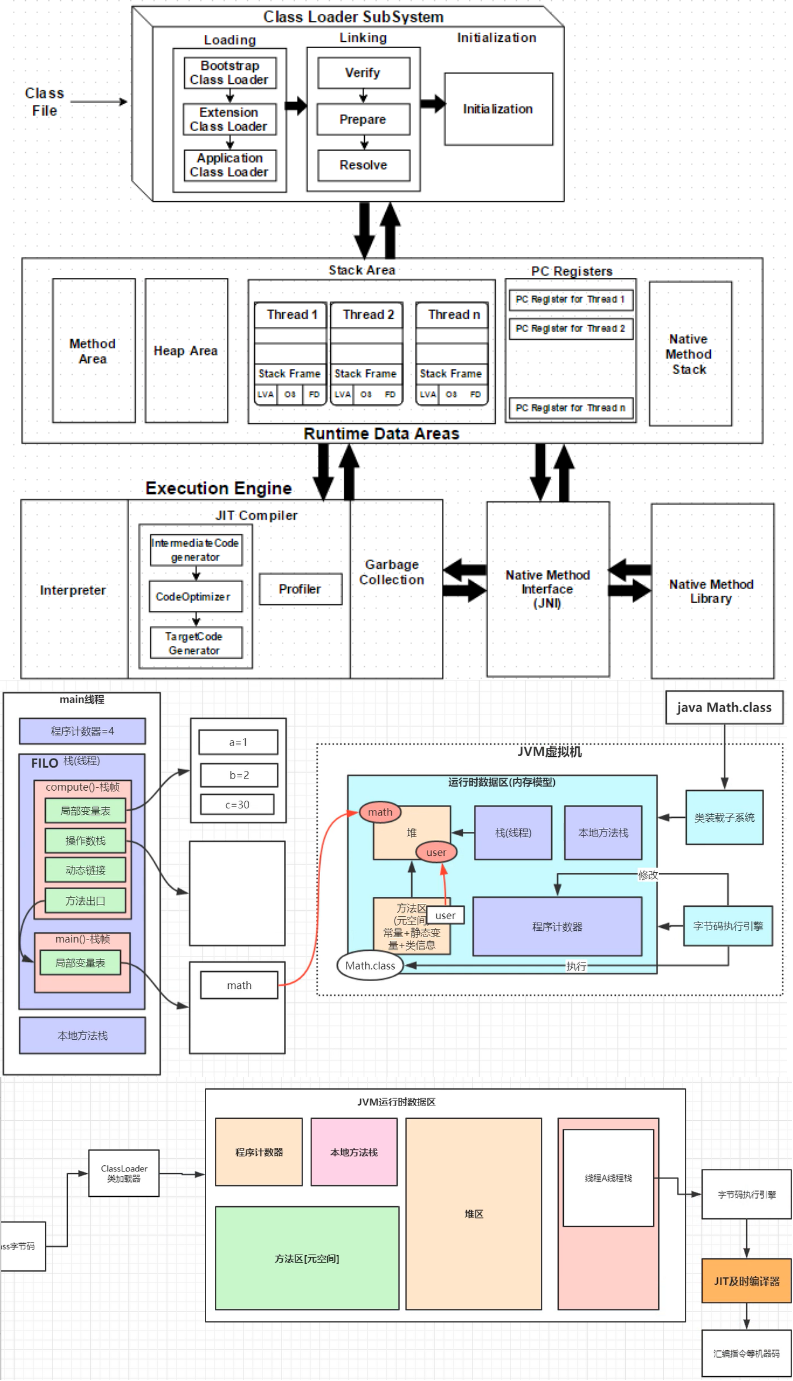
线程栈:栈帧的先进先出(异步方法呢?)
栈帧:对应每个线程中调用的方法,相应概念: 局部变量表 操作数栈 动态链接 方法出口
本地方法: Native method Stack,比如JNI调用c/C++程序
方法区 Method Area: 静态变量
Linux的内存空间地址从低到高一般分为五个部分:内核空间、栈区域、堆区域、BBS段、数据段和代码段
内核空间:我们在编写应用程序(非内核空间程序)的时候,这一块地址我们是不能够使用的 栈区域:程序中局部变量、函数参数、返回地址的地方地址。地址从低到高分配 堆区域:由malloc,calloc等创建的空间,是运行的时候由程序申请的。地址由高到低 BBS段:未初始化或初值为0的全局变量和静态局部变量 数据段:已初始化且初值非0的全局变量和静态局部变量 代码段:可执行代码、字符串字面值、只读变量
Notes: JVM VS Python VM JAVA需要经过一次编译成class文件,然后交给JVM跑,Python不需要编译,直接py交给PVM解释运行
JVM程序计数器 VS OS程序计数器
一. 介绍 JVM程序计数器:
程序计数器是一块较小的内存空间,它的作用可以看作是当前线程所执行的字节码的行号指示器。在虚拟机的概念模型里字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。- - 摘自《深入理解Java虚拟机》
pc 寄存器又称:程序计数器,指的是:当前线程正在执行的字节码指令地址(行号),简单的说指的是当前线程执行到了哪一行,任意时刻,一个线程只会执行一个方法,pc 寄存器保存一个指向当前线程正在执行的语句的指针。程序运行时,字节码解释器通过改变 pc 寄存器里面的值,达到选取下一条要执行的字节码指令地址的目的。个人理解是,pc 寄存器存储当前正在执行的指令的字节码地址,当该指令结束,字节码解释器会根据pc寄存器里的值选取下一条指令并修改pc寄存器里面的值,达到执行下一条指令的目的。 字节码解释器可以拿到所有的字节码指令执行顺序,而程序计数器只是为了记录当前执行的字节码指令地址,防止线程切换找不到下一条指令地址。
OS程序计数器: 为了保证程序(在操作系统中理解为进程)能够连续地执行下去,CPU必须具有某些手段来确定下一条指令的地址。而程序计数器正是起到这种作用,所以通常又称为指令计数器。在程序开始执行前,必须将它的起始地址,即程序的一条指令所在的内存单元地址送入PC,因此程序计数器(PC)的内容即是从内存提取的第一条指令的地址。当执行指令时,CPU将自动修改PC的内容,即每执行一条指令PC增加一个量,这个量等于指令所含的字节数,以便使其保持的总是将要执行的下一条指令的地址。由于大多数指令都是按顺序来执行的,所以修改的过程通常只是简单的对PC加1。 当程序转移时,转移指令执行的最终结果就是要改变PC的值,此PC值就是转去的地址,以此实现转移。有些机器中也称PC为指令指针IP(Instruction Pointer)
二. 特点 JVM程序计数器:
