# What's
Disruptor 是 LMAX开发的开源 Java library,是用来处理海量 transactions 并且低延迟(没有复杂的并发代码)的并发编程框架,其性能优化的思路是通过一种特殊的软件设计来充分发挥底层硬件的效率。
single thread queue - LMAX DisruptorHigh Performance Inter-Thread Messaging Library https://lmax-exchange.github.io/disruptor/
http://lmax-exchange.github.io/disruptor/files/Disruptor-1.0.pdf https://github.com/LMAX-Exchange/disruptor/wiki/Getting-Started
# Mechanical Sympathy
This is all about understanding how the underlying hardware operates and programming in a way that best works with that hardware.
For example, let's see how CPU and memory organization can impact software performance. The CPU has several layers of cache between it and main memory. When the CPU is performing an operation, it first looks in L1 for the data, then L2, then L3, and finally, the main memory. The further it has to go, the longer the operation will take.
If the same operation is performed on a piece of data multiple times (for example, a loop counter), it makes sense to load that data into a place very close to the CPU.
| Latency from CPU to | CPU cycles | Time |
|---|---|---|
| Main memory | Multiple | ~60-80 ns |
| L3 cache | ~40-45 cycles | ~15 ns |
| L2 cache | ~10 cycles | ~3 ns |
| L1 cache | ~3-4 cycles | ~1 ns |
| Register | 1 cycle | Very very quick |
- Distilling a Model
- Understand the Safety Features
- Importance of Testing
- Let Data drive Decisions
- Mechanical Sympathy in Action
A model is a representation of the domain in a given context.
Map != Territory Model != Domain Software != Real World
Distil the essence of what represents the domain
Testing is about gaining experimental evidence to prove the model
Apply telemetry and perform real-time monitoring on the data
Telemetry not only informs the design it also allows for the tuning of a system in production
https://www.infoq.com/presentations/mechanical-sympathy/#downloadPdf/
# Why
# multithread?
并发一定要多线程吗?多线程一定性能好(吞吐transaction per sec、延时 latency)吗?单线程一定不好吗? 开发者了解瓶颈在哪吗? 开发者对如何利用硬件(os架构)了解吗?
# Why Not Queues(普通的queue)
- contention(write->enqueue,read[actually also write]->dequeue) - solved by 'block' but will switch to kernel invalid the cache(竞争导致锁升级会陷入内核态) Queue implementations tend to have write contention on the head, tail, and size variables. (Queues are typically always close to full or close to empty due to the differences in pace between consumers and producers. They very rarely operate in a balanced middle ground where the rate of production and consumption is evenly matched.)
To deal with the write contention, a queue often uses locks(比如java的线程安全的blockingqueue), which can cause a context switch to the kernel. When this happens the processor involved is likely to lose the data in its caches.
To get the best caching behavior, the design should have only one core writing to any memory location (multiple readers are fine, as processors often use special high-speed links between their caches). Queues fail the one-writer principle.
- cache line false sharing issue If two separate threads are writing to two different values, each core invalidates the cache line of the other (data is transferred between main memory and cache in blocks of fixed size, called cache lines). That is a write-contention between the two threads even though they're writing to two different variables. This is called false sharing, because every time the head is accessed, the tail gets accessed too, and vice versa.
