回目录 《网络基础》
# 导读
计算机网络是节点和链路的集合,可以为两个或多个特定节点建立连接,以在这些节点之间进行通信:
- 按网络物理拓扑结构分类 网络拓扑结构是指网络中节点(设备)和链路(连接网络设备的信道)的几何形状,常见:总线型、星型、环型、树型、网型和混合型
- 按网络逻辑拓扑结构分类 网络结构经历了二层网络架构、三层网络架构以及最近兴起的大二层网络架构。
- 按网络的覆盖范围分类 局域网(LAN - Local Area Network) 城域网(MAN - Metropolitan Area Network) 广域网(WAN - Wide Area Network) 和 因特网(Internet)
工作模式:
- 基于服务器的网络(Server based)
- 对等网络(Peer to Peer network)
网络分层(本文前半部分的重点): 必读: <《图解TCP IP(第5版)》.((日)竹下隆史).[PDF].&ckook>
主要参考: A beginner's guide to network troubleshooting in Linux (opens new window)
Terminology guide (opens new window)
Common Port Numbers (opens new window)
# 1.网络分层 TCP/IP协议组
Open Systems Interconnection model (OSI model) is a conceptual model that characterises and standardises the communication functions of a telecommunication or computing system without regard to its underlying internal structure and technology.
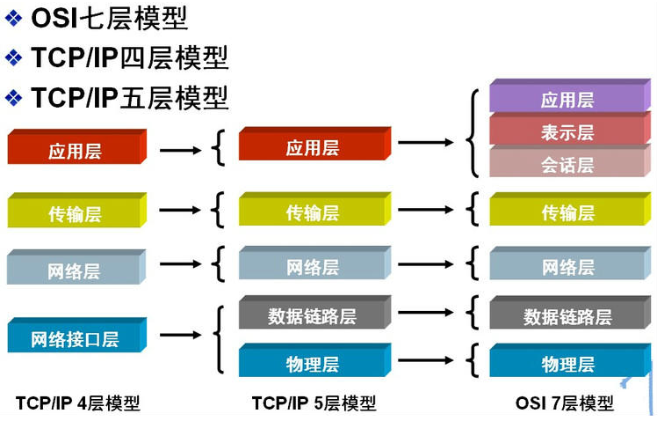
网上找到这张图还不错,OSI Model和TCP/IP Model对应关系图:
OSI七层是抽象的模型,而TCP/IP四层或五层是比较具体的协议;
五层模型
- Layer 5: Application FTP、HTTP、HTTPS、websocket、P2P, TELNET、SMTP、DNS等协议; 金融FIX协议;
- Layer 4: Transport TCP协议与UDP协议
- Layer 3: Network/Internet IP协议、ICMP协议、RIP,OSPF,BGP,IGMP,VXLAN
- Layer 2: Data Link SLIP,CSLIP,PPP,ARP,RARP,MTU,VLAN
- Layer 1: Physical ISO2110,IEEE802。IEEE802.2
OSI七层网络模型中:物理层,数据链路层和网络层是低三层网络,其余四层是高三层网络,其中二层网络指的就是数据链路层,三层网络指的就是网络层
注意:websocket是完整的应用层协议,所以不会访问raw tcp packets,但是常用的socket是可以的,因为它是基于应用层和传输层的抽象,并不是一个协议
七层模型:
- Layer 7: Application layer(HTTP)
- Layer 6: Presentation layer (none in this case)
- Layer 5: Session layer (SSL/TLS)
- Layer 4: Transport layer (TCP)
- Layer 3: Network layer (IPv4)
- Layer 2: Data link layer (ethernet)
- Layer 1: Physical layer (network cable / wifi)
# 1.0 数据通信流程
什么是数据网络(Data Network)?简单地说,数据网络就是一个由各种设备搭建起来的一张网,常见的设备有:路由器、交换机、防火墙、负载均衡器、IDS/IPS、VPN服务器等等。数据网络最基本的功能就是实现不同节点之间的数据互通,也就是数据通信。
TCP/IP模型是当今IP网络的基础(也被称为DoD模型),它将整个数据通信的任务划分成不同的功能层次(Layer),每一个层次有其所定义的功能,以及对应的协议。打个比方,对于一家公司而言,一笔业务需要各个部门相互协同工作才能完成,部门与部门之间既相互独立,但是又需要相互配合,可以借用这种思路来理解TCP/IP参考模型。分层参考模型的设计是非常经典的理念:
- 层次化的模型设计将网络的通信过程划分为更小、更简单的部件,因此有助于各个部件的独立开发、设计和故障排除;
- 层与层之间相互独立,又互相依赖,每一层都有该层的功能、以及定义的协议标准。层层之间相互配合,共同完成数据通信的过程;
- 通过组件的标准化,允许多个供应商进行开发;
- 通过定义在模型的每一层实现什么功能,鼓励产业的标准化;
- 允许各种类型的网络硬件和软件相互通信。
# 理解数据通信过程
参考 利用 TCP IP 模型理解数据通信过程 (opens new window) 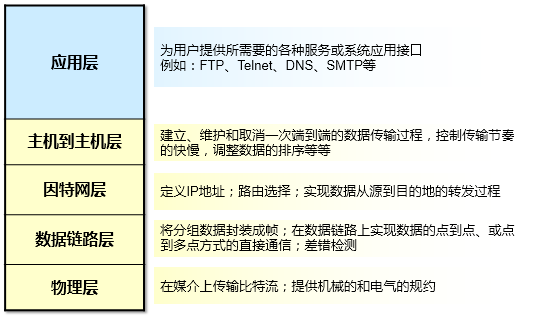 上图我贴出的并不是标准的TCP/IP模型,为了方便下文的阐述,这里给出的是一个TCP/IP模型与OSI模型的对等模型
上图我贴出的并不是标准的TCP/IP模型,为了方便下文的阐述,这里给出的是一个TCP/IP模型与OSI模型的对等模型
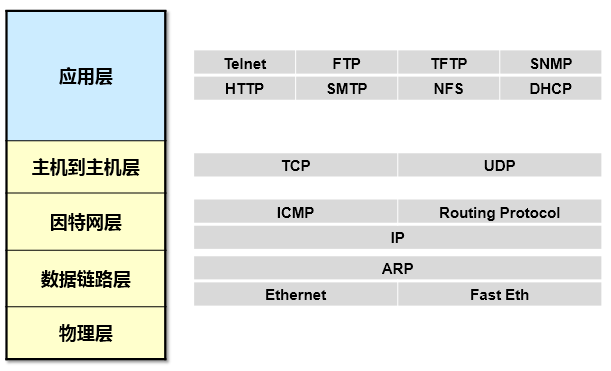 上面这张图显示的就是每个层次对应的代表性协议。
上面这张图显示的就是每个层次对应的代表性协议。
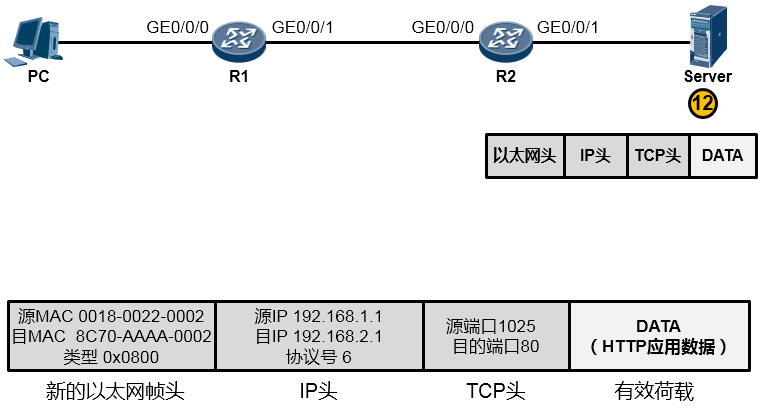
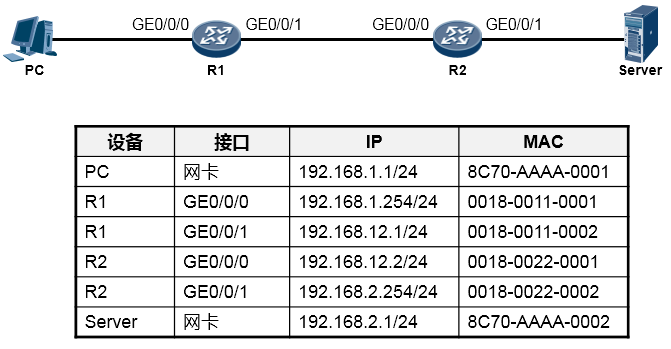 根据上图所示的网络拓扑(Topology),我们来分析一下PC访问Server的WEB服务的详细通信过程。
根据上图所示的网络拓扑(Topology),我们来分析一下PC访问Server的WEB服务的详细通信过程。
在阐述过程中,我们聚焦的重点是利用TCP/IP参考模型理解数据通信过程,因此可能会忽略部分技术细节,例如DNS、TCP三次握手等,这些技术细节这里暂不做讨论。现在你要换一种视野来看待这个“世界”了,想象一下上图所示的终端以及路由器都是一个个的“TCP/IP通信模型”,事实上,整个过程在宏观层面体现如下:
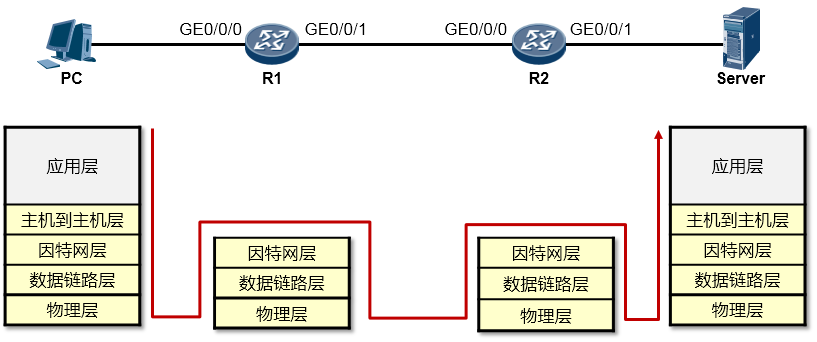
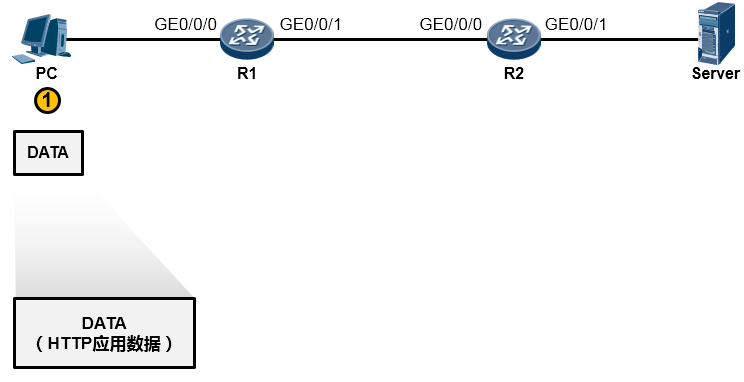
PC的用户在WEB浏览器中访问Server的WEB服务(这里我们暂且不去关注HTTP交互、DNS交互等细节,重点看通信过程),PC的这次操作将触发HTTP应用为用户构造一个应用数据(如下图所示)。当然这个数据最终要传递到Server并“递交”到Server的HTTP应用来处理,但是HTTP不关心数据怎么传、怎么寻址、怎么做差错校验等等,这些事情交由专门的层次来完成,所以HTTP应用数据还需经过一番“折腾”才能从PC传到Server
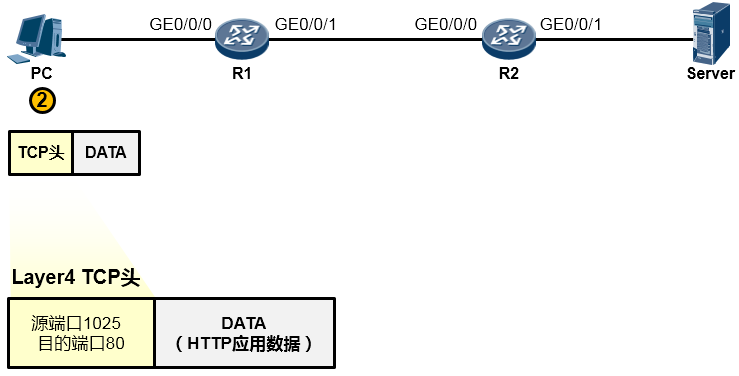
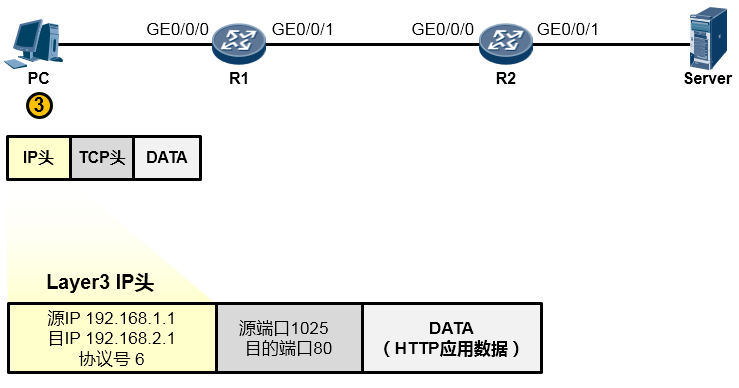
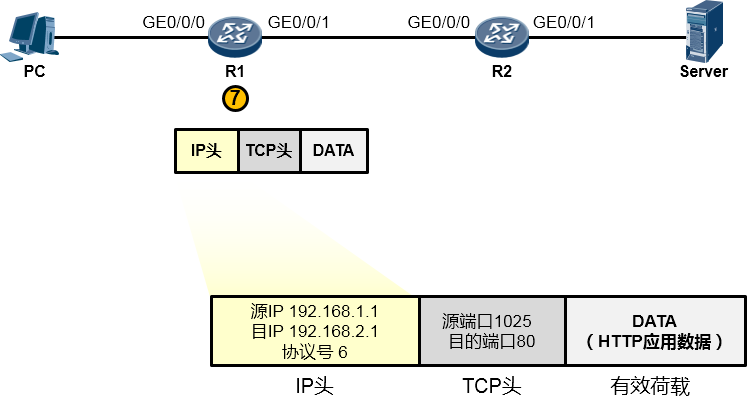
由于HTTP基于TCP,因此这个应用数据交由参考模型中的主机到主机层(第4层)进一步处理。在该层,上层HTTP应用的数据被封装一个TCP的头部(可以简单的理解为套了一个TCP的信封)在TCP头部中我们重点关注两个字段(信封上写的东西),一个是源端口号,另一个是目的端口号,源端口号为随机产生的端口号(是PC本地设置的、专门用于本次会话的端口),目的端口号为80(HTTP服务对应的默认端口号是80),如下图所示。然后这个数据段(Segment)被交给下一个层处理。
下一层是网络层,也叫因特网层(第3层),处于这个层的IP协议为这个上层下来的数据封装一个IP头部(在之前的基础上又套了一个信封,如下图所示),以便该数据能够在IP网络中被网络设备从源转发(路由)到目的地。在IP头当中我们重点关注源IP地址、目的IP地址、协议号这三个字段。其中源地址填写的是PC自己的IP地址192.168.1.1,目的地址存放的是Server的IP地址192.168.2.1,而协议号字段则存放的是值6,这个值是一个众所周知(Well-Known),也就是行业约定的值,该值对应上层协议类型TCP,表示这个IP头后面封装的上层协议为TCP(形象点的描述是,协议字段用于表示这个IP信封里装的是一个TCP的内容)。搞定之后,这个数据被交给下一层处理。
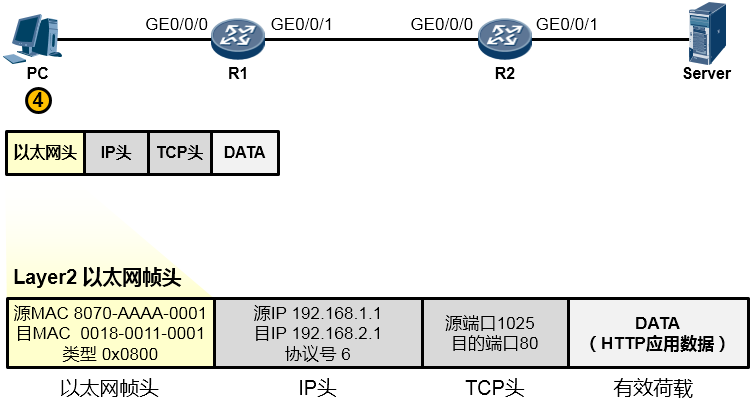
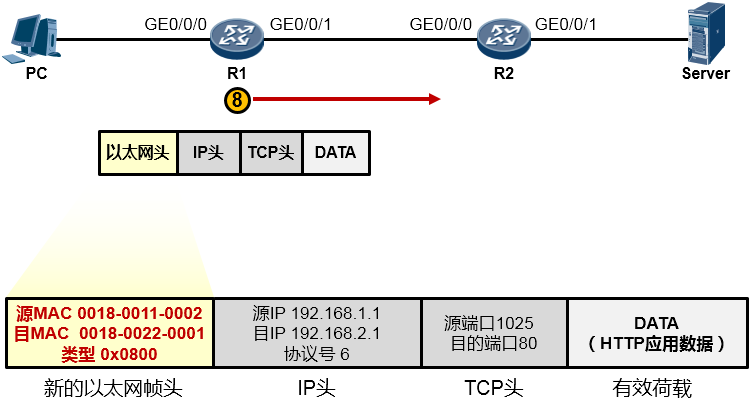
为了让这个IP数据包能够在链路上传输(从链路的一个节点传到另一节点),还要给数据包封装上一个数据链路层(第2层)的头部,以便该数据能够在链路上被顺利传输到对端。由于PC与R1之间为以太网链路,因此上层来的IP数据包被封装一个以太网的数据帧头(再增加一个信封)。这个帧头中写入的源MAC地址为PC的网卡MAC,那么目的MAC呢?PC知道,数据的目的地是192.168.2.1这个IP,而本机IP是192.168.1.1/24,显然,目的地与自己并不在同一个IP网段,因此需要求助于自己的默认网关,让网关来帮助自己将数据包转发出去。那首先得把数据转发到网关吧?因此目的MAC地址填写的就是网关192.168.1.254对应的MAC地址。但是初始情况下,PC可能并不知晓192.168.1.254对应的MAC地址,所以,它会发送一个ARP广播去请求192.168.1.254的MAC,R1的GE0/0/0口会收到这个ARP请求并且回送ARP响应报文。如此一来PC就知道了网关的MAC,它将网关MAC 0018-0011-0001填写在以太网数据帧头部的目的MAC地址字段中。另外,以太网数据帧头的类型字段写上0x0800这个值,表示这个数据帧头后面封装的是一个IP包。费了好大劲儿,这个数据帧(Frame)终于搞定了,如下图所示:
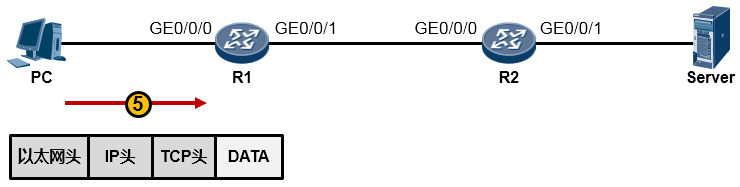
值得一提的是,事实上在物理链路中传输的是比特(bit)流,或者电气化的脉冲型号,只不过为了方便理解和更加直观地分析,我们往往会以IP包或者数据帧的形式来阐述通信过程。所以从物理上说,最终这个以太网数据帧变成了一堆的101110101从网线传到了路由器R1上,如下图所示:
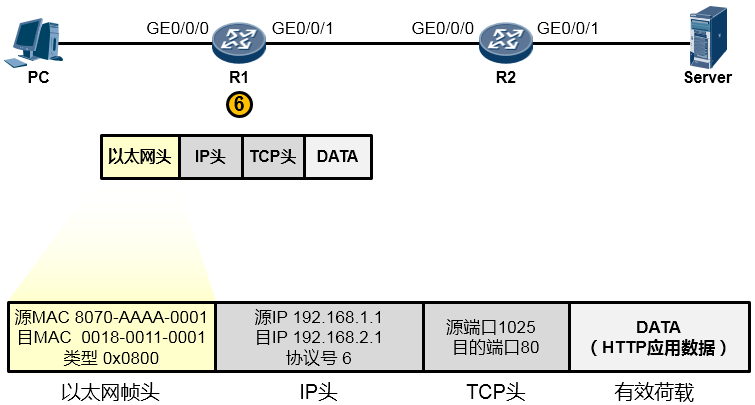
路由器R1在收到这一串的1010…后,先将他们还原成数据帧(如下图所示)。然后会采用相应的机制检查一下数据帧在传输过程中是否有损坏,如果没有损坏,那么就瞅瞅数据帧头部中的目的MAC地址,看看目的MAC地址是不是我收到这个数据帧的GE0/0/0接口的MAC,结果发现正好是自己的MAC,那么它会很高兴,觉得这个数据帧是给它的,它查看数据帧头部的类型字段,发现是0x0800,于是它知道里头装的是一个IP包,接着它将以太网帧头剥去,或者说解封装,然后将里面的数据移交给上层的IP协议继续处理。
现在R1的IP协议栈接着处理这个报文。它会先校验一下数据在传输过程中IP报文有没有受损,如果没有,它就查看IP头中的目的IP地址(如下图所示),结果发现目的IP地址为192.168.2.1,并不是自己的IP地址——原来这个数据包是发给别人的,于是它开始拿着目的地址192.168.2.1到自己的地图(路由表)里去查询,看看有没有到192.168.2.1这个目的地的路径,结果发现有,并且这个路由条目指示它把数据包从从GE0/0/1口送出去,并交给192.168.12.2这个下一跳IP地址。于是它不再继续拆开IP头看里头的东东了,而是乖乖的将IP数据包往下交还给数据链路层去处理。
现在数据链路层继续处理上层下来的IP包,它为这个IP包封装上一个新的以太网帧头,帧头中源MAC地址为R1的GE0/0/1口的MAC:0018-0011-0002,目的MAC是这个数据包即将交给的下一跳路由器192.168.12.2对应的MAC,当然初始情况下R1是不知道这个MAC的,因此又是一轮ARP请求广播及回应过程并最终拿到这个MAC:0018-0022-0001,于是它将这个值填写在目的MAC字段中。完成了新的数据帧封装后(如下图所示),R1把这个数据帧变成1010101…通过电气信号传递给R2。
R2收到这些10101…后,同样的,还是先将其还原成帧,然后查看帧头,发现目的MAC填写的就是自己接口的MAC,并且帧头中类型字段写的是0x0800(指示上层协议是IP,也就是数据帧头内封装的是一个IP包),于是将数据帧头剥去,将里头的IP数据包交给IP协议去处理。
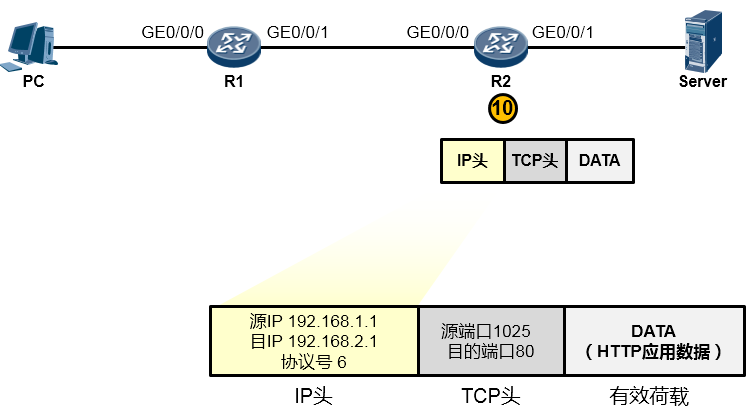
