回目录 《concurrency并发》
阿里巴巴亿级流量并发手册
# 并发
# concurrency并发 VS Parallelism并行
首先要明确个词的意思,首先引用:
Concurrency means multiple tasks which start, run, and complete in overlapping time periods, in no specific order. Parallelism is when multiple tasks OR several part of a unique task literally run at the same time, e.g. on a multi-core processor. Remember that Concurrency and parallelism are NOT the same thing. https://howtodoinjava.com/java/multi-threading/concurrency-vs-parallelism/
"concurrent" is used only for events that occur over a period of time, whereas "simultaneous" can also be used for events that occur at a point in time.
可以看到,cocurrency并发是只在一段时间内很多events一起发生,但是在这段时间内的任意一个时刻可能只有一个event发生,而parallelism是指events发生是simultaneously,某个时刻他们是可以同时发生;
以吃饭和说话举例: 有些人吃饭的时候不喜欢说话,只有吃完饭才说话,所以不支持并发concurrency和并行parallelism; 有些人吃饭的时候说话比较优雅礼貌,每次都是先吞下嘴里的食物才说话,然后说了一句再吃一口,所以他支持并发concurrency但不支持并行parallelism; 有些人吃饭不讲究,嘴里还没咽下去,同时还高声阔谈,食物有时候喷的对方一脸,所以他同时支持并发concurrency和并行parallelism;
所以并发只是强调可以在一段时间内同时处理多个事务,并行是强调可以在某一个时刻处理多个事务,并发可以不并行,并行一定是并发;
比如早期一个核的cpu也可以处理多个任务就是属于并发但是不是并行,在任何一个cpu时刻,只能处理一件任务,而多核则同一个时刻,多个cpu并行处理不同任务; 关于cpu这个层面的概念可以参考被神话的Linux, 一文带你看清Linux在多核可扩展性设计上的不足 (opens new window)
所以我们并太关心并行,因为这个涉及到硬件和底层操作系统的处理,我们现在只关心并发的处理;
一般谈到并发我们基本都是暗指高并发,实际上也有低并发的情况需要处理,比如低并发但是每个任务都是需要消耗长处理时间,下面也会提到;
concurrent control或者并发控制是关乎系统的consistency一致性, 最直接的想法是先来后到,但是先来后到也有问题,先来的可能做了一系列的读写操作,后到的就要一直等着吗,显然这种处理很粗暴, 所以对于单机系统来说,比如数据库,一般都是通过隔离水平isolation level来控制不同的粒度; 对于分布式系统来说,不同的产品的promise和guarantee也是不同的,比如zookeeper通过ZAP协议保证顺序一致性sequential consistency,但是zookeeper并不保证每个客户端看到的东西是一致的, 这个可以看我的zookeeper讲解,再比如kafka提供了exactly once的语义,意思是不会重复或丢失消息,但是也是取决于client的实现,实际项目中因为会涉及到跟其他产品比如数据库交互, 其实从业务角度或者项目角度是难以实现exactly once的,所以要分清产品本身(server端和client端)能做到什么,以及结合到实际项目中又是会如何;
另外关于并发的一个误区:handle并发并不一定需要多线程,比如nodejs,redis都是单线程处理的,原理就算通过event loop,再比如Disruptor框架是通过ringbuffer
# 高并发
1000W长连接,如何建立和维护?千万用户IM ,如何架构设计? (opens new window)
关键指标:
-响应时间(Response Time)
-吞吐量(Throughput)
-每秒查询率QPS(Query Per Second)
-每秒事务处理量TPS(Transaction Per Second)
-同时在线用户数量
关键指标的维度:
-平均,如:小时平均、日平均、月平均