# How Disruptor Work
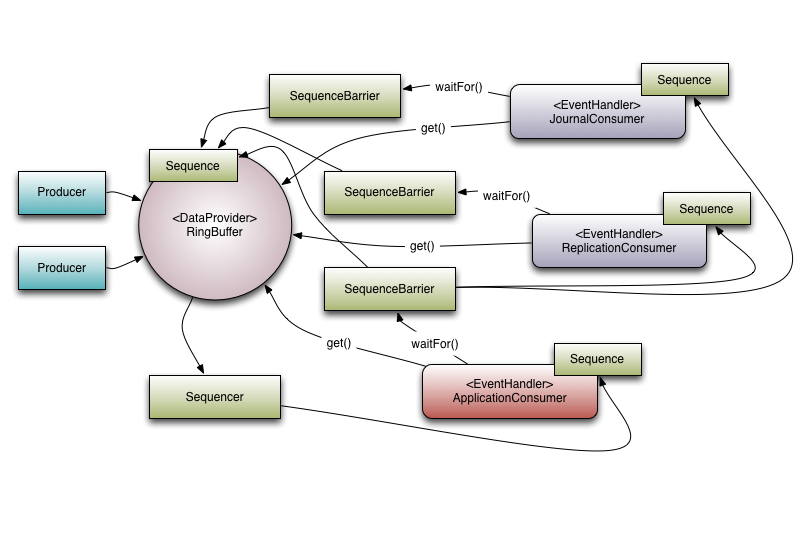
Disruptor has an array based circular data structure (ring buffer). It is an array that has a pointer to next available slot. It is filled with pre-allocated transfer objects. Producers and consumers perform writing and reading of data to the ring without locking or contention.
In a Disruptor, all events are published to all consumers (multicast), for parallel consumption through separate downstream queues. Due to parallel processing by consumers, it is necessary to coordinate dependencies between the consumers (dependency graph).
Producers and consumers have a sequence counter to indicate which slot in the buffer it is currently working on. Each producer/consumer can write its own sequence counter but can read other's sequence counters. The producers and consumers read the counters to ensure the slot it wants to write in is available without any locks.
# key concepts
- Ring Buffer
它通常被认为是 Disruptor 的主要方面, 但从 3.0 开始, 它仅负责存储和更新在 Disruptor 中移动的数据(事件). 对某些高级用例, 可完全由用户代替.
- Sequence
Disruptor 使用它作为一种手段来识别特定组件在哪里. 每个消费者 (EventProcessor) 和 Disruptor 本身一样都维护一个 Sequence . 大多数并发代码依赖于这些 Sequence 值的移动, 因此 Sequence 支持 AtomicLong 的许多当前功能. 实际上, 和版本 2 之间的唯一真正区别是, Sequence 包含其他功能, 以防止 Sequence 与其他值之间的伪共享.
- Sequencer
它是 Disruptor 的真正核心. 此接口的两个实(单生产者, 多生产者)实现了所有并发算法, 这些算法用于在生产者和消费者之间快速正确地传递数据
- Sequence Barrier
它是由 Sequencer 产生, 包含主要发布的 Sequence 的引用以及任何从属消费者的 Sequence . 它包含确定是否有任何事件可供消费者处理的逻辑.
- Wait Strategy
它确定消费者如何等待生产者将事件放入 Disruptor 中. 更多详细, 在下面的 可选无锁 部分.
- Event
从生产者到消费者的数据传递单元. 没有特定的代码来表示它, 完全是由用户定义的
- EventProcessor
用来处理来自 Disruptor 的事件的主事件循环(event loop), 并拥有消费者的 Sequence 所有权. 有一个 BatchEventProcessor , 它包含事件循环的高效实现并回调到 EventHandler 接口的提供的实现中.
- EventHandler
一个用于被用户实现的接口, 对于 Disruptor 来说, 就是一个消费者
- Producer
它是用户定义的代码, 调用 Disruptor 将事件进队. 这个概念并没有特定的代码表示.
# solve contention & false sharing issue 解决上面的问题
# 1. solve contention issue
无锁那基本就是 CAS - compare and swap
Lock Free:
All memory visibility and correctness guarantees are implemented using memory barriers and/or compare-and-swap operations.
There is only one use-case where an actual lock is required and that is within the BlockingWaitStrategy.
This is done solely for the purpose of using a condition so that a consuming thread can be parked while waiting for new events to arrive. Many low-latency systems will use a busy-wait to avoid the jitter that can be incurred by using a condition; however, in number of system busy-wait operations can lead to significant degradation in performance, especially where the CPU resources are heavily constrained, e.g. web servers in virtualised-environments.