而IP协议在处理过程中发现,目的IP地址并非本路由器的IP(如下图所示),于是它知道这个数据包不是发送给自己的,它拿着目的IP地址192.168.2.1在自己路由表中查询,结果发现,R2的GE0/0/1口就连接着192.168.2.0/24网络,原来家门口就是了,于是它将这个IP包交还给下层协议去处理。
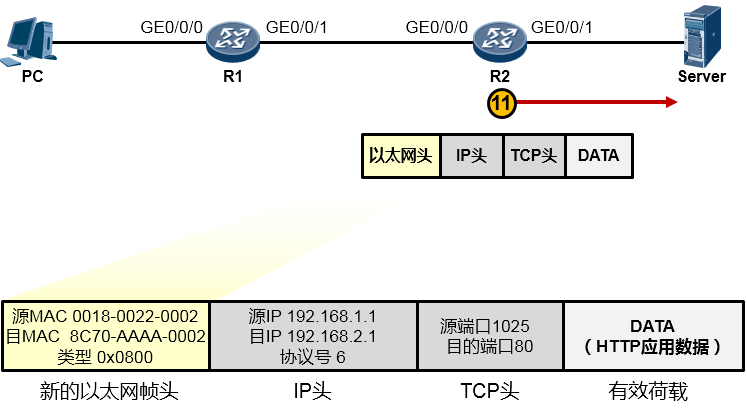
接下来又是重新封装成帧,R2为这个IP包封装一个新的数据帧头部,帧头中,源MAC为R2的GE0/0/1口的MAC,目的MAC为192.168.2.1这个IP地址对应的MAC,如果ARP表里有192.168.2.1对应的MAC,则直接将MAC地址写入目的MAC中,如果没有,则发ARP请求报文去请求该地址。另外类型字段依然填写0x0800。最终,R2将这个数据帧传给了Server,如下图所示:
好不容易,终于数据帧到达了Server(如下图所示)。Server首先将这些比特流还原成帧,然后做校验看看帧是否损坏,如果没有,则查看数据帧的目的MAC,结果发现就是自己的网卡MAC,于是查看类型字段,发现是0x0800,知道这里头装的是一个IP包,于是将帧头剥去,将内层的IP数据包交给IP协议去处理。IP协议层收到这个数据包之后,首先查看IP包是否损坏,如果没有,则查看目的IP地址,发现目的IP地址是192.168.2.1——正是自己的网卡IP,于是它知道,这个IP包是发给自己的,因此继续查看IP包头中的协议字段,发现协议字段填写的是6这个值,原来这个IP包头后面封装的是一个TCP的数据,于是将IP包头剥去,将里头的TCP数据交给上层的TCP协议处理。而TCP在处理这个数据的时候,查看TCP头部的目的端口号,发现目的端口号是80,而Server本地的TCP 80端口是开放的,开放给HTTP应用了,因此它将TCP头部剥去,将里头的载荷交给HTTP应用。终于,从PC发送出来的HTTP应用数据到达了目的地——Server的HTTP应用的手中。
# 理解数据通信过程+一些细节
听了马士兵的关于TCP的讲解,还是感觉挺有收获的,大概总结下整体过程:
用户从应用层发起http get request,比如通过浏览器或者直接通过shell命令
https://www.tldp.org/LDP/abs/html/devref1.html
有一个特殊的文件/dev/tcp,打开这个文件就类似于发出了一个socket调用,建立一个socket连接,读写这个文件就相当于在这个socket连接中传输数据。
1.打开/dev/tcp
以读写方式打开/dev/tcp,并指定服务器名为:www.baidu.com,端口号为:80,指定描述符为8
要注意的是:/dev/tcp本身是不存在的。
exec 8<> /dev/tcp/www.baidu.com/80
2. 向文件中写入数据,向文件中随便写一些数据
echo -e "GET / HTTP/1.0\n" 1>& 8
3. 读文件
cat 0<& 8 或 cat<&8
查看
cd /proc/$$/fd
关闭
exec 8<& -
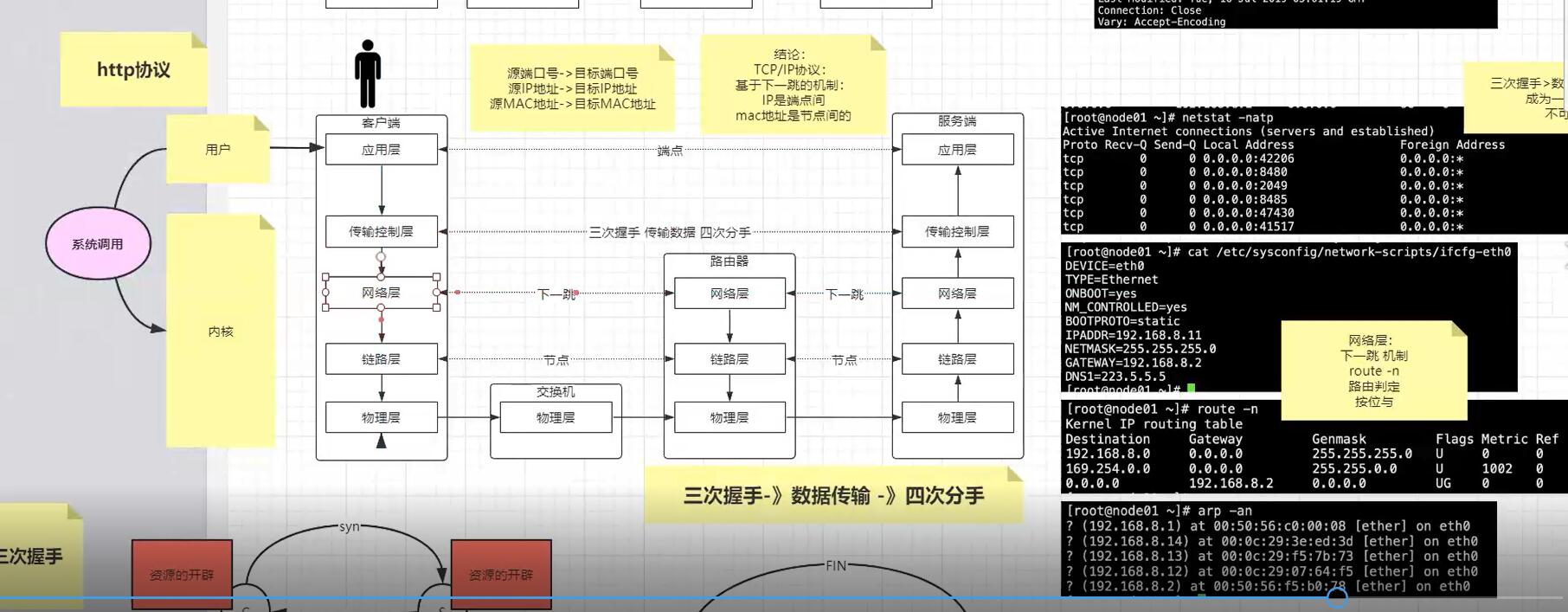
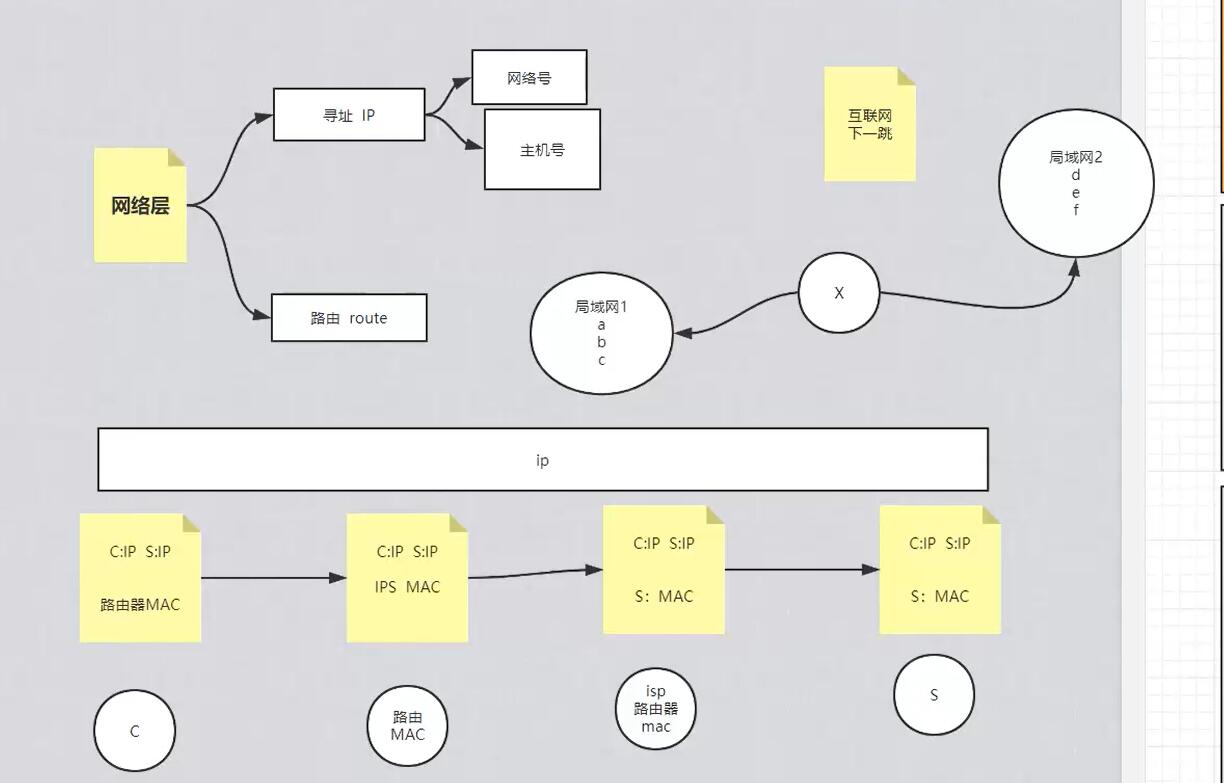
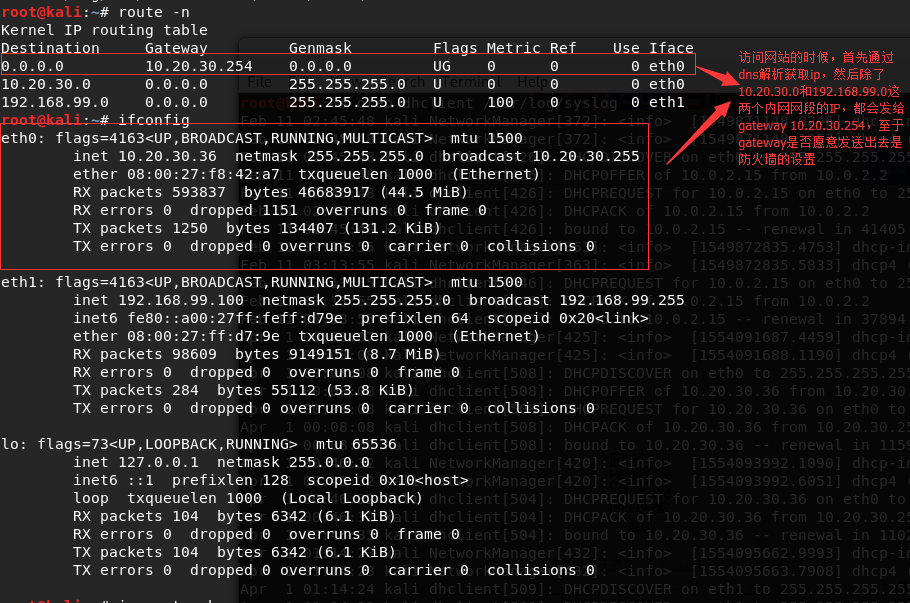
然后系统内核就会一层层往下打包,先打包“传输控制层”,这一层是需要通过三次握手建立连接的, 第一次握手就是发送SYN给服务器端(这里的百度),通过dns获取了百度的IP,TCP socket套接字需要用到local客户端的ip和port以及server端的ip和port,那么具体怎么发送出这第一个包呢,很多人误以为传输层就可以直接发送,其实这个层强调的是传输“控制”层, 所以还需要再下一层,网络层会根据目标ip地址,获取路由地址表(route -n),通过掩码来计算获取到走哪个网关,如果是内网就直接发送,如果是外网则走路由器网关,这就是所谓的下一跳的地址, 但是有个问题,我们是发送给百度服务器的,这里又多了一个下一跳的地址,怎么搞,链路层就是解决这个问题的, 通过arp表找到下一跳对应的mac地址,再包一层,最终通过物理层发送出去;
上面第二张图就很清楚的说明了网络层和链路层的工作过程:
网络层寻址,比如路由表:
| Destination | Gateway | Genmask | Iface |
|---|---|---|---|
| 192.168.1.0 | 0.0.0.0 | 255.255.255.0 | eth1 |
| 0.0.0.0 | 10.20.30.254 | 0.0.0.0 | eth0 |
ping 192.168.1.111; ip是192.168.1.111,掩码是255.255.255.0,与运算结果就是192.168.1.0即网络号,111就是这个网络中的主机号111,然后路由器表中192.168.1.0对应的网关gw是0.0.0.0,意思是直接内网通过eth1网卡发送,
如果我们ping的是21.12.1.1,跟255.255.255.0运算结果是21.12.1.0,第一条不匹配,然后走到第二条,跟0.0.0.0与运算结果匹配Destination 0.0.0.0,所以走网关10.20.30.254出去;
注:What is the meaning of 0.0.0.0 as a gateway? https://unix.stackexchange.com/questions/94018/what-is-the-meaning-of-0-0-0-0-as-a-gateway
链路层的工作过程就是,路由器接收到数据包之后,撕掉上面自己的mac地址,然后贴上下一跳比如isp路由器的mac地址(通过arp表获取),依次下去,直到到达百度服务器或者百度服务器所在局域网上的某个机器比如路由器,然后撕掉发现就是对应自己内网的ip,即可以通过上面说的主机号找到某台服务器;
下面展开说下开发常见的TCP协议,
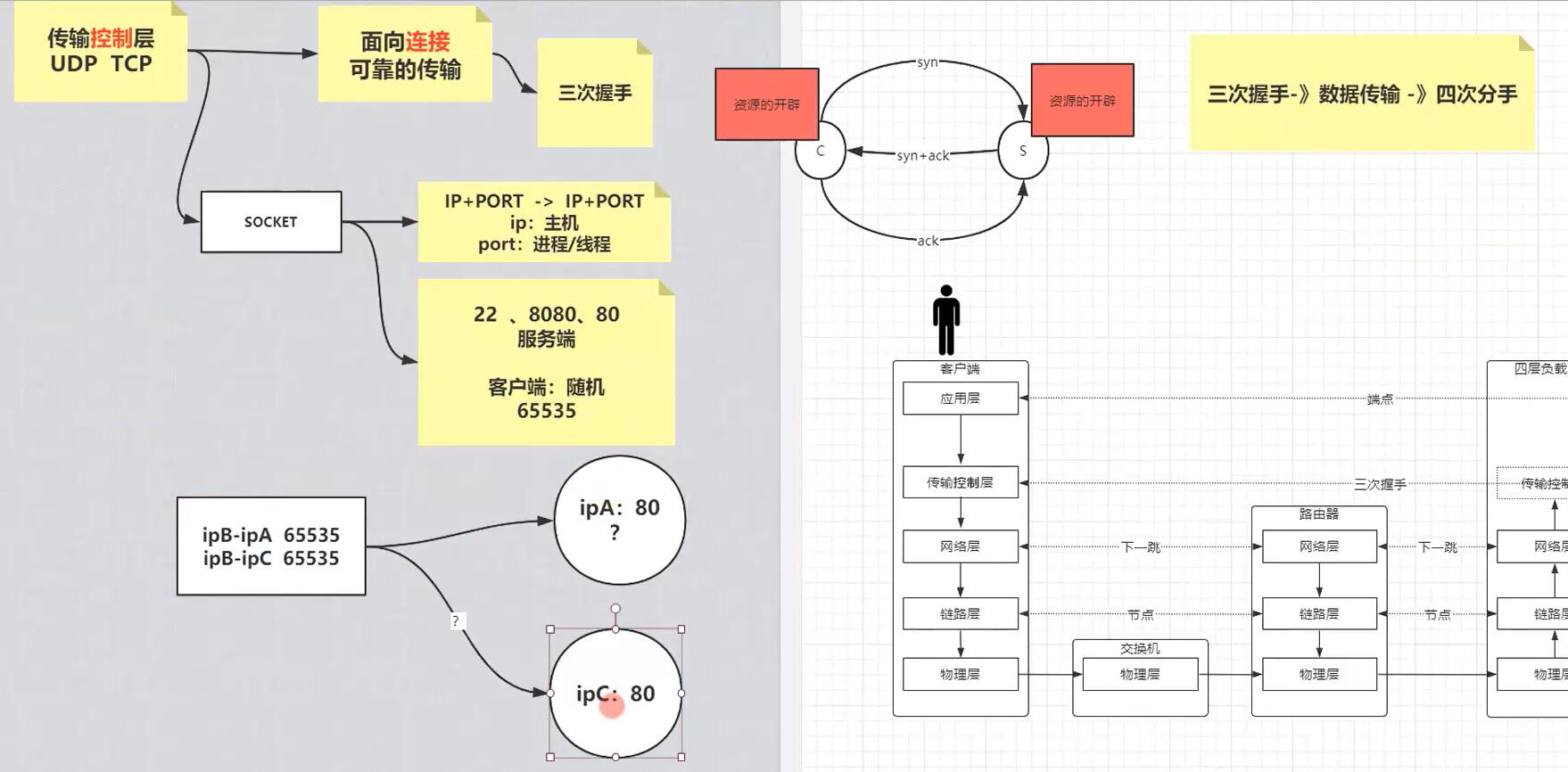
TCP面向连接,三次握手的本质就是,双方(客户端和服务端)都需要确认自己发送的信息对方可以收到,所以精简下来就是三次握手:
第一次客户端发送syn空包给服务端,服务端收到,证明自己可以接收信息,然后返回ack以及syn,这是第二次,客户端收到就可以确认自己可以发送以及接受信息,第三次客户端发送ack,然后服务端收到就可以确认自己可以发送信息;
而socket和资源的开辟大概是这样,比如服务器端起来一个http server,端口是80,我们通过netstat -natp命令会看到有一条处于listen状态的进程,这是代表这个服务开启的主进程(通常是Daemon守护进程);
假设此时客户端通过上面的命令或者浏览器发送http请求,通过前面解析的内核层的传输控制层三次握手建立连接,建立连接成功之后会发现服务端会spawn生成一个新的进程或线程(一般是线程,可以明确的看到其pid跟daemon的pid是相同的),状态是established,这就睡listen状态的主进程生成的worker线程,然后内核会分配资源给这个线程/进程,可以在/proc/<pid>下看到资源,在linux上面一切皆文件,包括这些进程线程,当然客户端也同样会开辟相应的资源,注意服务器端始终是一个端口,然后通过生成子线程来handle进来的请求,而客户端则是会用随机的端口,一个客户端耗尽所有端口最多同时可以产生65535个连接,不过需要注意的是客户端可以重用某个端口对另一个服务器B发起请求,这就是套接字socket的本质,套接字是src IP+PORT<-->dest IP+PORT,所以客户端同时通过端口比如21访问服务器A和B,tcp不会发生混乱,因为虽然sr IP+PORT相同,但是每对套接字的服务端是不同的,依然可以区分;
然后三次握手成功,资源开辟,就可以通信了,发送数据包;
结束是需要四次分手,也是因为双方都开辟了资源,所以双方不可以随意销毁资源,结束的方式是,客户端发送FIN给服务端,服务端收到后ACK,可能此时服务端还有东西要处理(假设是保存session),做完后服务端同样发起FIN,客户端ACK,所以总共是四次,
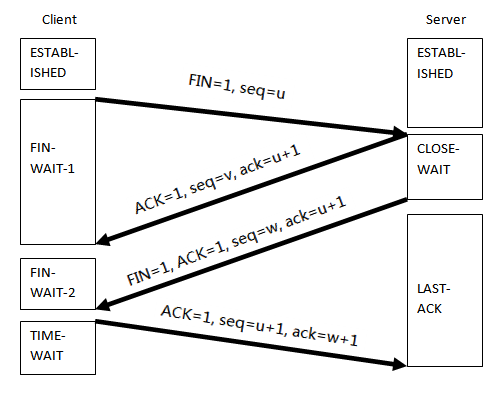
实际上在长时间无数据交互的时间段内,交互双方都有可能出现掉电、死机、异常重启等各种意外,当这些意外发生之后,这些 TCP 连接并未来得及正常释放,在软件层面上,连接的另一方并不知道对端的情况,它会一直维护这个连接,长时间的积累会导致非常多的半打开连接,造成端系统资源的消耗和浪费,为了解决这个问题,在传输层可以利用 TCP 的 KeepAlive 机制实现来实现。主流的操作系统基本都在内核里支持了这个特性(TCP协议本身并不约束使用keepalive,内核支持是允许应用层通过实现设置开启或关闭该特性,比如HTTP header keepalive或者其他的如quickfixj的socketkeepalive等)。
TCP KeepAlive 的基本原理是,隔一段时间给连接对端发送一个探测包,如果收到对方回应的 ACK,则认为连接还是存活的,在超过一定重试次数之后还是没有收到对方的回应,则丢弃该 TCP 连接。
以上过程可以通过抓包来数包:
curl parrot.live
tcpdump -nn -i eth0 port 80 or arp
关于资源开辟或者资源分配:
首先再明确下TCP连接的各种状态
LISTEN - 侦听来自远方TCP端口的连接请求;
SYN-SENT -在发送连接请求后等待匹配的连接请求;
SYN-RECEIVED - 在收到和发送一个连接请求后等待对连接请求的确认;
ESTABLISHED- 代表一个打开的连接,数据可以传送给用户;
FIN-WAIT-1 - 等待远程TCP的连接中断请求,或先前的连接中断请求的确认;
FIN-WAIT-2 - 从远程TCP等待连接中断请求;
CLOSE-WAIT - 等待从本地用户发来的连接中断请求;
CLOSING -等待远程TCP对连接中断的确认;
LAST-ACK - 等待原来发向远程TCP的连接中断请求的确认;
TIME-WAIT -等待足够的时间以确保远程TCP接收到连接中断请求的确认;
CLOSED - 没有任何连接状态;
当客户端 (opens new window)和服务器在网络中使用TCP协议发起会话时,在服务器内存 (opens new window)中会开辟一小块缓冲区 (opens new window)来处理会话过程中消息的“握手”交换
所以我理解的是实际上在三次握手的过程中就会分配内存资源,这也是synflood攻击存在的原因,
然后我们也知道的是,对方第一次握手服务端处于listen状态的daemon主线程收到肯定会fork一个子线程来handle进来的新连接,状态即为SYN-RECEIVED,
比较早的layer1是采用hub技术,容易浪费带宽,比如A和B两台机器上面运行不同的服务,外面请求进来的时候,采用hub技术就要盲目广播,浪费带宽; 而采用layer2的交换机技术,由于交换机会学习mac地址(arp mapping),大大降低了广播的浪费; 而layer3进一步采用ip网段隔开不同的分区,根据外部请求的ip可以准确的找到不同的网关
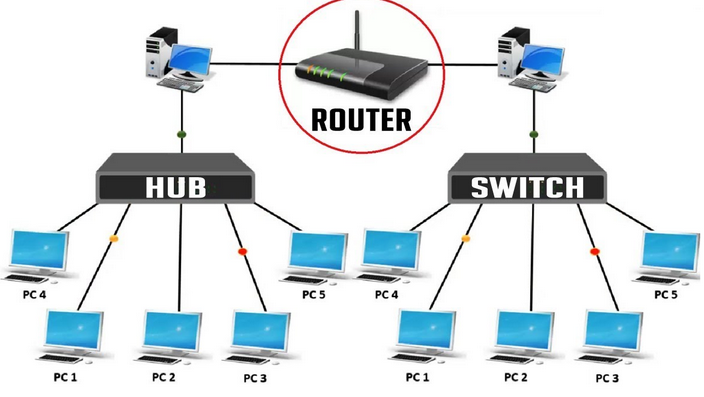 Switch:layer 2 datalink
Router:layer 3 network(dhcp server, dns, gateway)
Switch:layer 2 datalink
Router:layer 3 network(dhcp server, dns, gateway)
The OSI model explained in simple terms (opens new window)
DNS是域名转IP;NAT 是(外网)IP 转(内网)IP; ARP 是IP 转MAC
“网关”是一个概念,“路由器”是一个产品,路由器可以做网关,防火墙可以做网关,三层交换机可以做网关,一台普通pc可以做网关,甚至一个智能手机也可以做网关。网关实际上就是一个 IP地址,但他是一个网络连接到另一个网络的“关口”,他控制网络的进和出,他定义网络的边界。
40年前的协议战争,对区块链有什么启示? (opens new window)
十年码农内功:网络发包详细过程(一) (opens new window)
# 1.1 Layer 1: The physical layer 物理层
设备:
- 网桥:把两个不同物理层,不同MAC子层,不同速率的局域网连接在一起
网卡:- 中继器:
- 集线器:
We often take the physical layer for granted ("did you make sure the cable is plugged in?"), but we can easily troubleshoot physical layer problems from the Linux command line. That is if you have console connectivity to the host, which might not be the case for some remote systems.