如果线程正在执行的是Java 方法,则这个计数器记录的是正在执行的虚拟机字节码指令地址
如果正在执行的是Native 方法,则这个技术器值为空(Undefined)
此内存区域是唯一一个在Java虚拟机规范中没有规定任何OutOfMemoryError情况的区域
在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间的计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存
OS程序计数器:
PC永远指向下一条待执行指令的内存地址(永远不会为Undefined),并且在程序开始执行前,将程序指令序列的起始地址,即程序的第一条指令所在的内存单元地址送入PC, CPU按照PC的指示从内存读取第一条指令(取指)。
当执行指令时,CPU自动地修改PC的内容,即每执行一条指令PC增加一个量,这个量等于指令所含的字节数(指令字节数),使PC总是指向下一条将要取指的指令地址。
由于大多数指令都是按顺序来执行的,所以修改PC的过程通常只是简单的对PC 加“指令字节数”。 当程序转移时,转移指令执行的最终结果就是要改变PC的值,此PC值就是转去的目标地址。 处理器总是按照PC指向,取指、译码、执行,以此实现了程序转移。
三.存储位置 JVM程序技术器:
线程独立的,JVM内存模型一块独立的存储区域,一般是CPU高速缓存中(L1~L3)
OS程序计数器:
OS线程的PC寄存器中。
堆heap
Heap memory = The younger generation + The old generation + Forever The younger generation = Eden District + Two Survivor District (From and To)
ps_survivor_space https://stackoverflow.com/questions/14436183/ps-survivor-space-almost-full
字节码引擎后在后台线程执行垃圾收集(minor gc和full gc),当发生垃圾收集的时候,会stop the world暂停当前活跃的线程
gc root
object header 分代年龄
minor gc: 对象new除了后先放到新生代,满了后触发minor gc,挪到from(survivor0),后面就在from(survivor0) to(survivor1)之间周转,直到被回收,或者直到年龄到达15,被挪到老生代
老生代包含: 1.长生不死的对象 (比如web服务的bean对象,线程池对象等) 2.大对象 3.动态年龄判断
full gc:老年代满了会触发
jdk调优工具jvisualvm (插件 visualgc)
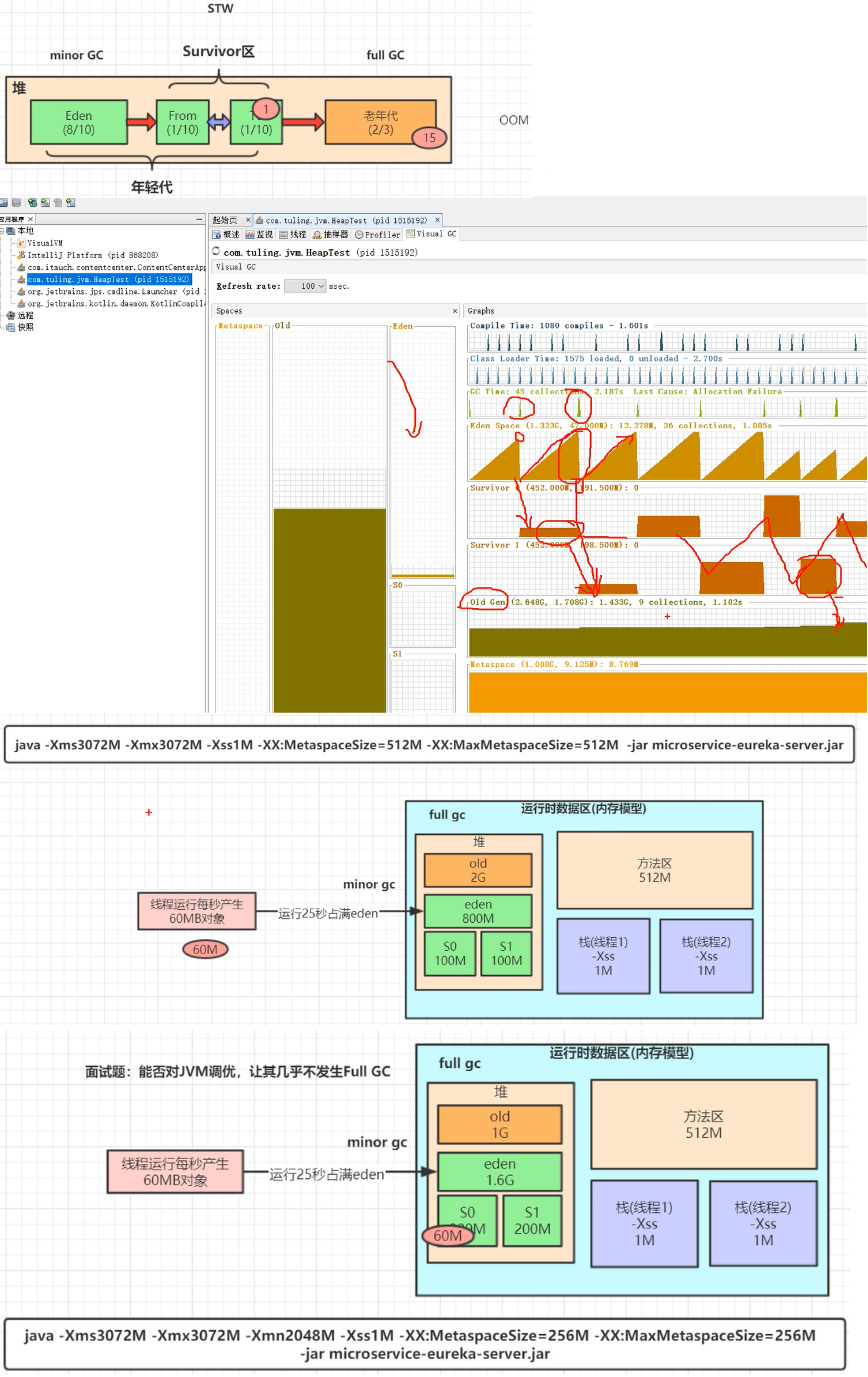
图中下部分给出了调优的例子
jmap -heap <pid>
print result:
using thread-local object allocation.