Single vs. Multiple Producers One of the best ways to improve performance in concurrent systems is to adhere to the Single Writer Principle (opens new window), this applies to the Disruptor. If you are in the situation where there will only ever be a single thread producing events into the Disruptor, then you can take advantage of this to gain additional performance.
如果想避免contention,使用Disruptor的时候需要指定SingleProducer模式, 只有一个producer写入ringbuffer,producer和consumer各自维护自己的sequence数值,通过SequenceBarrier来保证Producer不会比consumer更快(保证还没有被消费的数据不会被覆盖)
Alternative Wait Strategies
The default WaitStrategy used by the Disruptor is the BlockingWaitStrategy. Internally the BlockingWaitStrategy uses a typical lock and condition variable to handle thread wake-up. The BlockingWaitStrategy is the slowest of the available wait strategies, but is the most conservative with the respect to CPU usage and will give the most consistent behaviour across the widest variety of deployment options.
- SleepingWaitStrategy → Like the BlockingWaitStrategy the SleepingWaitStrategy it attempts to be conservative with CPU usage by using a simple busy wait loop. The difference is that the SleepingWaitStrategy uses a call to LockSupport.parkNanos(1) in the middle of the loop. On a typical Linux system this will pause the thread for around 60µs.
This has the benefits that the producing thread does not need to take any action other increment the appropriate counter and that it does not require the cost of signalling a condition variable. However, the mean latency of moving the event between the producer and consumer threads will be higher.
It works best in situations where low latency is not required, but a low impact on the producing thread is desired. A common use case is for asynchronous logging.
- YieldingWaitStrategy →
The YieldingWaitStrategy is one of two WaitStrategys that can be use in low-latency systems. It is designed for cases where there is the option to burn CPU cycles with the goal of improving latency.
The YieldingWaitStrategy will busy spin, waiting for the sequence to increment to the appropriate value. Inside the body of the loop Thread#yield() will be called allowing other queued threads to run.
This is the recommended wait strategy when you need very high performance, and the number of EventHandler threads is lower than the total number of logical cores, e.g. you have hyper-threading enabled.
- BusySpinWaitStrategy →
The BusySpinWaitStrategy is the highest performing WaitStrategy. Like the YieldingWaitStrategy, it can be used in low-latency systems, but puts the highest constraints on the deployment environment.
This wait strategy should only be used if the number of EventHandler threads is lower than the number of physical cores on the box, e.g. hyper-threading should be disabled.
# 2. solve cache line false sharing issue by padding
class LhsPadding
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding
{
protected volatile long value;
}
class RhsPadding extends Value
{
protected long p9, p10, p11, p12, p13, p14, p15;
}
# 3. More performance improvement: Event Pre-allocation
One of the goals of the Disruptor is to enable use within a low latency environment. Within low-latency systems it is necessary to reduce or remove memory allocations. In Java-based system the purpose is to reduce the number stalls due to garbage collection [1].
To support this the user is able to preallocate the storage required for the events within the Disruptor. During construction and EventFactory is supplied by the user and will be called for each entry in the Disruptor’s Ring Buffer. When publishing new data to the Disruptor the API will allow the user to get hold of the constructed object so that they can call methods or update fields on that store object. The Disruptor provides guarantees that these operations will be concurrency-safe as long as they are implemented correctly.
# 4. Multicast Events & Consumer Dependency Graph
This is the biggest behavioural difference between queues and the Disruptor.
When you have multiple consumers listening on the same Disruptor, it publishes all events to all consumers. In contrast, a queue will only send a single event to a single consumer. You can use this behaviour of the Disruptor when you need to independent multiple parallel operations on the same data. Example use-case: The canonical example from LMAX is where we have three operations: - journalling (writing the input data to a persistent journal file); - replication (sending the input data to another machine to ensure that there is a remote copy of the data); - and business logic (the real processing work).