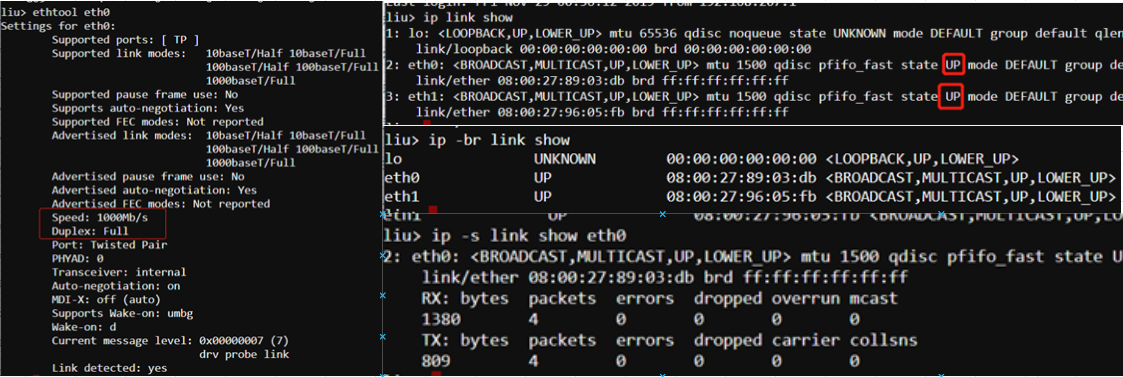
# 1.2 Layer 2: The data link layer 数据链路层
设备:
- 网卡:网卡工作在物理层和数据链路层的MAC子层,网卡是一块被设计用来允许计算机在计算机网络上进行通讯的计算机硬件。由于其拥有MAC地址,因此属于OSI模型的第2层。它使得用户可以通过电缆或无线相互连接。每一个网卡都有一个被称为MAC地址的独一无二的48位串行号,它被写在卡上的一块ROM中。在网络上的每一个计算机都必须拥有一个独一无二的MAC地址。
- 交换机: 交换机的工作原理 交换机根据收到数据帧中的源MAC地址建立该地址同交换机端口的映射,并将其写入MAC地址表中。 交换机将数据帧中的目的MAC地址同已建立的MAC地址表进行比较,以决定由哪个端口进行转发。 如数据帧中的目的MAC地址不在MAC地址表中,则向所有端口转发。这一过程称为泛洪(flood)。 广播帧和组播帧向所有的端口转发。
Layer2是交换机switch(记住arp mapping) The data link layer is responsible for local network connectivity; essentially, the communication of frames between hosts on the same Layer 2 domain (commonly called a local area network). The most relevant Layer 2 protocol for most sysadmins is the Address Resolution Protocol (ARP), which maps Layer 3 IP addresses to Layer 2 Ethernet MAC addresses. When a host tries to contact another host on its local network (such as the default gateway), it likely has the other host’s IP address, but it doesn’t know the other host’s MAC address. ARP solves this issue and figures out the MAC address for us. A common problem you might encounter is an ARP entry that won’t populate, particularly for your host’s default gateway. If your localhost can’t successfully resolve its gateway’s Layer 2 MAC address, then it won’t be able to send any traffic to remote networks. This problem might be caused by having the wrong IP address configured for the gateway, or it may be another issue, such as a misconfigured switch port.

Linux caches the ARP entry for a period of time, so you may not be able to send traffic to your default gateway until the ARP entry for your gateway times out. For highly important systems, this result is undesirable. Luckily, you can manually delete an ARP entry, which will force a new ARP discovery process
所谓的虚ip,ip漂移 (opens new window),就是利用了arp的高速缓存修改IP和mac地址的映射
Arpspoof https://www.youtube.com/watch?v=8SIP36Fym7U
# 1.3 Layer 3: The network/internet layer 网络层
设备:
- 路由器: 路由器是连接两个或多个网络的硬件设备,在网络间起网关的作用,是读取每一个数据包中的地址然后决定如何传送的专用智能性的网络设备。它能够理解不同的协议,例如某个局域网使用的以太网协议,因特网使用的TCP/IP协议。这样,路由器可以分析各种不同类型网络传来的数据包的目的地址,把非TCP/IP网络的地址转换成TCP/IP地址,或者反之;再根据选定的路由算法把各数据包按最佳路线传送到指定位置。所以路由器可以把非TCP/ IP网络连接到因特网上。
在数据链路层,物理信号以帧为单位进行组织,而每帧信号都需要一个目标地址和一个源地址,该地址基本上使用的是网卡MAC地址,在一层工作的主要是集线器和交换机,集线器会将所有帧信号投放到各个端口,因此连接端口的主机会收到很多没有意义的数据帧,这将造成集线器和主机之间信道冲突剧烈,因此集线器一般情况下使用较少,而交换机具有MAC地址学习记忆功能,能够准确的将数据帧投放到指定端口,从而大大地提高了数据传输效率;而在L2层,数据只能在一个子网间进行交换,如果要跨子网传输数据,则需要借助L3层的路径规划功能,也就是路由器的工作原理;
网络层概念太多搞不清?这里一次性给你做好总结 (opens new window)
layer3是路由器router(ip网段寻址) Layer 3 involves working with IP addresses, which should be familiar to any sysadmin. IP addressing provides hosts with a way to reach other hosts that are outside of their local network (though we often use them on local networks as well). The lack of an IP address can be caused by a local misconfiguration, such as an incorrect network interface config file, or it can be caused by problems with DHCP.
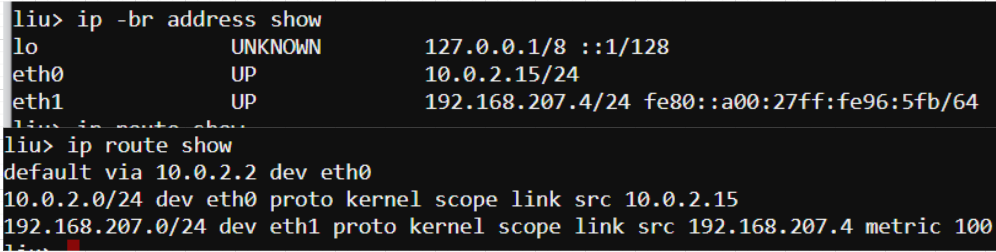
The most common frontline tool that most sysadmins use to troubleshoot Layer 3 is the ping utility. Ping sends an ICMP Echo Request packet to a remote host, and it expects an ICMP Echo Reply in return. While ping can be an easy way to tell if a host is alive and responding, it is by no means definitive. Many network operators block ICMP packets as a security precaution, although many others disagree with this practice. Another common gotcha is relying on the time field as an accurate indicator of network latency. ICMP packets can be rate limited by intermediate network gear, and they shouldn’t be relied upon to provide true representations of application latency. The next tool in the Layer 3 troubleshooting tool belt is the traceroute command. Traceroute takes advantage of the Time to Live (TTL) field in IP packets to determine the path that traffic takes to its destination. Traceroute will send out one packet at a time, beginning with a TTL of one. Since the packet expires in transit, the upstream router sends back an ICMP Time-to-Live Exceeded packet. Traceroute then increments the TTL to determine the next hop. The resulting output is a list of intermediate routers that a packet traversed on its way to the destination Another common issue that you’ll likely run into is a lack of an upstream gateway for a particular route or a lack of a default route. When an IP packet is sent to a different network, it must be sent to a gateway for further processing. The gateway should know how to route the packet to its final destination. The list of gateways for different routes is stored in a routing table
While not a Layer 3 protocol, it’s worth mentioning DNS while we’re talking about IP addressing. Among other things, the Domain Name System (DNS) translates IP addresses into human-readable names, such as www.redhat.com. DNS problems are extremely common, and they are sometimes opaque to troubleshoot. Plenty of books and online guides have been written on DNS, but we’ll focus on the basics here. A telltale sign of DNS trouble is the ability to connect to a remote host by IP address but not its hostname. Performing a quick nslookup on the hostname can tell us quite a bit. Taking a look at the /etc/hosts file, we can see an override that someone must have carelessly added. Host file override issues are extremely common, especially if you work with application developers who often need to make these overrides to test their code during development
Ipv4 ipv6
:::ffff: 用于IPv4的IPv6套接字通信。应用和套接字方面,它是IPv6,但网络和就包而言,它是IPv4。 In IPv6, you are allowed to remove leading zeros, and then remove consecutive zeros, meaning ::ffff: actually translates to 0000:0000:ffff:0000, this address has been designated as the IPv4 to IPv6 subnet prefix, so any IPv6 processor will understand it's working with an IPv4 address and handle it accordingly.
CIDR notation
IP address ranges are commonly expressed using CIDR notation, for example, 192.168.0.0/16.
IPv4 addresses consist of four 8-bit decimal values known as "octets", each separated by a dot. The value of each octet can range from 0 to 255, meaning that the lowest possible IPv4 address would be 0.0.0.0 and the highest 255.255.255.255.
In CIDR notation, the lowest IP address in the range is written explicitly, followed by another number that indicates how many bits from the start of the given address are fixed for the entire range. For example, 10.0.0.0/8 indicates that the first 8 bits are fixed (the first octet). In other words, this range includes all IP addresses from 10.0.0.0 to 10.255.255.255.
单播、广播和多播IP地址 除地址类别外,还可根据传输的消息特征将IP地址分为单播、广播或多播。 (opens new window)
子网掩码、ip地址、主机号、网络号、网络地址、广播地址 IPV4地址:4段十进制,共32位二进制,如:192.168.1.1 二进制就是:11000000|10101000|00000001|00000001
子网掩码可以看出有多少位是网络号,有多少位是主机号: 255.255.255.0 二进制是:11111111 11111111 11111111 00000000 网络号24位,即全是1 主机号8位,即全是0
129.168.1.1 /24 这个、24就是告诉我们网络号是24位,也就相当于告诉我们了子网掩码是:11111111 11111111 11111111 00000000即:255.255.255.0 172.16.10.33/27 中的/27也就是说子网掩码是255.255.255.224 即27个全1 ,11111111 11111111 11111111 11100000
Example: 一个主机的IP地址是202.112.14.137,掩码是255.255.255.224,要求计算这个主机所在网络的网络地址和广播地址 255.255.255.224 转二进制:11111111 11111111 11111111 11100000 网络号有27位,主机号有5位 网络地址就是:把IP地址转成二进制和子网掩码进行与运算 IP地址&子网掩码 11001010 01110000 00001110 10001001 && 11111111 11111111 11111111 11100000 ==》 11001010 01110000 00001110 10000000 即:202.112.14.128 广播地址:网络地址的主机位有5位全部变成1 ,10011111 即159 即:202.112.14.159 主机数:2^5-2=30 (减去全0的网络地址和全1的广播地址,再减去一个网关地址,还剩可用的29个地址)
ABC类/段IP地址
A类IP地址 在IP地址的四段号码中,第一段号码为网络号码,剩下的三段号码为本地计算机的号码。如果用二进制表示IP地址的话,A类IP地址就由1字节的网络地址和3字节主机地址组成,网络地址的最高位必须是“0”。A类IP地址中网络的标识长度为8位,主机标识的长度为24位。 地址范围从1.0.0.1到127.255.255.254 (二进制表示为:00000001 00000000 00000000 00000001 - 01111111 11111111 11111111 11111110)。最后一个是广播地址。 子网掩码为255.0.0.0
B类IP地址 在IP地址的四段号码中,前两段号码为网络号码。如果用二进制表示IP地址的话,B类IP地址就由2字节的网络地址和2字节主机地址组成,网络地址的最高位必须是“10”。B类IP地址中网络的标识长度为16位,主机标识的长度为16位。 地址范围从128.0.0.1-191.255.255.254 (二进制表示为:10000000 00000000 00000000 00000001-10111111 11111111 11111111 11111110)。 最后一个是广播地址。 子网掩码为255.255.0.0
C类IP地址 在IP地址的四段号码中,前三段号码为网络号码,剩下的一段号码为本地计算机的号码。如果用二进制表示IP地址的话,C类IP地址就由3字节的网络地址和1字节主机地址组成,网络地址的最高位必须是“110”。C类IP地址中网络的标识长度为24位,主机标识的长度为8位。 范围从192.0.0.1-223.255.255.254 (二进制表示为: 11000000 00000000 00000000 00000001 - 11011111 11111111 11111111 11111110)。最后一个是广播地址。 子网掩码为255.255.255.0
Penetration Testing Tools Cheat Sheet https://highon.coffee/blog/penetration-testing-tools-cheat-sheet/
Public ip vs NAT
详细见后面 2.2
NAT stands for Network Address Translation. In the context of our network, NAT is how one (public) IP address is turned into many (private) IP addresses. A public IP address is an address that is exposed to the Internet. If you search for "what's my IP" on the Internet, you'll find the public IP address your computer is using. If you look up your computer's IP address, you'll see a different IP address: this is your device's private IP. Chances are, if you check this on all of your devices, you'll see that all your devices are using the same public IP, but all have different private IPs. This is NAT in action. The network hardware uses NAT to route traffic going from the public IP to the private IP.
# 1.4 Layer 4: The transport layer 传输层
The transport layer consists of the TCP and UDP protocols, with TCP being a connection-oriented protocol and UDP being connectionless.
| Basis | Transmission control protocol (TCP) | User datagram protocol (UDP) |
|---|---|---|
| Type of Service | TCP is a connection-oriented protocol. Connection-orientation means that the communicating devices should establish a connection before transmitting data and should close the connection after transmitting the data. | UDP is the Datagram-oriented protocol. This is because there is no overhead for opening a connection, maintaining a connection, and terminating a connection. UDP is efficient for broadcast and multicast types of network transmission. |
| Reliability | TCP is reliable as it guarantees the delivery of data to the destination router. | The delivery of data to the destination cannot be guaranteed in UDP. |
| Error checking mechanism | TCP provides extensive error-checking mechanisms. It is because it provides flow control and acknowledgment of data. | UDP has only the basic error checking mechanism using checksums. |
| Acknowledgment | An acknowledgment segment is present. | No acknowledgment segment. |
| Sequence | Sequencing of data is a feature of Transmission Control Protocol (TCP). this means that packets arrive in order at the receiver. | There is no sequencing of data in UDP. If the order is required, it has to be managed by the application layer. |
| Speed | TCP is comparatively slower than UDP. | UDP is faster, simpler, and more efficient than TCP. |
| Retransmission | Retransmission of lost packets is possible in TCP, but not in UDP. | There is no retransmission of lost packets in the User Datagram Protocol (UDP). |
| Header Length | TCP has a (20-60) bytes variable length header. | UDP has an 8 bytes fixed-length header. |
| Weight | TCP is heavy-weight. | UDP is lightweight. |
| Handshaking Techniques | Uses handshakes such as SYN, ACK, SYN-ACK | It’s a connectionless protocol i.e. No handshake |
| Broadcasting | TCP doesn’t support Broadcasting. | UDP supports Broadcasting. |
| Protocols | TCP is used by HTTP, HTTPs, FTP, SMTP and Telnet. | UDP is used by DNS, DHCP, TFTP, SNMP, RIP, and VoIP. |
| Stream Type | The TCP connection is a byte stream. | UDP connection is message stream. |
| Overhead | Low but higher than UDP. | Very low. |
TCP: TCP achieves reliability in two ways. First, it orders packets by numbering them. Second, it error-checks by having the recipient send a response back to the sender saying that it has received the message. If the sender doesn’t get a correct response, it can resend the packets to ensure the recipient receives them correctly. TCP三次握手,实际上是因为TCP是双向全工通信,所以彼此互相确认对方的初始序号seq(sequence number),确认的返回就是确认号ack(acknowledgement number):
SYN SENT=>LISTEN SYN=1,seq=x
SYN SENT<=SYN REVD SYN=1,ACK=1,seq=y,ack=x+1
ESTAB=>SYN_REVD ACK=1,seq=x+1,ack=y+1
ESTAB<=>ESTAB 开始数据传输
发送方在发送数据包(假设大小为 10 byte)时, 同时送上一个序号( 假设为 500),那么接收方收到这个数据包以后, 就可以回复一个确认号(510 = 500 + 10) 告诉发送方 “我已经收到了你的数据包, 你可以发送下一个数据包, 序号从 510 开始”;
上面数据大小是1个字节,因为是三次握手阶段,数据包就是序号,一个字节足够
https://blog.csdn.net/lengxiao1993/article/details/82771768
UDP: The sender doesn’t wait to make sure the recipient received the packet—it just continues sending the next packets. If the recipient misses a few UDP packets here and there, they are just lost—the sender won’t resend them. UDP is used when speed is desirable and error correction isn’t necessary. For example, UDP is frequently used for live broadcasts and online games.
Applications listen on sockets, which consist of an IP address and a port. Traffic destined to an IP address on a specific port will be directed to the listening application by the kernel.
- localhost The result can be useful if you can’t connect to a particular service on the machine, such as a web or SSH server. Another common issue occurs when a daemon or service won’t start because of something else listening on a port. The ss command is invaluable for performing these types of actions:

- Remote TCP: telnet UDP: netstat: nc 192.168.122.1 -u 80 The netcat utility can be used for many other things, including testing TCP connectivity. Note that netcat may not be installed on your system, and it’s often considered a security risk to leave lying around. You may want to consider uninstalling it when you’re done troubleshooting. The examples above discussed common, simple utilities. However, a much more powerful tool is nmap,some of the things that it’s capable of doing: ● TCP and UDP port scanning remote machines. ● OS fingerprinting. ● Determining if remote ports are closed or simply filtered.
# 1.5 Layer 5: Application Layer 应用层
设备: 网关(Gateway):又称网间连接器、协议转换器。网关在传输层上以实现网络互连,是最复杂的网络互连设备,仅用于两个高层协议不同的网络互连。网关既可以用于广域网互连,也可以用于局域网互连。 网关是一种充当转换重任的计算机系统或设备。在使用不同的通信协议、数据格式或语言,甚至体系结构完全不同的两种系统之间,网关是一个翻译器。与网桥只是简单地传达信息不同,网关对收到的信息要重新打包,以适应目的系统的需求。同时,网关也可以提供过滤和安全功能。大多数网关运行在OSI 7层协议的顶层--应用层
对应了七层的上面三层:
- Layer 7: Application layer(HTTP)
- Layer 6: Presentation layer (none in this case)
- Layer 5: Session layer (SSL)
HTTP协议是建立在请求/响应模型上的, 首先由客户建立一条与服务器的TCP链接,并发送一个请求到服务器,请求中包含请求方法、URI、协议版本以及相关的MIME样式的消息; 服务器响应一个状态行,包含消息的协议版本、一个成功和失败码以及相关的MIME式样的消息。
HTTP/1.0为每一次HTTP的请求/响应建立一条新的TCP链接,因此一个包含HTML内容和图片的页面将需要建立多次的短期的TCP链接。一次TCP链接的建立将需要3次握手。 另外,为了获得适当的传输速度,则需要TCP花费额外的回路链接时间(RTT),每一次链接的建立需要这种经常性的开销,而其并不带有实际有用的数据,只是保证链接的可靠性, 因此HTTP/1.1提出了可持续链接的实现方法-默认启用Keep-Alive。HTTP/1.1将只建立一次TCP的链接而重复地使用它传输一系列的请求/响应 消息,因此减少了链接建立的次数和经常性的链接开销。 当然HTTP服务器端底层应该对tcp有超时设置,不然http client端如果不释放连接,有可能消耗掉TCP最大连接数,见后面的“一次排查send-q”;
ASN即自治系统号(AutonomousSystemNumber) 也是应用层的概念:
http://ip.yqie.com/tips/f94e7b8826754ce0a9fbe7c8a94f8b97.htm
https://www.obj-sys.com/asn1tutorial/node1.html
# 2. 协议详解
# 2.1 链路层协议
LLDP链路层发现协议
LLDP(链路层发现协议)是定义在802.1ab中的一个二层协议,接入网络的设备可以通过其,将管理地址、设备标识、接口标识等信息发送给同一个局域网络的其它设备。
# 2.2 网络层的协议测试工具
# ICMP协议:ping,tracert
tcping fping hping psping paping
如果是使用ipv6,加 -6
C:\WINDOWS\system32>tracert 101.OO.XX.39
Tracing route to 101.32.168.39 over a maximum of 30 hops
1 69 ms 70 ms 69 ms 172.OO.XX.11
............................
11 102 ms 91 ms 83 ms 203.208.152.81
12 188 ms 175 ms 155 ms 203.208.169.54
13 * * * Request timed out.
14 * * * Request timed out.
15 * * * Request timed out.
16 * * * Request timed out.
17 543 ms 164 ms 167 ms 101.OO.XX.39
解释:
1. asterisks:
The asterisks indicate that the target server did not respond as traceroute expected before a timeout occurred - this does not always indicate packet loss. If you suspect packet loss because of asterisks in the output or because the server you are running a traceroute to is not reached, you can attempt to ping the server where problems have started occur 不过本例中,没有显示出对应ip,不过可以通过ping 最后的101可以确定是通的
2. Request timed out: This is because the server at hop four is not accepting Internet Control Message Protocol (ICMP) traffic. As a result it ignores Traceroutes request for information. As you can see, however, it has still sent the data to the next hop as there are results that follow.
查询ip arin:
https://mxtoolbox.com/SuperTool.aspx?action=ptr%3a203.208.169.54&run=toolpage
# 网络层NAT“协议” VS 应用层代理服务器
为什么需要NAT技术?
首先NAT违反了基本的网络分层结构模型的设计原则。因为在传统的网络分层结构模型中,第N层是不能修改第N+1层的报头内容的。NAT破坏了这种各层独立的原则,NAT不算是真正的TCP/IP协议,而是一种工作在网络层和传输层的技术。
要真正了解NAT就必须先了解现在IP地址的使用情况,私有 IP 地址是指内部网络或主机 (opens new window)的IP 地址,公有IP 地址是指在因特网上全球唯一的IP 地址。RFC 1918 为私有网络预留出了三个IP 地址块(不会在因特网上被分配,因此可以不必向ISP 或注册中心申请而在公司或企业内部自由使用):
A 类:10.0.0.0~10.255.255.255
B 类:172.16.0.0~172.31.255.255
C 类:192.168.0.0~192.168.255.255
IPV4地址只有32位,随着接入Internet的计算机数量的不断猛增,IP地址资源也就愈加显得捉襟见肘,1994年提出NAT(Network Address Translation,网络地址转换)技术;
虽然NAT可以借助于某些代理服务器 (opens new window)来实现,但考虑到运算成本和网络性能,很多时候都是在路由器 (opens new window)上来实现的,这种方法需要在专用网(私网IP)连接到因特网(公网IP)的路由器上安装NAT软件。装有NAT软件的路由器叫做NAT路由器,它至少有一个有效的外部全球IP地址(公网IP地址)。这样,所有使用本地地址(私网IP地址)的主机在和外界通信时,都要在NAT路由器上将其本地地址转换成全球IP地址,才能和因特网连接。
两种模式:
- DNAT DNAT Destination Network Address Translation 目的网络地址转换
- SNAT SNAT Source Network Address Translation 源网络地址转换,其作用是将ip数据包的源地址转换成另外一个地址,可能有人觉得奇怪,好好的为什么要进行ip地址转换啊,为了弄懂这个问题,我们要看一下局域网用户上公网的原理,假设内网主机A(192.168.2.8)要和外网主机B(61.132.62.131)通信,A向B发出IP数据包,如果没有SNAT对A主机进行源地址转换,A与B主机的通讯会不正常中断,因为当路由器将内网的数据包发到公网IP后,公网IP会给你的私网IP回数据包,这时,公网IP根本就无法知道你的私网IP应该如何走了。所以问它上一级路由器,当然这是肯定的,因为从公网上根本就无法看到私网IP,因此你无法给他通信。为了实现数据包的正确发送及返回,网关必须将A的址转换为一个合法的公网地址,同时为了以后B主机能将数据包发送给A,这个合法的公网地址必须是网关的外网地址,如果是其它公网地址的话,B会把数据包发送到其它网关,而不是A主机所在的网关,A将收不到B发过来的数据包,所以内网主机要上公网就必须要有合法的公网地址,而得到这个地址的方法就是让网关进行SNAT(源地址转换),将内网地址转换成公网址(一般是网关的外部地址),所以大家经常会看到为了让内网用户上公网,我们必须在routeros的firewall中设置snat,俗称IP地址欺骗或伪装(masquerade)
NAT对待UDP的实现方式有4种,分别如下:
- Full Cone NAT
完全锥形NAT,所有从同一个内网IP和端口号发送过来的请求都会被映射成同一个外网IP和端口号,并且任何一个外网主机都可以通过这个映射的外网IP和端口号向这台内网主机发送包。
- Restricted Cone NAT
限制锥形NAT,它也是所有从同一个内网IP和端口号发送过来的请求都会被映射成同一个外网IP和端口号。与完全锥形不同的是,外网主机只能够向先前已经向它发送过数据包的内网主机发送包。
- Port Restricted Cone NAT
端口限制锥形NAT,与限制锥形NAT很相似,只不过它包括端口号。也就是说,一台IP地址X和端口P的外网主机想给内网主机发送包,必须是这台内网主机先前已经给这个IP地址X和端口P发送过数据包。
- Symmetric NAT
对称NAT,所有从同一个内网IP和端口号发送到一个特定的目的IP和端口号的请求,都会被映射到同一个IP和端口号。如果同一台主机使用相同的源地址和端口号发送包,但是发往不同的目的地,NAT将会使用不同的映射。此外,只有收到数据的外网主机才可以反过来向内网主机发送包。
三种类型:
- Static NAT 静态NAT Static NAT is of the types of NAT that is used for One-to-One Translation of Ports or IP Addresses. In other words, for example in this NAT type, one Private IP Address is mapped to one Public IP Address
- Dynamic NAT 动态NAT Dynamic NAT is one of the NAT types that is used with a Public IP Address Pool and works with more than one Public IP Address. Here, multiple Private IP Addresses are mapped to a Pool of Public IP Addresses.And these IP Addresses are given to the Internal users randomly. So, it is difficult to reach any Internal user from outside.