Parallel GC with 8 thread(s)
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 5221908480 (4980.0MB)
NewSize = 109051904 (104.0MB)
MaxNewSize = 1740636160 (1660.0MB)
OldSize = 218103808 (208.0MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 967835648 (923.0MB)
used = 368550864 (351.4774932861328MB)
free = 599284784 (571.5225067138672MB)
38.079901764478095% used
From Space:
capacity = 2097152 (2.0MB)
used = 0 (0.0MB)
free = 2097152 (2.0MB)
0.0% used
To Space:
capacity = 20447232 (19.5MB)
used = 0 (0.0MB)
free = 20447232 (19.5MB)
0.0% used
PS Old Generation
capacity = 207618048 (198.0MB)
used = 22015016 (20.995155334472656MB)
free = 185603032 (177.00484466552734MB)
10.60361380528922% used
21451 interned Strings occupying 2317096 bytes.
XX:SurvivorRatio
https://blog.csdn.net/flyfhj/article/details/86630105
JAVA内存模型 JMM
从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读/写共享变量的副本。 本地内存是JMM的一个抽象概念,它涵盖了各种CPU缓存、寄存器以及其他的硬件和编译器优化。
openJDK, IBM JDK, 阿里巴巴内部定制JVM
Java 内存模型对主内存与工作内存之间的具体交互协议定义了八种操作,具体如下:
- lock(锁定):作用于主内存变量,把一个变量标识为一条线程独占状态。
- unlock(解锁):作用于主内存变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
- read(读取):作用于主内存变量,把一个变量从主内存传输到线程的工作内存中,以便随后的 load 动作使用。
- load(载入):作用于工作内存变量,把 read 操作从主内存中得到的变量值放入工作内存的变量副本中。
- use(使用):作用于工作内存变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量值的字节码指令时执行此操作。
- assign(赋值):作用于工作内存变量,把一个从执行引擎接收的值赋值给工作内存的变量,每当虚拟机遇到一个需要给变量进行赋值的字节码指令时执行此操作。
- store(存储):作用于工作内存变量,把工作内存中一个变量的值传递到主内存中,以便后续 write 操作。
- write(写入):作用于主内存变量,把 store 操作从工作内存中得到的值放入主内存变量中。