To support real world applications of the parallel processing behaviour it was necessary to support co-ordination between the consumers. Referring back to the example described above, it is necessary to prevent the business logic consumer from making progress until the journalling and replication consumers have completed their tasks. We call this concept “gating” (or, more correctly, the feature is a form of “gating”).
“Gating” happens in two places:
Firstly we need to ensure that the producers do not overrun consumers. This is handled by adding the relevant consumers to the Disruptor by calling RingBuffer.addGatingConsumers(). 就是说Producer和consumer各自维护自己的sequence number,然后让consumer可以读取Producer的sequence number,比如Producer生产到producer.seq=10,consumer现在读取到consumer.seq=4,然后consumer就知道自己可以继续读取[5,6,7,8,9,10]
Secondly, the case referred to previously is implemented by constructing a SequenceBarrier containing Sequences from the components that must complete their processing first.
Referring to [Figure 1] there are 3 consumers listening for Events from the Ring Buffer. There is a dependency graph in this example.
The ApplicationConsumer depends on the JournalConsumer and ReplicationConsumer. This means that the JournalConsumer and ReplicationConsumer can run freely in parallel with each other. The dependency relationship can be seen by the connection from the ApplicationConsumer's SequenceBarrier to the Sequences of the JournalConsumer and ReplicationConsumer.
It is also worth noting the relationship that the Sequencer has with the downstream consumers. One of its roles is to ensure that publication does not wrap the Ring Buffer. To do this none of the downstream consumer may have a Sequence that is lower than the Ring Buffer’s Sequence less the size of the Ring Buffer.
However, by using the graph of dependencies an interesting optimisation can be made. Because the ApplicationConsumer's Sequence is guaranteed to be less than or equal to that of the JournalConsumer and ReplicationConsumer (that is what that dependency relationship ensures) the Sequencer need only look at the Sequence of the ApplicationConsumer. In a more general sense the Sequencer only needs to be aware of the Sequences of the consumers that are the leaf nodes in the dependency tree.
# 注意:Disruptor 默认是MultiProducer+BlockingWaitStrategy也就是加锁的策略
this.disruptor = new Disruptor<>(KafkaEventWrapper::new, 1 << queueSizeBits, new NamedThreadFactory(threadPrefix));
public Disruptor(final EventFactory<T> eventFactory, final int ringBufferSize, final ThreadFactory threadFactory)
{
this(RingBuffer.createMultiProducer(eventFactory, ringBufferSize), new BasicExecutor(threadFactory));
}
public static <E> RingBuffer<E> createMultiProducer(EventFactory<E> factory, int bufferSize)
{
return createMultiProducer(factory, bufferSize, new BlockingWaitStrategy());
}
/**
* Blocking strategy that uses a lock and condition variable for {@link EventProcessor}s waiting on a barrier.
* <p>
* This strategy can be used when throughput and low-latency are not as important as CPU resource.