- 网络地址端口转换NAPT(Port-Level NAT) / PAT (NAT Overload) PAT (Port Address Translation) is one of the NAT types that is also known as NAT Overload. Here, many Private IP Addresses are translated to one Public IP Address. The traffic distinguisher in PAT are Port Numbers, TCP/UDP ports are used in PAT (NAT Overload).
NAT技术实现:
1)基本IP地址替换
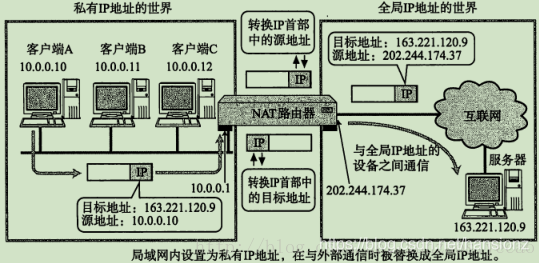
- NAT路由器将源地址从10.0.0.10替换成全局的IP 202.244.174.37
- NAT路由器收到外部的数据时, 又会把目标IP从202.244.174.37替换回10.0.0.10
- 在NAT路由器内部, 有一张自动生成的用于
地址转换的表 - 当
10.0.0.10第一次向163.221.120.9发送数据时就会生成表中的映射关系
2)NAPT技术 - Network Address and Port Translation
如果局域网内, 有多个主机都访问同一个外网服务器, 那么对于服务器返回的数据中, 目的IP都是相同的。 那么NAT路由器如何判定将这个数据包转发给哪个局域网的主机? NAPT技术使用IP+Port来解决这个问题。
在NAT网关上会有一张映射表,表上记录了内网向公网哪个IP和端口发起了请求,然后如果内网有主机向公网设备发起了请求,内网主机的请求数据包传输到了NAT网关上,那么NAT网关会修改该数据包的源IP地址和源端口为NAT网关自身的IP地址和任意一个不冲突的自身未使用的端口,并且把这个修改记录到那张映射表上。最后把修改之后的数据包发送到请求的目标主机,等目标主机发回了响应包之后,再根据响应包里面的目的IP地址和目的端口去映射表里面找到该转发给哪个内网主机。这样就实现了内网主机在没有公网IP的情况下,通过NAPT技术借助路由器唯一的一个公网IP来访问公网设备。
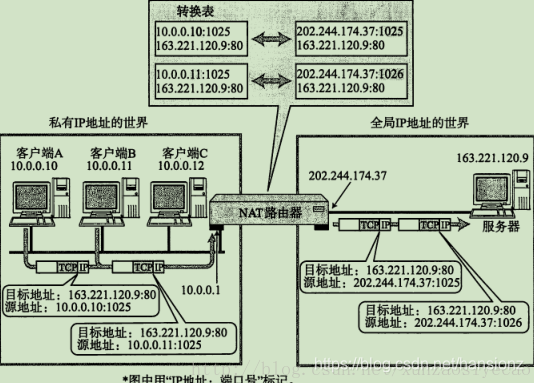
在使用TCP或UDP的通信当中,只有目标地址、源地址、目标端口、源端口以及协议类型(TCP还是UDP)五项内容都一致时才被认为是同一个通信连接。此时所使用的正是NAPT。
这种转换表在NAT路由器上自动生成。例如,在TCP情况下,建立TCP连接首次握手时的SYN包一经发出,就会生成这个表。而后又随着收到关闭连接时发出FIN包的确认应答从表中被删除。
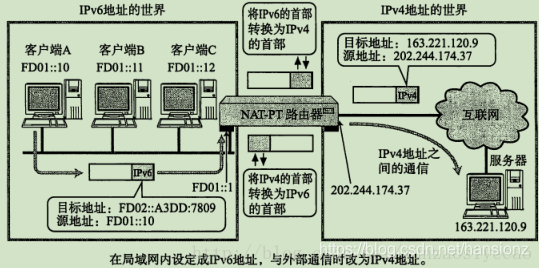
3)NAT-PT(NAPT-PT)
现在很多互联网服务都基于IPv4。如果这些服务不能做到IPv6中也能正常使用的话,搭建IPv6网络环境的有时也就无从谈起。 为此,就产生了NAT-PT(NAPT-PT)规范,PT是Protocol Translation的缩写。NAT-PT是将IPv6的首部转换为IPv4的首部的一种技术。有了这种技术,那些只有IPv6地址的主机也就能够与IPv4地址的其他主机进行通信了。
代理服务器看起来和NAT设备有一点像, 客户端像代理服务器发送请求, 代理服务器将请求转发给真正要请求的服务器,服务器返回结果后代理服务器又把结果回传给客户端。
NAT技术无法从外部网络向内网建立连接,所以如果外网要访问内网中某台机器,需要在路由器上设置 port forward端口转发,或者利用代理服务器,明白了NAT的这个“缺点”就也会明白了为啥vm的NAT模式时如果host需要访问vm也是需要设置端口转发,这是同样的道理。
NAT和代理服务器的区别:
- NAT设备是网络基础设备之一,解决的是
IP不足的问题,而代理服务器则是更贴近具体应用, 比如通过代理服务器进行翻墙,另外像迅游这样的加速器, 也是使用代理服务器。 - NAT是工作在
网络层直接对IP地址进行替换。代理服务器往往工作在应用层。 NAT一般在局域网的出口部署,代理服务器可以在局域网做也可以在广域网做也可以跨网。- NAT一般集成在
防火墙,路由器等硬件设备上。代理服务器则是一个软件程序, 需要部署在服务器上。
三层转发基本原理 https://blog.csdn.net/baidu_24553027/article/details/54928580 NAT地址转换 https://blog.csdn.net/hjgblog/article/details/23356409
# IGMP 组播协议
https://www.linuxprobe.com/igmp-tcpip.html 通常,我们把工作在网络层的IP 组播称为“三层组播”,相应的组播协议称为“三层组播协议”,包括IGMP、PIM、MSDP、MBGP等;把工作在数据链路层的IP 组播称为“二层组播”,相应的组播协议称为“二层组播协议”,包括IGMP Snooping、组播VLAN 等。
# 2.3 传输层的协议测试工具
参见《/doc/software/network/vpn》 注意ping和trcert都是走ICMP协议,并不是tcp协议,如果想追踪tcp需要用: tcproute TCPTraceroute
tcproute安装使用: 工具tcproute: https://www.elifulkerson.com/projects/tcproute.php win10需要安装qin10pcap http://www.win10pcap.org/download/ tcproute -p 443 github.io
https://serverfault.com/questions/199434/how-do-i-make-curl-use-keepalive-from-the-command-line
$ while :;do echo -e "GET / HTTP/1.1\nhost: $YOUR_VIRTUAL_HOSTNAME\n\n";sleep 1;done|telnet $YOUR_SERVERS_IP 80
# 2.4 应用层之“协议”
应用层的协议有FTP、HTTP、websocket、TELNET、SMTP、DHCP、DNS等协议:
# DHCP协议
DHCP服务一般位于路由器(家用)或者服务器(公司用),内网中电脑上的dhcp client发出请求, dhcp服务端返回分配ip地址、网关gateway、掩码及dns服务器地址; how dhcp works (opens new window) 当我们配置静态IP或者一些内网渗透的测试环境时,需要网络配置的四大基本要素: IP + Netmask + Gateway + DNS (opens new window)
参考私人笔记《hacker_theory/tools_metasploit》以及类似的vm实验环境配置;
configure proxy setting through dhcp option 252 (opens new window)
# **DNS协议 **
DNS测试工具windows:nslookup, linux: dig
https://blog.csdn.net/hansionz/article/details/86570290
 Gateway: internal send packets to gateway
Dns: resolve hostname
https://superuser.com/questions/77914/whats-the-difference-between-default-gateway-and-preferred-dns-server
Gateway: internal send packets to gateway
Dns: resolve hostname
https://superuser.com/questions/77914/whats-the-difference-between-default-gateway-and-preferred-dns-server
好了,既然 DNS 系统使用的是网路的查询,那么自然需要有监听的 port 啰!没错!很合理!那么 DNS 使用的是那一个 port 呢?那就是 53 这个 port 啦!你可以到你的 Linux 底下的 /etc/services 这个档案看看!搜寻一下 domain 这个关键字,就可以查到 53 这个 port 啦!
但是这里需要跟大家报告的是,通常DNS 查询的时候,是以udp 这个较快速的资料传输协定来查询的, 但是万一没有办法查询到完整的资讯时,就会再次的以tcp 这个协定来重新查询的!所以启动 DNS 的 daemon (就是 named 啦) 时,会同时启动 tcp 及 udp 的 port 53 喔!所以,记得防火墙也要同时放行 tcp, udp port 53 呢!
http://linux.vbird.org/linux_server/0350dns.php
DNS防火墙: https://developer.aliyun.com/article/766501
# Socket '协议'
前面也提到websocket是完整的应用层协议,所以不会访问raw tcp packets,但是常用的socket是可以的,因为它是基于应用层和传输层的抽象,并不是一个协议;
在《nio_epoll》中提到了ServerSocket,用来跟客户端建立连接,实际上socket也常常作为进程间通信的“协议”,有个特殊情况是,如果是本机进程间通信,有个特别的所谓socket Unix域套接字(Unix Domain Socket)https://blog.csdn.net/roland_sun/article/details/50266565,例子gitlab server、haproxy
# HTTP协议和 RPC'协议'
HTTP则长作为一种general purpose的协议通常是用于客户端和服务端之间的通信,尤其是通过公网的通信,当然也可以用于组件之间或者系统内部之间的通信; 但是有些情况下,HTTP是不够的:首先HTTP是应用层,对于系统内部的调用尤其是分布式系统之间调用来说性能比较低,此时就引入了基于传输层TCP的架构--RPC(基于传输层,所以本身在会话层);
RPC即远程过程调用,再加上proxy代理模式就可以让远程调用像本地调用一样, 这样讲起来rpc是基于TCP的,偏偏有个rpc over http,目的就是internet用户也可以通过http来进行远程过程调用RPC,比如Using HTTP as an RPC Transport (opens new window), 一个完整的RPC架构里面包含了四个核心的组件,分别是Client ,Server,Client Stub以及Server Stub, RPC框架众多,比如netty:
Nowadays we use general purpose applications or libraries to communicate with each other. For example, we often use an HTTP client library to retrieve information from a web server and to invoke a remote procedure call via web services. However, a general purpose protocol or its implementation sometimes does not scale very well. It is like how we don't use a general purpose HTTP server to exchange huge files, e-mail messages, and near-realtime messages such as financial information and multiplayer game data. What's required is a highly optimized protocol implementation that is dedicated to a special purpose. For example, you might want to implement an HTTP server that is optimized for AJAX-based chat application, media streaming, or large file transfer. You could even want to design and implement a whole new protocol that is precisely tailored to your need. Another inevitable case is when you have to deal with a legacy proprietary protocol to ensure the interoperability with an old system. What matters in this case is how quickly we can implement that protocol while not sacrificing the stability and performance of the resulting application. https://netty.io/wiki/user-guide-for-4.x.html
要了解这些框架的原理首先要搞明白TCP本身的原理,最重要的一个问题是: TCP面向字节流,UDP面向报文段,TCP的报文段呢?
问题的关键在于TCP是有缓冲区,作为对比,UDP面向报文段是没有缓冲区的。 TCP发送报文时,是将应用层数据写入TCP缓冲区中,然后由TCP协议来控制发送这里面的数据,而发送的状态是按字节流的方式发送的,跟应用层写下来的报文长度没有任何关系,所以说是流。 作为对比的UDP,它没有缓冲区,应用层写的报文数据会直接加包头交给网络层,由网络层负责分片,所以是面向报文段的。 https://www.zhihu.com/question/34003599/answer/204379413
所以说TCP本质是一个面向字节流的协议,本质是流式的,如同水流,没有分段,无法得知何时开始结束, 而TCP提供了可靠的流控方式:滑动窗口sliding window (opens new window),简单来说这个滑动窗口跟收发两端的缓存有关,可以控制“流速”;
由于这个滑动窗口的存在,跟发送端和接收端的收发节奏和表现出来的现象形象分为“拆包和粘包”问题:
首先包(Packet)的定义:在包交换网络里,单个消息被划分为多个数据块,这些数据块称为包,它包含发送者和接收者的地址信息。这些包然后沿着不同的路径在一个或多个网络中传输,并且在目的地重新组合。
打个比方,发送端先后发送两个信息 hello和world,接收端正常是期待同样先后收到hello和world, 但是因为tcp流,假设滑动窗口是1024字节,接收端可能会一次收到 helloworld连起来,这叫做“粘包”, 假设滑动窗口很小4个字节,接收端则会收到类似 hell o worl d 这种所谓“拆包”或者 hell owor ld 这种拆包+粘包;
粘包问题的处理一般是加“分隔符”来标志一个包packet结束; 拆包问题则是一般加上长度length字段,让接收方知道这个包的长度,比如10M,接收端可以把这些拆的包合并起来;
# HTTPS
https通信是http建立在tls上,最新的tls1.3(SSL is deprecated predecessor of TLS),TLS typically relies on a set of trusted third-party certificate authorities to establish the authenticity of certificates. 也就是CA
TLS握手发生在TCP握手结束之后,具体参考《publickey_infrastructure.md/#3.1 SSL/TLS》
# 2.5 应用层之proxy代理服务器
前面说过NAT技术和代理服务器技术的区别,现在具体说下代理服务器的作用:
- 翻*:)墙: 广域网中的代理。跟vpn是不同的技术
- 负载均衡: 局域网中的代理。
- 端口转发: http/ssh tunnel 隧道技术
正向代理/反向代理/端口转发:
其实端口转发根据方向可以分为正向和反向代理
首先要了解两种代理模式:forward proxy(正向代理),reverse proxy(反向代理): 正向代理,位于客户端,隐藏客户端信息,forward proxy proxies in behalf of clients (or requesting hosts) 例子:vpn技术基本都是正向代理,隐藏客户端信息 反向代理,位于服务器端,隐藏目标机器或服务信息,主要用于load balance等, a reverse proxy proxies in behalf of servers,另外很多WAF也是反向代理,隐藏服务器的真实ip,比如cloudflare可以防护对服务器真实IP的高频请求; 例子:nginx或者tomcat作为Oracle数据库的反向代理,再比如nginx作为监控UIgrafana的反向代理:Grafana-server runs its own service and hosts dashboard on 3000, if bind to domain, to the normal use access domain, default using 80, need a proxy server who use 80 to forward request to grafana-server for example nginx https://www.jscape.com/blog/bid/87783/Forward-Proxy-vs-Reverse-Proxy
# 2.6 内网穿透 - 隧道技术 Tunnel
# 2.7 其他network测试工具
network丢包延迟重复模拟器 https://jagt.github.io/clumsy/
# 3. 概念对比
# 二层广播 三层IP协议广播/组播 四层UDP协议广播/组播
TCP可以广播吗? 答一 不可以: Can I use broadcast or multicast for TCP? (opens new window) No, you can't. TCP is a protocol for communication between exactly two endpoints. Compared to UDP it features reliable transport, that means, that packets get not only send, but it is expected that the peer acknowledges the receipt of the data and that data will be retransmitted if the acknowledgment is missing. And because Broadcast and Multicast only send but never receive data, the reliability of TCP cannot be implemented on top of these protocols.
答二 “可以”(It does not implement "real" broadcasting, it just implements a subscribe and publish scenario with many subscribers and on publisher. ): Now why TCP broadcasting is necessary and even multicasting. Well, suppose you created a WebSocket server or any simple plain TCP server and millions of clients are connected to a single channel for like live streaming of a channel going on and people connected to that channels are writing comments now web-browser does not support UDP yet, WebRTC is based on UDP but is a caller callee protocol. So we will talk about browser connected to a WebSocket server and pushing messages concurrently and the messages need to be shown back to the clients in the UI of other clients who are writing comments or whatever in that case what server does is it creates a hashmap of the array and put all clients socket object inside the array and can map the array to a hashmap using a key as channel name and whenever a message is received it iterates over the array and send the message to all socket that is in the array. https://sudeepdasgupta.medium.com/broadcasting-and-multicasting-millions-of-clients-using-tcp-5794d784829a
总结: TCP is generally unicast that means the server needs to send the response to each client individually whereas UDP has multicast and broadcast support. Multicast means server transmits data to a group and client connected to the same group gets the data. 虽然前面有人可以实现所谓TCP的广播,实际上并不是真正的广播而是在代码层面通过遍历仍然是一个个的单独向clients发送消息,所以要理解“广播”在不同的场景下的含义
上面网络层介绍了三种IP地址:单播地址,广播地址,多播地址。对于这些通讯方式的理解是:单播地址是一对一的通讯,广播是一对多的通讯,多播是一对多的通讯。多播是对一个特定的通讯主体集合的通讯。广播与多播仅仅应用于UDP协议。单播的典型方式是TCP协议。
在交换以太网上运行TCP/IP环境下: 二层广播是在数据链路层的广播,它 的广播范围是二层交换机连接的所有端口;二层广播不能通过路由器。 三层广播就是在网络层的广播,它的范围是同一IP子网内的设备,子网广播也不能通过路由器。 第三层的数据必须通过第二层的封装再发送,所以三层广播必然通过二层广播来实现。 设想在同一台二层交换机上连接2个ip子网的设备,所有的设备都可以接收到二层广播,但三层广播只对本子网设备有效,非本子网的设备也会接收到广播包,但会被丢弃。 安装一个sniffer,抓个广播包,
路由器默认是不转发UDP广播包的,这样可以净化内网环境。但是某些特殊场合,需要使用udp广播,最常见的是DHCP服务,因为给每个网段都架设DHCP服务器,效率太低。怎么办呢? cisco有ip广播转发的解决方案:DHCP中继代理和UDP广播转发。
广播帧属于二层并不会跨越三层,所以为了解决广播风暴,可以使用三层设备隔离广播域,减小广播域范围。比如使用路由器来隔离广播域,由于路由器是三层设备,对数据的转发容易形成瓶颈,所以一般我们使用VLAN来隔离广播域。
案例: 华为云上vpc,某交易系统需要进行UDP广播 ,但是对于普通的ECS实例来说,因为物理资源交换机是跟其他租户共用的,所以被限流产生丢包,搜易只能使用专属主机deh,专属主机的网络设备是独立的,不会影响其他主机(注:通过专属主机deh创建的机器比如vm1 vm2可以跟普通机器比如ecs1 ecs2 同在一个vpc,但是不能在同一个子网,否则在同一个子网,广播仍然无法控制)。
# VPN & DNS resolve
连接VPN后:
>ipconfig /all
Windows IP Configuration
Host Name . . . . . . . . . . . . : TEST-LP
Primary Dns Suffix . . . . . . . : lyhistory.com
Node Type . . . . . . . . . . . . : Hybrid
IP Routing Enabled. . . . . . . . : No
WINS Proxy Enabled. . . . . . . . : No
DNS Suffix Search List. . . . . . : lyhistory.com
VPN_Access - X.X.X.X:
Connection-specific DNS Suffix . :
Description . . . . . . . . . . . : VPN IP: - X.X.X.X
Physical Address. . . . . . . . . :
DHCP Enabled. . . . . . . . . . . : No
Autoconfiguration Enabled . . . . : Yes
IPv4 Address. . . . . . . . . . . : 172.x.x.x(Preferred)
Subnet Mask . . . . . . . . . . . : 255.255.255.255
Default Gateway . . . . . . . . . :
DNS Servers . . . . . . . . . . . : 192.168.111.100
x.x.x.x
NetBIOS over Tcpip. . . . . . . . : Enabled
Wireless LAN adapter Wi-Fi:
Connection-specific DNS Suffix . :
Description . . . . . . . . . . . : Intel(R) Dual Band Wireless-AC 8265
Physical Address. . . . . . . . . :
DHCP Enabled. . . . . . . . . . . : Yes
Autoconfiguration Enabled . . . . : Yes
IPv4 Address. . . . . . . . . . . : 192.x.x.x(Preferred)
Subnet Mask . . . . . . . . . . . : 255.255.255.0
Lease Obtained. . . . . . . . . . : Wednesday, 7 December 2022 8:53:28 AM
Lease Expires . . . . . . . . . . : Thursday, 15 December 2022 9:08:12 AM
Default Gateway . . . . . . . . . : 192.168.5.1
DHCP Server . . . . . . . . . . . : 192.168.5.1
DNS Servers . . . . . . . . . . . : 1.1.1.1
NetBIOS over Tcpip. . . . . . . . : Enabled
测试:
>nslookup google.com
Server: UnKnown
Address: 192.168.111.100
Non-authoritative answer:
Name: google.com
Addresses: 2404:6800:4003:c04::64
2404:6800:4003:c04::8b
2404:6800:4003:c04::65
2404:6800:4003:c04::66
172.217.194.113
172.217.194.139
172.217.194.101
172.217.194.100
172.217.194.138
172.217.194.102
断开VPN测试:
>nslookup google.com
Server: one.one.one.one
Address: 1.1.1.1
Non-authoritative answer:
Name: google.com
Addresses: 2607:f8b0:4005:813::200e
142.251.32.46
# Proxy VS Tunnel
The terms are often intermixed, tunnel providers are called proxies.
Originally, tunneling is the technique of using one protocol to transport data inside another protocol.
A proxy (as in proxy representative) A proxy acts as an intermediary. It will hide your IP address from the destination (unless it adds it in a HTTP header field such as "Forward"). A proxy uses the same protocol throughout, it can alter the network flow, do caching or security scanning etc. So it's more of an extra hop on the way to the destination.
For example you can use a SOCKS proxy as a HTTP tunnel, i.e. you transport HTTP over it. This is due to the fact that SOCKS is a protocol that is designed to tunnel IP packets.
To add to the confusion, you can use a HTTP proxy to transport some other protocols such as FTP.
A good example for a tunnel is a VPN. Tunnels are often used to evade censorship or firewall rules blocking traffic. https://stackoverflow.com/questions/46804813/http-tunnel-vs-http-proxy#:~:text=Originally%2C%20tunneling%20is%20the%20technique,such%20as%20%22Forward%22).
When navigating through different networks of the Internet, proxy servers and HTTP tunnels are facilitating access to content on the World Wide Web. A proxy can be on the user's local computer, or anywhere between the user's computer and a destination server on the Internet.
# SOCKS vs. HTTP Proxies
https://brightdata.com/blog/leadership/socks5-proxy-vs-http-proxy
# Proxy Server (VS/&) VPN
# Proxy Server VS VPN
VPNs are Virtual Private Servers that encrypt all of a users’ web activity and device IP addresses. Typically, they come in the form of either an app or a browser extension.
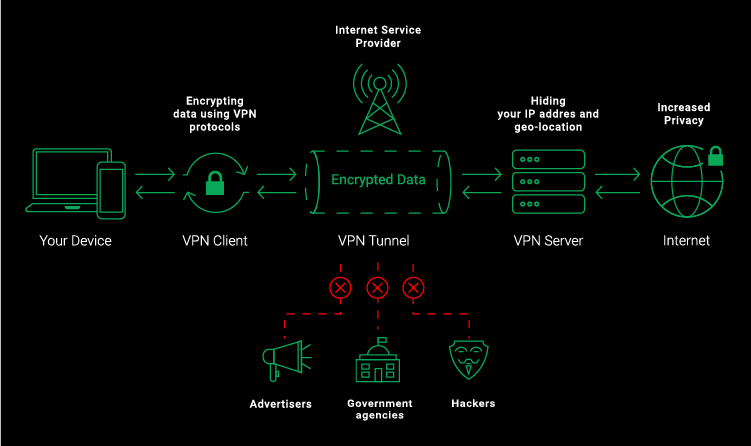
VPN如何工作:
- The vpn client establishes a connection to the server.
- Both ends verify what they are.