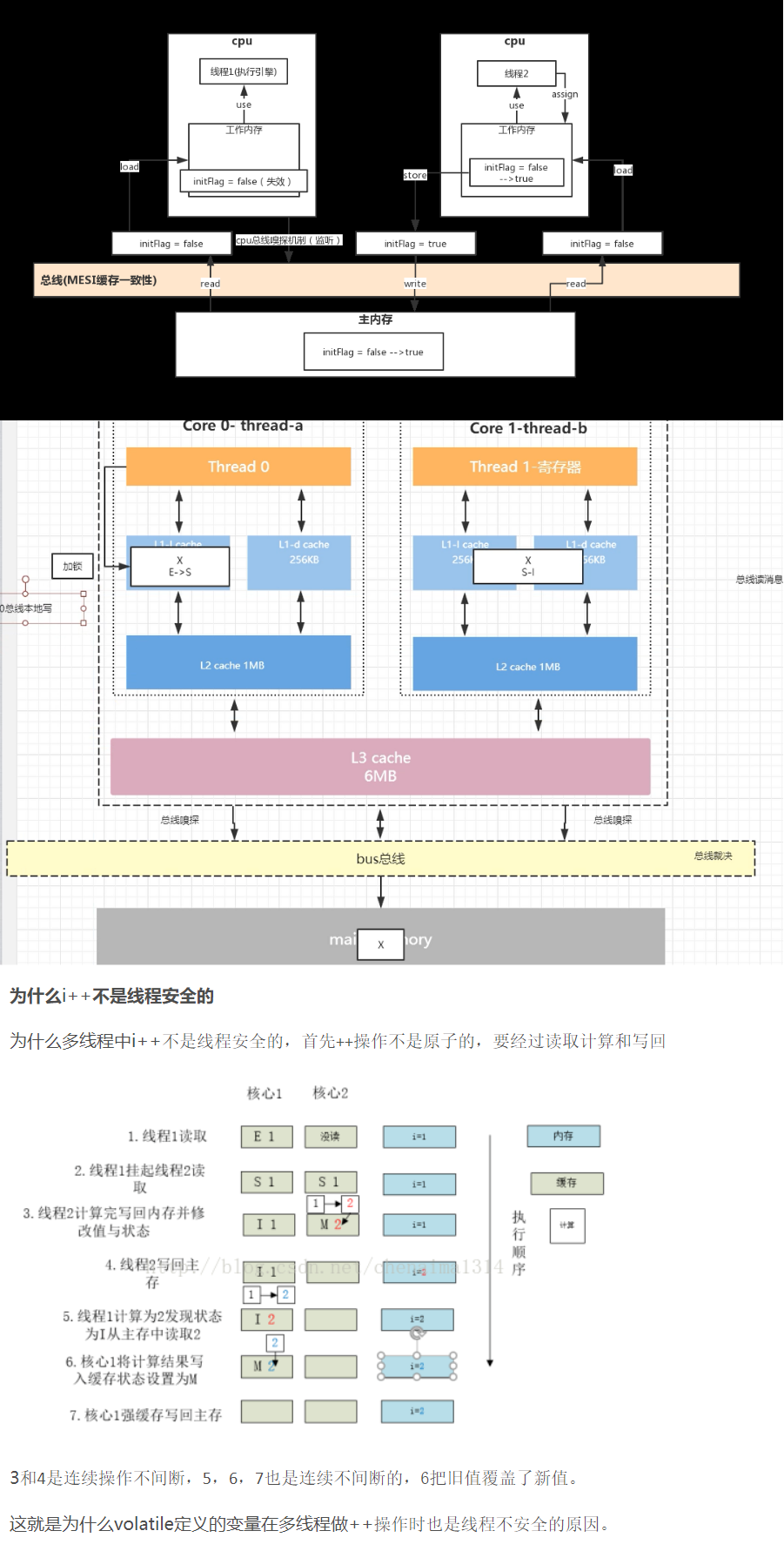
默认如图采用缓存一致性:MESI一致性协议 总线消息;总线嗅探;总线裁决; 指令重排 https://efectivejava.blogspot.com/2013/07/what-is-reordering-in-java-when-you.html
总线锁,如果是跨多个缓存行则采取总线锁
volatile避免指令重排,图下部分可见,volatile并不能保证线程安全(线程1最终并非基于线程2的最新结果2加1,而是基于旧的值1计算,虽然知道线程2修改的结果,但是它的做法是直接覆盖!)
入门到放弃 https://juejin.im/post/5b45ef49f265da0f5140489c
JMX Monitor https://docs.oracle.com/javase/6/docs/technotes/guides/management/agent.html
JPDA https://zhuanlan.zhihu.com/p/59639046
Load jni library from jar: https://blog.csdn.net/Revivedsun/article/details/86562934 https://stackoverflow.com/questions/1611357/how-to-make-a-jar-file-that-includes-dll-files http://www.jdotsoft.com/JarClassLoader.php#tempfiles
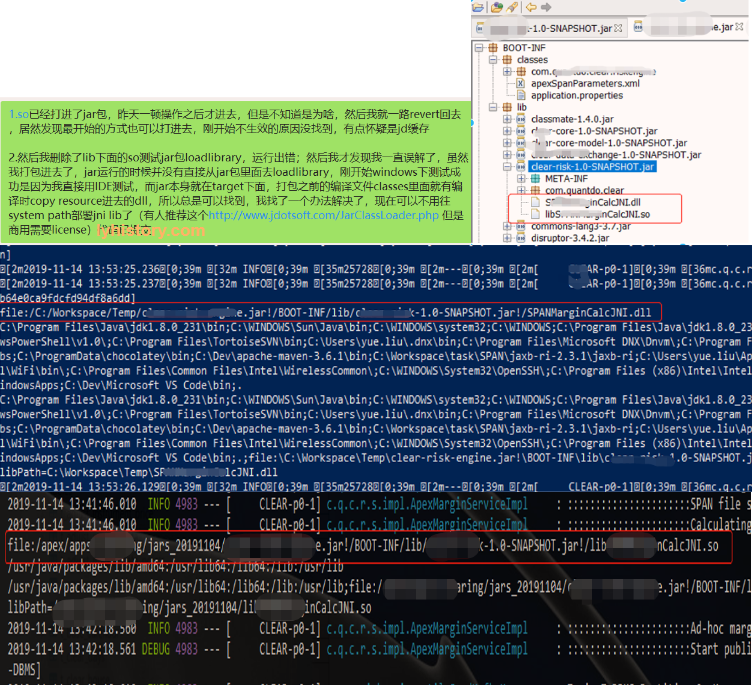
file:/C:/Workspace/Temp/XXX.jar!/BOOT-INF/lib/XXX-1.0-SNAPSHOT.jar!/XXXJNI.dll
file:/opt/XXX.jar!/BOOT-INF/lib/XXX-1.0-SNAPSHOT.jar!/libXXXJNI.so
getClass().getResourceAsStream(“/filename”); https://stackoverflow.com/questions/20389255/reading-a-resource-file-from-within-jar
GC
https://www.baeldung.com/java-verbose-gc#/ https://juejin.cn/post/6999865723145158670#/ https://www.baeldung.com/jvm-garbage-collectors#/
The Serial Collector(Stop-the-world)
The serial collector is the simplest one, and the one you probably won’t be using, as it’s mainly designed for single-threaded environments (e.g. 32 bit or Windows) and for small heaps. This collector freezes all application threads whenever it’s working, which disqualifies it for all intents and purposes from being used in a server environment.