-Top百分数TP(Top Percentile),如:TP50、TP90、TP99、TP4个9
-最大值
-趋势
「并发」由于在互联网架构中,已经从机器维度上升到了系统架构层面,所以和「并行」已经没有清晰的界限。「并」(同时)是其中的关键。由于「同时」会引发多久才叫同时的问题,将时间扩大,又根据不同业务关注点不同,引申出了引申指标。
引申指标:
-活跃用户数,如:日活DAU(Daily Active User)、月活MAU(Monthly Active Users)
-点击量PV(Page View)
-访问某站点的用户数UV(Unique Visitor)
-独立IP数IP(Internet Protocol)
-日单量
# 1. 数据库Database Isolation
Isolation (database systems) https://en.wikipedia.org/wiki/Isolation_(database_systems)#Read_committed
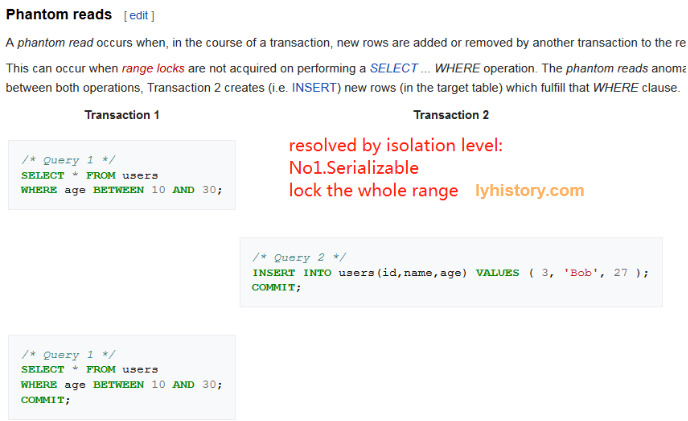
幻读
解决办法:整个区间加锁
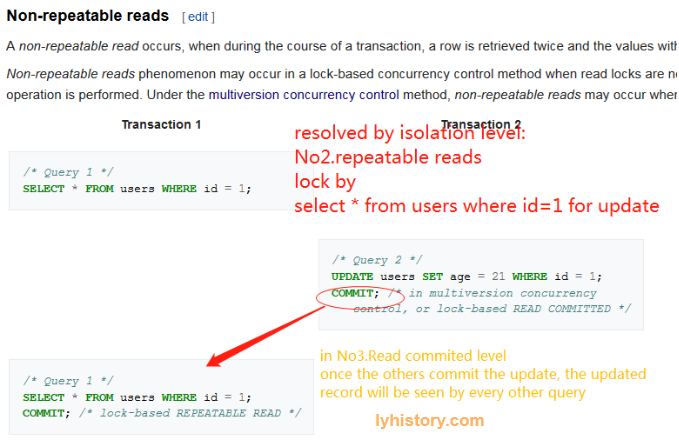
不可重复读
解决办法: 记录级别加锁 select for update
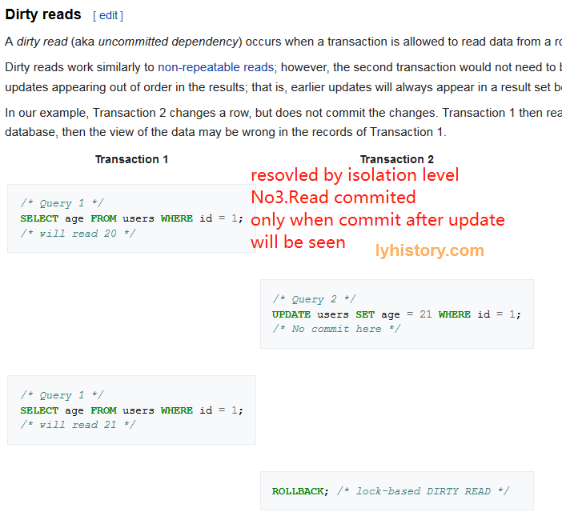
脏读取
解决办法:commit之后才生效
Common scenarios
- no matter what the db level lock settings, it’s better to add extra lock when doing transaction update
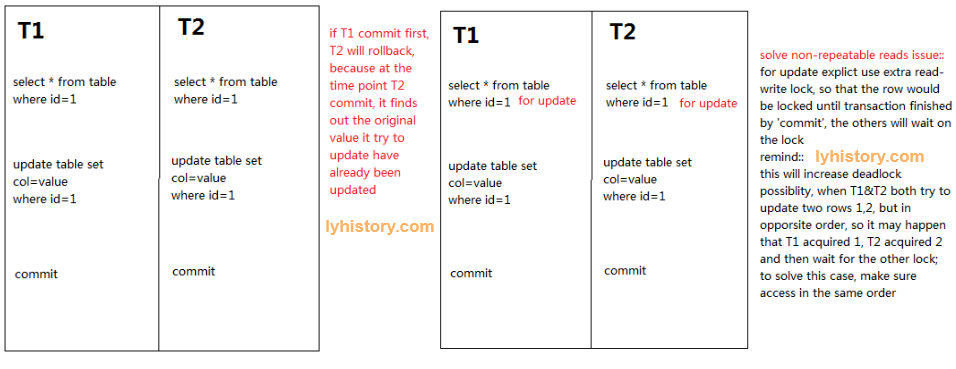
- ‘duplicate’ issue
这里只举例一个用户手快点了多次的情况(真实发生过),解决方法是不要在function或者存储过程中生成id,而是从外部传入; 不过如果发生另外一个极端情况,不同用户同一时刻注册相同用户名,则需要另想办法,因为这样的话id肯定不同,username又不是主键不会冲突, 所以要么从username生成id,比如hash运算,要么去掉username的概念,只允许手机号或者邮箱注册;

# 2. 应用层面的并发
从单个应用来讲,有几种方式:
a.采用多线程,多开几个线程或线程池,充分利用cpu和内存,尤其是当遇到比较复杂的计算时,单个线程处理时间过长会阻塞影响性能,所以可以用java等forkjoinpool之类的方式处理;
b.采用多进程,多个应用协同,比如前面加个load balance反向代理分流比如ha proxy (opens new window) 或者nginx,比如淘宝CDN采用ha proxy, 当然如果应用之间需要业务层面的协同,比如用户session管理,几个应用之间可以采用share session之类的其他工具或框架;
c.采用队列,比如消息队列
实际上第一种方式基本都不是为了处理高并发,现在很少有给一个单体应用加cpu内存的这种处理方式,如上面举例,一般都是用来处理long processing time的问题(低并发但是处理时间较长的任务), 然后本质上b和c的原理差不多,只是观察的角度和粒度不同,实际ha proxy和nginx这些内部也是可能采用队列思想,这个我没有深入探索只是粗略知道;
最后换个角度从整体架构上看,第三种方式比较有优势,比如采用FIFO排队方式来处理高并发, 额外的好处:解耦了消息的生产者和消费者,生产者负责把消息放到队列尾部,消费者则从队列头拉取消息进行处理, 由于解耦了生产者和消费者,互相就不需要等待对方处理,所以是异步操作,生产者不需要等待消费者处理某条消息的结果;
如果有同步需求怎么办,比如有些场景生产者还是要等待消费者处理结果才能进入下一步的, 这种完全可以拆解成消费者处理完之后将处理之后的结果放入另一个队列,然后生产者再作为消费者去消费这个队列即可, 然后可以对刚才这个过程做一个封装,将第二个队列的生产消费做成回调,就可以做成同步请求,比如类似:
producer1.sendTransaction({from: '0x123...', data: '0x432...'})
.on('confirmation', function(confNumber, receipt){ //回调 })
.on('error', function(error){ ... })
.then(function(receipt){
});
架构也是建立在一个个等应用之上的,所以落实到对应架构中要直面高并发情况的某个应用程序,如何去实现这个队列呢?