- Then the client and the server exchange what are called “public keys” – they’re like one-way equations that allow you to encrypt data, but not decrypt it.
- The client takes the server’s public key and uses it to make your data unreadable to ISPs, hackers, and other malicious actors.
- The data travels to the server, which uses its own private key to make that data usable.
- The server sends the decrypted data to the website or service you wanted to reach. The server also puts its own IP address (like an online street address) on the data, so your online destination thinks you’re connecting from the server’s location – very handy when bypassing geo-blocking.
- When something is sent to you, the server grabs it, uses the client’s public key to encrypt it, and sends it your way for the client to decrypt.
VPN协议:PPTP,L2TP,OpenVPN,IPSec。其中L2TP和PPTP作为最老牌的vpn,是工作在OSI七层模型的数据链路层
A Proxy server, on the other hand, is a computer that stands between the user and their server that hides only their device IP address, not all of their web activity. It also works on one website or app, not several.
代理协议及工具:Shadowsocks,Shadowsocks-R ,Socks5,VMess,VLESS,Trojann,V2Ray,Xray,Clash
# VPN over Proxy Server
场景: allow the administrator to configure protection, control and filtering of outbound web traffic when the VPN tunnel is connected; layering security: Proxy servers protect you from malicious websites - access out. VPN protects you from malicious intruders - access in.
Overview of the BIG-IP APM Edge Client Web Proxy for Windows (opens new window) Layering network security with VPN proxy together (opens new window) How DNS lookups work when using an HTTP proxy (or not) in IE (opens new window) How to connect to VPN through Proxy Server (opens new window) Proxy Settings Not Applied to VPN Connection (opens new window)
# 4. 抓包技术 Packet Sniffer
A packet sniffer is simply a piece of software that allows you to capture packets on your network. Tcpdump and Wireshark are examples of packet sniffers. Tcpdump provides a CLI packet sniffer, and Wireshark provides a feature-rich GUI for sniffing and analyzing packets. By default, tcpdump operates in promiscuous mode. This simply means that all packets reaching a host will be sent to tcpdump for inspection. This setting even includes traffic that was not destined for the specific host that you are capturing on, such as broadcast and multicast traffic. Of course, tcpdump isn’t some magical piece of software: It can only capture those packets that somehow reach one of the physical interfaces on your machine.
Looking at the above captures provides us with basic information about the packets traversing our network. It looks like these packets contain Spanning Tree Protocol (STP) output, perhaps from an upstream switch. Technically, these aren’t packets, they’re layer two frames. However, you’ll hear the terms used interchangeably when discussing packet captures. Knowing how to adjust the verbosity of your capture is important, as it allows you to dig deeper into the actual data contained within the packets. The verbosity level of tcpdump is controlled by appending between one and three -v flags to the command:
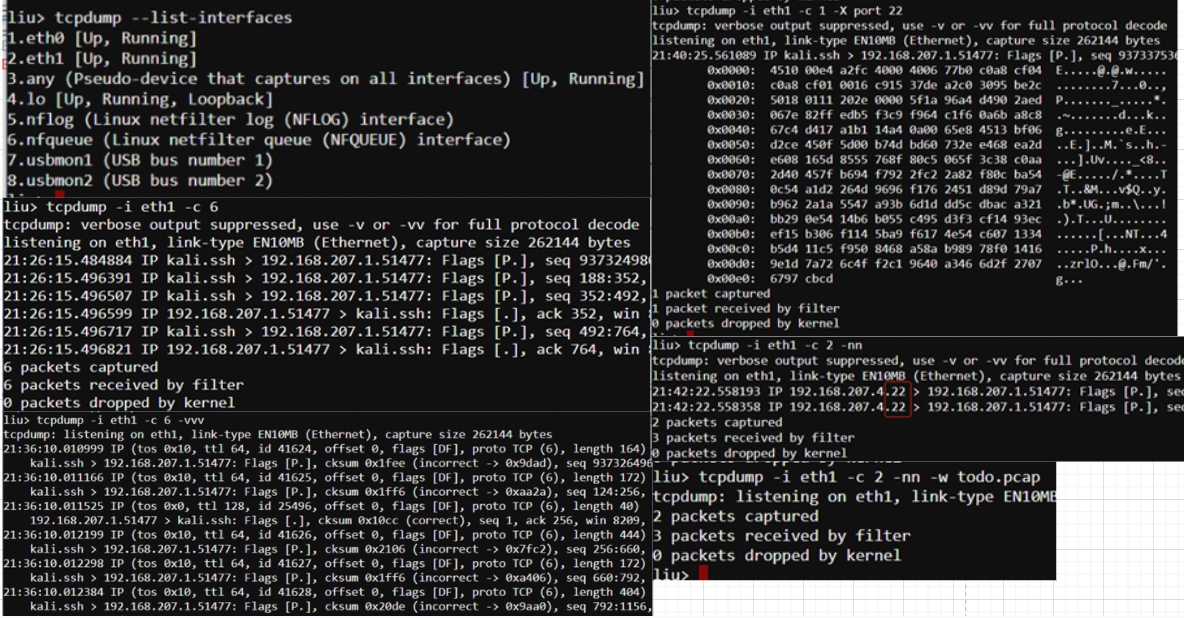
處于LISTEN狀態的socket: Recv-Q表示了current listen backlog隊列元素數目(等待用戶調用accept的完成3次握手的socket) Send-Q表示了listen socket最大能容納的backlog.這個數目由listen時指定,且不能大於 /proc/sys/net/ipv4/tcp_max_syn_backlog;
對於非LISTEN socket: Recv-Q表示了receive queue中的位元組數目(等待接收的下一個tcp段的序號-尚未從內核空間copy到用戶空間的段最前面的一個序號) Send-Q表示發送queue中容納的位元組數(已加入發送隊列中最後一個序號-輸出段中最早一個未確認的序號)
More https://blog.cloudflare.com/this-is-strictly-a-violation-of-the-tcp-specification/ https://102.alibaba.com/detail?id=140 http://netkiller.sourceforge.net/linux/system/network/ch14s02.html https://www.jianshu.com/p/30b861cac826
netstat属于net-tools工具集,ss属于iproute工具集
ss比netstat快的主要原因是,netstat是遍历/proc下面每个PID目录,ss直接读/proc/net下面的统计信息。所以ss执行的时候消耗资源以及消耗的时间都比netstat少很多。 当服务器的socket连接数量非常大时(如上万个),无论是使用netstat命令还是直接cat /proc/net/tcp执行速度都会很慢,相比之下ss可以节省很多时间。ss快的秘诀在于,它利用了TCP协议栈中tcp_diag,这是一个用于分析统计的模块,可以获得Linux内核中的第一手信息。如果系统中没有tcp_diag,ss也可以正常运行,只是效率会变得稍微慢但仍然比netstat要快。
在服务器产生大量sockets连接时,我们会使用这个命令在做宏观统计 ss -s 查看所有打开的网络端口 ss -pl 查看这台服务器上所有的socket连接 TCP sockets -ta UDP sockets -ua RAW sockets -wa UNIX sockets -xa
实时流量监听: nethogs -v 2
# 5.实战问题
# 5.1 wireshark
配置如下
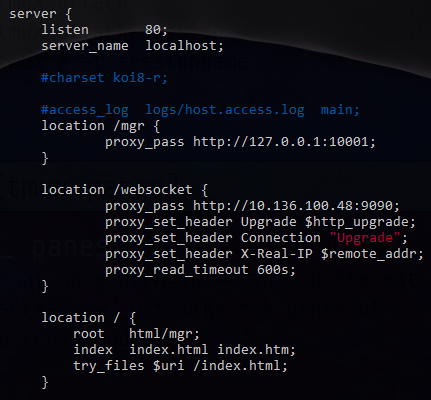
本地浏览器通过前端访问位于另一个vpn网段的server10.***.48的/wescoket, 然后nginx会forward到9090端口,首先我直接从server上抓(转发的)包 sudo tcpdump -c 1 -X port 9090 没有抓到,因为默认是抓取eth0,而这个是nginx通过本地lo转发,所以需要指定-i lo或者-i any 最终实时监控命令
sudo sh -c 'tcpdump -i any -X port 9090 -l | tee dat'
sudo sh -c 'tcpdump -i any -X host 192.168.207.4 -l | tee dat'
这里看不懂这些ASCII‘乱码’,尝试用在线工具http://packetor.com/,https://hpd.gasmi.net/ 解析失败 所以想到直接在前端用wireshark抓包,interfaces这里显示了很多ipconfig下面没有的名字,然后试了半天,才知道内网走的是这个Local Area Connection*12
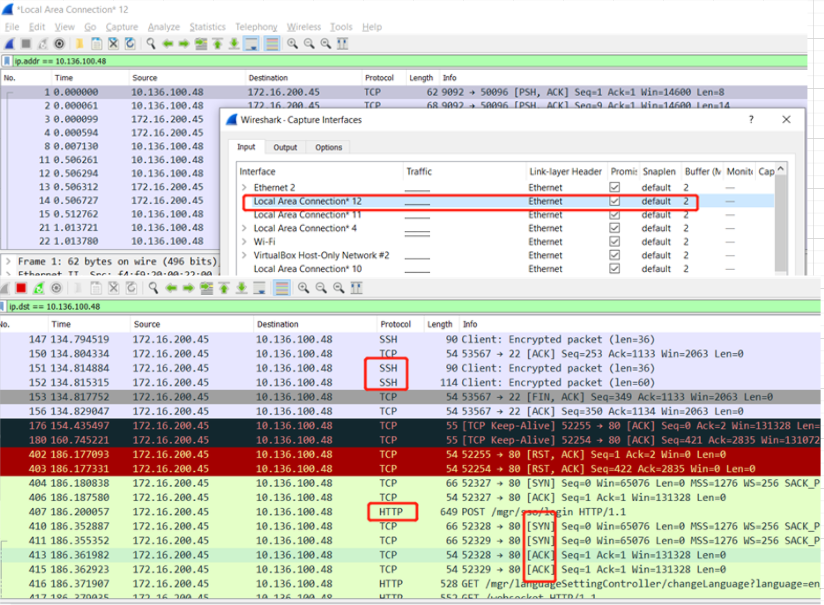
可以看到还有SSH的请求干扰视线,所以果断关掉(其实也可以加过滤条件比如tcp.port!=22),但是发现黑色背景的tcp不断的出现,然后关掉网站,居然还在,决定根据端口查一下 netstat -aon | find /i "53072" tasklist /fi "pid eq 81304" 居然是chrome,关掉chrome就完全停掉了
进一步看下http请求,看到左侧的箭头表示request和response,然后中间的两个点表示相关联的(https://www.wireshark.org/docs/wsug_html_chunked/ChUsePacketListPaneSection.html ),应该是http底层依赖的tcp请求,然后后面的TCP Keep Alive基本就是与之想的,应该是http header里面的keep alive起作用 https://www.imperva.com/learn/performance/http-keep-alive/
使用wireshark还有个要注意的是,比如 http.host contains lyhistory.github.io 因为我的域名是解析到github page 所以host不是我自己的lyhistory.com了
# 5.2 一次排查send-q
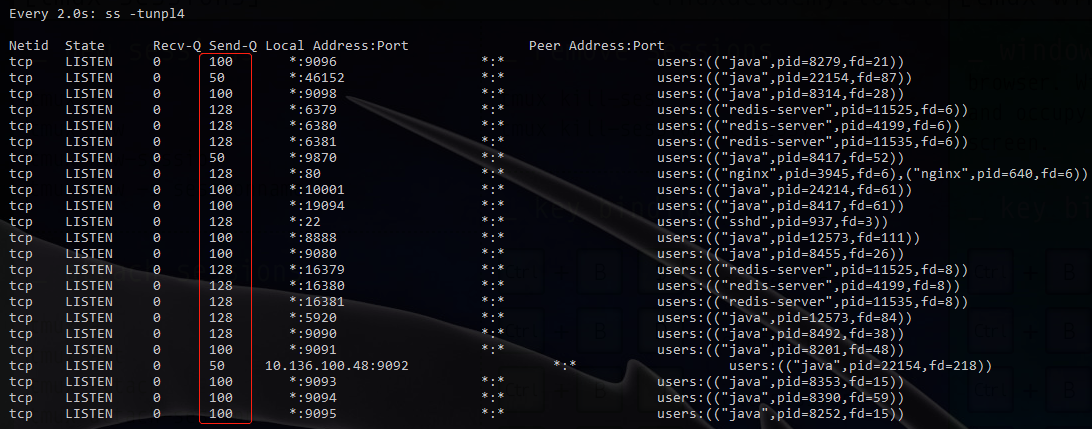
可以看到有 50 100 128 根据网上资料,排查系统参数
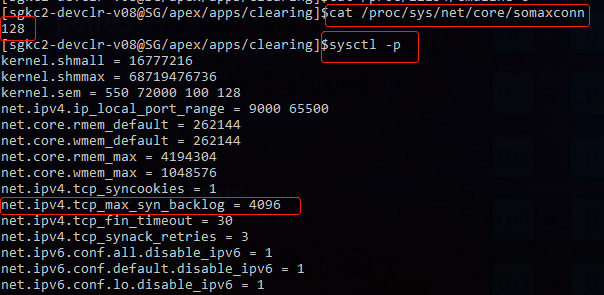
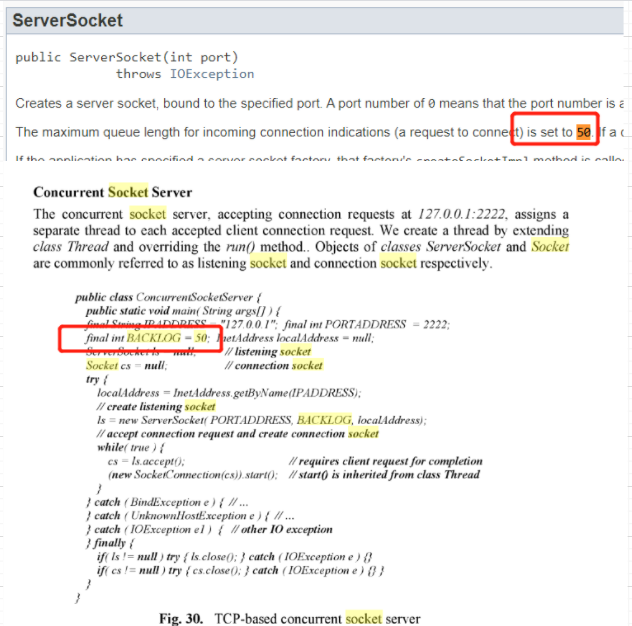
可以看到128是因为这里的设置限制 然后 google了下50,看到
但是实际上我根据cat /proc/
虽然这里没有写默认是多少,大概可以先猜测一下,java应该都是统一的默认50;
所以我在quickfix java提了个proposal https://github.com/quickfix-j/quickfixj/issues/248
同样的
cat /proc/<PID>/cmdline
查到了100的对应程序之一是我们的一个继承了spring-boot-starter-web程序,然后搜了下貌似tomcat默认就是100,所以查了下dependency,
这里确实是spring-boot-starter-web依赖于tomcat;
然后想到既然都是java程序受各种限制,比如socket默认的50以及tomcat默认的100,那么128又是怎么来的,搜了下,果然,比如websocket,这里是用了netty,然后有自定义的config
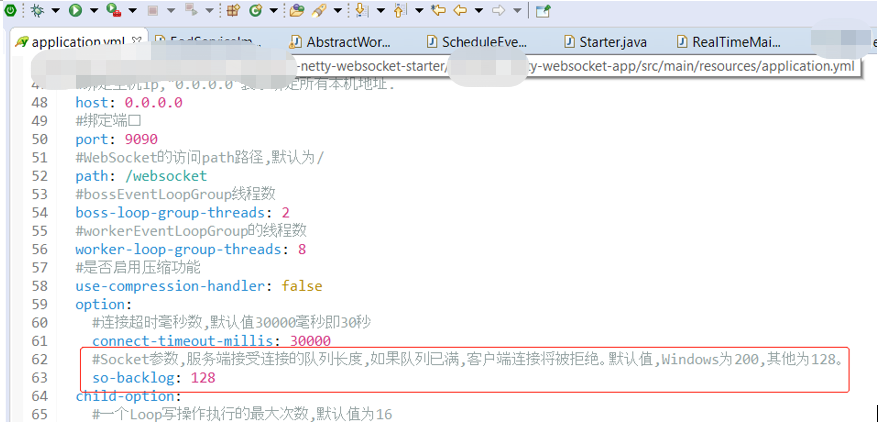
然后再查到其他的一些程序,比如kafka和zookeeper默认50 然后可以看到显示出来的redis-server和nginx都是128
再后来遇到另外一个问题:
the ESTAB tcp connection remains even after closed initiator (opens new window) 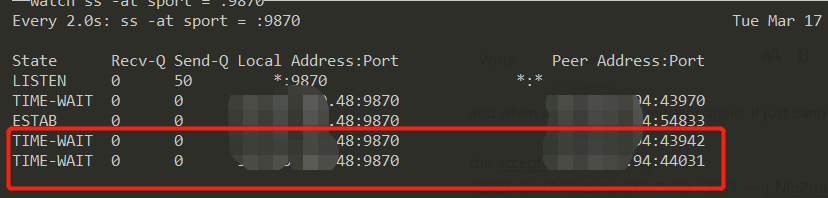 我配错了heartbeat,然后导致了一个神奇的现象,客户端连接服务端,由于他这个协议里面是客户端主动发起heartbeat,所以我配错了之后,即使客户端断掉(连接之后过二十分钟再断),服务端就认为连接一直在,
所以会一直保持这个ESTABLISHED连接,除非重启服务端,然后因为quickfix不允许同一个配置的initiator多次连接,所以再连接都变成了TIME_WAIT;
我配错了heartbeat,然后导致了一个神奇的现象,客户端连接服务端,由于他这个协议里面是客户端主动发起heartbeat,所以我配错了之后,即使客户端断掉(连接之后过二十分钟再断),服务端就认为连接一直在,
所以会一直保持这个ESTABLISHED连接,除非重启服务端,然后因为quickfix不允许同一个配置的initiator多次连接,所以再连接都变成了TIME_WAIT;
参考:记一次惊心的网站TCP队列问题排查经历https://zhuanlan.zhihu.com/p/36731397 https://juejin.im/post/5d8488256fb9a06b065cad98 https://cloud.tencent.com/developer/article/1143712
# 5.3 死亡ping
ping -l 65500 目标ip -t (65500 表示数据长度上限,-t 表示不停地ping目标地址) 这就是简单的拒绝服务攻击。
首先是因为以太网长度有限,IP包片段被分片。当一个IP包的长度超过以太网帧的最大尺寸(以太网头部和尾部除外)时,包就会被分片,作为多个帧来发送。接收端的机器提取各个分片,并重组为一个完整的IP包。在正常情况下,IP头包含整个IP包的长度。当一个IP包被分片以后,头只包含各个分片的长度。分片并不包含整个IP包的长度信息,因此IP包一旦被分片,重组后的整个IP包的总长度只有在所在分片都接受完毕之后才能确定。 在IP协议规范中规定了一个IP包的最大尺寸,而大多数的包处理程序又假设包的长度超过这个最大尺寸这种情况是不会出现的。因此,包的重组代码所分配的内存区域也最大不超过这个最大尺寸。这样,超大的包一旦出现,包当中的额外数据就会被写入其他正常区域。这很容易导致系统进入非稳定状态,是一种典型的缓存溢出(Buffer Overflow)攻击。在防火墙一级对这种攻击进行检测是相当难的,因为每个分片包看起来都很正常。 由于使用ping工具很容易完成这种攻击,以至于它也成了这种攻击的首选武器,这也是这种攻击名字的由来。当然,还有很多程序都可以做到这一点,因此仅仅阻塞ping的使用并不能完全解决这个漏洞。预防死亡之ping的最好方法是对操作系统打补丁,使内核将不再对超过规定长度的包进行重组。
https://zixuephp.net/article-99.html
# 5.4 大量TIME_WAIT状态的TCP 连接
https://mp.weixin.qq.com/s/t1ZUXvAUKlIt5UtiZFh1VQ
这个跟前面开篇介绍的TCP三次握手和端口有关,
在高并发的场景中,会出现批量的 TIME_WAIT 的 TCP 连接,短时间后,所有的 TIME_WAIT 全都消失,被回收,端口包括服务,均正常。即,在高并发的场景下,TIME_WAIT 连接存在,属于正常现象。
如果是持续的高并发场景:
- 一部分
TIME_WAIT连接被回收,但新的TIME_WAIT连接产生; - 一些极端情况下,会出现大量的
TIME_WAIT连接。
这个对业务有何影响,如果服务器上是用nginx作为反向代理,意思是,客户端是请求到nginx,然后nginx再作为客户端请求到具体的程序或后台服务,比如java spring mvc程序,websocket等,get post请求mvc程序执行速度比较快,所以不好观察,除非是想办法模拟高并发,我觉着用websocket举例更容易,可以看到
[vm2-devclr-v08@SG/opt/haproxy-2.2.1]$netstat -anp|grep :80
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 3945/nginx: master
tcp 0 0 x.x.x.48:80 10.30.30.94:25748 ESTABLISHED 15394/nginx: worker
tcp 0 0 127.0.0.1:80 127.0.0.1:10693 ESTABLISHED 15394/nginx: worker
tcp 0 0 127.0.0.1:10693 127.0.0.1:80 ESTABLISHED 25613/haproxy
这个10693的端口是做什么的先不用管,是我测试的haproxy;
我们主要看这个10.30.30.94:25748是客户端的连接,访问x.x.x.48:80,即nginx的监听的80端口,然后nginx立马会转发产生跟本地的websocket服务器也就是x.x.x.48:19090的连接,所以会占用一个nginx的端口,比如13576,下面可以看到,这里有两个连接,占用了两个nginx的端口13576和18973,因为是双向连接,所以还有反过来的连接
[vm2-devclr-v08@SG/opt/haproxy-2.2.1]$netstat -anp|grep :19090
tcp 0 0 0.0.0.0:19090 0.0.0.0:* LISTEN 3136/java
tcp 0 0 x.x.x.48:13576 x.x.x.48:19090 ESTABLISHED 15394/nginx: worker
tcp 0 0 x.x.x.48:19090 x.x.x.48:13576 ESTABLISHED 3136/java
tcp 0 0 x.x.x.48:18973 x.x.x.48:19090 ESTABLISHED 15394/nginx: worker
tcp 0 0 x.x.x.48:19090 x.x.x.48:18973 ESTABLISHED 3136/java
所以Nginx 作为反向代理时,大量的短链接,可能导致 Nginx 上的 TCP 连接处于 time_wait 状态:
- 每一个 time_wait 状态,都会占用一个「本地端口」,上限为
65535(16 bit,2 Byte); - 当大量的连接处于
time_wait时,新建立 TCP 连接会出错,address already in use : connect 异常
统计:各种连接的数量
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
TCP 本地端口数量,上限为 65535(6.5w),这是因为 TCP 头部使用 16 bit,存储「端口号」,因此约束上限为 65535。
大量的 TIME_WAIT 状态 TCP 连接存在,其本质原因是什么?
- 大量的短连接存在
- 特别是 HTTP 请求中,如果
connection头部取值被设置为close时,基本都由「服务端」发起主动关闭连接 - 而,
TCP 四次挥手关闭连接机制中,为了保证ACK 重发和丢弃延迟数据,设置time_wait为 2 倍的MSL(报文最大存活时间)
TIME_WAIT 状态:
- TCP 连接中,主动关闭连接的一方出现的状态;(收到 FIN 命令,进入 TIME_WAIT 状态,并返回 ACK 命令)
- 保持 2 个
MSL时间,即,4 分钟;(MSL 为 2 分钟)
解决上述 time_wait 状态大量存在,导致新连接创建失败的问题,一般解决办法:
1、客户端,HTTP 请求的头部,connection 设置为 keep-alive,保持存活一段时间:现在的浏览器,一般都这么进行了 2、服务器端,
- 允许
time_wait状态的 socket 被重用 - 缩减
time_wait时间,设置为1 MSL(即,2 mins)
更多细节,参考:
- https://www.cnblogs.com/yjf512/p/5327886.html
几个核心要点
1、 time_wait 状态的影响:
- TCP 连接中,「主动发起关闭连接」的一端,会进入 time_wait 状态
- time_wait 状态,默认会持续
2 MSL(报文的最大生存时间),一般是 2x2 mins - time_wait 状态下,TCP 连接占用的端口,无法被再次使用
- TCP 端口数量,上限是 6.5w(
65535,16 bit) - 大量 time_wait 状态存在,会导致新建 TCP 连接会出错,address already in use : connect 异常
2、 现实场景:
- 服务器端,一般设置:不允许「主动关闭连接」
- 但 HTTP 请求中,http 头部 connection 参数,可能设置为 close,则,服务端处理完请求会主动关闭 TCP 连接
- 现在浏览器中, HTTP 请求
connection参数,一般都设置为keep-alive - Nginx 反向代理场景中,可能出现大量短链接,服务器端,可能存在
3、 解决办法:服务器端,
- 允许
time_wait状态的 socket 被重用 - 缩减
time_wait时间,设置为1 MSL(即,2 mins)
# 5.5 端口占用冲突 Ephemeral ports
某应用程序监听端口9001,但是发现该端口已经被本地一个client端占用
An ephemeral port is a communications endpoint of a transport layer protocol of the Internet protocol suite that is used for only a short period of time for the duration of a communication session. 除了给常用服务保留的Well-known Port numbers之外,给客户端的端口号通常是动态分配的,称为ephemeral port(临时端口),在Linux系统上临时端口号的取值范围是通过这个内核参数定义的:net.ipv4.ip_local_port_range (/proc/sys/net/ipv4/ip_local_port_range),端口号动态分配时并不是从小到大依次选取的,而是按照特定的算法随机分配的。
We need to change ephemeral ports range in linux server to avoid port clash with application ports. Instructions below.