*/
public final class BlockingWaitStrategy implements WaitStrategy
{
private final Lock lock = new ReentrantLock();
private final Condition processorNotifyCondition = lock.newCondition();
@Override
public long waitFor(long sequence, Sequence cursorSequence, Sequence dependentSequence, SequenceBarrier barrier)
throws AlertException, InterruptedException
{
long availableSequence;
if (cursorSequence.get() < sequence)
{
lock.lock();
try
{
while (cursorSequence.get() < sequence)
{
barrier.checkAlert();
processorNotifyCondition.await();
}
}
finally
{
lock.unlock();
}
}
while ((availableSequence = dependentSequence.get()) < sequence)
{
barrier.checkAlert();
ThreadHints.onSpinWait();
}
return availableSequence;
}
@Override
public void signalAllWhenBlocking()
{
lock.lock();
try
{
processorNotifyCondition.signalAll();
}
finally
{
lock.unlock();
}
}
@Override
public String toString()
{
return "BlockingWaitStrategy{" +
"processorNotifyCondition=" + processorNotifyCondition +
'}';
}
}
public static <E> RingBuffer<E> createMultiProducer(
EventFactory<E> factory,
int bufferSize,
WaitStrategy waitStrategy)
{
MultiProducerSequencer sequencer = new MultiProducerSequencer(bufferSize, waitStrategy);
return new RingBuffer<E>(factory, sequencer);
}
public final class MultiProducerSequencer extends AbstractSequencer
{
}
public abstract class AbstractSequencer implements Sequencer
{
@Override
public SequenceBarrier newBarrier(Sequence... sequencesToTrack)
{
return new ProcessingSequenceBarrier(this, waitStrategy, cursor, sequencesToTrack);
}
}
final class ProcessingSequenceBarrier implements SequenceBarrier
{
@Override
public long waitFor(final long sequence)
throws AlertException, InterruptedException, TimeoutException
{
checkAlert();
long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this);
if (availableSequence < sequence)
{
return availableSequence;
}
return sequencer.getHighestPublishedSequence(sequence, availableSequence);
}
}
public final class RingBuffer<E> extends RingBufferFields<E> implements Cursored, EventSequencer<E>, EventSink<E>
{
RingBuffer(
EventFactory<E> eventFactory,
Sequencer sequencer)
{
super(eventFactory, sequencer);
}
}
@SuppressWarnings("varargs")
@SafeVarargs
public final EventHandlerGroup<T> handleEventsWith(final EventHandler<? super T>... handlers)
{
return createEventProcessors(new Sequence[0], handlers);
}
EventHandlerGroup<T> createEventProcessors(
final Sequence[] barrierSequences,
final EventHandler<? super T>[] eventHandlers)
{
checkNotStarted();
final Sequence[] processorSequences = new Sequence[eventHandlers.length];
final SequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences);
for (int i = 0, eventHandlersLength = eventHandlers.length; i < eventHandlersLength; i++)
{
final EventHandler<? super T> eventHandler = eventHandlers[i];
final BatchEventProcessor<T> batchEventProcessor =
new BatchEventProcessor<>(ringBuffer, barrier, eventHandler);
if (exceptionHandler != null)
{
batchEventProcessor.setExceptionHandler(exceptionHandler);
}
consumerRepository.add(batchEventProcessor, eventHandler, barrier);
processorSequences[i] = batchEventProcessor.getSequence();
}
updateGatingSequencesForNextInChain(barrierSequences, processorSequences);
return new EventHandlerGroup<>(this, consumerRepository, processorSequences);
}
private void processEvents()
{
T event = null;
long nextSequence = sequence.get() + 1L;
while (true)
{
try
{
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
if (batchStartAware != null)
{
batchStartAware.onBatchStart(availableSequence - nextSequence + 1);
}
while (nextSequence <= availableSequence)
{
event = dataProvider.get(nextSequence);
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
nextSequence++;
}
sequence.set(availableSequence);
}
catch (final TimeoutException e)
{
notifyTimeout(sequence.get());
}
catch (final AlertException ex)
{
if (running.get() != RUNNING)
{
break;
}
}
catch (final Throwable ex)
{
exceptionHandler.handleEventException(ex, nextSequence, event);
sequence.set(nextSequence);
nextSequence++;
}
}
}
/**
* <p>Concurrent sequence class used for tracking the progress of
* the ring buffer and event processors. Support a number
* of concurrent operations including CAS and order writes.
*
* <p>Also attempts to be more efficient with regards to false
* sharing by adding padding around the volatile field.
*/
public class Sequence extends RhsPadding
{
# todo
https://emacsist.github.io/2019/10/12/disruptor%E5%AD%A6%E4%B9%A0/
javadoc
https://javadoc.io/doc/com.lmax/disruptor/latest/index.html
https://www.youtube.com/watch?v=DCdGlxBbKU4