java sdk默认提供了非线程安全的队列和线程安全的队列,实际项目多涉及到多线程,所以我们只说后者,线程安全队列又分为两类队列:
无界的队列 不用锁的队列:LinkedTransferQueue,ConcurrentLinkedQueue,由于无界,所以有内存溢出的风险
有界队列 加锁的队列: ArrayBlockingQueue,LinkedBlockingQueue,但是有锁就有阻塞,所以性能会比较低
但是,
# 多线程不代表高性能!
# cache line false sharing
# 维护线程以及线程间开销
# 多线程锁升级可能触发内核态,从而降低性能
要处理高并发,肯定要考虑性能,有没有性能高即无锁non-blocking并且有界的队列呢,LMAX开发的Disruptor就是这么一个无锁高性能有界循环队列,
但是需要注意的是:
1)所谓无锁并非完全没有锁,而是指没有用到重锁从而导致系统调用操作系统线程的挂起唤醒等耗时操作,本质还是要用到所谓原子锁(无锁队列通常使用原子操作(如CAS)来避免锁的使用。原子操作能够在单个CPU指令中完成,这减少了线程之间的冲突和等待时间,从而提高了性能)
2)所谓的单线程并非完全单线程,而是分为单线程模式(单个生产者)和多线程模式(多个生产者),即使单线程模式下也并非只有一个线程,而是指没有竞争线程,而多线程模式下是指少量的竞争者并且竞争时间很短可以使用轻量级锁
“It ensures that any data is owned by only one thread for write access, therefore reducing write contention compared to other structures.”
现在Disruptor已经成为很多交易所的基础框架一部分,性能对比参考 (opens new window) 你应该知道的高性能无锁队列Disruptor (opens new window) 可以看到越来越多的框架集成了disruptor队列,比如log4j,storm,solr https://mvnrepository.com/artifact/com.lmax/disruptor/3.2.1/usages https://mvnrepository.com/artifact/com.lmax/disruptor/3.4.0/usages
NOTES: 虽然Disruptor的ring buffer队列可以处理高并发,但是有时候业务上对消息队列有更复杂的要求,比如可以pub sub,可以存储当做db,如果下游挂掉可以重新恢复到之前的位置重跑等等, 所以我们有kafka消息队列, kafka消息队列底层的基于sequential consistency的zab协议一定程度上保证了可以实现‘exactly-once’的语义: 消息生产者producer可以保证幂等性(kafka系统内的重发不会造成下游收到多条重复数据,当然也不会丢失), 消息消费者consumer可以通过自主管理offset和使用事务提交offset以及下游写入kafka的消息,可以保证不重复消费也不会丢失;
# java线程与并行
Java 平台从Java 1.0 开始就以Thread 类和Runnable接口来支持多线程或并行程序设 计。Java 5.0 以针对并行程序设计的新的实用程序的广泛组来加强支持。 创建、运行以及操作线程 Java 使得在程序中定义与运作多个线程变得容易。java.lang.Thread 是Java API 中 的基础线程类。定义线程的方法有两种:一种是制作Thread 的子类,覆盖run() method,然后实例化你的Thread 子类;另一种是定义实现了Runnable method 的类 (也就是定义run() method),然后传递此Runnable 对象的instance 给Thread()构 造函数。无论是哪种方法,结果都是Thread 对象,其中run() method 是线程的主体。 当你调用Thread对象的start() method时,解释器会创建一个新的线程来执行run() method。此新线程会继续运行,直到run() method 结束。此时,原来的线程会从接在 start() method 后面的语句开始继续运行其本身。以下程序代码说明这点:
/** 用来在后台对List 排序的Thread 类*/
class BackgroundSorter extends Thread {
List l;
public BackgroundSorter(List l) { this.l = l; } // 构造函数
public void run() { Collections.sort(l); } // 线程主体
}
// 创建BackgroundSorter 线程
Thread sorter = new BackgroundSorter(list);
// 开始运行;在原来的线程继续执行接下来
// 的语句时,新的线程会执行run() method
sorter.start();
// 这是另一个定义类似线程的方法
Thread t = new Thread(new Runnable() { // 创建一个新的线程
public void run() { Collections.sort(list); } // 为对象列表排序
});
t.start(); // 开始运行
线程的生命周期 线程可以处于六种状态中的一种。在Java 5.0 中,这些状态是由Thread.State枚举类 型表示,而线程的状态可以用getState() method 来查询。Thread.State 常量列表 很好地提供了线程生命周期的一览: NEW Thread 已被创建,但其start() method 尚未被调用。所有线程都会从这个状态 开始。 RUNNABLE 线程正在运行或在操作系统调度它时就可运行。 BLOCKED 因为线程在等待取得锁定以便进入同步method 或程序块,所以线程并未运行。我 们会在本节的稍后看到更多关于同步method 和程序块的信息。 WAITING 线程因为调用了Object.wait()或Thread.join()而未运行。 TIMED_WAITING 线程因为调用了Thread.sleep()或加上逾时值来调用Object.wait()或 Thread.join()而未运行。 TERMINATED 线程已运行完毕。它的run() method 已正常结束或通过抛出异常而结束。 线程优先级 线程可以以不同的优先级运行。指定优先级的线程通常会在已无具较高优先级的线程等 待时才会运行。在运作线程优先级时,你可以使用这里的一些程序代码: // 将线程优先级设定为低于一般标准 t.setPriority(Thread.NORM_PRIORITY-1); // 将线程的优先级设定为低于当前线程 t.setPriority(Thread.currentThread().getPriority() - 1); // 不需等待I/O 的线程应该要明确地让出CPU,以让其他具有相同优先 // 级的线程有机会运行 Thread t = new Thread(new Runnable() { public void run() { for(int i = 0; i < data.length; i++) { // 逐一处理一组数据 process(data[i]); // 加以处理 if ((i % 10) == 0) // 但在每处理10 个后,就暂 Thread.yield(); // 停以让其他线程运行 } } }); 处理未被捕获的异常 线程通常会在到达run() method终点或执行到那个method 中的return语句时终止。 但是,线程也可以通过抛出异常来终止。当线程以这种方式结束时,默认的行为就是列 出线程的名称、异常类型、异常信息以及堆栈追踪。在Java 5.0 中,你可以对线程中未 被捕获的异常安装自定义的处理程序。例如:
// 此线程正好抛出一个异常
Thread t = new Thread() {
public void run() {throw new UnsupportedOperationException();}
};
// 给线程一个名称以帮助调试
t.setName("My Broken Thread");
// 这是针对错误的处理程序
t.setUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
public void uncaughtException(Thread t, Throwable e) {
System.err.printf("Exception in thread %d '%s':" +
"%s at line %d of %s%n",
t.getId(), // 线程id
t.getName(), // 线程名称
e.toString(), // 异常名称与信息
e.getStackTrace()[0].getLineNumber(), // 行号
e.getStackTrace()[0].getFileName()); // 文件名
}
});
使线程休眠 通常,线程被用来执行一些固定间隔时间的重复工作。在进行牵涉到动画或类似效果的 图形程序设计时更是如此。做到这个操作的关键就是让线程在特定的一段时间休眠或停 止运行。这可以用静态的Thread.sleep() method 做到,或者在Java 5.0 中可以用 TimeUnit 类的列举常量的实用程序method:
import static java.util.concurrent.TimeUnit.SECONDS; // 实用程序类
public class Clock extends Thread {
// 此字段是易变的,因为两个不同的线程会访问它
volatile boolean keepRunning = true;
public Clock() { // 构造函数
setDaemon(true); //daemon 线程:解释器可以在它运行时跳出
}
public void run() { // 线程主体
while(keepRunning) { // 此线程会运行直到被要求停止为止
long now = System.currentTimeMillis(); // 取得当前时间
System.out.printf("%tr%n", now); // 输出当前时间
try { Thread.sleep(1000); } // 等待1000 毫秒
catch (InterruptedException e) { return; } // 在中断时结束
}
}
// 要求线程停止运行。这是interrupt()的替代方案
public void pleaseStop() { keepRunning = false; }
// 此method 示范如何使用Clock 类
public static void main(String[] args) {
Clock c = new Clock(); // 创建Clock 线程
c.start(); // 激活它
try { SECONDS.sleep(10); } // 等待10 秒
catch(InterruptedException ignore) {} // 忽略中断
// 现在停止 clock thread。我们也可以使用 c.interrupt()
c.pleaseStop();
}
}
请注意此范例中的pleaseStop() method:它被设计来以可控制的方式来停止时钟线 程。此范例被编写为可以通过调用从Thread 继承来的interrupt() method 来停止。 Thread 类定义了stop() method,但不建议使用。
运行与安排任务 Java 提供了一些方法,可以在无需显式地创建Thread 对象的情况下,异步地执行任务 或安排它们以供将来执行。接下来的章节介绍Java 1.3 中增加的Timer 类和Java 5.0 的java.util.concurrenct 包的执行者(executor)框架。 使用Timer 安排工作 在Java 1.3 中加入的java.util.Timer 和java.util.TimerTask 类使得重复任务的 执行变得容易。这有一些程序代码的行为与先前显示的Clock 类非常像:
import java.util.*;
// 定义显示时间的任务
TimerTask displayTime = new TimerTask() {
public void run() { System.out.printf("%tr%n",
System.currentTimeMillis()); }
};
// 创建timer 对象来执行此任务(或其他任务)
Timer timer = new Timer();
// 现在将那个任务定为每1000 毫秒执行一次,就从现在开始
timer.schedule(displayTime, 0, 1000);
// 停止显示时间的任务
displayTime.cancel();
Executor 接口 在Java 5.0 中,java.util.concurrent 包包含了Executor interface。Executor是 个可以执行Runnable对象的对象。Executor的使用者通常不需要知道Executor完 成工作的方法:它只需要知道Runnable会在某个时间点执行。创建Executor实现可 以使用一些不同的线程策略,从以下程序代码中可较清楚地得知(请注意,此范例也示 范了BolckingQueue 的用法)。
import java.util.concurrent.*;
/** 在当前线程中执行Runnable。 */
class CurrentThreadExecutor implements Executor {
public void execute(Runnable r) { r.run(); }
}
/** 使用新创建的线程来执行各个Runnable */
class NewThreadExecutor implements Executor {
public void execute(Runnable r) { new Thread(r).start(); }
}
/**
* 创建一个线程来排列Runnable 并依序加以执行
*/
class SingleThreadExecutor extends Thread implements Executor {
BlockingQueue<Runnable> q = new LinkedBlockingQueue<Runnable>();
public void execute(Runnable r) {
// 这里不执行Runnable,只是把它放入队列
// 我们的队列是不受限的,所以应该不会阻塞
// 由于它不会阻塞,所以绝不会抛出InterruptedException
try { q.put(r); }
catch(InterruptedException never) { throw new AssertionError(never); }
}
// 这是实际执行了Runnable 的线程主体
public void run() {
for(;;) { // 无限循环
try {
Runnable r = q.take(); // 取得下一个Runnable 或等待
r.run(); // 运行!