1. Show current ephemeral port range using command below
$ sysctl net.ipv4.ip_local_port_range
2. Add the following configuration to /etc/sysctl.conf to change this to the preferred range (32768 61000)
net.ipv4.ip_local_port_range = 32768 61000
3. Activate the new settings with command below
$ sysctl -p
4. Verify settings using command below
$ sysctl net.ipv4.ip_local_port_range
# 5.6 final_wait-1 final_wait-2,大量 time_wait
统计连接状态:
netstat -nat | awk '{print $6}' | sort | uniq -c
统计连接数:
netstat -anp|wc -l
netstat -anp|grep ESTABLISHED|wc -l
Active UNIX domain sockets (servers and established)
Active Internet connections (servers and established)
计算每秒最大连接数
$ sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range = 32768 61000
$ sysctl net.ipv4.tcp_fin_timeout
net.ipv4.tcp_fin_timeout = 60
This basically means your system cannot consistently guarantee more than (61000 - 32768) / 60 = 470 sockets per second.
https://stackoverflow.com/questions/410616/increasing-the-maximum-number-of-tcp-ip-connections-in-linux
为什么这里只考虑 final wait 没有考虑time wait:
> A socket in TIME-WAIT will gladly accept a new connection from a device using the same 5 tuple (protocol, source IP, source port, destination IP, destination port) providing that the Initial Sequence Number (ISN) of the new connection is higher than the last sequence number seen on the previous connection. As per RFC 1122:
> When a connection is closed actively, it MUST linger in TIME-WAIT state for a time 2xMSL (Maximum Segment Lifetime). **However, it MAY accept a new SYN from the remote TCP to reopen the connection directly from TIME-WAIT state**, if it:...
> https://superuser.com/questions/1179009/ephemeral-port-collision
- 优化1: 缩短FIN_WAIT_2 即fin_timeout 或者扩大 ephemeral port range
fin_timeout 作用 https://blog.csdn.net/qq_45859054/article/details/106885630 https://sean22492249.medium.com/tcp-%E7%9A%84%E9%97%9C%E9%96%89%E5%8B%95%E4%BD%9C-1469750cd099
优化2:time_wait TCP 状态 https://sean22492249.medium.com/tcp-%E7%9A%84%E9%97%9C%E9%96%89%E5%8B%95%E4%BD%9C-1469750cd099 为什么 TCP 协议有 TIME_WAIT 状态 https://draveness.me/whys-the-design-tcp-time-wait/
- shorten time wait缩短时间
$ sysctl net.ipv4.tcp_tw_timeout - disable socket lingering;
- 直接复用 recycleThis allows fast cycling of sockets in time_wait state and re-using them. But before you do this change make sure that this does not conflict with the protocols that you would use for the application that needs these sockets. Make sure to read post "Coping with the TCP TIME-WAIT" (opens new window) from Vincent Bernat to understand the implications. The net.ipv4.tcp_tw_recycle option is quite problematic for public-facing servers as it won’t handle connections from two different computers behind the same NAT device, which is a problem hard to detect and waiting to bite you. Note that net.ipv4.tcp_tw_recycle has been removed from Linux 4.12.
$ sysctl net.ipv4.tcp_tw_recycle=1 $ sysctl net.ipv4.tcp_tw_reuse=1
- shorten time wait缩短时间
https://serverfault.com/questions/962874/how-to-reach-1m-concurrent-tcp-connections https://serverfault.com/questions/660237/hitting-ephemeral-tcp-port-exhaustion https://serverfault.com/questions/10852/what-limits-the-maximum-number-of-connections-on-a-linux-server https://stackoverflow.com/questions/10085705/load-balancer-scalability-and-max-tcp-ports
# 6. (数据中心/云)组网 Network architecture
组网技术是指以太网组网技术和ATM局域网的组网技术。
internet intranet extranet ethernet: the Internet is open to the entire world, whereas an intranet is a private space, usually within a business. An extranet is essentially a combination of both the Internet and an intranet. An extranet is like an intranet that allows access only to certain outside individuals or businesses. The internet connects users from all over the world in a single massive network. Devices on the internet can talk to one another using the global infrastructure. Ethernet connects devices in a local area network (LAN), which is a much smaller collection of interconnected devices.
# 小范围的二层网络架构
传统的数据交换都是在OSI 参考模型的数据链路层发生的,也就是按照MAC 地址进行寻址并进行数据转发,并建立和维护一个MAC 地址表, 用来记录接收到的数据包中的MAC 地址及其所对应的端口。此种类型的网络均为小范围的二层网络。
例子:
假设现有如下网络拓扑图,ABCD四台主机属于10.0.0.0子网,网关指向路由器1的10.0.0.1,EFGH四台主机属于10.0.1.0子网,网关指向路由器2的10.0.1.1;
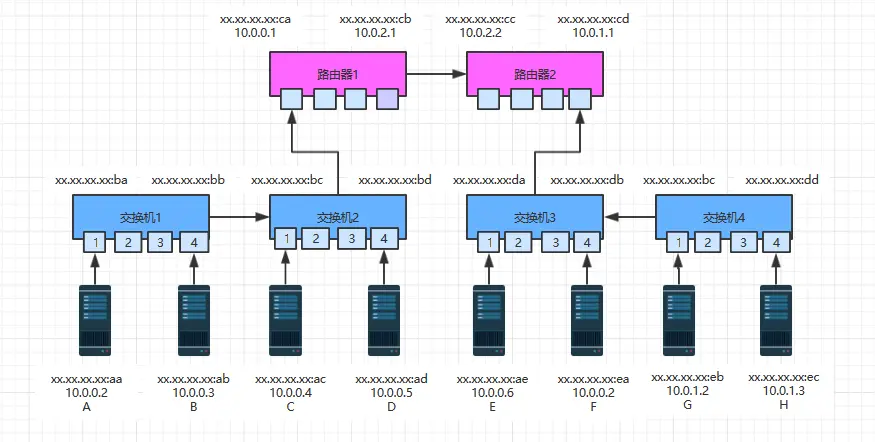
同一子网通信 先看同一子网内通信情况,A向C发送数据,这种情况下都是ip指定的,假设所有主机,交换机和路由器都刚刚通电,没缓存任何MAC映射和路由表。A在向C发送数据之前,是知道C的ip地址,发现它俩在同一物理子网,于是A试图在物理子网内来寻找C,但是在物理子网内寻址是通过MAC地址的,A并不知道C的MAC地址,于是A发送了一个ARP广播包,ARP广播用的地址是ff:ff:ff:ff:ff:ff,包内容如下:
源MAC 目标MAC 源IP 目标IP xx:xx:xx:xx:xx:aa ff:ff:ff:ff:ff:ff 10.0.0.2 10.0.04 交换机收到ARP广播后,首先会学习到主机A是连接到1端口的,然后缓存起来,同时在缓存中查找C的MAC地址,没找到便将这个广播包从所有端口发出去(1端口除外),交换机2收到广播包后,也会在缓存中查找C的MAC地址,没找到同样进行转发,其中B,D主机收到广播包后发现和自己无关便丢弃,而C收到广播后便会进行回应,来告知自己的身份,内容格式如下:
源MAC 目标MAC 源IP 目标IP xx:xx:xx:xx:xx:ac xx:xx:xx:xx:xx:aa 10.0.0.4 10.0.0.2 这个对于参与的交换机也是个学习的过程,在过程中记忆了主机A和主机C的ip地址和mac地址,AC找到彼此后,便可以在同一子网内依靠mac地址进行相互通信,格式如下:
源MAC 目标MAC 源IP 目标IP C--->A xx:xx:xx:xx:xx:ac xx:xx:xx:xx:xx:aa 10.0.0.4 10.0.0.2 A--->C xx:xx:xx:xx:xx:aa xx:xx:xx:xx:xx:ac 10.0.0.2 10.0.0.4
跨物理子网通信 同样假设所有设备都刚刚通电,没有缓存任何信息,这时A向E发送数据,A是知道E的ip地址,发现属于同一网段,同样不知道E的mac地址,于是A同样发送ARP广播包,BCD没有响应,但是路由器1收到广播后,为了避免广播风暴,会把自己的mac地址告诉A,格式如下:
源MAC 目标MAC 源IP 目标IP xx:xx:xx:xx:xx:ca xx:xx:xx:xx:xx:aa 10.0.0.1 10.0.0.2 A等待超时后,会知道E不在当前物理子网内,于是会向路由器1发送数据包,路由器收到数据包后,发现没有缓存E的ip地址,于是路由器1开始寻找E的过程。相比较交换机的广播找人,路由器寻址的空间范围更大,很多情况下是整个internet网络,要跨很多网络运营商,因此L3层面路由器的路径寻址计算协议涉及很多,例如:RIP、OSPF、IS-IS、BGP、IGRP等协议。路由器计算路径时,是无法窥探整个互联网的,因此每台路由器都是通过路由算法找到下一跳的最优路径,这些最优路径汇集起来就是完整的寻址路径,换句话说,路由器的转发路径不是一台路由器选出来的,而是很多路由器共同选择出来的最优下一跳地址序列;在这里为了解释原理,假设路由器1直接找到了路由器2。
这样路由器1开始想路由器2发送数据包,路由器2便开始在自己的物理子网内寻找E,进过一次广播后,发现E在自己子网内,于是向前一跳,找到离自己最近的路由器1,反馈自己离E主机最近,最终经过“A->广播->路由器->路由器寻址->找到E主机所在子网”过程的A,便可以和E进行通信了。由于A和E之间经历了多个物理子网,因此需要经历多次L2的转发才能实现数据包的转达,在这个过程中,ip包外包的数据帧中的mac地址是不断变换的。在A-E-A的过程中,数据帧和IP包的地址经历了如下过程(假设A的通信端口是88,而E的是99): 去包:
源MAC 目标MAC 源IP 目标IP 源端口 目的端口 用户数据 帧尾 A--->路由1 xx:xx:xx:xx:xx:aa xx:xx:xx:xx:xx:ca 10.0.0.2 10.0.0.6 88 99 ..... .... 路由1--->路由2 xx:xx:xx:xx:xx:cb xx:xx:xx:xx:xx:cc 10.0.0.2 10.0.0.6 88 99 ... ..... 路由2--->E xx:xx:xx:xx:xx:cd xx:xx:xx:xx:xx:ae 10.0.0.2 10.0.0.6 88 99 ... ..... 回包:
源MAC 目标MAC 源IP 目标IP 源端口 目的端口 用户数据 帧尾 E--->路由2 xx:xx:xx:xx:xx:ae xx:xx:xx:xx:xx:cd 10.0.0.6 10.0.0.2 99 88 ... ..... 路由2--->路由1 xx:xx:xx:xx:xx:cc xx:xx:xx:xx:xx:cb 10.0.0.6 10.0.0.2 99 88 ... ..... 路由1--->A xx:xx:xx:xx:xx:ca xx:xx:xx:xx:xx:aa 10.0.0.6 10.0.0.2 99 88 ..... .... 数据包在路由1和2中的1,4端口中进行转发时,因为是在设备内部,因此可以直接转发,不用变换帧头,从而提高效率,另外如果A向其他子网的FGH发送数据时,过程基本上一样,只不过不会通过广播寻址,而是直接将数据包发送给路由器出口网关。
ref: https://blog.csdn.net/cj2580/article/details/80107037
总结一、二层网络的工作流程: 1)数据包接收:首先交换机接收某端口中传输过来的数据包,并对该数据包的源文件进行解析,获取其源MAC 地址,确定发放源数据包主机 2)传输数据包到目的MAC 地址:首先判断目的MAC 地址是否存在,如果交换机所存储的MAC 地址表中有此MAC 地址所对应的端口,那么直接将数据包发送给这个端口;如果在交换机存储列表中找不到对应的目的MAC 地址,交换机则会对数据包进行全端口广播,直至收到目的设备的回应,交换机通过此次广播学习、记忆并建立目的MAC 地址和目的端口的对应关系,以备以后快速建立与该目的设备的联系; 3)如果交换机所存储的MAC 地址表中没有此地址,就会将数据包广播发送到所有端口上,当目的终端给出回应时,交换机又学习到了一个新的MAC 地址与端口的对应关系,并存储在自身的MAC 地址表中。当下次发送数据的时候就可以直接发送到这个端口而非广播发送了。
以上就是交换机将一个MAC 地址添加到列表的流程,该过程循环往复,交换机就能够对整个网络中存在的MAC 地址进行记忆并添加到地址列表,这就是二层(OSI 二层)交换机对MAC 地址进行建立、维护的全过程。
从上述过程不难看出,传统的二层网络结构模式虽然运行简便但在很大程度上限制了网络规模的扩大,由于传统网络结构中采用的是广播的方式来实现数据的传输,极易形成广播风暴,进而造成网络的瘫痪。这就是各个计算机研究机构所面临的“二层网络存在的天然瓶颈”,由于该瓶颈的存在,使得大规模的数据传输和资源共享难以实现,基于传统的二层网络结构也很难实现局域网络规模化。
为了适应大规模网络的产生于发展,基于分层、简化的思想,三层网络模式被成功设计推出。三层网络架构的基本思想就是将大规模、较复杂的网络进行分层次分模块处理,为每个模块指定对应的功能,各司其职,互不干扰,大大提高了数据传输的速率。
# 三层网络架构(vlan+xstp)
二、三层网络结构的设计,顾名思义,具有三个层次:核心层、汇聚层、接入层:
比如说一栋楼,其网络机房中的网络设备,如核心交换机、路由器、防火墙等设备共同组成的区域可以看做是核心层,每个楼层中的交换机等设备可以看做是接入层,而连接接入层和核心层之间的区域就是汇聚层
# 核心层 core layer
主要功能是实现骨干网络之间的优化传输。骨干层设计任务的重点通常是冗余能力、可靠性和高速传输。核心层一直被认为是所有流量的最终承受者和汇聚者。
在互联网中承载着网络服务器与各应用端口间的传输功能,是整个网络的支撑脊梁和数据传输通道,重要性不言而喻。因此,网络对于核心层要求极高,核心层必须具备数据存储的高安全性,数据传输的高效性和可靠性,对数据错误的高容错性,以及数据管理方面的便捷性和高适应性等性能。在核心层搭建中,设备的采购必须严格按需采购,满足上述功能需求,这就对交换机的带宽以及数据承载能力提出了更高的要求,因为核心层一旦堵塞将造成大面积网络瘫痪,因此必须配备高性能的数据冗余转接设备和防止负载过剩的均衡过剩负载的设备,以降低各核心层交换机所需承载的数据量,以保障网络高速、安全的运转。
# 汇聚层 aggregation/distribution layer
通常指网络中直接面向用户连接或访问的部分。接入层通过光纤、双绞线、同轴电缆、无线接入技术等传输媒介,实现与用户的对接,并进行业务和带宽的分配。接入层交换机具有低成本和高端口密度特性。
连接网络的核心层和各个接入的应用层,在两层之间承担“媒介传输”的作用。每个应用接入都经过汇聚层进行数据处理,再与核心层进行有效的连接,通过汇聚层的有效整合对核心层的荷载量进行降低。根据汇聚层的作用要求,汇聚层应该具备以下功能:实施安全功能、工作组整体接入功能、虚拟网络过滤功能等。因此,汇聚层中设备的采购必须具备三层网络的接入交换功能,同时支持虚拟网络的创建功能,从而实现不同网络间的数据隔离安全,能够将大型网络进行分段划分,化繁为简。
汇聚层的目的是为了减少核心的负担,将本地数据交换机流量在本地的汇聚交换机上交换,减少核心层的工作负担,使核心层只处理到本地区域外的数据交换。
汇聚层主要承担的基本功能有:
▲ 汇接接入层的用户流量,进行数据分组传输的汇聚、转发和交换;
▲ 根据接入层的用户流量,进行本地路由、过滤、流量均衡、QoS优先级管理,以及安全机制,IP地址转换、流量整形、组播管理等处理;
▲ 根据处理结果将用户流量转发到核心交换层或在本地进行路由处理;
▲ 完成各种协议的转换(如路由的汇总和重新发布等),以保证核心层连接运行不同的协议的区域。
# 接入层 access layer
通常指网络中直接面向用户连接或访问的部分。接入层通过光纤、双绞线、同轴电缆、无线接入技术等传输媒介,实现与用户的对接,并进行业务和带宽的分配。接入层交换机具有低成本和高端口密度特性。
接入层的面向对象主要是终端客户,为终端客户提供接入功能,区别于核心层和汇聚层提供各种策略的功能。接入层的主要功能是规划同一网段中的工作站个数,提高各接入终端的带宽。在搭建网络架构时,既要考虑网络的综合实用性,也要考虑经济效益,因此在接入层设备采购时可以选择数据链路层中较低端的交换机,而不是越高端越昂贵越好。
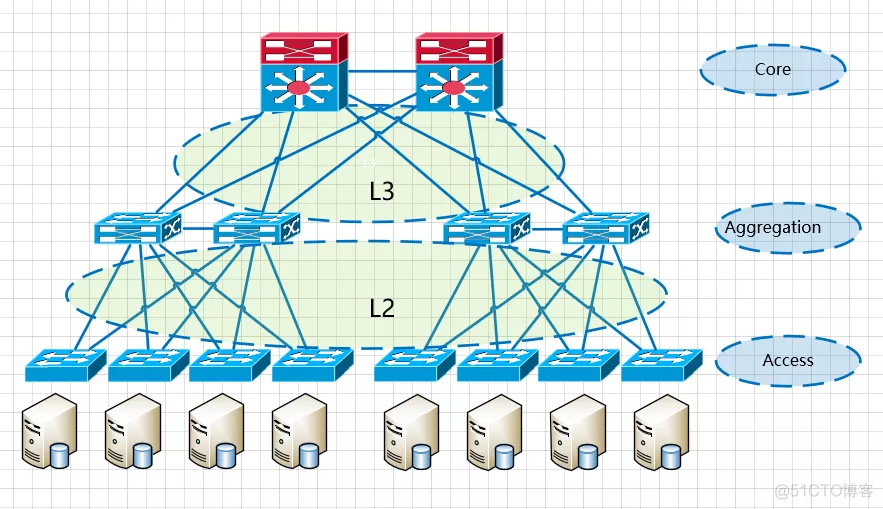 汇聚是网络的分界点,汇聚交换机以下是L2网络,以上是L3网络,每组汇聚交换机是一个pod,根据业务分区分模块。pod内是一个或者多个VLAN网络,一个POD对应一个广播域。
这种架构部署简单,(vlan+xstp)技术成熟。 (opens new window)
汇聚是网络的分界点,汇聚交换机以下是L2网络,以上是L3网络,每组汇聚交换机是一个pod,根据业务分区分模块。pod内是一个或者多个VLAN网络,一个POD对应一个广播域。
这种架构部署简单,(vlan+xstp)技术成熟。 (opens new window)
the computers, servers and other network devices are logically connected regardless of their physical location, VLANs can logically create several virtual networks to separate the network broadcast traffic, one of the main reason of creating VLAN is for traffic management because as a local area network grows and more network devices are added, the frequency of the broadcasts will also increase and the network will get heavily congested with data, but by creating VLANs which divided up the network into smaller broadcast domains, it will help alleviate the broadcast traffic. VLAN identifiers 12bits=4094 VLANs https://www.youtube.com/watch?v=jC6MJTh9fRE
对于办公网络来说,三层是足够适用的,但是对于业务网络来说存在一定的瓶颈: 随着近年来互联网的应用规模急剧扩张,对数据传输的要求也越来越高,基于数据整合的云计算技术逐渐受到人们的关注。计算机网络作为当今社会各种信息的传输媒介,其组成架构也即将发生重大变革。鉴于传统三层网络VLan 隔离以及STP 收敛上的缺陷,传统网络结构急需打破。现有研究机构开始致力于新型高效网络架构的研发与探索,结合早期的扁平化架构的原有二层网络与现有三层网络的优缺点提出了大二层网络架构。
# 大二层网络架构 (spine and leaf architecture)
# 为什么需要大二层网络
传统的三层数据中心架构结构的设计是为了应付服务客户端-服务器应用程序的纵贯式大流量,同时使网络管理员能够对流量流进行管理。工程师在这些架构中采用生成树协议(STP)来优化客户端到服务器的路径和支持连接冗余,通常将二层网络的范围限制在网络接入层以下,避免出现大范围的二层广播域;
虚拟化从根本上改变了数据中心网络架构的需求,既虚拟化引入了虚拟机动态迁移技术。从而要求网络支持大范围的二层域。从根本上改变了传统三层网络统治数据中心网络的局面。具体的来说,虚拟化技术的一项伴生技术—虚拟机动态迁移(如VMware的VMotion)在数据中心得到了广泛的应用,虚拟机迁移要求虚拟机迁移前后的IP和MAC地址不变,这就需要虚拟机迁移前后的网络处于同一个二层域内部。由于客户要求虚拟机迁移的范围越来越大,甚至是跨越不同地域、不同机房之间的迁移,所以使得数据中心二层网络的范围越来越大,甚至出现了专业的大二层网络这一新领域专题。
思考两个问题: a)IP及MAC不变的理由? 对业务透明、业务不中断 b)IP及MAC不变,那么为什么必须是二层域内? IP不变,那么就不能够实现基于IP的寻址(三层),那么只能实现基于MAC的寻址,既二层寻址,大二层,顾名思义,此是二层网络,根据MAC地址进行寻址
传统的二层网络大不起来的原因:
在数据中心网络中,“区域”对应VLAN的划分。相同VLAN内的终端属于同一广播域,具有一致的VLAN-ID,二层连通;不同VLAN内的终端需要通过网关互相访问,二层隔离,三层连通。传统的数据中心设计,区域和VLAN的划分粒度是比较细的,这主要取决于“需求”和“网络规模”。
传统的数据中心主要是依据功能进行区域划分,例如WEB、APP、DB,办公区、业务区、内联区、外联区等等。不同区域之间通过网关和安全设备互访,保证不同区域的可靠性、安全性。同时,不同区域由于具有不同的功能,因此需要相互访问数据时,只要终端之间能够通信即可,并不一定要求通信双方处于同一VLAN或二层网络。
传统的数据中心网络技术, STP是二层网络中非常重要的一种协议。用户构建网络时,为了保证可靠性,通常会采用冗余设备和冗余链路,这样就不可避免的形成环路。而二层网络处于同一个广播域下,广播报文在环路中会反复持续传送,形成广播风暴,瞬间即可导致端口阻塞和设备瘫痪。因此,为了防止广播风暴,就必须防止形成环路。这样,既要防止形成环路,又要保证可靠性,就只能将冗余设备和冗余链路变成备份设备和备份链路。即冗余的设备端口和链路在正常情况下被阻塞掉,不参与数据报文的转发。只有当前转发的设备、端口、链路出现故障,导致网络不通的时候,冗余的设备端口和链路才会被打开,使得网络能够恢复正常。实现这些自动控制功能的就是STP(Spanning Tree Protocol,生成树协议)。 由于STP的收敛性能等原因,一般情况下STP的网络规模不会超过100台交换机。同时由于STP需要阻塞掉冗余设备和链路,也降低了网络资源的带宽利用率。因此在实际网络规划时,从转发性能、利用率、可靠性等方面考虑,会尽可能控制STP网络范围。
随着数据大集中的发展和虚拟化技术的应用,数据中心的规模与日俱增,不仅对二层网络的区域范围要求也越来越大,在需求和管理水平上也提出了新的挑战。
数据中心区域规模和业务处理需求的增加,对于集群处理的应用越来越多,集群内的服务器需要在一个二层VLAN下。同时,虚拟化技术的应用,在带来业务部署的便利性和灵活性基础上,虚拟机的迁移问题也成为必须要考虑的问题。为了保证虚拟机承载业务的连续性,虚拟机迁移前后的IP地址不变,因此虚拟机的迁移范围需要在同一个二层VLAN下。反过来即,二层网络规模有多大,虚拟机才能迁移有多远。