How to use it: You can use it by turning on the -XX:+UseSerialGC JVM argument
The Parallel/Throughput Collector
Next off is the Parallel collector. This is the JVM’s default collector. Much like its name, its biggest advantage is that is uses multiple threads to scan through and compact the heap. The downside to the parallel collector is that it will stop application threads when performing either a minor or full GC collection. The parallel collector is best suited for apps that can tolerate application pauses and are trying to optimize for lower CPU overhead caused by the collector.
The CMS Collector
Following up on the parallel collector is the CMS collector (“concurrent-mark-sweep”). This algorithm uses multiple threads (“concurrent”) to scan through the heap (“mark”) for unused objects that can be recycled (“sweep”). This algorithm will enter “stop the world” (STW) mode in two cases: when initializing the initial marking of roots (objects in the old generation that are reachable from thread entry points or static variables) and when the application has changed the state of the heap while the algorithm was running concurrently, forcing it to go back and do some final touches to make sure it has the right objects marked.
The biggest concern when using this collector is encountering promotion failures which are instances where a race condition occurs between collecting the young and old generations. If the collector needs to promote young objects to the old generation, but hasn’t had enough time to make space clear it, it will have to do so first which will result in a full STW collection – the very thing this CMS collector was meant to prevent. To make sure this doesn’t happen you would either increase the size of the old generation (or the entire heap for that matter) or allocate more background threads to the collector for him to compete with the rate of object allocation.
Another downside to this algorithm in comparison to the parallel collector is that it uses more CPU in order to provide the application with higher levels of continuous throughput, by using multiple threads to perform scanning and collection. For most long-running server applications which are adverse to application freezes, that’s usually a good trade off to make. Even so, this algorithm is not on by default. You have to specify XX:+USeParNewGC to actually enable it. If you’re willing to allocate more CPU resources to avoid application pauses this is the collector you’ll probably want to use, assuming that your heap is less than 4Gb in size. However, if it’s greater than 4GB, you’ll probably want to use the last algorithm – the G1 Collector.
The G1 Collector
Garbage-First Garbage Collector Garbage First Garbage Collector Tuning
The Garbage first collector (G1) introduced in JDK 7 update 4 was designed to better support heaps larger than 4GB. The G1 collector utilizes multiple background threads to scan through the heap that it divides into regions, spanning from 1MB to 32MB (depending on the size of your heap). G1 collector is geared towards scanning those regions that contain the most garbage objects first, giving it its name (Garbage first). This collector is turned on using the –XX:+UseG1GC flag.
This strategy reduced the chance of the heap being depleted before background threads have finished scanning for unused objects, in which case the collector will have to stop the application which will result in a STW collection. The G1 also has another advantage that is that it compacts the heap on-the-go, something the CMS collector only does during full STW collections.
Large heaps have been a fairly contentious area over the past few years with many developers moving away from the single JVM per machine model to more micro-service, componentized architectures with multiple JVMs per machine. This has been driven by many factors including the desire to isolate different application parts, simplifying deployment and avoiding the cost which would usually come with reloading application classes into memory (something which has actually been improved in Java 8).
Even so, one of the biggest drivers to do this when it comes to the JVM stems from the desire to avoid those long “stop the world” pauses (which can take many seconds in a large collection) that occur with large heaps. This has also been accelerated by container technologies like Docker that enable you to deploy multiple apps on the same physical machine with relative ease.
JVM Crash debug
注意:jdk版本要跟工具一致(不过我成功的用oracle jdk的visualvm解析了openjdk的hprof文件)
- 文件类型:
- core dump: core.xxx
- heap dump: pid.hprof
- 常用工具:
- jvisualvm
- jps
- jstat
- jmap
- jstack https://www.jianshu.com/p/c6a04c88900a https://docs.oracle.com/javase/8/docs/technotes/guides/troubleshoot/tooldescr016.html
Debug Live Process:
javax.net.debug
tls/ssl: java -jar -Djavax.net.debug=all java -jar -Djavax.net.debug=help
java -XX:ErrorFile=/var/log/java/java_error%p.log If the -XX:ErrorFile=file flag is not specified, the default log file name is hs_err_pid.log, where pid is the PID of the process.
JVM参数 https://stackoverflow.com/questions/43087831/complete-list-of-jvm-options java -XX:+UnlockDiagnosticVMOptions -XX:+UnlockExperimentalVMOptions -XX:+PrintFlagsFinal -XX:+PrintFlagsWithComments -version JVM启动参数大全 https://www.cnblogs.com/qlqwjy/p/8037797.html
java -cp vs java -jar https://stackoverflow.com/questions/11922681/differences-between-java-cp-and-java-jar 基本区别就是,如果jar包,比如springboot的包将依赖都已经打入了META-INF,则用-jar,否则如果需要依赖外部的lib,则需要用cp指定classpath java -server -jar *.jar java程序启动参数-D含义详解 https://www.cnblogs.com/grefr/p/6087955.html
strace
strace -tt -f -o /tmp/output.log -p {pid}
Analysis Core dump
core file(core.XXX): In case of a JVM crash, the operating system creates a core dump file which is a memory snapshot of a running process. A core dump is created by the operating system when a fatal or unhandled error like signal or system exception occurs.