}
catch(InterruptedException e) {
// 如果被中断,就停止执行已排入队列的Runnable
return;
}
}
}
}
这些示例实现帮助说明Executor运作的方法以及它分隔由安排策略执行任务及线程实 现细节的方法。但是, 很少有必要真的实现你自己的E x e c u t o r , 因为 java.util.concurrent提供了有灵活性且强大的ThreadPoolExecutor类。此类通 常会通过Executor 类中的静态factory method 来使用:
Executor oneThread = Executors.newSingleThreadExecutor();// 1 的池的大小 Executor fixedPool = Executors.newFixedThreadPool(10); // 池中有10 个线程 Executor unboundedPool = Executors.newCachedThreadPool();// 要多少有多少
除了这些方便的factory method 之外,如果你想指定线程池的最小与最大的大小或想针
对不会被线程立即执行的任务来指定队列类型(例如有限制的、无限制的、依优先级排
序或同步化)以供使用,也可以显式地创建ThreadPoolExecutor。
ExecutorService
如果你查看了ThreadPoolExecutor 或以上Executor factory method 所引用的签名,
就会知道它是个ExecutorService。ExecutorService interface 扩展了Executor,
并加上了执行Callable对象的能力。Callable与Runnable很像,但是Callable不
是随意把程序代码封装在run() method 中,而是把程序代码放在call() method 中。
call()与run()有两个地方非常不同:它会返回一个结果,而且允许抛出异常。
因为call()会返回一个结果,所以Callable interface 会接收结果的类型作为参数。
例如,计算大质数的耗时程序块可以被封装在Callable
import java.util.concurrent.*;
import java.math.BigInteger;
import java.util.Random;
import java.security.SecureRandom;
/** 这是针对计算大质数的Callable实现 */
public class RandomPrimeSearch implements Callable<BigInteger> {
static Random prng = new SecureRandom(); // self-seeding
int n;
public RandomPrimeSearch(int bitsize) { n = bitsize ; }
public BigInteger call() { return BigInteger.probablePrime(n, prng); }
}
当然,你可以直接调用任一个Callable对象的call() method,但如果要执行,则要
用ExecutorService把它传递给submit() method。因为ExecutorService实现通
常会以异步方式执行任务,所以submit() method 不可以只返回call() method 的结
果。submit() method会返回Future对象。Future只是对未来某个时间的结果承诺,
它是对结果的类型来参数化,如以下程序代码片段所示:
// 尝试同时计算两个质数
ExecutorService threadpool = Executors.newFixedThreadPool(2);
Future
BigInteger product = p.get().multiply(q.get()); 请注意,get() method 可能会抛出ExecutionExecption。应记住Callable.call() 可以抛出任何种类的异常。如果这个状况发生了,Future 就会把那个异常封装在 ExecutionExcetion中并从get()将它抛出。请注意,Future.isDone() method 会 把Callable 想成是“已完成(done)”,即使call() method 是因为有异常而不正常 终止。 ScheduledExecutorService ScheduledExecutorService是ExecutorService的扩展,它增加了类似Timer 的 进度安排能力。它能让你将Runnable 或Callable安排为延迟一段指定时间之后执行 或把Runnable安排为重复执行。在各种情况下,针对未来执行的进度安排工作的结果 就是ScheduledFuture对象。Future也实现了Delay interface并提供了getDelay() method,可以用来查询在任务开始之前的剩余时间。 取得ScheduledExecutorService 的最简单方法就是使用Executor 类的factory method。以下程序代码使用ScheduledExecutorService来重复执行一个动作,也在 固定时间间隔之后取消重复的动作。
/**
* 以每秒cps 个字符的速度输出随机ASCII 字符,总
* 共持续totalSeconds 秒
*/
public static void spew(int cps, int totalSeconds) {
final Random rng = new Random(System.currentTimeMillis());
final ScheduledExecutorService executor =
Executors.newSingleThreadScheduledExecutor();
final ScheduledFuture<?> spewer =
executor.scheduleAtFixedRate(new Runnable() {
public void run() {
System.out.print((char)(rng.nextInt('~' - ' ') + ' '));