传统的基于STP备份设备和链路方案已经不能满足数据中心规模、带宽的需求,并且STP协议几秒至几分钟的故障收敛时间,也不能满足数据中心的可靠性要求。因此,需要能够有新的技术,在满足二层网络规模的同时,也能够充分利用冗余设备和链路,提升链路利用率,而且数据中心的故障收敛时间能够降低到亚秒甚至毫秒级。
# 实现大二层网络的技术
大二层网络是针对当前最火热的虚拟化数据中心的虚拟机(服务器虚拟化)动态迁移这一特定需求而提出的概念,对于其他类型的网络并无特殊的价值和意义。
在虚拟化数据中心里,一台物理服务器被虚拟化为多台逻辑服务器,被称为虚拟机VM,每个VM都可以独立运行,有自己的OS、APP,在网络层面有自己独立的MAC地址和IP地址。而VM动态迁移是指将VM从一个物理服务器迁移到另一个物理服务器,并且要保证在迁移过程中,VM的业务不能中断。
为了实现VM动态迁移时,在网络层面要求迁移时不仅VM的IP地址不变、而且运行状态也必须保持(例如TCP会话状态),这就要求迁移的起始和目标位置必须在同一个二层网络域之中。
所以,为了实现VM的大范围甚至跨地域的动态迁移,就要求把VM迁移可能涉及的所有服务器都纳入同一个二层网络域,这样才能实现VM的大范围无障碍迁移。这就是大二层网络的需求由来,一个真正意义的大二层网络至少要能容纳1万以上的主机,才能称之为大二层网络。而传统的基于VLAN+xSTP的二层网络,由于环路和广播风暴、以及xSTP协议的性能限制等原因,通常能容纳的主机数量不会超过1K,无法实现大二层网络。当前,实现大二层网络的主要技术有以下几种:
网络/物理设备虚拟化技术-堆叠(网络厂商主导技术)
网络设备虚拟化是将相互冗余的两台或多台物理网络设备组合在一起,虚拟化成一台逻辑网络设备,在整个网络中只呈现为一个节点。例如华为的CSS框式堆叠、iStack盒式堆叠、SVF框盒堆叠技术等。
网络设备虚拟化再配合链路聚合技术,就可以把原来网络的多节点、多链路的结构变成逻辑上单节点、单链路的结构,解决了二层网络中的环路问题。没有了环路问题,就不需要xSTP,二层网络就可以范围无限(只要虚拟网络设备的接入能力允许),从而实现大二层网络。
例如华为的CSS/iStack、Cisco的VSS和H3C的IRF等,可以将同一网络层次上的同类型或同型号交换机多虚一,又称为横向虚拟化
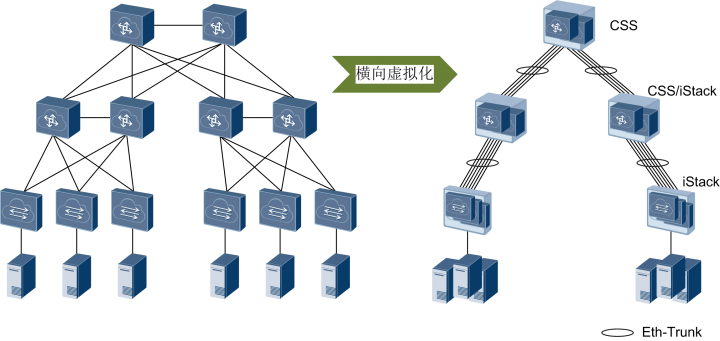
随着设备虚拟化技术的发展,一种更加极致的“纵向虚拟化”技术出现了――混堆,例如华为的SVF、Cisco的FEX、H3C的IRF3。纵向虚拟化可以将不同网络层次、不同类型的交换机多虚一
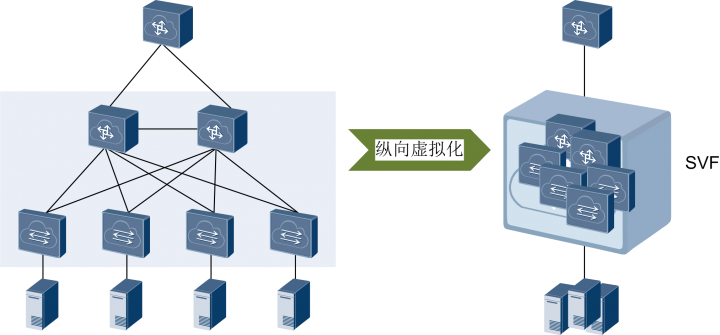
设备虚拟化系统本身的规模限制:虚拟化后所有设备的控制平面合一,只有一个主控节点,其它都是备份角色,控制平面是1:N备份的(1+1=2在这里不适用)。因此,整个系统的物理节点规模就受限于主控节点的处理能力,不是想做多大就做多大的。例如框式设备虚拟化一般<4台,盒式设备一般<20~30台。目前最大规模的虚拟化系统大概可以支持接入1~2万台主机,可以从容应付一般的中、小型数据中心,但对于一些超大型的数据中心来说,就显得力不从心了。这也就是为什么接下来会出现TRILL、VXLAN等大二层技术的原因了
网络/物理设备虚拟化技术-大二层转发技术/路由二层转发(网络厂商主导技术)
网络设备厂商,基于硬件设备开发出了EVI(Ethernet Virtualization Interconnect)、TRILL(Transparent Interconnection of Lots of Links)、SPB(Shortest Path Bridging)等大二层技术。这些技术通过网络边缘设备对流量进行封装/解封装,构造一个逻辑的二层拓扑,同时对链路充分利用、表项资源分担、多租户等问题采取各自的解决方法。此类技术一般要求网络边缘设备必须支持相应的协议,优点是硬件设备表项容量大、转发速度快。
大二层转发技术是通过定义新的转发协议,改变传统二层网络的转发模式,将三层网络的路由转发模式引入到二层网络中。例如TRILL、SPB等。
以TRILL为例,TRILL协议在原始以太帧外封装一个TRILL帧头,再封装一个新的以太帧来实现对原始以太帧的透明传输,支持TRILL的交换机可通过TRILL帧头里的Nickname标识来进行转发,而Nickname就像路由一样,可通过IS-IS路由协议进行收集、同步和更新。
然而,通过网络设备虚拟化技术,TRILL、EVN技术构建的物理上的大二层网络可以将虚拟机迁移的范围扩大,但是构建物理上的大二层,难免要对原来的网络做较大的改动,并且大二层网络的范围依然会受到种种条件的限制,VXLAN技术能很好的解决上述问题。
Overlay技术(IT厂商主导技术)
虚拟化软件厂商,从自身出发,提出了VXLAN(Virtual eXtensible LAN)、NVGRE(Network Virtualization Using Generic Routing Encapsulation)、STT(A Stateless Transport Tunneling Protocol for Network Virtualization)等一系列技术。这部分技术利用主机上的虚拟交换机(vSwitch)作为网络边缘设备,对流量进行封装/解封装。优点是对网络硬件设备没有过多要求。
- Underlay网络对应物理网络;
- Overlay网络对应虚拟网络;
Overlay技术是通过用隧道封装的方式,将源主机发出的原始二层报文封装后在现有网络中进行透明传输,从而实现主机之间的二层通信。通过封装和解封装,相当于一个大二层网络叠加在现有的基础网络之上,所以称为Overlay技术。
Overlay技术通过隧道封装的方式,忽略承载网络的结构和细节,可以把整个承载网络当作一台“巨大无比的二层交换机”, 每一台主机都是直连在“交换机”的一个端口上。而承载网络之内如何转发都是 “交换机”内部的事情,主机完全不可见。Overlay技术主要有VXLAN、NVGRE、STT等。
Virtual extensible Local Area Network, at its most basic level VXLAN is a tunneling protocol that tunnels ethernet Layer2 二层 traffic over an IP Layer3 network 三层, it's an extension to VLAN, it encapsulates a Layer2 ethernet frame into a udp packet and then transmit this packet over a Layer3 network, VXLAN is a formal internet standard specified in RFC7348, if you go back to OSI model VXLAN is another Application Layer protocol based on UDP that runs on port 4789, why we need VXLAN: the traditional layer 2 networks have issues due to below three main reasons:
- Spanning-tree blocks any redundant links to avoid loops, blocking links to create a loop free topology gets the job done but it also means we pay for the links we can't use
- limitted amount of VLANs, VXLAN overcomes this limitation by using a longer logical network identifier that is 24 bit which allows more VLANs and therefore more logical network isolation for large network such as cloud that typically include many VMs
- large mac address tables, before server virtualization a switch only had to learn one mac address per switch port, with server virtualization we run many VMs or containers on a single physical server, each VM has a virtual nick and a virtual mac address, the number of addresses in the mac address table of switches has grown exponentially, the switch has to learn many mac addresses on a single switch port, a Top-Of-Rack(TOR) switch in data center could connect to 24 or 28 physical servers, a data center could have many racks so each switch has to store the mac address of all VMs that communicates with each other, we requrie much larger mac address tables compared to network without server virtualization, with benefits that VLANs can't provide:
- 16 million VXLANs
- migration of VMs, migration of virtual machines between servers that exists in separtate layer 2 domains by tunneling the traffic over layer 3 networks, the funtionality allows you to dynamically allocate resources within or between data centers without being constrained by layer 2 boundaries or being forced to create large or geographically streached layer 2 domains https://www.youtube.com/watch?v=QPqVtguOz4w Linux VXLAN (opens new window)
# 实现大二层网络的技术之VXLAN技术细节:
VLAN作为传统的网络隔离技术,在标准定义中VLAN的数量只有4000个左右,无法满足大二层网络的租户间隔离需求。另外,VLAN的二层范围一般较小且固定,无法支持虚拟机大范围的动态迁移。
VXLAN完美地弥补了VLAN的上述不足,一方面通过VXLAN中的24比特VNI字段,提供多达16M租户的标识能力,远大于VLAN的4000;另一方面,VXLAN本质上在两台交换机之间构建了一条穿越基础IP网络的虚拟隧道,将IP基础网络虚拟成一个巨型“二层交换机”,即大二层网络,满足虚拟机大范围动态迁移的需求。
- VTEP(VXLAN Tunnel Endpoints,VXLAN隧道端点)
VXLAN网络的边缘设备,是VXLAN隧道的起点和终点,VXLAN报文的相关处理均在这上面进行。总之,它是VXLAN网络中绝对的主角。VTEP既可以是一***立的网络设备(比如华为的CE系列交换机),也可以是虚拟机所在的服务器。那它究竟是如何发挥作用的呢?答案稍候揭晓。
- VNI(VXLAN Network Identifier,VXLAN 网络标识符)
前文提到,以太网数据帧中VLAN只占了12比特的空间,这使得VLAN的隔离能力在数据中心网络中力不从心。而VNI的出现,就是专门解决这个问题的。VNI是一种类似于VLAN ID的用户标示,一个VNI代表了一个租户,属于不同VNI的虚拟机之间不能直接进行二层通信。VXLAN报文封装时,给VNI分配了足够的空间使其可以支持海量租户的隔离。详细的实现,我们将在后文中介绍。
- VXLAN隧道
“隧道”是一个逻辑上的概念,它并不新鲜,比如大家熟悉的GRE。说白了就是将原始报文“变身”下,加以“包装”,好让它可以在承载网络(比如IP网络)上传输。从主机的角度看,就好像原始报文的起点和终点之间,有一条直通的链路一样。而这个看起来直通的链路,就是“隧道”。顾名思义,“VXLAN隧道”便是用来传输经过VXLAN封装的报文的,它是建立在两个VTEP之间的一条虚拟通道。
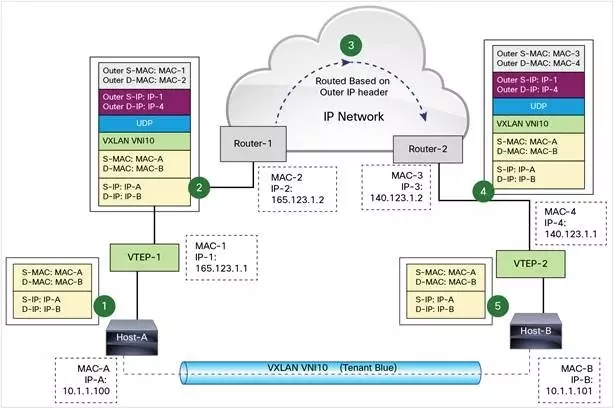
注:更详细的流程图(VXLAN同子网和不同子网通信流程包括arp学习),参考技术发烧友:认识VXLAN (opens new window)
图中 Host-A 和 Host-B 位于 VNI 10 的 VXLAN,通过 VTEP-1 和 VTEP-2 之间建立的 VXLAN 隧道通信。数据传输过程如下:
Host-A 向 Host-B 发送数据时,Host-B 的 MAC 和 IP 作为数据包的目标 MAC 和 IP,Host-A 的 MAC 作为数据包的源 MAC 和 IP,然后通过 VTEP-1 将数据发送出去。
VTEP-1 从自己维护的映射表中找到 MAC-B 对应的 VTEP-2,然后执行 VXLAN 封装,加上 VXLAN 头,UDP 头,以及外层 IP 和 MAC 头。此时的外层 IP 头,目标地址为 VTEP-2 的 IP,源地址为 VTEP-1 的 IP。同时由于下一跳是 Router-1,所以外层 MAC 头中目标地址为 Router-1 的 MAC。
数据包从 VTEP-1 发送出后,外部网络的路由器会依据外层 IP 头进行路由,最后到达与 VTEP-2 连接的路由器 Router-2。
Router-2 将数据包发送给 VTEP-2。VTEP-2 负责解封数据包,依次去掉外层 MAC 头,外层 IP 头,UDP 头 和 VXLAN 头。VTEP-2 依据目标 MAC 地址将数据包发送给 Host-B。
上面的流程我们看到 VTEP 是 VXLAN 的最核心组件,负责数据的封装和解封。隧道也是建立在 VTEP 之间的,VTEP 负责数据的传送。
哪些VTEP间需要建立VXLAN隧道? 通过VXLAN隧道,“二层域”可以突破物理上的界限,实现大二层网络中VM之间的通信。所以,连接在不同VTEP上的VM之间如果有“大二层”互通的需求,这两个VTEP之间就需要建立VXLAN隧道。换言之,同一大二层域内的VTEP之间都需要建立VXLAN隧道。比如假设VTEP_1连接的VM、VTEP_2连接的VM以及VTEP_3连接的VM之间需要“大二层”互通,那VTEP_1、VTEP_2和VTEP_3之间就需要两两建立VXLAN隧道
什么是“同一大二层域”? 前面提到的“同一大二层域”,就类似于传统网络中VLAN(虚拟局域网)的概念,只不过在VXLAN网络中,它有另外一个名字,叫做Bridge-Domain,简称BD。 我们知道,不同的VLAN是通过VLAN ID来进行区分的,那不同的BD是如何进行区分的呢?其实前面已经提到了,就是通过VNI来区分的。对于CE系列交换机而言,BD与VNI是1:1的映射关系,这种映射关系是通过在VTEP上配置命令行建立起来的。
哪些报文要进入VXLAN隧道? 回答这个问题之前,不妨先让我们想下VLAN技术中,交换机对于接收和发送的报文是如何进行处理的。我们知道,报文要进入交换机进行下一步处理,首先得先过接口这一关,可以说接口掌控着对报文的“生杀大权”。传统网络中定义了三种不同类型的接口:Access、Trunk、Hybrid。这三种类型的接口虽然应用场景不同,但他们的最终目的是一样的:一是根据配置来检查哪些报文是允许通过的;二是判断对检查通过的报***怎样的处理。
其实在VXLAN网络中,VTEP上的接口也承担着类似的任务,只不过在CE系列交换机中,这里的接口不是物理接口,而是一个叫做“二层子接口”的逻辑接口。类似的,二层子接口主要做两件事:一是根据配置来检查哪些报文需要进入VXLAN隧道;二是判断对检查通过的报***怎样的处理。下面我们就来看下,二层子接口是如何完成这两件事的。
在二层子接口上,可以根据需要定义不同的流封装类型(类似于传统网络中不同的接口类型)。CE系列交换机目前支持三种不同的流封装类型,分别是dot1q、untag和default,它们各自对报文的处理方式如下表所示。有了这张表,你就能明白哪些报文要进VXLAN隧道了。
| 流封装类型 | 允许进入VXLAN隧道的报文类型 | 报文进行封装前的处理 | 收到VXLAN报文并解封装后的处理 |
|---|---|---|---|
| dot1q | 只允许携带指定VLAN Tag的报文进入VXLAN隧道。 (这里的“指定VLAN Tag”是通过命令进行配置的) | 进行VXLAN封装前,先剥掉原始报文的外层VLAN Tag。 | 进行VXLAN解封装后: 若内层原始报文带有VLAN Tag,则先将该VLAN Tag替换为指定的VLAN Tag,再转发; 若内层原始报文不带VLAN Tag,则先将其添加指定的VLAN Tag,再转发。 |
| untag | 只允许不携带VLAN Tag的报文进入VXLAN隧道。 | 进行VXLAN封装前,不对原始报***处理,即不添加任何VLAN Tag。 | 进行VXLAN解封装后,不对原始报***处理,即不添加/不替换/不剥掉任何VLAN Tag。 |
| default | 允许所有报文进入VXLAN隧道,不论报文是否携带VLAN Tag。 | 进行VXLAN封装前,不对原始报***处理,即不添加/不替换/不剥掉任何VLAN Tag。 | 进行VXLAN解封装后,不对原始报***处理,即不添加/不替换/不剥掉任何VLAN Tag。 |
- 如何确定报文属于哪个BD 只要将二层子接口加入指定的BD,然后根据二层子接口上的配置,就可以确定报文属于哪个BD啦!
# 大二层网络需要有多大、及技术选型
- 数据中心内 大二层首先需要解决的是数据中心内部的网络扩展问题,通过大规模二层网络和VLAN延伸,实现虚拟机在数据中心内部的大范围迁移。由于数据中心内的大二层网络都要覆盖多个接入交换机和核心交换机,主要有以下两类技术。
a) 虚拟交换机技术 虚拟交换机技术的出发点很简单,属于工程派。既然二层网络的核心是环路问题,而环路问题是随着冗余设备和链路产生的,那么如果将相互冗余的两台或多台设备、两条或多条链路合并成一台设备和一条链路,就可以回到之前的单设备、单链路情况,环路自然也就不存在了。尤其是交换机技术的发展,虚拟交换机从低端盒式设备到高端框式设备都已经广泛应用,具备了相当的成熟度和稳定度。因此,虚拟交换机技术成为目前应用最广的大二层解决方案。 虚拟交换机技术的代表是H3C公司的IRF、Cisco公司的VSS,其特点是只需要交换机软件升级即可支持,应用成本低,部署简单。目前这些技术都是各厂商独立实现和完成的,只能同一厂商的相同系列产品之间才能实施虚拟化。同时,由于高端框式交换机的性能、密度越来越高,对虚拟交换机的技术要求也越来越高,目前框式交换机的虚拟化密度最高为4:1。虚拟交换机的密度限制了二层网络的规模大约在1万~2万台服务器左右。
b) 隧道技术 隧道技术属于技术派,出发点是借船出海。二层网络不能有环路,冗余链路必须要阻塞掉,但三层网络显然不存在这个问题,而且还可以做ECMP(等价链路),能否借用过来呢?通过在二层报文前插入额外的帧头,并且采用路由计算的方式控制整网数据的转发,不仅可以在冗余链路下防止广播风暴,而且可以做ECMP。这样可以将二层网络的规模扩展到整张网络,而不会受核心交换机数量的限制。 隧道技术的代表是TRILL、SPB,都是通过借用IS-IS路由协议的计算和转发模式,实现二层网络的大规模扩展。这些技术的特点是可以构建比虚拟交换机技术更大的超大规模二层网络(应用于大规模集群计算),但尚未完全成熟,目前正在标准化过程中。同时传统交换机不仅需要软件升级,还需要硬件支持。
- 跨数据中心 随着数据中心多中心的部署,虚拟机的跨数据中心迁移、灾备,跨数据中心业务负载分担等需求,使得二层网络的扩展不仅是在数据中心的边界为止,还需要考虑跨越数据中心机房的区域,延伸到同城备份中心、远程灾备中心。 一般情况下,多数据中心之间的连接是通过路由连通的,天然是一个三层网络。而要实现通过三层网络连接的两个二层网络互通,就必须实现“L2 over L3”。
L2oL3技术也有许多种,例如传统的VPLS(MPLS L2VPN)技术,以及新兴的Cisco OTV、H3C EVI技术,都是借助隧道的方式,将二层数据报文封装在三层报文中,跨越中间的三层网络,实现两地二层数据的互通。这种隧道就像一个虚拟的桥,将多个数据中心的二层网络贯穿在一起。
也有部分虚拟化和软件厂商提出了软件的L2 over L3技术解决方案。例如VMware的VXLAN、微软的NVGRE,在虚拟化层的vSwitch中将二层数据封装在UDP、GRE报文中,在物理网络拓扑上构建一层虚拟化网络层,从而摆脱对网络设备层的二层、三层限制。这些技术由于性能、扩展性等问题,也没有得到广泛的使用。
# 隔离
- 东西向流量是数据中心内部机器之间流量
- 南北向是数据中心内部机器和数据中心外(互联网)的流量。
隔离性通常可以分为两个层面,一是不同租户间的网络隔离,鉴于安全考虑,不同租户间内部网络不可达;二是同一租户内部不同子网(vlan)间的隔离,为业务规模较大的租户提供的多层组网能力。
# 软件定义的隔离 software-defined segmentation : software-defined Perimeter - SDN
在网络应用的初期,其在逻辑上就是一条线,网络上的主机彼此自由通信。这样的网络是没有内部结构的,看起来高效,但是有两个大的问题。第一是不安全,好人坏人都在一起,正常流量和恶意代码相互混淆。第二个问题是拥挤,各种流量都在一起,让网络变得很低效,无法有效管理和运维。这个时候,网安领域上一代明星产品——防火墙闪亮登场。防火墙把网络分成了不同的网段(segment),从而把特定的流量限制在特定网段上,这让网络比过去安全和高效得多。就靠这个杀手级应用,防火墙曾经一度占据全球网安市场的半壁江山。
随着云计算时代的到来,对防火墙的应用提出巨大挑战。云计算网络是在物理网络之上构建起来的虚拟化网络,真正负责业务处理的网络是这个虚拟化网络,而底层的物理网络上跑的都是封装之后的无意义的数据报文。云内的虚拟化网络不但是虚拟的,而且还非常动态,这是它与传统网络最大的不同,这个网络可以根据需要随意的构建,灵活程度前所未有。防火墙作为一种硬件产品,被云计算阻挡在真实的业务网络之外,而它的变种——虚拟防火墙,也因为继承了防火墙复杂繁琐的体系架构,很难适应灵活多变的软件定义网络。
结合大二层技术使用的租户隔离方式有两种常用的,一个是vlan隔离,一个是VRF(Virtual Routing Forwarding虚拟路由转发)隔离。若是采用vlan隔离,通常需要把云主机网关终结在防火墙上,这样才能满足租户间安全隔离的需求。这种模式下,一般是一个租户对应一个vlan;针对同一租户有多子网的需求,则需要在网关设备防火墙上通过较为复杂策略来实现。若是采用VRF隔离的方式,通常是把云主机网关终结在高端交换机或者路由器上,一个租户对应一个VRF。针对同租户有多子网的需求,则是一个VRF+多个vlan的模式。
受限于vlan/VRF规模,无论是“大二层+vlan”还是“大二层+VRF”,都存在云数据中心租户数量不超过4096个的限制,同时也不允许租户间的IP地址段冲突。在加上传统IP网络架构在虚拟化、灵活配置和可编程方面能力不足,在云数据中心网络服务业务链编排上也有所制约。为了解决上述问题,出现了在云数据中心网络中引入了SDN的技术潮。
# 基于身份的隔离 ID-BASED SEGMENTATION
在网络安全领域,一直以来我们用的都是五元组,也就是源和目的的IP地址和端口以及传输协议。但是IP地址本质上只是个通信参数,它无法描述业务属性和身份信息。在过去,网络相对静态的时候,我们还可以用IP近似替代身份(而这恰恰是很多网络攻击所利用的点),但是随着网络日益灵活多变,远程互联,公有云,物联网等基础设施的广泛部署,IP地址已经完全失去了身份意义。
我们必须把隔离和分段这种网络安全的核心动作构建在一种新的参数之上,也就是身份标识(ID)。所以,微隔离的新名字就是ID-BASED SEGMENTATION,可以称之为基于身份的隔离(基于身份的网络分段)。
所谓基于身份的隔离,顾名思义,就是说过去的网络隔离是面向IP的,现在的网络隔离是面向ID的。看起来是一个字母的区别,但是背后代表的技术内涵有着本质不同。我们能进行基于IP地址的隔离,事实上有个默认假设,那就是我们所要进行访问控制的资源一定有着网络位置上的确定性。但是在今天,随着云计算的广泛使用,特别是随着远程办公和BYOD的盛行,地址不再唯一确定。
在这样的背景下,IP已经逐渐变得只有通信价值而基本没有什么安全价值了,网络安全在这个时候又面临着一场史无前例的颠覆性危机。而这个时候,微隔离再一次挺身而出。我们发现,微隔离这个技术是在云计算时代出现的,它从诞生之日起就是在软件定义网络(SDN)环境下工作的。微隔离从来就认为网络地址是个不稳定参数,所以微隔离技术(真正的微隔离技术)都是面向ID的而不是IP。这个本来为应对SDN而设计的技术特征,在零信任时代,忽然焕发出了始料未及的光彩。
安全人员发现,微隔离可以有效解决当下基于IP的网络安全技术所面临的难题,从而成为了大家所熟知的零信任三个核心技术基石之一。换言之,在今天,软件定义也好,微细的控制能力也好,都已经不再是微隔离为网络安全能做的主要贡献,能够面向身份去定义网络,去进行访问控制,才是微隔离最大的价值。所以,才有了这次更名,Gartner的意思很明确,微不微的不重要,面向ID才是王道!