版本问题: 如果产品上装了多个JVM环境的化,注意core dump要和JVM的分析的版本一致(比如用的是openjdk还是oracle的) SA环境需要root权限
系统配置: ulimit -c unlimited,
不过对于java来说,jvm本身可能有自己的设置,默认应该就是unlimited,所以可以忽略系统设置,查看配置:
jps
jinfo <PROCESS ID>
cat /proc/<PROCESS ID>/limits
JSTAT
JVM Statistical monitoring tools
jstat -gc <PID> 250 4 //sampling interval is 250ms,Sampling number for 4
Output:
S0C、S1C、S0U、S1U:Survivor 0/1 Area capacity (Capacity) And usage (Used)
EC、EU:Eden Area capacity and usage
OC、OU: Capacity and usage of older generations
PC、PU: Permanent generation capacity and usage
YGC、YGT: The younger generation GC Times and GC Time consuming
FGC、FGCT:Full GC Times and Full GC Time consuming
GCT:GC Total time
hprof: to show CPU Usage rate , Statistics heap memory usage .
java -agentlib:hprof[=options] ToBeProfiledClass
java -Xrunprof[:options] ToBeProfiledClass
javac -J-agentlib:hprof[=options] ToBeProfiledClass
example:
java -agentlib:hprof=cpu=samples,interval=20,depth=3 Hello
Every other day on the top 20 Millisecond sampling CPU Consumption information , The stack depth is 3, Generated profile File name is java.hprof.txt, In the current directory .
JSTACK -> Live Process|Core dump
查死锁 jstack -J-d64 -l -m $JAVA_HOME/bin/java core.xxxxx
查内存泄露
top -Hp <PID>
输出结果,TIME一列查看时间占用比较久的 NID
printf "%x" <NID>
jstack <PID>|grep <NID IN hex format>
https://www.cnblogs.com/duanxz/p/5487576.html
JMAP | JHAT
查内存占用,jhat追查内存泄露 https://programs.wiki/wiki/performance-test-and-analysis-tools-jps-jstack-jmap-jhat-jstat-hprof-use-details.html
jmap $JAVA_HOME/bin/java core.xxxxx
jmap -J-d64
jmap -heap
jmap -histo
jmap + jhat
jmap -dump:format=b,file=core.xxxxx.dump $JAVA_HOME/bin/java core.xxxxx
jhat -port 9998 core.xxxxx.dump
open in browser: http://XXX:9998
jmap crashes with “can not get class data for” known bug, fixed starting with Java 8 Update 60. https://stackoverflow.com/questions/26882094/jmap-crashes-with-can-not-get-class-data-for
HSDB -> Live Process|Core dump
Java9为了简化hsdb和clhsdb的使用引入了一个新的命令jhsdb,可以通过该命令直接调用hsdb,clhsdb,jstack, jmap等命令 jhsdb jmap –histo –exe $JAVA_HOME/bin/java –core core.xxxxx
openjdk: GUI: sun.jvm.hotspot.HSDB command: sun.jvm.hotspot.CLHSDB
java -cp .:$JAVA_HOME/lib/sa-jdi.jar sun.jvm.hotspot.CLHSDB
java -cp .:$JAVA_HOME/lib/sa-jdi.jar sun.jvm.hotspot.CLHSDB $JAVA_HOME/bin/java /opt/core.10759