System.out.flush();
}
},
0, 1000000/cps, TimeUnit.MICROSECONDS);
executor.schedule(new Runnable() {
public void run() {
spewer.cancel(false);
executor.shutdown();
System.out.println();
}
},
totalSeconds, TimeUnit.SECONDS);
}
互斥与锁 在使用多线程时,如果你允许多个线程访问同一个数据结构,就必须非常小心。考虑一 下,当一个线程正试着逐一处理List 中的元素时,而另一个线程正在排序那些元素, 这样会发生什么事。预防这类有害的并行操作是多线程计算的主要问题之一。避免两个 线程同时访问同一个对象的基本技巧,就是要求线程必须先取得对象的锁,才能加以修 改。当任一个线程占有锁时,另一个请求得到锁的线程就必须等待,直到第一个线程完 成任务并释放锁。每个Java 对象都有基本功能来提供这样的锁定能力。 要让对象具有线程安全性的最简单方式就是把所有具有敏感性的m e t h o d 声明为 synchronized。线程必须取得对象的锁才可以执行它的synchronized method,这代 表其他的线程都不可以同时执行任何其他的synchronized method(如果static method 被声明为synchronized,线程就必须取得类的锁且以相同的方式运作)。如果 要做到较精细的锁定,你可以指定在短时间内占有指定对象的锁的synchronized程序代 码块:
// 此method 在synchronized 块中交换两个数组元素
public static void swap(Object[] array, int index1, int index2) {
synchronized(array) {
Object tmp = array[index1];
array[index1] = array[index2];
array[index2] = tmp;
}
}
// java.util 中的Collection、Set、List 和Map 的实现不具
// 有synchronized method(除了原有的Vector 和Hashtable
// 实现)。在处理多线程时,可以取得同步的封装程序
// 的对象
List synclist = Collections.synchronizedList(list);
Map syncmap = Collections.synchronizedMap(map);
java.util.concurrent.locks 包 请注意,当你使用synchronized 修饰符或语句时,你所要求的锁是作用在块内,当线 程离开method或块时,它就会被自动释放。Java 5.0中的java.util.concurrent.locks 包提供了替代方案:你可以用Lock 对象显式地锁定与开锁。Lock 对象不会自动以块 为作用范围,你必须小心使用try/finally 结构来确保锁一定会被释放。另一方面, Lock 使得只运用以块为作用范围的锁无法达到的算法成为可能,例如以下的“交叉前 进(hand-over-hand)”链接列表追踪:
import java.util.concurrent.locks.*; // New in Java 5.0
:多个线程可以同时追踪
* 列表的不同部分
**/
public void append(E value) {
LinkList<E> node = this; // 从this 节点开始
node.lock.lock(); // 锁定它
// 循环处理,直到发现列表中的最后一个节点
while(node.rest != null) {
LinkList<E> next = node.rest;
// 这是交叉前进的部分。锁定下一个节点,然后释放
// 当前节点的锁。我们使用try/finally 结构,以
// 让当前节点即使在对下一个节点的锁定因为异常
// 而失败时仍能释放锁
try { next.lock.lock(); } // 锁定下一个节点
finally { node.lock.unlock(); } // 释放当前节点的锁
node = next;
}
// 在这时,此节点是列表中的最后一个节点,我们
// 对它做锁定。使用try/finally 来确保释放锁
try {
node.rest = new LinkList<E>(value); // 添加新节点
}
finally { node.lock.unlock(); }
}
}
死锁 当你使用锁定来预防线程同时访问同一个数据时,就必须小心避免死锁,这会发生在当 两个线程互相等待对方释放它们所需的锁时。由于两者都无法继续,也没有任何一方会 释放所占有的锁,所以它们都会停止运行。以下程序代码有发生死锁的倾向。死锁是否 发生会随系统而异,也会随每次执行而异。
// 当两个线程试图锁定两个对象时,死锁就能发生,除
// 非它们都是以相同顺序要求锁
final Object resource1 = new Object(); // 这有两个要锁定的对象
final Object resource2 = new Object();
Thread t1 = new Thread(new Runnable() { // 先锁定resource1,然后锁定resource2
public void run() {
synchronized(resource1) {
synchronized(resource2) { compute(); }
}
}
});
Thread t2 = new Thread(new Runnable() { // 先锁定resource2,然后锁定resource1
public void run() {
synchronized(resource2) {
synchronized(resource1) { compute(); }
}
}
});
t1.start(); // 锁定resource1
t2.start(); // 锁定resource2,现在两个线程都无法进行!