# example: 零信任实践 Zero trust security compliance technology framework
1、南北向:外部远程接入 在南北向,访问控制的主要挑战来自于传统VPN技术的几个隐患:
长期开放固定端口,导致网络层暴露面持续存在,这一缺陷在攻防演练中多次被攻击方成功利用。 长连接机制下,网络质量敏感型应用可能存在性能问题。 在多云和混合云接入环境下,权限控制不够精细或维护成本过高。 终端安全管控能力不足。 目前主流的VPN替代方案是软件定义边界SDP(Software Defined Perimeter),这一方案已有较为广泛的应用,其核心优势如下:
采用先认证再连接模式,避免固定端口暴露。 使用短连接方案,增强业务性能体验。 基于人和业务系统定制全局策略并实现动态自适应,在多云和混合云接入场景下更为适用,且能降低维护难度。 支持全品类主机和移动终端操作系统、SDK及浏览器环境接入,采用人+端+接入环境三维校验技术,在终端身份核验方面更具执行力,更适合移动应用和IoT终端接入场景。 2、东西向:内部主机互访 在东西向流量层面,零信任的主要解决方案是微隔离。其针对的主要安全攻击手段是横向扩散,也即攻击者获取失陷主机后作为跳板在安全域内继续扩大攻击,最终威胁到核心资产。微隔离可以通俗地理解为业务系统间防火墙,在数据中心等场景中,大二层环境和虚拟化工作负载使得这一技术更为流行。
微隔离产品一般可以做三种分类,分别是:
Hyper-V微隔离:以VM为单位进行隔离。 网络微隔离:在L3/L4进行隔离(经常借助SDN控制器)。 主机微隔离:基于主机/业务系统进行隔离。 其中最受欢迎的微隔离方案是主机微隔离,其中一个原因是这个方案相对容易部署,通过管理平台和主机上部署Agent就可以开始部署策略。无论是Windows或Linux操作系统,Agent可以通过iptables等方式进行策略控制,而在管理平台上可以将主机互访关系与路径进行可视化与管理,并针对访问需求进行策略自适应计算、异常分析与下发,这种方案在云负载、虚拟负载和物理服务器上都保持一致有效,从而阻断东西向安全威胁,缩减业务交付时间和维护成本。
3、斜向:安全域访问控制 除了讨论特别多的南北向和东西向之外,兼具二者的所谓“斜向”经常被忽略,尤其是当网络规模足够大和安全访问控制策略足够复杂时,这一方向会显得尤为重要。在跨广域网的多分支机构网络中,同时有众多远程接入用户,包括居家办公员工、供应链及第三方合作伙伴,此时安全域的划分与安全策略规划将会比较复杂。试想,此时两个主机之间的访问可能会跨三层及安全域,也就是说在南北和东西两个方向同时发生,而真正的访问控制落地会在安全设备的访问控制策略上,单纯的南北向或东西向权限控制都不能独立解决问题。
斜向对应的零信任解决方案是NSPM(Network security policy management)技术。在NSPM的访问控制基线管理功能中,可以基于业务需求和安全域访问规则设置访问控制基线,访问控制基线信息至少包括源域、源地址、目的域、目的地址、协议、端口、动作等信息,支持黑白名单、高危端口、病毒端口的自定义,支持定期依据访问控制基线对网络访问控制策略进行检查,及时发现和清除导致非法越权访问的违规策略。此外,NSPM的网络暴露风险管理功能能够以某一主机或主机组为对象,自动化实现网络暴露路径与暴露风险的分析,从网络访问关系与安全路径的角度描述其对外的暴露情况,可以帮助用户及时了解某些重要主机与网络暴露面的大小、风险的高低,辅助用户进行暴露面收敛与暴露路径的安全加固。
# 7. 概念对比
# server virtualization vs network virtualization
Server virtualization is decoupling of computing resources such as CPU, memory, storage etc from underlying physical hardware. Whereas, Network virtualization is decoupling of networking resources such as switches, routers, firewalls, load balancers etc from underlying physical network hardware.
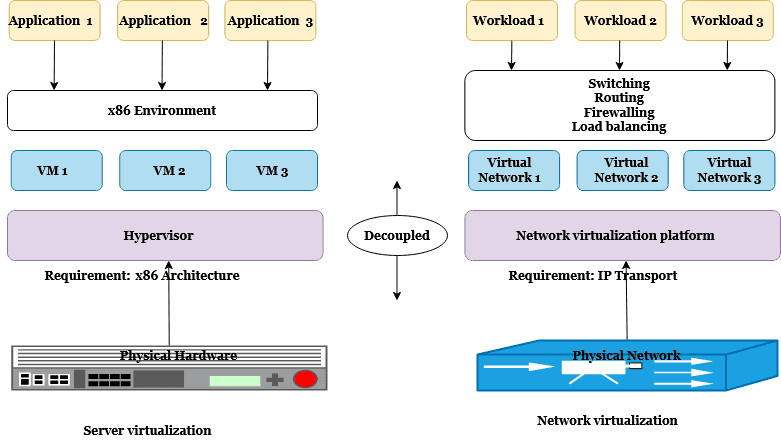
# 经典网络 VS VPC & VPC VS VXLAN
经典网络 VS VPC: 虽然各家都没有公布自己的实现细节,但是这里有点类似VXLAN和VLAN的关系
vpc是基于vxlan吗? 各家厂商的vpc实现细节各有不同不能一概而论, 从AWS公布的资料看,VPC的数据封装与VXLAN这类网络Overlay技术也很像, 需要澄清的是,AWS在2010年就已经开始应用VPC,而VXLAN标准是2014年才终稿; 阿里云的介绍有提到“使用vxlan协议对每个vpc网络进行隔离”; 华为云: provider:network_type 扩展属性:网络类型(支持vxlan,geneve),租户只能创建vxlan类型网络。
虚拟私有云 (VPC) 是托管在公共云内的安全、孤立的私有云(不是真正的单租户私有云,而是多租户虚拟私有云)。 VPC 将具有专用的子网和 VLAN,仅 VPC 客户可以访问。这样可以防止公共云中的任何其他人访问 VPC 内的计算资源 - 有效地在桌子上放置“预留”牌。VPC 客户通过 VPN 连接到其 VPC,因此其他公共云用户看不到传入和传出 VPC 的数据。
A VPC isolates computing resources from the other computing resources available in the public cloud. A VPC will have a dedicated subnet and VLAN that are only accessible by the VPC customer. This prevents anyone else within the public cloud from accessing computing resources within the VPC – effectively placing the "Reserved" sign on the table. The VPC customer connects via VPN to their VPC, so that data passing into and out of the VPC is not visible to other public cloud users.
The key technologies for isolating a VPC from the rest of the public cloud are:
子网 Subnets: A subnet is a range of IP addresses within a network that are reserved so that they're not available to everyone within the network, essentially dividing part of the network for private use. In a VPC these are private IP addresses that are not accessible via the public Internet, unlike typical IP addresses, which are publicly visible. 子网是网络中的一个 IP 地址范围,它们被预留,因此对网络内的每个人都不可用,实际上是划分了一部分网络供私人使用。在 VPC 中,这些是地址是私有 IP 地址,无法通过公共互联网访问,这不同于通常可见的典型 IP 地址。
VLAN: A LAN is a local area network, or a group of computing devices that are all connected to each other without the use of the Internet. A VLAN is a virtual LAN. Like a subnet, a VLAN is a way of partitioning a network, but the partitioning takes place at a different layer within the OSI model (layer 2 instead of layer 3). LAN 是局域网,也就是一组未通过互联网相互连接的计算设备。VLAN 是虚拟 LAN。就像子网一样,VLAN 是对网络进行分区的一种方式,但是分区发生在 OSI 模型的另一层(第二层而不是第三层)。
VPN: A virtual private network (VPN) uses encryption to create a private network over the top of a public network. VPN traffic passes through publicly shared Internet infrastructure – routers, switches, etc. – but the traffic is scrambled and not visible to anyone. 虚拟专用网络 (VPN) 使用加密在公用网络的顶部创建专用网。VPN 流量通过公众共享的互联网基础设施(路由器、交换机等)进行传输,但是流量是混乱的,任何人都看不到。
一些 VPC 提供商通过以下方式提供其他自定义:
- 网络地址转换 (NAT):此功能将专用 IP 地址与公用 IP 地址进行匹配,以便与公用互联网连接。使用 NAT,可以在 VPC 中运行面向公众的网站或应用程序。Network Address Translation (NAT): This feature matches private IP addresses to a public IP address for connections with the public Internet. With NAT, a public-facing website or application could run in a VPC.
- BGP 路由配置:一些提供商允许客户定制 BGP 路由表,以将其 VPC 与其他基础设备连接。BGP route configuration: Some providers allow customers to customize BGP routing tables for connecting their VPC with their other infrastructure. (Learn how BGP works.)
# 8.实例
# example: 虚拟机网络模式:桥接 VS NAT
# example: 无线组网 WLAN架构
参考:六种无线网络(WLAN)典型组网架构分析 (opens new window)
# example: 华为云 huawei cloud
典型结构:

例子: 从公网进入的流量
从互联网进入的流量, 主要是访问VPC-COM中的应用, 如WEB等, 这些应用需要开放给互联网用户, 进入的流量首先云防火墙(IPS), 可以过滤掉恶意网络攻击流量, 再经过 VPC-FWOUT 的安全组的访问控制, 最后经过CheckPoint防火墙进行DNAT操作才能访问到目标服务器.
example: www.lyhistory.com 云解析到 cdn 浏览器=》cdn=》waf地址池=》负载均衡器elb 公网地址<只开放访问给waf地址池>(ELB NAT到内网,后端指向防火墙服务inbound)=》 再转到内部http负载均衡器=》源服务器,
访问公网的出去的流量
云上的云服务器要访问Internet资源, 需要先经过虚拟私有云VPC-COM中的proxy服务器(趋势科技), 再经过VPC-FWOUT中的安全组规则, 最后经过CheckPoint防火墙做SNAT后进入互联网.
example: VPC-COM内网ecs实例机器访问google.com,内网路由表没有google.com对应的内网路径,所以路由匹配 0.0.0.0 走华为云的对等连接peering-com-fwout 到VPC-FWOUT,该VPC-FWOUT的路由表 rtb-VPC-FWOUT 0.0.0.0下一跳类型为虚拟IP--该虚拟ip是绑定到子网subnet-fwout,而子网subnet-fwout可以直接绑定ECS实例:ecs-fwout (上面运行防火墙服务比如checkpoint) ,最后经过防火墙进行DNAT操作才能访问到目标服务器.
Network Protocols and Architecture https://www.coursera.org/learn/network-protocols-architecture
ipset vpn(一般对外走公网,不可靠) VS leased line(一般连接内网和数据中心)
vlan/vxlan技术(用于连接多个数据中心,让其变成逻辑上一个中心)
BB: underlay backbone core switch FW: Firewalls DC: VXLAN overlay network Core switch leaf access switch 一套配置是指一个BB+一个FW+一个DC,BB通过防火墙连接DC,DC再连接access layer,access layer连接服务器; 两个datacenter各自有两套配置,两个datacenter的两套配置各自通过一条黑色物理电缆连接,一条一个运营商, 然后可以看到逻辑上蓝色和黑色是分开的,但物理上是用黑色同一条线,逻辑上是通过协议来区分的,协议就是在通信的header里面加多一点信息来区分BB和DC
# example: VPN+Proxy服务器(从私人电脑在任何地方访问办公网络及外网)
例如: Remote Access VPN(加密访问流量,从而可以在任何地方安全访问办公网络,如使用checkpoint vpn,设置自定义DNS服务器)+ 代理服务器 (split traffic 有些流量走内网,有些走外网,并且代理服务器内设置有防火墙规则可以对访问进行限制以及记录)
用户电脑安装 vpn client并设置 系统代理 windows system proxy => pac script
pac script: 规则大概就是,dns解析(这里是自定义的dns服务器,不是公共的)出来的如果是内网ip则直接访问,否则(是外网)则需要走Proxy服务器
function NextFindProxyForURL(url, host) {
// If the requested website is hosted within the internal network, send direct.
if (isPlainHostName(host) ||
shExpMatch(host, "*.local") ||
isInNet(dnsResolve(host), "192.168.0.0", "255.255.0.0") ||
isInNet(dnsResolve(host), "x.x.x.x", "255.255.255.255") ||
isInNet(host, "x.x.x.x", "255.255.255.255")
return "DIRECT";
if (dnsDomainIs(host, "example.com") ||
dnsDomainIs(host,"www.example.com"))
return "DIRECT";
if (isInNet(myIpAddress(), "x.x.x.0", "255.255.252.0")){
return "PROXY x.x.x.x:8080";
}
// DEFAULT RULE: All other traffic, use below proxies, in fail-over order.
return "PROXY x.x.x.x:8080";
}
function FindProxyForURL (url, host)
{
var resolvedIP ;
if (isResolvable(host))
resolvedIP = dnsResolve(host);
else
return NextFindProxyForURL(url, host);
if (isInNet(resolvedIP, "x.x.x.x", "255.255.255.255") ||
isInNet(resolvedIP, "x.x.x.x", "255.255.255.255") ||
(resolvedIP== "127.0.0.1") ||
(host=="127.0.0.1") ||
(url=="127.0.0.1"))
return "DIRECT";
else
return NextFindProxyForURL(url, host);
}
Checkpoint VPN =》Advanced proxy settings (默认detect proxy from IE settings,不过我好像设置了no proxy也没有什么作用?)
首先VPN会增加一条路由,比如:
192.168.1.101 是本地无线路由的ip,电脑通过vpn客户端成功连接vpn则会获取到vpn分配的内网ip 172.16.10.101,增加路由(临时路由?)从 192.168.1.101 到 vpn的网关172.26.1.100, 这样所有流量就会走vpn了
route print
Active Routes:
Network Destination Netmask Gateway Interface Metric
0.0.0.0 0.0.0.0 192.168.1.100 192.168.1.101 35
192.168.1.101 255.255.255.255 172.26.1.100 172.16.10.101 1
员工电脑访问网站A,浏览器首先是走vpn配置的dns服务器(ipconfig /all 查看)进行域名解析,拿到ip后对比pac规则,如果是内网ip直接访问; 如果是外网,比如通过chrome访问https://www.google.com/search?q=test,
浏览器检测到 pac proxy:
t=39031 [st=0] +HTTP_STREAM_JOB_CONTROLLER [dt=6]
--> is_preconnect = false
--> privacy_mode = "disabled"
--> url = "https://www.google.com/search?q=test&rlz=1C1GCEU_enSG1047SG1047&oq=test&aqs=chrome..69i57j0i67l3j0i67i433j69i60j69i65j69i60.1924j0j1&sourceid=chrome&ie=UTF-8"
t=39031 [st=0] HTTP_STREAM_JOB_CONTROLLER_BOUND
--> source_dependency = 53302 (URL_REQUEST)
t=39031 [st=0] +PROXY_RESOLUTION_SERVICE [dt=5]
t=39032 [st=1] +HOST_RESOLVER_MANAGER_REQUEST [dt=0]
--> allow_cached_response = true
--> dns_query_type = 1
--> host = "www.google.com:0"
--> is_speculative = false
--> network_anonymization_key = "https://google.com null same_site"
--> secure_dns_policy = 0
t=39032 [st=1] HOST_RESOLVER_MANAGER_CACHE_HIT
--> results = {"aliases":[],"expiration":"13322549710063767","ip_endpoints":[{"endpoint_address":"142.251.10.103","endpoint_port":0},{"endpoint_address":"142.251.10.105","endpoint_port":0},{"endpoint_address":"142.251.10.99","endpoint_port":0},{"endpoint_address":"142.251.10.106","endpoint_port":0},{"endpoint_address":"142.251.10.147","endpoint_port":0},{"endpoint_address":"142.251.10.104","endpoint_port":0}]}
t=39032 [st=1] HOST_RESOLVER_MANAGER_CACHE_HIT
--> results = {"aliases":[],"expiration":"13322549710063767","ip_endpoints":[{"endpoint_address":"142.251.10.103","endpoint_port":0},{"endpoint_address":"142.251.10.105","endpoint_port":0},{"endpoint_address":"142.251.10.99","endpoint_port":0},{"endpoint_address":"142.251.10.106","endpoint_port":0},{"endpoint_address":"142.251.10.147","endpoint_port":0},{"endpoint_address":"142.251.10.104","endpoint_port":0}]}
t=39032 [st=1] -HOST_RESOLVER_MANAGER_REQUEST
t=39036 [st=5] PROXY_RESOLUTION_SERVICE_RESOLVED_PROXY_LIST
--> pac_string = "PROXY X.X.X.X:8080"
t=39036 [st=5] -PROXY_RESOLUTION_SERVICE
t=39036 [st=5] HTTP_STREAM_JOB_CONTROLLER_PROXY_SERVER_RESOLVED
--> proxy_server = "PROXY X.X.X.X:8080"
t=39036 [st=5] HTTP_STREAM_REQUEST_STARTED_JOB
--> source_dependency = 53305 (HTTP_STREAM_JOB)
t=39037 [st=6] -HTTP_STREAM_JOB_CONTROLLER
53305: HTTP_STREAM_JOB
https://www.google.com/
Start Time: 2023-03-06 12:15:01.539
该http请求中携带有proxy,vpn client网关将该http请求加密然后发送到vpn server,vpn server解密后拆包后发现proxy就将请求继续转发到proxy server,然后代理服务器经过过滤审查放行之后再去到最终的目的地,所以最终外网看到的员工的公网地址实际是代理服务器的公网地址;
如果此时使用wireshark抓包则会发现包的 destination 就是代理服务器的IP,即上面的 PROXY X.X.X.X:8080 的 X.X.X.X
注意:
- 如果 nslookup google.com 肯定显示的是google的公网地址,因为dns resolve on UDP 不是一个browser traffic
- nslookup myip.opendns.com resolver1.opendns.com 查询到的myip是本地网络的公网IP,而不是VPN或者代理服务器的公网IP,原因应该也是 dns resolve on UDP 不是一个browser traffic
- 如果使用curl查询当前ip,会发现默认是绕过了代理服务器,暴露的是真实的本地网络的公网ip,如果使用vpn则暴露的是VPN公网IP,因为如果使用proxy需要特别指定给curl --proxy "proxy server"
不信你试试不加proxy curl 'https://zh-hans.ipshu.com/my_info' \ -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9' \ -H 'Accept-Language: en-US,en;q=0.9' \ -H 'Connection: keep-alive' \ -H 'Referer: https://www.google.com/' \ -H 'Sec-Fetch-Dest: document' \ -H 'Sec-Fetch-Mode: navigate' \ -H 'Sec-Fetch-Site: cross-site' \ -H 'Sec-Fetch-User: ?1' \ -H 'Upgrade-Insecure-Requests: 1' \ -H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36' \ -H 'sec-ch-ua: "Not?A_Brand";v="8", "Chromium";v="108", "Google Chrome";v="108"' \ -H 'sec-ch-ua-mobile: ?0' \ -H 'sec-ch-ua-platform: "Windows"' \ --compressed - 跟curl相反,浏览器默认是使用系统proxy,绕过代理服务器需要设置no proxy
- 不管是curl还是设置了no proxy的浏览器,暴露的是真实的本地网络的公网ip,如果使用vpn则暴露的是VPN公网IP,不过有一种情况,比如通过DHCP option 252 配置了pac proxy,然后使用比如checkpoint vpn配置了自定义的DHCP,那么no proxy的状态下会同时绕过VPN,然后直接暴露的是本地网络的公网ip
同理,当我们访问whatsmyip.com来查看当前公网IP的时候,显示的公网IP也将是代理服务器的IP,如果只用了VPN没用代理服务器,则是显示VPN服务器的IP, 如果显示的是自己本地网络的公网IP,则说明访问路径存在问题,比如: vpn is working but ip address not changing (opens new window)
再比如之前使用用友的财务web版本的时候,设置了ip白名单(放了公司代理服务器的公网IP),但是某个同事在家中访问的时候被拦截,原因有些复杂: 安全上使用了 checkpoint VPN配置的自定义的DHCP,然后通过DHCP option 252 配置了pac proxy, 所以连接VPN自动获取IP的同时会拉取pac文件,然后vpn客户端也会根据pac的配置连接代理服务器,但是因为一些原因连接不上,造成电脑虽然连上了VPN客户端,但是VPN并没有工作,所以浏览器访问的时候还是走了本地网络而不是VPN,从而用友的网站检测到的是用户自己的家庭网络公网IP;
VPN不工作分析:
最有可能的就是,vpn客户端设置了规则,虽然用户连接到了vpn,但是vpn客户端检测到代理服务器不通的时候则不会在路由表中添加上面的这条记录:
192.168.1.101 255.255.255.255 172.26.1.100 172.16.10.101 1
从而所有流量仍然是走本地网卡如WLAN 而不是VPN虚拟网卡;
但是有个疑问:浏览器默认不是会用系统proxy吗,即使VPN失效,应该依然走proxy呀?
可能是这样,正常我们静态设置代理或者使用比如v2ray配置客户端全局代理,但是这里是通过vpn客户端配置的全局代理,当vpn发现代理服务器连不上时就同时不去设置全局代理了。 正常情况下是vpn client将http请求加密后送到vpn服务器,然后vpn服务器解密后送到代理服务器,可能用户本地直连proxy服务器也是不通的,所以也就没走代理服务器了;佐证:看到网上中英文社区都有人提到,在代理失效后浏览器无法上网,办法就是在 LAN settings 中选用自动检测,而刚好该用户电脑配置的也是自动检测的pac脚本,所以代理失效(连不上)浏览器会自动直连上网
谜底揭开:发现同事的chrome浏览器装了插件 unblock youku,导致chrome默认就是走这个插件的proxy规则:即访问优酷的时候是用国内ip,其他的站点都是direct访问,也就是相当于绕过了vpn,自然也绕过了公司的proxy
# example: VPN 分流 split/selective traffic
https://superuser.com/questions/12022/how-can-i-make-the-windows-vpn-route-selective-traffic-by-destination-network
todo:
虚连接(VC:Virtual Connection)TCP虚连接?
# 参考 Ref:
[局域网技术与组网工程 第二版]
Packet sniffer basics for network troubleshooting (opens new window)
网络7层协议,4层,5层?理清容易混淆的几个概念 (opens new window) Netty(三) 什么是 TCP 拆、粘包?如何解决? (opens new window)
如何用30分钟快速优化家中Wi-Fi?阿里工程师有绝招 (opens new window)
网络知识梳理--OSI七层网络与TCP/IP五层网络架构及二层/三层网络 (opens new window)
技术发烧友:网络设备虚拟化 (opens new window) 走近数据中心大二层网络 (opens new window)
【安全科普】阿里云“经典网络”真的不安全? (opens new window) 浅谈VPC二三,秒懂秒透 (opens new window)
组播 VLAN (opens new window) 交易系统设计要点 (opens new window)
单播、多播、广播、组播、泛播、冲突域、广播域、VLAN概念汇总 (opens new window)
从攻击面视角,理解零信任 (opens new window) SDN在云数据中心的应用——架构篇 (opens new window) 为什么说不要用VLAN、VPC解决东西向隔离问题 (opens new window)