java -cp .:/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.232.b09-0.el7_7.x86_64/lib/sa-jdi.jar sun.jvm.hotspot.CLHSDB /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.232.b09-0.el7_7.x86_64/bin/java /opt/core.10759
输入threads可以查看所有的子线程,输入thread 线程id可以查看该线程的详情
jhisto:trying to print a histogram from the core dump, which shows an unusually high number of instances for Object.
classes是列出已经加载的所有的类的类型信息,class 完整类名是查找该类的类型信息
Inspect,用于查看指定地址的类(C++的类)的各属性信息
jstack用于查看是否存在死锁,查看所有线程的调用栈,加上-v选项可以输出详细的内存地址信息
pstack [-v]
universe同图形界面中的Heap Paramters选项,显示年轻代和老年代堆内存的地址范围
scanoops 用于在指定地址范围内搜索所有指定类型的所有实例(Oop),后跟起始地址和类型信息,然后通过inspect 可查看具体的实例属性
revptrs可根据对象地址查看引用该对象的活跃对象的地址,这里的引用是指通过类全局属性而非局部变量引用,修改上述测试用例在类A中增加一个私有属性,private Base ba=new Base(1);,然后依次执行universe,scanoops,revptrs,inspect命令
mem命令可查看指定起始地址和以位宽为单位的长度的内存的数据,64位CPU的位宽是8字节
print输入一个Klass*, Method*的地址,可以打印该类或者方法,效果等同于Code Viewer选项
where 通过threads可查看所有的线程,输入线程id,查看该线程的调用栈,输入-a,查看所有线程的调用栈
printas 后跟一个Hotspot Type和地址,会打印该Type对象的各属性,效果同inspect命令,不过不局限与oop,也可以是对象的真实地址
printstatics 可以用于获取Hotspot 定义的C++类的静态属性,如表示Java堆内存的Universe对象
printmdo用于打印指定地址的MethodData对象,该对象保存了Profile统计的方法性能的数据
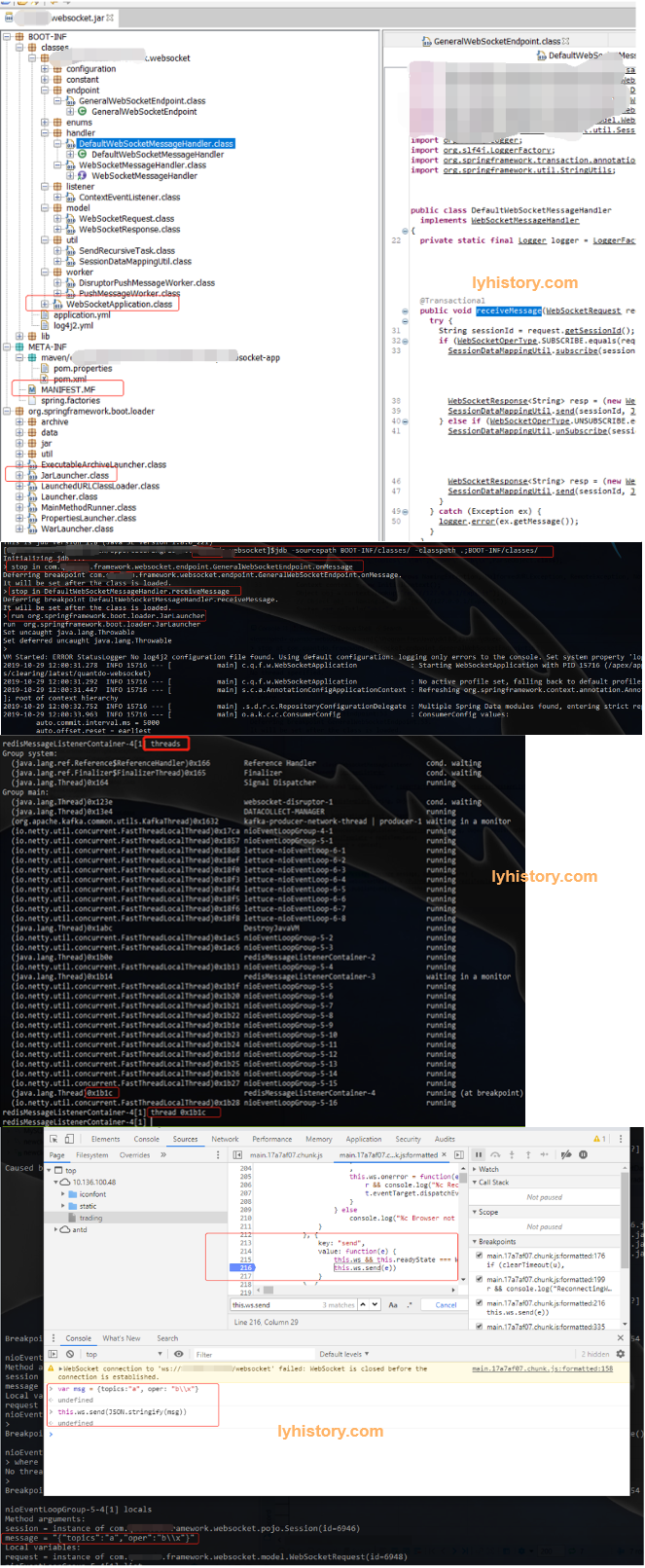
hsdb> threads
.....
30977 main
hsdb> where 30977
Thread 30977 Address: 0x00007fbd80008800
Java Stack Trace for main
Thread state = BLOCKED
hsdb> jhisto
hsdb> help
Available commands:
assert true | false
attach pid | exec core
buildreplayjars [ all | app | boot ] | [ prefix ]
class name
classes
detach
dis address [length]
disassemble address
dumpcfg { -a | id }
dumpclass { address | name } [ directory ]
dumpcodecache
dumpheap [ file ]
dumpideal { -a | id }
dumpilt { -a | id }
dumpreplaydata { <address > | -a | <thread_id> }
echo [ true | false ]
examine [ address/count ] | [ address,address]
field [ type [ name fieldtype isStatic offset address ] ]
findpc address
flags [ flag | -nd ]
help [ command ]
history
inspect expression
intConstant [ name [ value ] ]
jdis address
jhisto
jseval script
jsload file
jstack [-v]
livenmethods
longConstant [ name [ value ] ]
mem address [ length ]
pmap
print expression
printall
printas type expression
printmdo [ -a | expression ]
printstatics [ type ]
pstack [-v]
quit
reattach
revptrs address
scanoops start end [ type ]
search [ heap | perm | rawheap | codecache | threads ] value
source filename
symbol address
symboldump
symboltable name
sysprops
thread { -a | id }
threads
tokenize ...
type [ type [ name super isOop isInteger isUnsigned size ] ]
universe
verbose true | false
versioncheck [ true | false ]
vmstructsdump
whatis address
where { -a | id }
JDB
https://docs.oracle.com/javase/8/docs/technotes/tools/unix/jdb.html https://stackoverflow.com/questions/20018866/specifying-sourcepath-in-jdb-what-am-i-doing-wrong https://stackoverflow.com/questions/19843096/how-to-debug-a-java-application-without-access-to-the-source-code/58555431#58555431 https://stackoverflow.com/questions/3668379/use-a-jar-with-source-as-source-for-jdb/58603802#58603802
Live:
java -jar -agentlib:jdwp=transport=dt_shmem,address=jdbconn,server=y,suspend=n C:\Workspace\EclipseWorkspace\lyhistory-websocket\lyhistory-websocket.jar
jdb -attach jdbconn
jdb -sourcepath BOOT-INF/classes/ -classpath . org.springframework.boot.loader.JarLauncher
jdb -sourcepath BOOT-INF/classes/ -classpath .;BOOT-INF/classes/
stop at com.lyhistory.framework.websocket.endpoint.GeneralWebSocketEndpoint:54
stop at com.lyhistory.framework.websocket.handler.DefaultWebSocketMessageHandler:32
stop in DefaultWebSocketMessageHandler.receiveMessage
stop in com.lyhistory.framework.websocket.endpoint.GeneralWebSocketEndpoint.onMessage
stop in com.alibaba.fastjson.parser.JSONLexerBase.scanString
public final void scanString() {
public String scanString(char expectNextChar) {
stop at com.alibaba.fastjson.parser.JSONLexerBase:880
run org.springframework.boot.loader.JarLauncher
jdb -sourcepath BOOT-INF/classes/ -classpath .;BOOT-INF/classes/;BOOT-INF/lib/
stop at com.lyhistory.framework.cache.autoconfigure.support.WebsocketMessageListener:35
stop at org.springframework.data.redis.listener.RedisMessageListenerContainer:968
stop at com.lyhistory.framework.websocket.endpoint.GeneralWebSocketEndpoint:54
stop at com.lyhistory.framework.websocket.handler.DefaultWebSocketMessageHandler:32
stop at com.alibaba.fastjson.parser.JSONLexerBase:880
run org.springframework.boot.loader.JarLauncher
** command list **
connectors -- list available connectors and transports in this VM
run [class [args]] -- start execution of application's main class
threads [threadgroup] -- list threads
thread <thread id> -- set default thread
suspend [thread id(s)] -- suspend threads (default: all)
resume [thread id(s)] -- resume threads (default: all)
where [<thread id> | all] -- dump a thread's stack
wherei [<thread id> | all]-- dump a thread's stack, with pc info
up [n frames] -- move up a thread's stack
down [n frames] -- move down a thread's stack
kill <thread id> <expr> -- kill a thread with the given exception object
interrupt <thread id> -- interrupt a thread
print <expr> -- print value of expression
dump <expr> -- print all object information
eval <expr> -- evaluate expression (same as print)
set <lvalue> = <expr> -- assign new value to field/variable/array element
locals -- print all local variables in current stack frame
classes -- list currently known classes
class <class id> -- show details of named class
methods <class id> -- list a class's methods
fields <class id> -- list a class's fields
threadgroups -- list threadgroups
threadgroup <name> -- set current threadgroup
stop in <class id>.<method>[(argument_type,...)]
-- set a breakpoint in a method
stop at <class id>:<line> -- set a breakpoint at a line
clear <class id>.<method>[(argument_type,...)]
-- clear a breakpoint in a method
clear <class id>:<line> -- clear a breakpoint at a line
clear -- list breakpoints
catch [uncaught|caught|all] <class id>|<class pattern>
-- break when specified exception occurs
ignore [uncaught|caught|all] <class id>|<class pattern>
-- cancel 'catch' for the specified exception
watch [access|all] <class id>.<field name>
-- watch access/modifications to a field
unwatch [access|all] <class id>.<field name>
-- discontinue watching access/modifications to a field
trace [go] methods [thread]
-- trace method entries and exits.
-- All threads are suspended unless 'go' is specified
trace [go] method exit | exits [thread]
-- trace the current method's exit, or all methods' exits
-- All threads are suspended unless 'go' is specified
untrace [methods] -- stop tracing method entrys and/or exits
step -- execute current line
step up -- execute until the current method returns to its caller
stepi -- execute current instruction
next -- step one line (step OVER calls)
cont -- continue execution from breakpoint
list [line number|method] -- print source code
use (or sourcepath) [source file path]
-- display or change the source path
exclude [<class pattern>, ... | "none"]
-- do not report step or method events for specified classes
classpath -- print classpath info from target VM
monitor <command> -- execute command each time the program stops
monitor -- list monitors
unmonitor <monitor#> -- delete a monitor
read <filename> -- read and execute a command file
lock <expr> -- print lock info for an object
threadlocks [thread id] -- print lock info for a thread
pop -- pop the stack through and including the current frame
reenter -- same as pop, but current frame is reentered
redefine <class id> <class file name>
-- redefine the code for a class
disablegc <expr> -- prevent garbage collection of an object
enablegc <expr> -- permit garbage collection of an object
!! -- repeat last command
<n> <command> -- repeat command n times
# <command> -- discard (no-op)
help (or ?) -- list commands
version -- print version information
exit (or quit) -- exit debugger
<class id>: a full class name with package qualifiers
<class pattern>: a class name with a leading or trailing wildcard ('*')
<thread id>: thread number as reported in the 'threads' command
<expr>: a Java(TM) Programming Language expression.
Most common syntax is supported.
Startup commands can be placed in either "jdb.ini" or ".jdbrc"
in user.home or user.dir
Core dump:
jdb -connect sun.jvm.hotspot.jdi.SACoreAttachingConnector:javaExecutable=$JAVA_HOME/bin/java,core=core.XXXX
GDB
https://darkdust.net/files/GDB%20Cheat%20Sheet.pdf
$ export LD_LIBRARY_PATH=/customized/lib
$ gdb --args bin/HelloWorld config/some.xml
<gdb>run
$ gdb $JAVA_HOME/bin/java core.xxxxx
>where
>bt
https://blog.csdn.net/haolipengzhanshen/article/details/106728244?ops_request_misc=%7B%22request_id%22%3A%22165362535516781818746673%22%2C%22scm%22%3A%2220140713.130102334..%22%7D&request_id=165362535516781818746673&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-106728244-null-null.142%5Ev11%5Epc_search_result_control_group,157%5Ev12%5Enew_style1&utm_term=free%28%29%3A+invalid+size&spm=1018.2226.3001.4187
Arthas(阿尔萨斯)
https://github.com/alibaba/arthas https://arthas.aliyun.com/doc/
case study: https://github.com/alibaba/arthas/issues?q=label%3Auser-case
unzip arthas-bin.zip -d arthas
cd arthas
java -jar arthas-boot.jar
>dashboard
java -javaagent:/tmp/test/arthas-agent.jar -jar math-game.jar
./as.sh --select <program name>
MAT
https://www.eclipse.org/mat/downloads.php
jmap -dump:format=b,file=core.26635.dump $JAVA_HOME/bin/java core.26635