协调线程 在多线程程序设计中,要求一个线程等待另一个线程来采取某些操作是很常见的。Java 平台提供了一些方法来协调线程,其中包括了内置于Object和Thread 类的method 以 及Java 5.0 中引入的“synchronizer”实用程序类。 wait()与notify() 有时线程必须停止运行并等待,直到某个事件发生,在那之后它会被告知继续运行。这 可以用wait()和notify() method 来实现。但是,这些不是Thread 类的method,它 们是Object 的method。就和每个Java 对象都有与其相关联的锁一样,每个对象都可 以维持等待线程列表。当线程调用对象的wait() method时,线程所占有的每一个锁都 会被暂时释放,而线程会被加到那个对象的等待线程列表并停止运行。当另一个线程调 用同一个对象的notifyAll() method时,对象就会唤醒等待的线程并允许它们继续运 行:
import java.util.*;
/**
* 一个队列。有个线程会调用push()来把一个对象插入队列。
* 另一个线程会调用pop()将对象从队列取出。如果没有数据,pop()就
* 会等待,直到有数据为止。这里所使用的是wait()/notify()。
* wait()和notify()必须被使用在synchronized method 或程序块中。在Java 5.0
* 中,要用java.util.concurrent.BlockingQueue 来代替
*/
public class WaitingQueue<E> {
LinkedList<E> q = new LinkedList<E>(); // 存储对象的地方
public synchronized void push(E o) {
q.add(o); // 将对象添加到列表的末尾
this.notifyAll(); // 告诉等待中的线程,数据已准备好
}
public synchronized E pop() {
while(q.size() == 0) {
try { this.wait(); }
catch (InterruptedException ignore) {}
}
return q.remove(0);
}
}
请注意,这样的类在Java 5.0 中是不必要的,因为java.util.concurrent 定义了 BlockingQueue interface 和例如ArrayBlockingQueue 这样的一般用途的实现。 等待指定条件 Java 5.0 为对象的wait()和notifyAll() method 提供了替代方案。java.util. concurrent.locks 定义了具有await()和signalAll() method 的Condition 对 象。Condition对象一定会与Lock 对象相结合,而且在用法上与置于每个Java 对象内 的锁定和等待能力大都相同。它的主要用途就是让每个Lock 具有多个Condition 成 为可能,这在使用基于对象的锁定和等待时是不可能的。 等待线程完成 有时一个线程必须停止并等待另一个线程完成。你可以用join() method 来完成:
List list; // 要被排序的详细列表;已在其他地方初始化
// 定义线程来排序列表:降低其优先级,以让它只
// 有在当前线程在等待I/O 时才开始运行
Thread sorter = new BackgroundSorter(list); // 先前已定义
sorter.setPriority(Thread.currentThread.getPriority()-1); // 降低优先级
sorter.start(); // 开始排序
// 同时,在原先的线程中从文件中读取数据
byte[] data = readData(); // 在其他地方定义的method
// 在能继续处理之前,列表需已被彻底排序,所以如果sorter 线程
// 还没完成,则我们必须等它结束
try { sorter.join(); } catch(InterruptedException e) {}
同步化实用程序 java.util.concurrent包含了四个“同步化程序(synchronizer)”类,能通过让线程 等待直到出现指定条件为止来同步化并行程序的状态:
Semaphore Semaphore类摸拟了信号量(semaphore),是传统的并行程序设计结构。概念上, semaphore 代表了一个或多个“许可证”(permit)。需要许可证的线程会调用 acqure(),接着在使用完时调用release()。如果没有可用的许可证,acquire() 就会停止以使线程暂停,直到另一个线程释放许可证为止。 CountDownLatch 闩(latch)在概念上是任一个具有两种可能状态而且从初始状态到最终状态只会变 换一次的变量或并行结构。一旦变换发生, 就会永久保持在最终状态。 CountDownLatch是个并行实用程序,它可以存在两种状态:关闭与开启。在初始 的关闭状态中,调用await() method 的线程会暂停而且不能继续处理,直到变 换为闩开启状态为止。一旦此变换发生,所有等待中的线程就会继续处理,所有将 来调用await()的线程不会被暂停。从关闭到开启的变换发生于对countDown() 调用指定次数时。 Exchanger E x c h a n g e r 是个实用程序,能让两个线程会合并交换一些值。第一个调用 exchange() method 的线程会暂停,直到有第二个线程调用了相同的method。当 这个情况发生时,由第一个线程传递给exchange() method 的自变量,就会变成 第二个线程的method 的返回值,反之亦然。当两个exchange()调用返回时,这 两个线程都能随意继续并行运行。Exchanger是generic 类型且使用其类型参数来 指定要被交换的值的类型。 CyclicBarrier CyclicBarrier是个实用程序,能让N个线程的组互相等待以达到同步化的时刻。 线程的数量是在CyclicBarrier第一次被创建时所指定的。线程会调用await() method 来暂停,直到最后一个线程调用await(),所有的线程在那个时刻都会再 次继续。与CountDownLatch不同的是,CyclicBarrier 会重设其计数值,并且 可以立即被再次使用。CyclicBarrier在并行算法中很有用,并行算法中的计算 会被分为许多部分,每个部分都会由独立的线程处理。在这样的算法中,线程通常 必须会合,以让它们的部分解答能合并为完整的解答。为了使这样的操作较为容 易,CyclicBarrier构造函数允许你指定最后一个线程所要执行的Runnable对 象,它会在其他线程被唤醒并重新运行之前先调用await()。此Runnable可以 提供从各线程的计算组合出解答所需的协调,或指定新的计算给各个线程。 线程中断 在说明sleep()、join()和wait() method 的范例中,你或许注意到,对这些method 的调用都是被封装在捕获InterruptedException 的try 语句中。这是必要的,因为 interrupt() method能让一个线程中断另一个线程的运行。中断的结果取决于你处理 InterruptedException的方法,一般对于被中断的线程较好的响应是停止运行。另一 方面,如果你只是捕获并忽略InterruptedException,中断就仅只是停止线程,而不 是暂停。 如果interrput() method 是在未被暂停的线程上被调用,线程就会继续运行,但它的 “ 中断状态” 会被设定, 以指出已有请求被中断。线程可以通过调用静态的 Thread.interrupted() method 来测试它自己的中断状态,如果线程已被中断就会返 回true,但副作用就是会清除中断状态。线程可以用isInterrupted()这个instance method 来测试另一个线程上的中断状态,此method 会查询状态,但不会加以清除。 如果线程在中断状态被设定时调用sleep()、join()或wait(),那么它不会被冻结, 而是立即抛出InterruptedException(中断状态会因为抛出异常所造成的副作用而被 清除)。同样地,如果调用interrupt() method 的线程已在对sleep()、join()或 wait()的调用中被冻结,那个线程就会因为抛出InterruptedException而不再被冻 结。 线程冻结的最常见情况之一,就是在进行输入/ 输出时,线程通常必须暂停并等待来自 文件系统或网络的数据(用来执行I/O 操作的java.io、java.net以及java.nio API 会在本章稍后讨论)。很不幸的是,interrupt() method 不会唤醒冻结在java.io 包 的I/O method 中的线程。这是java.io 的缺点之一,已通过java.nio 的New I/O API修正。如果线程在执行任一实现了java.nio.channels.InterruptibleChannel 信道上的I/O 操作时被中断,信道就会关闭,线程的中断状态会被设定,而且线程会通 过抛出java.nio.channels.ClosedByInterruptException被唤醒。如果线程在中 断状态已被设定时试图调用阻塞式I/O method,就会发生相同的事情。同样地,如果线 程在被冻结在java.nio.channels.Selector 的select() method 中时被中断(或 是在其中断状态已被设定时调用select()),select()就会停止冻结(或永不启动) 并立即返回。在这样的情况下,不会有异常被抛出;被中断的线程会醒来,而select() 调用会返回。 阻塞式队列 就如本章前面的“Queue与BlockingQueue接口”一节中所提到的,队列是个collection, 其中的元素会在“尾端”被插入并在“前端”被移除。Queue interface 和各种实现被 加入java.util 作为Java 5.0 的一部分。java.util.concurrent 扩展了Queue interface:BlockingQueue 定义了put()和take() method,能让你增加或移除队列 的元素,它在有必要时会被冻结,直到队列有空间或有元素可被移除为止。阻塞式队列 在多线程程序设计中常被使用:一个线程产生了一些对象并把它们放在队列中以供另一 个队列消耗—— 将那些对象从队列移除。 java.util.concurrent 提供了五个BlockingQueue 的实现: ArrayBlockingQueue 此实现是以数组为基础,而且就和所有的数组一样,具有在创建时就已建立的固定 能力。以降低总处理能力为代价,此队列可在“尚可”模式中操作,线程会因put() 或take()而被冻结,元素的取用是依它们到达的顺序。 LinkedBlockingQueue 此实现是以链接列表数据结构为基础。它可以有指定的最大大小,但按照默认,它 实际上是无限的。 PriorityBlockingQueue 此无限队列没有实现FIFO(先进先出)顺序,而是以指定Comparator 对象为基 础来排序其元素,或者如果它们是Comparable对象而且没有被指定Comparaotr 时,就是以它们的自然顺序为基础。由take()返回的元素是依据Comparator或 Comparable 排序的最小元素。关于非阻塞的版本,请参阅java.util. PriorityQueue。 DelayQueue DelayQueue就像PriorityBlockingQueue,但元素实现了Delayed interface。 Delayed是Comparable而且依元素被延迟的时间来排序,但DelayQueue只是个 对元素排序的无限队列。它也限制了take()和相关的method,以让元素要到延 迟时间已过时才能从队列中被移除。 SynchronousQueue 此类实现了具有能力为零的BlockingQueue 的退化状况。对put()的调用会冻 结,直到有其他的线程调用了take(),并且此时对take()的调用会冻结,直到 有其他线程调用put()。 atomic 变量 java.util.concurrent.atomic包包含了实用程序类,能在不锁定的情况下在字段上 进行原子操作(atomic operation)。原子操作是不可分割的操作:其他的线程无法看到 在原子操作中的atomic 变量。这些实用程序类定义了get()和set()访问method,它 们具有volatile 字段的特性,但也定义了如“比较与设定(compare-and-set)”和“取 得与递增(get-and-increment)”这样行为上的一个原子的复合操作。以下的程序代码示 范了AtomicInteger 的用法,并与传统synchronized method 的用法作了对比:
// count1()、count2()和count3()都是具有线程安全性的。两个
// 线程可以同时调用这些method,而且它们绝不会看到相同的返回值
public class Counters {
// 这个计数器使用了synchronized method 和锁定
int count1 = 0;
public synchronized int count1() { return count1++; }
// 这个计数器使用了在AtomicInteger 上的单元递增
AtomicInteger count2 = new AtomicInteger(0);
public int count2() { return count2.getAndIncrement(); }
// 这个乐观的计数器使用了compareAndSet()
AtomicInteger count3 = new AtomicInteger(0);
public int count3() {
// 使用get()来取得计数器值,并使用compareAndSet()加以设定
// 如果compareAndSet()返回false,就再试一下,直到我们在没有
// 阻塞的情况下处理完循环
int result;
do {
result = count3.get();
} while(!count3.compareAndSet(result, result+1));
return result;
}
}
async await https://stackoverflow.com/questions/17250047/how-is-async-with-await-different-from-a-synchronous-call#/
# 状态机
同步状态机 异步状态机 https://blog.the-pans.com/state-machine-and-sync/#/ https://www.volcengine.com/theme/9743656-C-7-1#/
https://www.volcengine.com/theme/8113445-R-7-1#/
# 3.系统和框架层面的并发限制
# IO的高并发发展
参考 BIO/NIO/多路复用/NETTY 100万级连接,爱奇艺WebSocket网关如何架构 (opens new window)
# 其他
比如linux句柄数 执行ulimit –n检查文件句柄数为1024,将该数值改为10240 /etc/security/limits.con
从框架层面可以参考我在network一文中的一个案例### 4.2 一次排查send-q
CopyRight 刘跃 LYHISTORY.COM
ref: